神经网络可解释性的另一种方法:积分梯度,解决梯度饱和缺陷
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
今天介绍一种特定的神经网络可解释性方法 -- 积分梯度法 (Integrated Gradient)。几天前 Keras网站刚刚添加了这种方法的示例代码(2020/06/02),Distill 网站也增加了积分梯度的科普文章(2020/06/10)。本人非常好奇这种可解释性方法为何突然蹿红,故进行调查。
这种方法的提出是为了解决传统基于梯度的可解释性方法的一个缺陷 -- 梯度饱和。在最原始的 Saliency map方法中,假设神经网络的分类结果线性依赖于输入图片中的每个像素或特征, 表示为 , 则输出 y 对输入 x 的梯度 能够直接用来量化每个像素对分类决策的重要程度。
然而,真正的神经网络高度非线性。某个像素或特征增强到一定程度后可能对网络决策的贡献达到饱和。李宏毅老师举过一个例子,大象的鼻子对神经网络将一个物体识别为大象的决策很重要,但当大象的鼻子长度增加到一定程度后(比如1米),继续增加不会带来决策分数的增加,导致输出对输入特征的梯度为0。

鼻子的长度对大象很重要,但原始的 Saliency map 方法在饱和区将其重要性设为0,明显违反常识。在鼻子长度大于0.5米小于1米的样本中,鼻子长度的重要性又能表现出来,
画在图上,
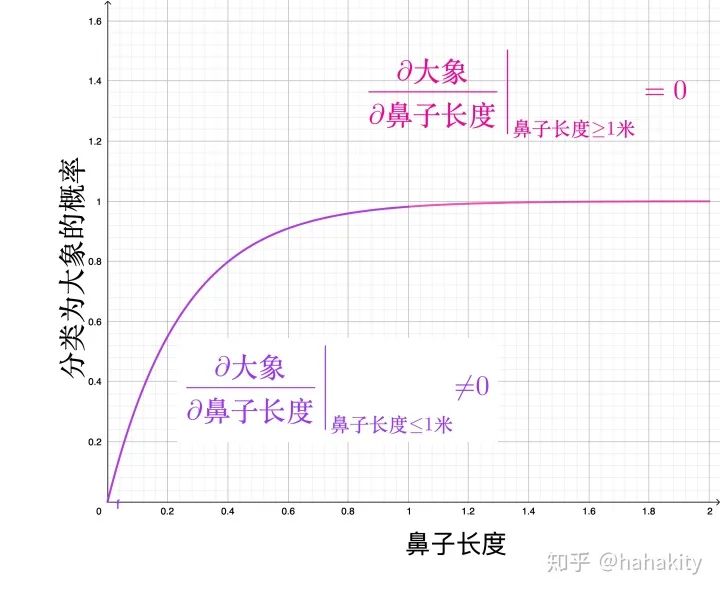
对于鼻子长度大于等于 1 米的大象,为了正确捕捉鼻子长度的重要性,积分梯度法不是使用上面这张图中粉红色部分的梯度(基本为0),而是使用沿整条梯度线的积分值,作为鼻子长度对决策分类的重要程度。写成公式就是,
这是一个挺好玩的想法。唯一困难的地方在于对于一张给定的图片,大象鼻子长度已定(比如=2 米), 如何得到鼻子长度小于 2 米时输出对输入的梯度呢?
假设当前图像为x,如果知道鼻子长度 = 0 米时的基线图像 x',那倒可以做一个线性插值,
当常数 时,输入图像为基线图像 x', 当 时, 就是当前图像,在中间即为其他图像。这种方法不能说得到了鼻子长度改变的梯度积分,只能说得到了图像所有像素变化时的梯度积分。
假设神经网络的输出为函数 f, 则积分梯度法的最终公式为,
注意第一项 来自于后面积分变量 。分母上的 表示变分。这里整个偏导被换成了变分的形式,变分边界是基线图像和当前图像,变分路径可以任意选择。
积分梯度法使用线性插值作为变分路径。
如何选择基线图像呢?原始文献考虑了使用纯黑图片和噪声图片作为基线的情形,也讨论了使用这些基线的缺陷。比如纯黑图片,可能不在 valid 区间。Distill 文章对比了几种替代方案,
-
最大距离图片。从图片集中选择与当前图片L1距离( L1=|x - x'| )最大的图片,使得每个像素都在 valid 区间。 -
光滑模糊图片。最大距离图片的问题是,它可能包含了当前图片的信息,不能表示特征丢失对分类结果的影响。使用模糊的照片,可以捕获特征丢失对梯度的贡献。 -
均匀随机图片。每个像素通过 valid 区间内均匀分布抽样得到。 -
高斯随机图片。为当前图片的每个像素安排一个高斯分布,从高斯分布中抽样生成基线图片。
至于说究竟哪种基线图片最好,Distill 文章没有下结论,只是声称可解释性本身没有很好的判断标准,即便是人眼,也很难说明孰好孰坏。
除了积分梯度法,DeepLift 方法也使用了基线图片来量化可解释性。DeepLift 使用类似层间相关性传递的算法(LRP),把重要性从输出一层层传递到输入。
总结
直接使用输出对输入的梯度作为特征重要性会遇到梯度饱和问题。积分梯度法从通过对梯度沿不同路径积分,期望得到非饱和区非零梯度对决策重要性的贡献。原始积分梯度法使用纯黑图片,噪声图片作为积分基线。Distill 尝试了4种不同的积分基线。积分路径一般选作线性插值,不知到是否有人考虑过选择不同的插值函数做积分路径。
参考文献:
-
原始文章:https://arxiv.org/abs/1611.02639 -
DeepLift: https://arxiv.org/abs/1704.02685 -
Distill 科普:https://distill.pub/2020/attribution-baselines/ -
Keras 代码:https://keras.io/examples/vision/integrated_gradients/ -
李宏毅课程:https://www.bilibili.com/video/av77023354/?p=2
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




