![]()
在本文中,Facebook人工智能研究院研究员、卡耐基梅隆大学机器人系博士田渊栋以ReLU网络为例,分享了深度学习理论和可解释性方面的研究进展。田渊栋博士提到,
在学生-教师设置下的ReLU神经网络中,存在学生网络和教师网络的节点对应关系,通过对这种关系的分析,可以帮助我们理解神经网络的学习机制,以及剪枝、优化、数据增强等技术的理论基础。
2020年7月31日至8月5日,VALSE 2020视觉与学习青年学者研讨会在线上举行。在主题为《机器学习前沿进展》的论坛中,田渊栋博士发表了题目为《深度ReLU网络中可证明的理论性质》的演讲。
VALSE年度研讨会的主要目的是为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。截至目前,VALSE已举办9届。
以下是讲座全文,AI科技评论进行了不改变原意的整理。
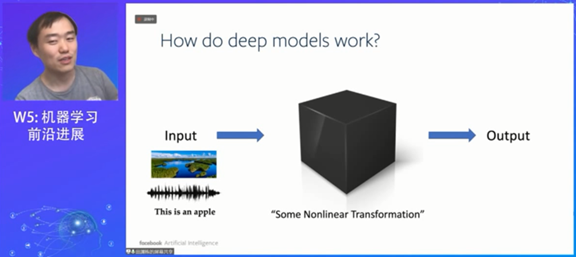
深度学习模型缺乏可解释性,它的工作模式对于我们而言就是个黑盒,意思是我们不关心深度学习的内部机制,只需要知道输入对应的输出就好。但问题是,如果以后我们要提高神经网络的性能,就需要把黑盒打开,理解其机制。
![]()
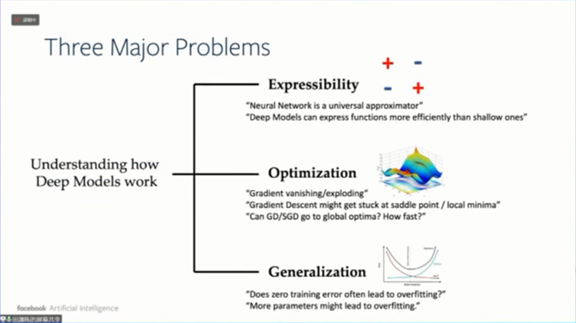
神经网络的理论研究有三个的方向,第一个是可表达性(Expressibility),即神经网络能多大程度上拟合函数。现在我们知道,只要有一层无限神经元的隐层,神经网络就能拟合任何函数,这个结论在80年代就已经有人证明出来了。
![]()
但是关于泛化能力的理解,还需要解决后面两个问题,即优化和泛化。
在非凸优化中,损失函数有很多局部最小值,但是神经网络能找到一个比较好的最小值,这应该如何解释?
对于神经网络,不同的学习设置导致的学习效果几乎没有什么区别,这令人惊讶。因为按照一般假设,不同的初始化设置学习的结果应该是完全不一样的。我们现在在这些问题上还没有很好的理论解释。最后一个问题是泛化问题。
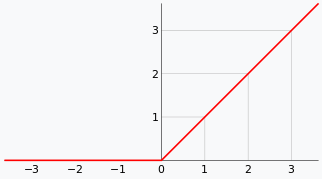
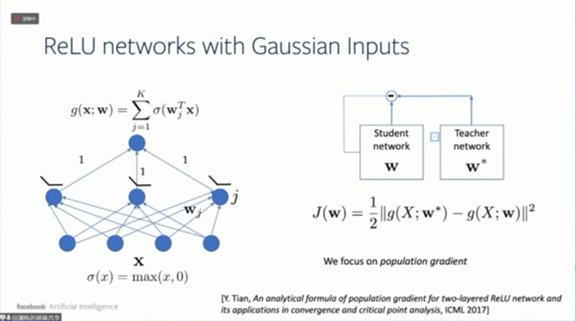
今天我们讨论ReLU 网络,ReLU激活函数在神经网络的应用非常广泛。因为它很容易实现,而且学习比较快,能自然地实现网络稀疏性。除此之外,它还有一些非常有趣的理论性质,并且它的函数性质对理论分析来说有好处。当然,它也有不足的地方,比如说不可微的、不可逆,存在参数化奇点等。
![]()
![]()
ReLU函数(图源:维基百科)
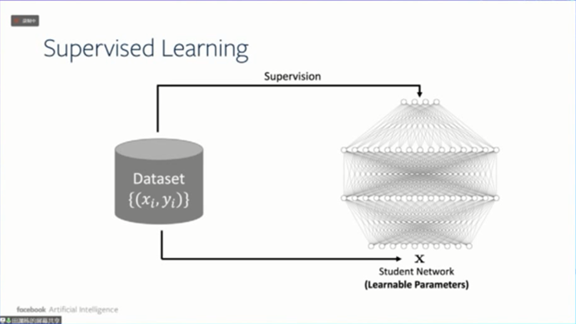
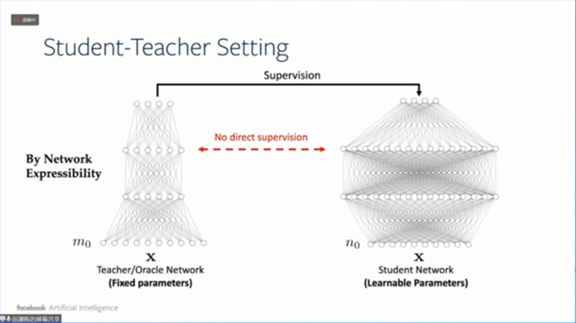
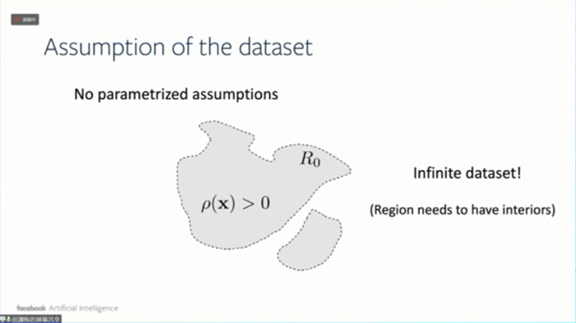
接下来讨论ReLU网络在学生-教师设置下的理论性质。设置是什么意思呢?举个例子,比如监督学习。在监督学习设置中,我们有将x标记为y的数据集,然后我们训练一个神经网络,输入x能得到y。
![]()
而在学生-教师的设置中,我们把数据集替换成一个教师网络(或者Oracle Network)。
![]()
这种设置有一些良好的性质,首先是解决可表达性,
按照万能逼近定理,任给一个数据集总存在一个教师网络能拟合数据集
。假设总有教师神经网络能够完全拟合所有数据,然后用学生神经网络去学习教师神经网络,就可以拥有参考点,这个参考点可以用来做细致的优化分析。以前只能通过损失函数来学习,现在可以通过学生网络和教师网络之间的权重对应关系来进行。
这种设置对于理解泛化能力有更多的优势。因为如果我们能证明,学生网络跟教师网络的节点存在对应关系,就可以证明泛化能力。因为学生网络不仅仅只是在输出结果上相同,而且在内部结构上也相同,也即是学生网络学到了教师的“精髓”。对于新的输入,我们可以预言学生网络和教师网络的输出是一样的。所以这种设置其实在某种程度上可以简化一些理论分析。
学生-教师设置在1995年就已经有物理学家提出来,当时使用的是两层神经网络,并且没有使用ReLU函数,此外他们还假设,输入样本的维度必须是无穷大的。
![]()
在现代的理论看来,无穷维不是一个很好的假设。我们可以假设ReLU网络的输入是有限维的,并且服从高斯分布。这样,我们可以解析地得到梯度的期望值。
![]()
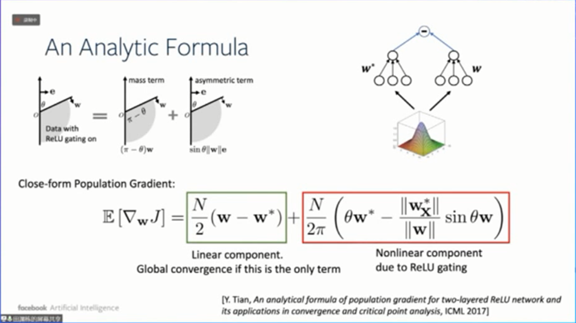
梯度有两个部分,分别是线性部分和ReLU函数导致的非线性部分。如果只有线性部分,神经网络会收敛到最小值。
![]()
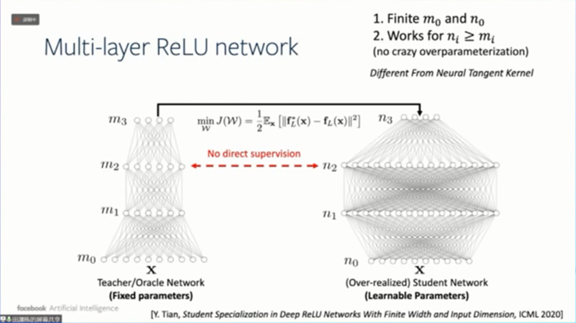
我们现在来看多层的学生神经网络和教师神经网络,其中m和n是相对宽度,都是有限的,学生神经网络比教师神经网络稍微宽一点。
![]()
我们可以证明,
至少对于最靠近输入的那一层,学生网络的每个节点跟教师网络的节点都是有对应关系的,也就是说学生网络可以学到一些教师网络的精髓。
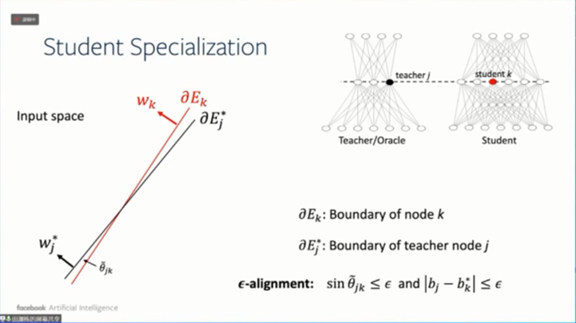
什么叫学到了教师网络的精髓?就是说我们把学生网络节点和教师网络节点的边界显示出来,他们的边界之间会存在重叠。
![]()
现在问题在于,如果我们假设在训练过程中,对每个训练样本都得到了很小的梯度,与学生网络和教师网络的节点对齐之间存在关系呢?
![]()
首先,我们能得到一个引理,即学生网络的梯度其实可以写成教师网络激活函数和学生网络激活函数的线性组合。
![]()
我们来通过两个案例解释如何使用这个引理来导出学生与教师网络节点的对应关系。
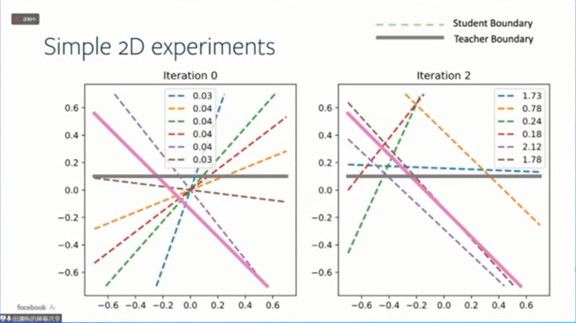
先考虑理想化假设,两层ReLU神经网络,梯度等于0,样本数无限。其中有6个学生网络节点,用点画线表示,2个教师网络节点,用粗体线表示,下图显示了这些节点的边界。
![]()
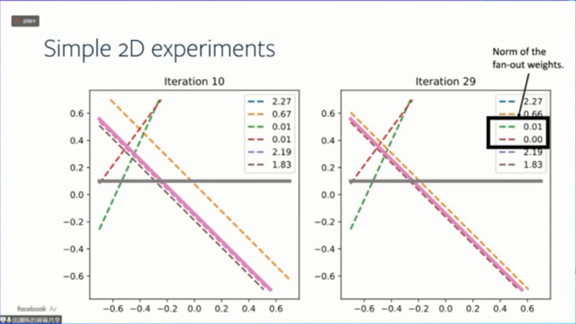
随着训练迭代进行,有些学生网络节点会慢慢收敛到教师网络节点,有些则不会,而是随机排列,比如下图中红色和绿色的点画线。
![]()
与此同时,这两个学生网络节点对外的输出权重的范围刚好是很小的。
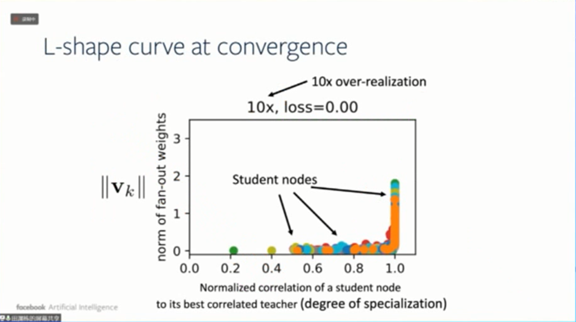
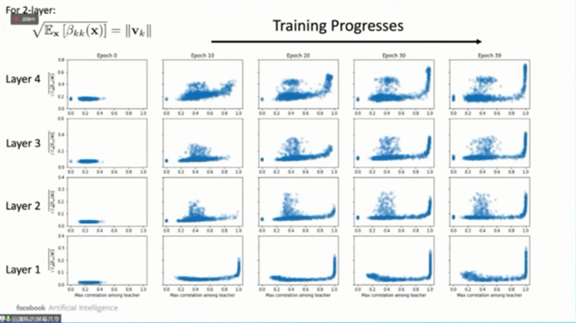
下图是另外一个实验的结果,横轴是学生网络节点和最佳关联教师网络节点之间的相关程度,纵轴是输出权重的范围。从图中我们可以看出,这两个变量形成了“L”形曲线关系。如果学生节点和教师节点没有太大关联,那它输出权重的范数就很小,反之则有很强的关联。
![]()
要证明这个结论成立,其实需要很多假设。那么其中一个假设是数据集样本数无限。之后我们会把这个假设去掉。但是关键在于我们不需要对数据的分布做任何的假设。
![]()
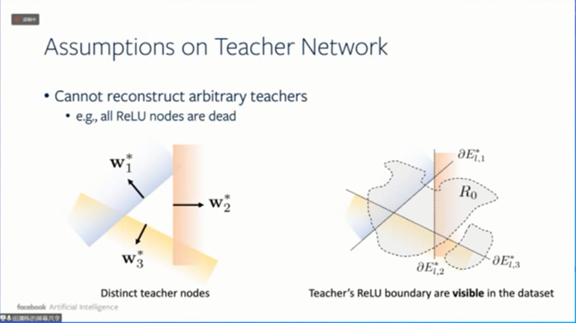
第二个假设是,教师神经网络的每个节点的ReLU边界对于数据集都是可见的。
![]()
有了这两个条件,我们可以得出,
对于任意一个教师网络节点j,至少存在一个学生网络节点k’与它对齐。
![]()
对于任何一个教师网络节点,都存在一个学生网络节点与它对齐,实际上对齐的节点可能会有2到3个。反过来,并不是所有的学生网络节点都一定和教师网络节点对齐,有些学生网络节点可能没有跟任何教师网络节点对齐。
这样我们能得到另外一个定理,
可以证明在满足某些条件时,那些没有对齐的学生网络节点(下图的黑色点),它的输出权重会是0,这就给我们提供了如何对神经网络进行剪枝的理论基础。
![]()
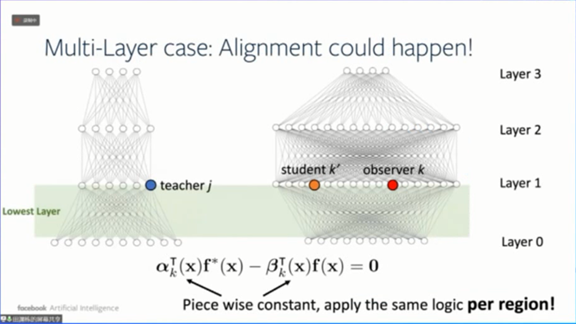
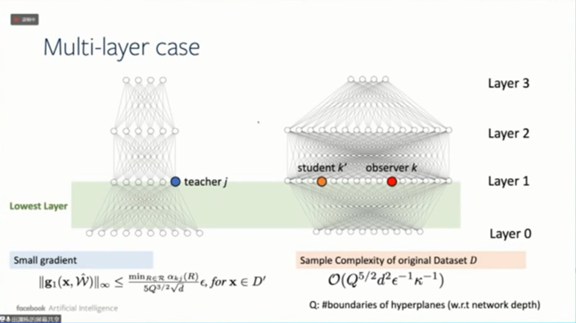
这个结论对于多层神经网络同样成立,因为之前提到的引理能应用到任何深度神经网络。
![]()
下图展示了多层神经网络的实验,我们同样得到了“L”形曲线关系。
![]()
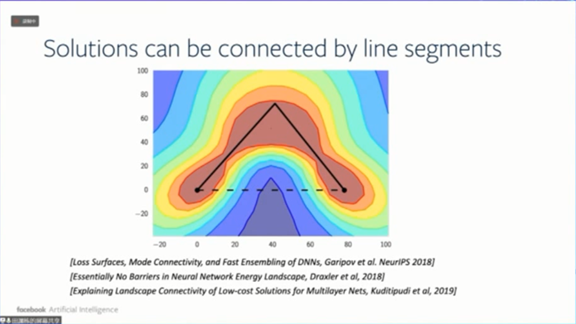
同样的思路可以用来解释神经网络的一些非常奇怪的现象,比如说将神经网络训练到两个局部最小值,这两个解如果用折线(而不是直线)连起来,可以保证折线上的每个解的错误率都比较小,这跟凸优化的情况很不一样。
![]()
2、非理想化假设
我们之前做了一些理想化的假设,比如说梯度等于0,数据集样本数无限,现在我们做一些更加实际的假设,即两层ReLU神经网络,梯度很小但不等于0,数据集样本数有限。
我们规定梯度不等于0,而且比较小,是小于某个样本复杂度上界。然后我们对数据集也做了增强,增强数据本身会影响到最后样本复杂度上界的松紧。
![]()
最后能得到两个结论,第一个是,
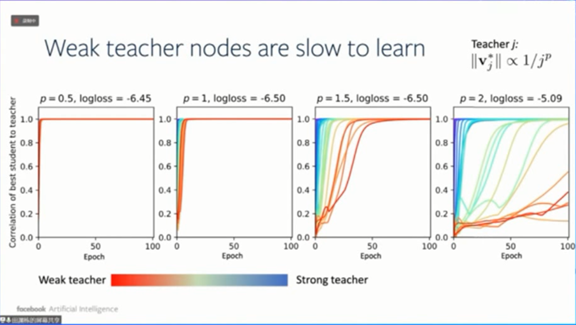
更强的教师网络节点学习更快。
简单来说就是,
那些输出权重较大的教师网络节点,有更多的学生网络节点与其对齐。
此外由于样本复杂度上界和学生网络节点与教师网络节点的点积正相关,当教师网络节点更强时,梯度的样本复杂度上界更加宽松。
![]()
反过来结论也成立,
更弱的教师网络节点学习更慢。
下图展示了不同教师网络节点的关联强度随训练的变化。
![]()
另外,不同的数据增强的技术会得到不同的样本复杂度上界。
如果数据增强的方向,跟教师网络节点的样本复杂度上界的方向一致的话,样本复杂度上界就会变得更紧。
![]()
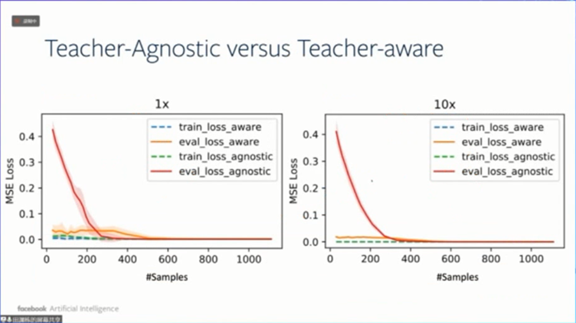
使用不同数据增强技术的数据集,样本复杂度可能会非常不同。如果我们利用教师网络的知识增强数据集,即使只有少量样本,经过训练的学生网络也不会过拟合,并能大大降低评估损失。
![]()
![]()
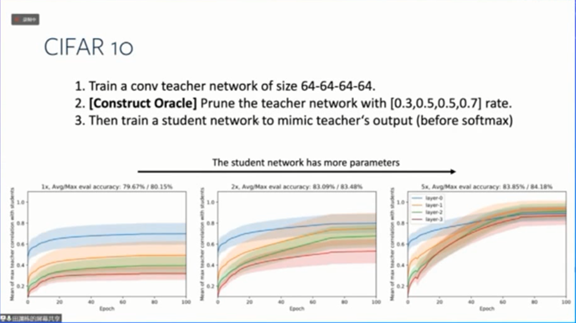
我们还在CIFAR-10上进行了实验。首先在CIFAR-10训练集上使用64-64-64-64 ConvNet对教师网络进行预训练。然后以结构化方式对教师网络进行剪枝,以保留更强的教师网络节点,并且剪掉那些对输出没有太大影响的节点。基于教师网络的剩余通道,学生网络被“过实现”(over-realized)。
下图展示了学生网络的收敛和专业化行为。
“过实现”会导致在CIFAR-10评估集上教师节点和学生节点的相关性更强,泛化能力得到改善。
![]()
https://arxiv.org/pdf/1703.00560.pdf
https://arxiv.org/pdf/1909.13458.pdf