悉尼科技大学提出:域迁移分割算法,即插即用
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:交大第一carry
https://zhuanlan.zhihu.com/p/102388584
本文已授权,未经允许,不得二次转载
在实际场景中,我们往往有很多source domain的数据(比如游戏生成的模拟数据)有着标签,但是拿去实际场景预测,往往模型由于domain gap表现得不好。Domain Gap是多方面的,有因为不同天气,不同城市,不同光照等等影响。所以大多数domain adaptation 方法研究的是如何尽可能挖掘常识,采用了很多特征对齐(alignment)的方法。但是忽略了本身域内部的信息。
本文就是提出了一个即插即用的memory regularization 正则项来让模型学intra-domain knowledge,在两个benchmark上都有了一些提升。
论文:Unsupervised Scene Adaptation with Memory Regularization in vivo

论文地址:https://arxiv.org/abs/1912.11164
国内镜像:http://xxx.itp.ac.cn/abs/1912.11164
简介:
What
本文想要解决的是无监督域迁移问题,具体研究的是场景分割,测试的数据集为 GTA5 -> Cityscapes 和 Synthia -> Cityscapes;
已存在的方法往往关注于特征对齐,即不同域的图像要映射到相同的特征空间,但是这往往是次优的,因为target域里本身的一些特有的有区分力的特征被忽略了;
同时,如下图,他们发现在对没有标注的目标域图像上,基于对齐的方法,预测结果往往是抖动的,这也说明了目标域本身的特征Consistency并没有随着特征对齐而 自然而然的学到。
提出的方法即插即用,利用了两个分类器的结果,一个是主要分类器,一个是辅助分类器;
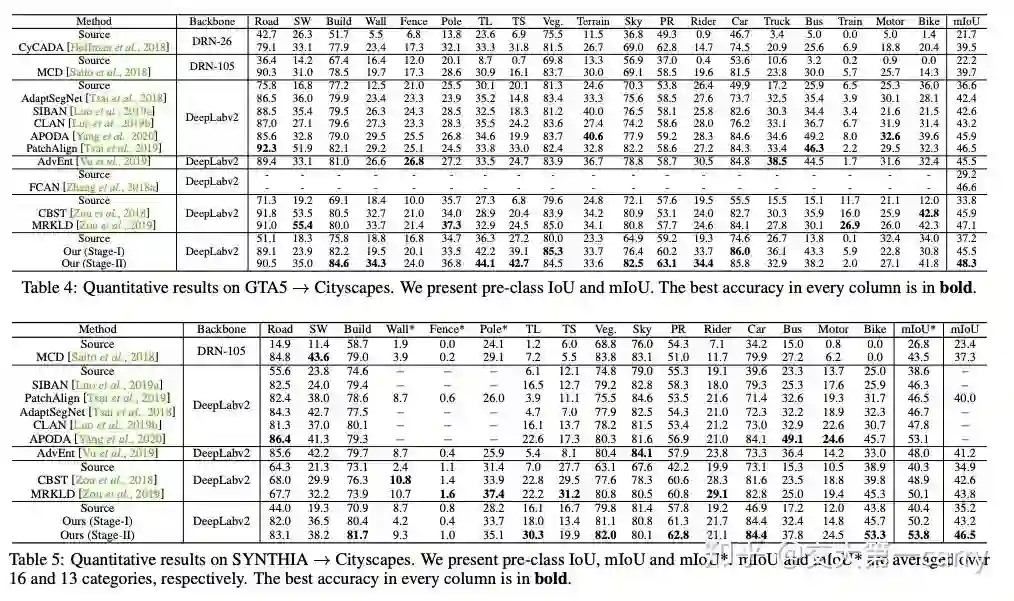
在GTA5 -> Cityscapes 上相比source only提升了11.1% mIoU, 在SYNTHIA-> Cityscapes 上提升了11.3% mIoU

How:
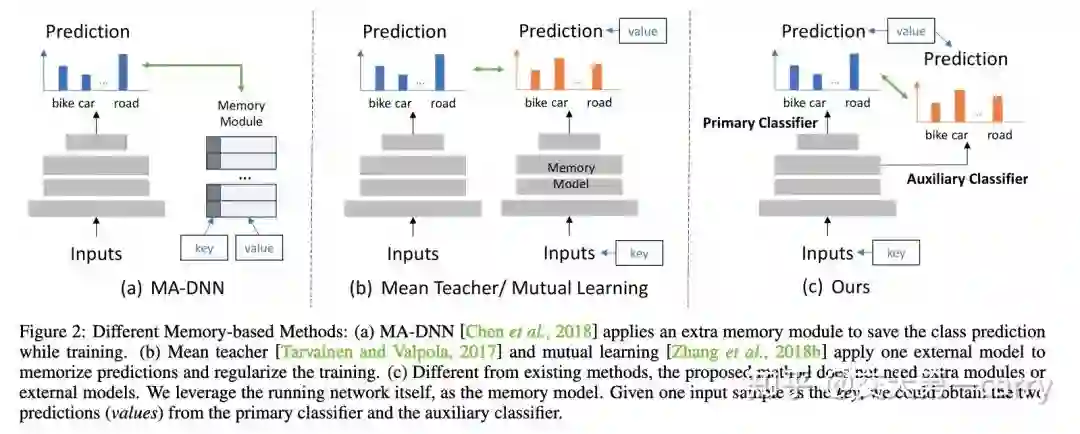
作者利用了memory term来正则网络训练,具体什么是memory?我们从相关工作说起,MA-DNN是一个半监督的CNN训练方法,提出用一个look up table来存每一类的特征向量,类似center loss里面weight的感觉,但是是使用一个外部module,采用moving average来更新;而CCF优秀论文 deep mutual learning 和 mean teacher 两个semi-supervised常用的方法,则可以看成利用了一个模型来代替look up table,本质上也是输入一个input,得到一个value。此时input可以看成MA-DNN的key。
而作者提出的方法则进一步整合了模型,他提出用模型自己两个不同分类器的结果来互相正则(如下图)。
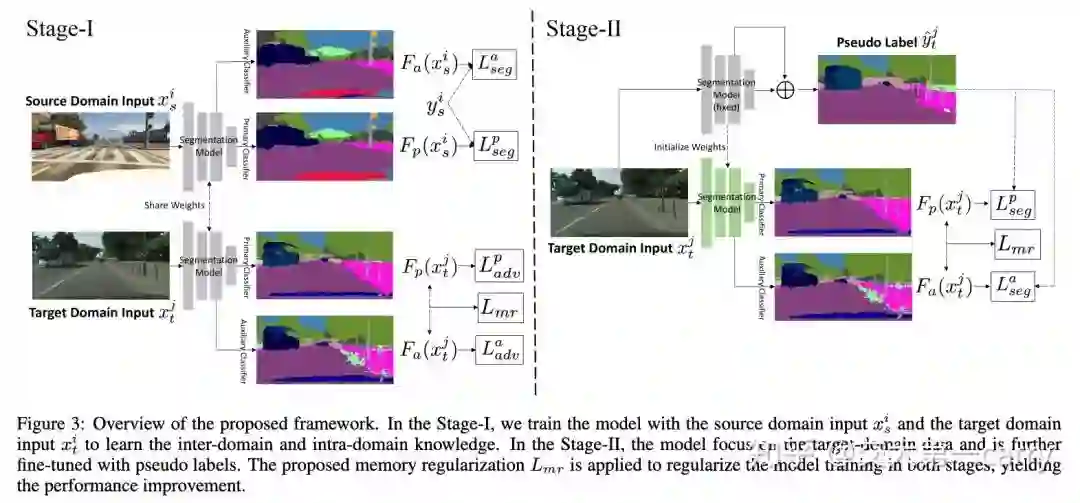
除此之外,这个memory based 正则项可以和之前feature alignment 的方法结合,来做两阶段的训练,进一步提升之前工作的效果。
其中第一阶段采用的是feature alignment结合,利用对抗损失要求特征对齐,挖掘inter-domain的共享的特征;在这个阶段memory regularization 是去挖掘intra-domain的特有特征
而第二阶段则是采用ECCV19zouyang文章中的伪标签,进一步提升结果,在这个阶段memory regularizations则是去防止网络过度拟合到 有noisy的伪标签上
实验
这个方法很简单,不需要额外的参数,加个两个classifier之间的loss就好了。
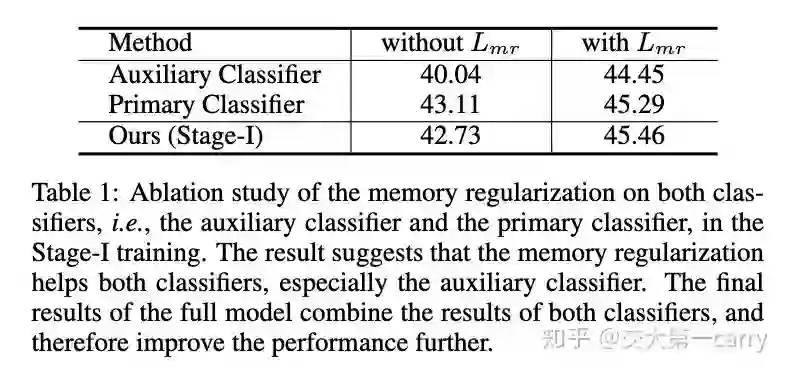
首先,加了regularization后两个分类器的效果都有提升。这个结果和deep mutual learning的结论是相似的,学生模型互相学习也是会有提升的。
这是一个常用的打勾表,逐渐加上不同的损失项,结果慢慢提升。值得注意的是光用memory regularization结果就比光用特征对齐高了!
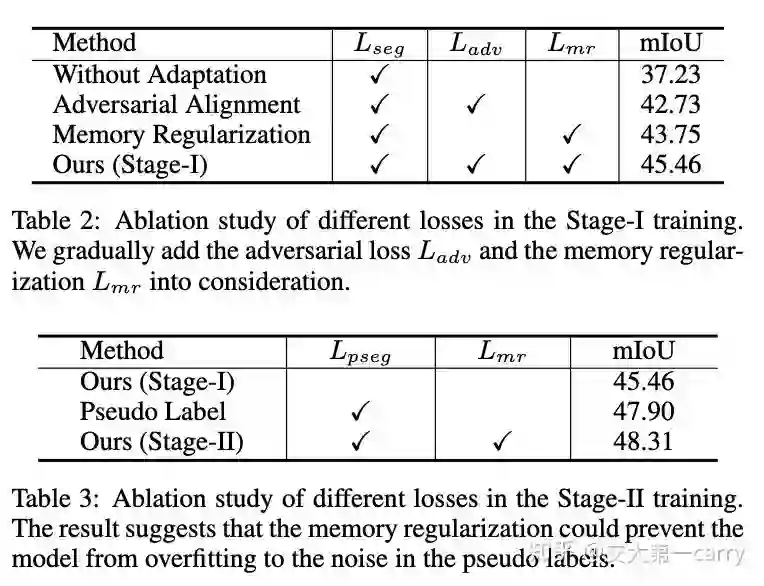
最后的结果
带回家:
本文的方法特别简单,同时效果也不错,在第一阶段确实比feature alignment的方法都高。套了一个memory的概念,本质还是semi-supervised 方法的在域迁移的一次实践。不过,像作者说的一样,反过来看,其实很多方法也都可以划到memory的概念里。所以是谁包含了谁。
参考
1. Yanbei Chen, Xiatian Zhu, and Shaogang Gong. Semi-supervised deep learning with memory. In ECCV, 2018.
2. Ying Zhang, Tao Xiang, Timothy M Hospedales, and Huchuan Lu. Deep mutual learning. In CVPR, 2018
3. Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In NeurlPS, 2017.
4. Yang Zou, Zhiding Yu, Xiaofeng Liu, BVK Kumar, and Jinsong Wang. Confidence regularized self-training. In ICCV, 2019.
重磅!CVer-图像分割交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!




