CVPR 2022|利用属性编辑实现可控、可靠的小样本图像生成

极市导读
由于GAN训练过程不稳定,训练数据有限,生成的图像往往质量低,多样性低。本文提出了一种新的基于编辑的方法,即属性组编辑,在不重新训练GAN的情况下,AGE不仅能够为数据有限的下游视觉应用生成更逼真和多样化的图像,而且还能够实现具有可解释类别无关方向的可控图像编辑。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

Paper Link:https://arxiv.org/abs/2203.08422
Code Link:https://github.com/UniBester/AGE
Motivation
受StyleGAN2启发,一张图片可以被视作是多种不同的属性的集合,而判断一张图片是否属于某一类的方式,就是根据这一张图片类别相关的(Category-relevant)属性,如人脸、形态,而属于同一类的不同图片之间在类别无关(Category-irrelevant)的属性,如表情、姿势。并且GANs在Latent Space中学习这些属性的表示,那么如果朝着某个方向移动Latent Space中的Latent Code,可能导致输出的图片发生语义的改变。理论上来说,对于一个给定的预训练模型,GAN生成新图片的方式就是将学习到的属性给组合起来。而通过编辑类别无关的那些属性,作用在类别相关的属性上,我们是不是可以实现更多样的图像生成呢?另外如果这些类别无关的特征是可以辨识的,那我们就可以实现可控的、更可靠的小样本生成。
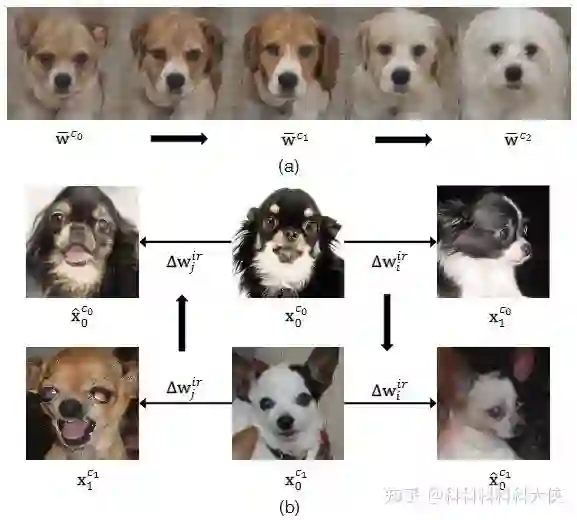
如下图所示,(a)表示对类别相关的属性进行编辑,会导致图片朝着不同的类移动;(b)表示对类别无关的属性进行编辑,可以看出类别并不会发生变化,但是生成图片的毛发、角度、嘴巴发生了很大的改变。基于这样的观察,我们可以通过找到语义无关的属性可能发生变化的方向,对这些方向进行编辑,从而产生不同的图片。首先想到的思路就是通过Inversion将生成图片逆映射为Latent Code,然后对latent Code进行修改,再对比发生的变化后进行人为的属性编辑(可以参考GAN Space),而这样的方式需要很高的代价。那有没有可能实现一种隐式的不需要监督信号的属性编辑呢?本文提出的AGE实现了这一功能。
Preliminaries
在介绍具体的AGE方法之前,我们介绍一下GAN Inversion和语义编辑。
生成网络G学习将一个低维的Latent Code映射为真实图片,那么给定一张图片,我们也可以通过逆映射将其映射回latent space:
那么我们可以通过对得到的 进行修改,使得Latent code 发生变化,那么生成器再获得相同输入时,就可能会得到属性发生变化的生成图片:
对于一个预训练好的多类图像生成网络,我们可以将对图像进行的语义编辑分为类别相关和类别无关的,对于类别相关的编辑:
, 表示类别相关的属性变化方向,编辑后的结果属于另一个类别 。
对于类别无关的编辑:
, 表示类别无关的属性变化方向,编辑后的结果仍然属于同一类别 。
Method
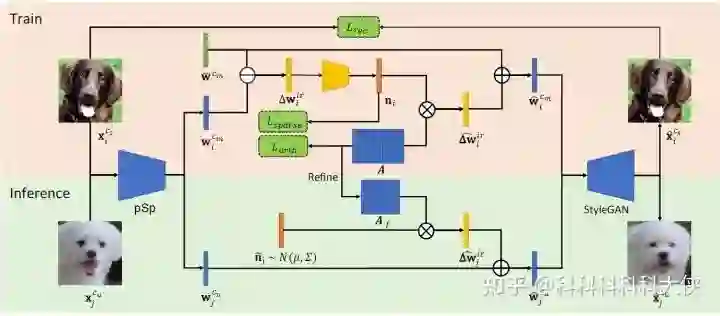
上面介绍了如果对类别相关和无关的属性进行编辑会得到什么样的结果,回到问题本身,我们希望在小样本场景下生成尽可能多样的图片,那么就是需要对类别无关的属性进行编辑,首先,对于给定的图片,文章采用pSp的编码器将图片编码到 空间:
而对于属于同一类的图片来说,所有与类别相关的属性都应该是所有图片共享的,所以所有属性的平均就应该可以表示所有类别相关属性:
,而不同类别的属性保存在一个字典中: 。这样我们将类别无关的属性添加到类别相关属性上,就可以得到编辑后的新的图片:
现在我们的任务在于如何学习找出 ,我们选择一个全局字典 包含所有无关属性变化方向,对于一个样本对应的编辑方向,有:
为一个稀疏表示,我们找到对应的 就可以得到对应编辑方向。在实践中,通过Encoder-Decoder结构进行优化上式,且由MLP学得 :
由于L0损失不可微分,采用L1约束和Sigmoid激活来实现稀疏表示 的约束:
为了进一步的保证 只包括类别无关的属性,编辑得到的图片应该满足编辑前后还是属于同一类,也就是说对于存在一个字典的图片中来说,类别相关的所有表示都包含在编辑后的图片中:
为了保证上式成立,有:
最后的优化目标函数为:
在推理阶段,为了找到最通用的类别无关编辑方向,首先将类别无关变化属性映射为稀疏表示:
,然后计算所有M类的稀疏表示的平均绝对值:
可以解释为整个所有类别都通用的方向。为了实现自动生成,假设稀疏表示符合高斯分布,然后对稀疏表示进行采样,将采样后的表示作用于语义无关属性,生成同类的新图片:
Experiments
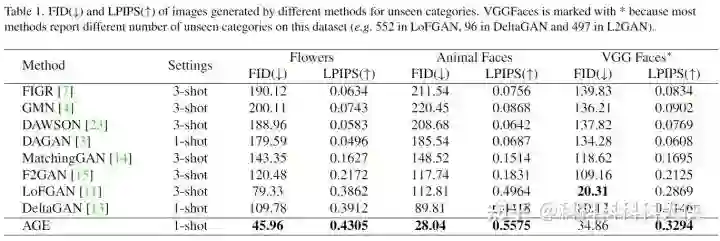
(1)Quantitative Comparison with State-of-the-art
(2)Qualitative Evaluation


(3)Ablation Study on Downstream Task On
下图的准确率表示将Animal Face生成的图片作为增广数据,在Resnet预训练后的模型进行微调得到的准确率,参数 表示编辑程度,可以看出编辑程度越大,多样性越高,但是真实性会越差,在其他实验中都设置为1,作为多样性和真实性的折中。

(4)属性编辑分解



Conclusion
本文从语义编辑的角度出发,通过语义编辑能够实现不同图片生成的方式,将图片表示分为类别相关和类别无关的,并且利用稀疏表示和字典学习来保存并提取类别无关的表示,作用于原始图片上后,能够得到类别不变但是属性发生变化的图片,使得生成任务更具多样性。
这样的思路在逆映射进行语义编辑其实是很常见的,GANSpace通过线性分类来标记图像编辑的方向,周博磊老师CVPR2021的Sefa通过无监督的方式对编辑方向进行PCA估计进行可控编辑,ACE的方法也有异曲同工之妙,不一样的是它将编辑的过程直接放在推理阶段的生成过程,帮助小样本生成模型生成语义编辑后的图片,提升生成数据的多样性。
公众号后台回复“数据集”获取30+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




