自监督3D手部姿态估计方法

极市导读
手部姿态估计任务作为一个对空间信息敏感的下游任务,任何改变空间信息的数据增强操作都会改变手部动作,让人很难想象如何将其套入到自监督学习这种“我的增强结果还是我自己”的instance discrimination模板里,因此我在刷到这篇ICCV论文的第一时间进行了学习。>>加入极市CV技术交流群,走在计算机视觉的最前沿
自MoCo等基于contrastive learning的自监督模型横空出世,在各类下游任务上超越监督训练的模型以来,针对各种任务优化的自监督学习框架层出不穷,算是在ViT到来前学术界的一大研究热点。手部姿态估计任务作为一个对空间信息敏感的下游任务,任何改变空间信息的数据增强操作都会改变手部动作,让人很难想象如何将其套入到自监督学习这种“我的增强结果还是我自己”的instance discrimination模板里,因此我在刷到这篇ICCV论文的第一时间进行了学习。
论文名:Self-Supervised 3D Hand Pose Estimation from monocular RGB via Contrastive Learning(基于单目RGB图片,通过对比学习的方式来做自监督3D手部姿态估计)
论文地址:https://openaccess.thecvf.com/content/ICCV2021/papers/Spurr_Self-Supervised_3D_Hand_Pose_Estimation_From_Monocular_RGB_via_Contrastive_ICCV_2021_paper.pdf
代码地址:https://github.com/dahiyaaneesh/peclr
1. 简介
自监督对比学习
为了照顾到一部分没有相关知识的小伙伴,我先对self-supervised contrastive learning做一个简单的回顾。
首先,自监督学习是无监督学习的一个子类,因此用到的数据是无标签的,而自监督的“自”体现在,虽然没有人工标注告诉我哪些图片是我的同类,但我至少知道我就是我,我经过数据增强变换以后的图片也都是我自己,由于数据增强的结果千变万化,因此一个我也能衍生出千千万万个同类的我,这千千万万个我也就自然具有了相同的标签,所有不是我变换来的,便都跟我不同标签,如此一来,也就给无标签的数据赋予了标签,这就叫自监督。
而对比学习依赖的标签,正是两个对象的标签相同或不相同,如果相同则把两个特征在特征空间中拉近,不同则远离。
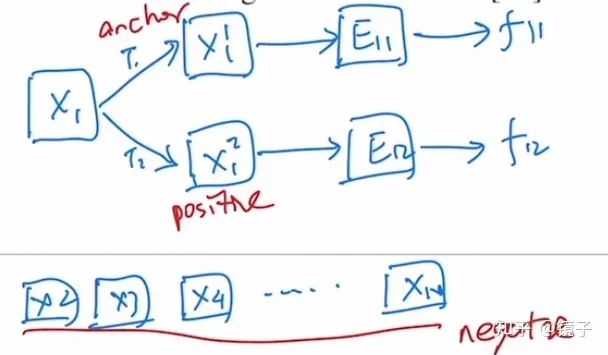
因此在训练中,我们可以任取一张图片作为锚点(anchor),基于它变换得到的同标签样本称为正样本(positive),数据集中剩下的所有样本都视为不同标签,称为负样本(negative)。
以下是一个简单的图例,x代表图片,T代表数据增强变换,E代表模型,f代表特征:
姿态估计任务的独特性质
以往的对比学习自监督任务,都是通过对无标注数据进行数据增强,鼓励模型学习出不随数据增强变换而改变的特征表示,这种性质称为不变性(invariance)。这一点在手部姿态估计任务上显然是不太适用的:一张手部图片只有在经过不涉及几何学的变换时(color jittering),我们才期望模型的表征具有不变性;一旦发生了任何几何学上的变换(rotation, flip, resize),便都会导致关键点位置改变,模型提取的表征也理所应当随之改变,这个时候我们则会期望模型表征具有等变性(equivariance)。
3D手部姿态估计任务难点
相对于已经近似于被解决的2D姿态估计任务而言,3D姿态估计目前还是一个具有挑战性的问题,原因主要在于数据标注的难度,普通的2D标注很容易完成,拍一张照片,然后在普通电脑上由一个稍微经过培训的标注员就能完成。3D标注信息的采集却需要依赖专业的器材,往往都在实验室环境下,这些采集器材的场地、摆放限制又会导致数据背景信息的单一,以及动作姿态的单一,这个问题不论在手部姿态还是人体姿态上都是普遍存在的。这也导致了3D标注数据规模受到相当大的限制,很难通过增大数据量、增加数据多样性等常见数据手段来提升模型性能。
既然监督学习有困难,大家又想了很多弱监督学习的办法,依赖丰富的2D标注数据、形态学先验知识等手段自动生成2D标注,但这些方法都不可避免地存在精度不够高的问题,生成的数据存在大量噪声。
2. PeCLR
为了应对以上姿态估计任务的独特性质,和数据标注面临的问题,本文提出了Pose Equivariant Contrastive Learning(PeCLR)方法,即一个具有等变性的对比学习目标函数,能在不利用任何标注信息的情况下学习到几何变换上的等变性特征,并通过实验证明,具有等变性的对比学习自监督训练,能取得比原来只有不变性的对比学习自监督更好的效果,在FreiHAND数据集上取得了14.5%的提升。
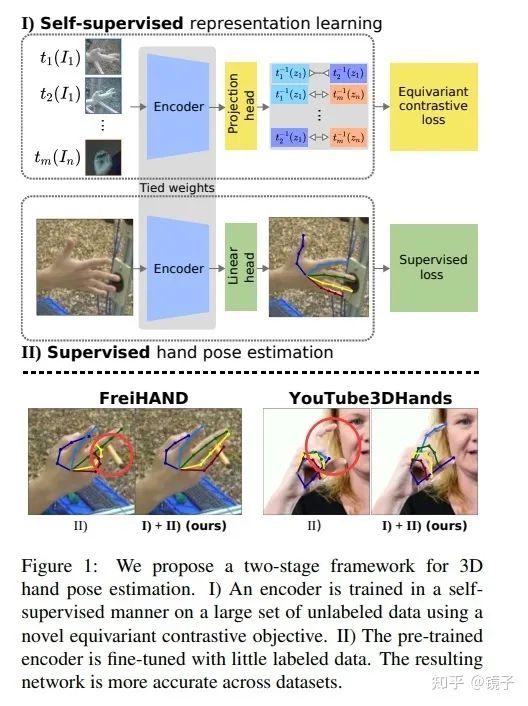
本文的主要贡献有:
-
第一篇高效利用无标注数据来做3D手部姿态估计对比学习的工作 -
提出了一个对比学习目标函数,能对外观变换(appearance transformation)具有不变性(invariance),对几何变换(geometric transformation)具有等变性(equivariance) -
实验探索了该任务上的最佳数据增强方式 -
实验证明了本方法的有效性,更多的无标注数据能带来更多的性能提升 -
用标准ResNet模型达到了SOTA
SimCLR
作为风头最盛的两大自监督对比学习工作,MoCo和SimCLR分别来自Facebook和Google,在MoCov1论文中有指出,自监督对比学习性能提升的关键和限制在于两点,正负样本对的规模大和样本一致性,规模主要受限于GPU显存,让我们一个batch做到1024已经到极限了,样本一致性则是针对利用memory bank来扩充样本对导致的encoder历史版本不一致问题,MoCo正是针对这两点做出了改进使普通人在有限显存情况下也能提升自监督性能。而SimCLR实际上就属于第一类工作,但作为Google的工作,他们表示显存并不是个限制,我们有TPU,batch可以开到8192,所以也不需要MoCo那么麻烦了,Money is all you need。
关于MoCo跟SimCLR的对比部分这里不做过多赘述,有兴趣的同学建议看 https://www.bilibili.com/video/BV1C3411s7t9 这个视频,保证获益匪浅。
简单来说,SimCLR采用了一种end-to-end的模式,将N张图片经过两种不同的数据增强T1和T2,得到2N张增强过的图片,于是对于每个样本I而言,都有1个正样本和2(N-1)个负样本,将这些样本送入encoder提取特征后再经过一个MLP投影到一个向量空间,通过NT-Xent(the Normalized Temperature-scaled Cross Entropy loss),将同类样本在向量空间中互相拉近,不同类样本相互远离。
NT-Xent公式如下:

Equivariant contrastive representations
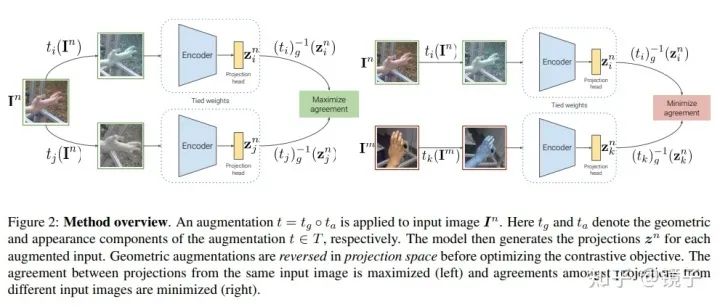
对于NT-Xent而言,这个目标函数会鼓励模型将不同变换得到的样本,提取出相同的表征,具体如下:
即模型从变换前后的样本提取到的特征不变。
然而手部姿态估计要求模型对于几何变换具有等变性,因为几何变换会改变关键点的位置,因此我们的需求变成了:
要满足上面的需求,我们只需要对NT-Xent做一个很小的修改,即:
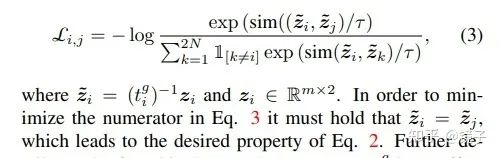
换句话说,我们不再追求两个正样本对提取的特征一样,而是对这两个特征做逆变换,追求逆变换后得到的特征一样。
由于几何变换本质上是一种仿射变换,可以通过矩阵乘法完成,所以逆变换是很容易得到的。
另外需要注意的一个点是,由于图片所在的空间,跟特征所在的向量空间是不同的,而缩放、旋转等变换是与图片尺寸相关的,比如将图片移动x个像素与将特征移动x个单位含义是不同的,因此不能简单地直接把针对图片的逆变换用在特征上,在应用之前还需要根据各自的大小计算比例,进行等比例的变换:
如果理解了上面的内容,剩下的工作就都是顺其自然了,通过自监督对模型进行预训练后,用少量标注数据对模型进行微调即可。模型的结构上本文遵循了SimCLR的做法,在encoder的输出上接了一个线性层做投影。
总结一下:
由于新的目标函数,只比旧的多了一步操作,即对特征向量进行逆变换。因此我们只需要对经过了几何变换的样本特征做逆变换,其他的正常进行自监督学习即可。
3D Hand Pose Estimator
3D姿态估计的部分就不是本文的重点了,本文的设计也非常简单,通过L1 loss来分别监督2D坐标和深度。
3. 实验
实验部分,用ResNet50作为encoder,输入图片为128x128的单目RGB图片。
预训练阶段用LARS和ADAM,batch size取2048,学习率为4.5e-3。微调阶段用ADAM,学习率为5e-4。
由于自监督学习的数据增强选择会很大程度上影响模型性能,本文也从单个变换到多个变换组合递进的方式,探索了适合于手部姿态估计任务的数据增强集合。如下图所示,绿字为外观变化,蓝字为几何变换:

单个变换
本文首先在手部姿态数据上验证了SimCLR使用单个变换的表现,对预训练好的模型使用两层MLP进行全监督微调:
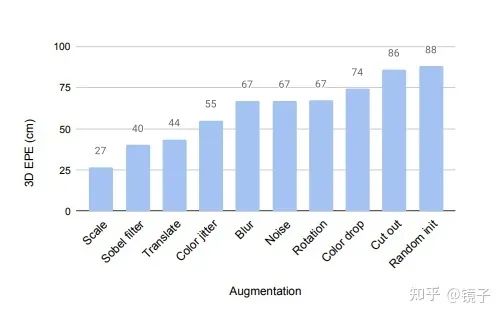
可以看到,尽管SimCLR不那么适用于姿态估计任务,但经过了自监督预训练的模型表现,仍然是超过随机初始化后进行监督训练的表现的。并且我们可以观察到scale变换带来的收益依然是非常大。
接下来又对比了PeCLR跟SimCLR在几何变换上的表现,由于相似度计算采用的是余弦相似度,消除了scale的影响,因此只对比了translate和rotate:

可以看到PeCLR的确在几何变换上大幅超越了SimCLR,而外观变换的模型,由于两种方法目标函数完全一样,模型结果也是一致的。
多个变换
为了压缩搜索空间,本文只取了单独效果最好的4个变换进行组合,结论如下:
对PeCLR,scale+rotation+translation+color jittering的组合表现最好。
对SimCLR,scale+color jittering的组合表现最好。
半监督学习
这个部分实验了只使用一部分数据进行监督学习,以及在更大规模的数据上进行自监督预训练得到的模型表现:
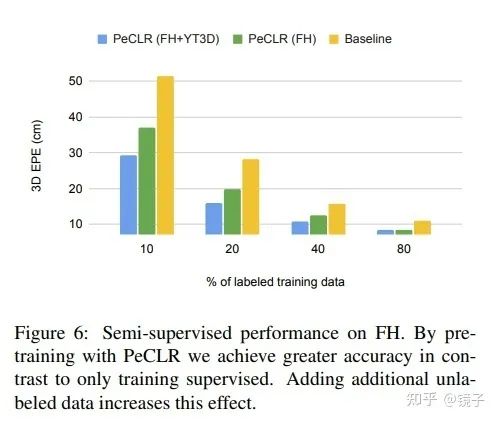
更多的标注、更多的自监督数据量,都带来了更好的性能。
结果对比
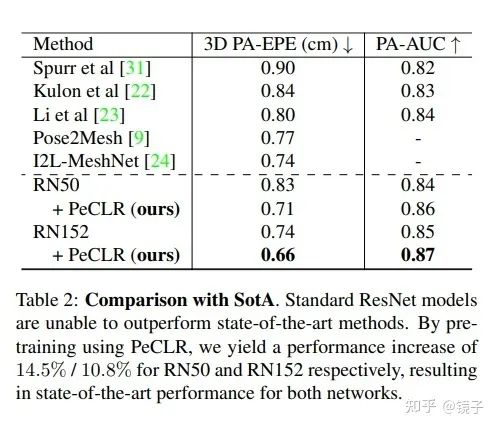
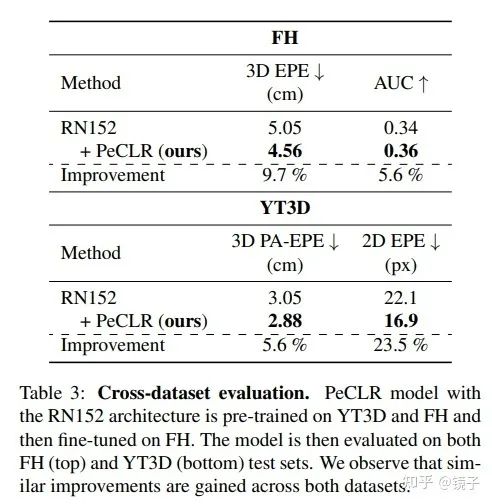
最后与过往SOTA进行了对比,其中包括去年CVPR2020的Oral。
也验证了在FredHAND+Youtube3D数据上自监督预训练,再在FreiHAND上微调的模型,跨数据集的泛化能力。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



