CFGAN:基于生成对抗网络的协同过滤框架

“ 本文介绍了一种生成对抗网络在推荐领域的应用CFGAN的原理以及潜在问题和解决方案,并给出了代码实现和在公开数据集的运行样例。”
作者介绍:张旭鑫,华中科技大学硕士在读,主要研究数据攻防与推荐系统,ARASC社区成员。联系邮箱:xuxinz@hust.edu.cn。
前言
使用生成对抗网络来做推荐最近几年愈演愈烈,上个月的一篇综述
《Adversarial Machine Learning in Recommender Systems: State of the art and Challenges》详细概括了推荐系统领域中的对抗性机器学习,值得一读!附上论文链接:https://arxiv.org/pdf/2005.10322.pdf
CFGAN是发表在CIKM2018上的一篇文章,题目为《CFGAN: A Generic Collaborative Filtering Framework based on Generative Adversarial Networks》(https://dl.acm.org/doi/pdf/10.1145/3269206.3271743)
在它之前GAN在推荐上的应用主要有IRGAN和GraghGAN,下面简单介绍一下IRGAN的主要思想。
IRGAN主要思想
考虑我们有一些序列query(IRGAN应用在推荐系统中的时候query是代表user profiles),document是一些和query相关的文档(在推荐系统中document是information items)。query和document之间的相关性用r来表示。我们用条件概率分布 来表示真实的序列和文档之间的潜在概率分布,给定从训练数据中观察得到的条件概率分布 ,从而设计出IRGAN包含的两个模型:
-
生成式检索模型:该模型的目标是学习 ,想要从给定的序列q来生成或者选择相关的d,使其分布接近于 。 -
判别式检索模型:该模型的目标是学习fΦ(q,d),试图从不匹配的query-document对(q,d)中识别良好匹配的(q,d)。
接着参考GAN的思想,将上述两种模型结合起来做一个最大最小化的博弈,生成器试图生成和真实分布类似的,和序列高度相关的文档,从而“骗过”判别器;而判别器的任务则是尽可能准确地分辨真实的文档以及生成器生成的文档,在不断的博弈中迭代模型,最后达到训练的目的。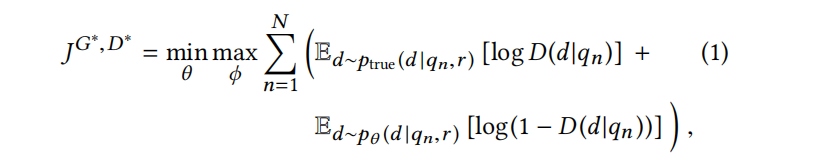
Discrete item index generation存在的问题
IRGAN的问题在于训练过程中,生成器会慢慢学到真实的概率分布(下图 a-b的过程),从而生成和真实情况相同的项目ID,但是这会让判别器“感到困惑”,比如下图中的i3,既出现在“real”中,被标记为真实数据,又出现在“fake”中,被标记为生成的数据。
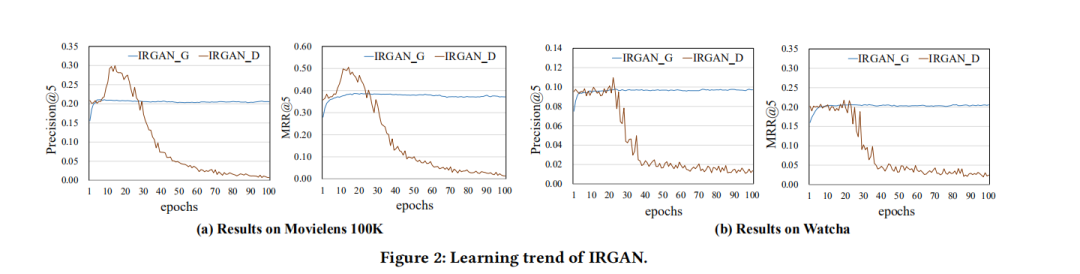
本质上来说,IRGAN存在的问题是其生成的是离散的项目,CFGAN考虑到这一问题后,调整G网络的生成为用户的评分向量,取值范围为0~1,对于离散的项目来说容易出现重合的情况,但是对于连续的评分向量而言,重合的概率就可以忽略不计了(评分向量维度较高时)。
CFGAN
我们来看看CFGAN的结构:
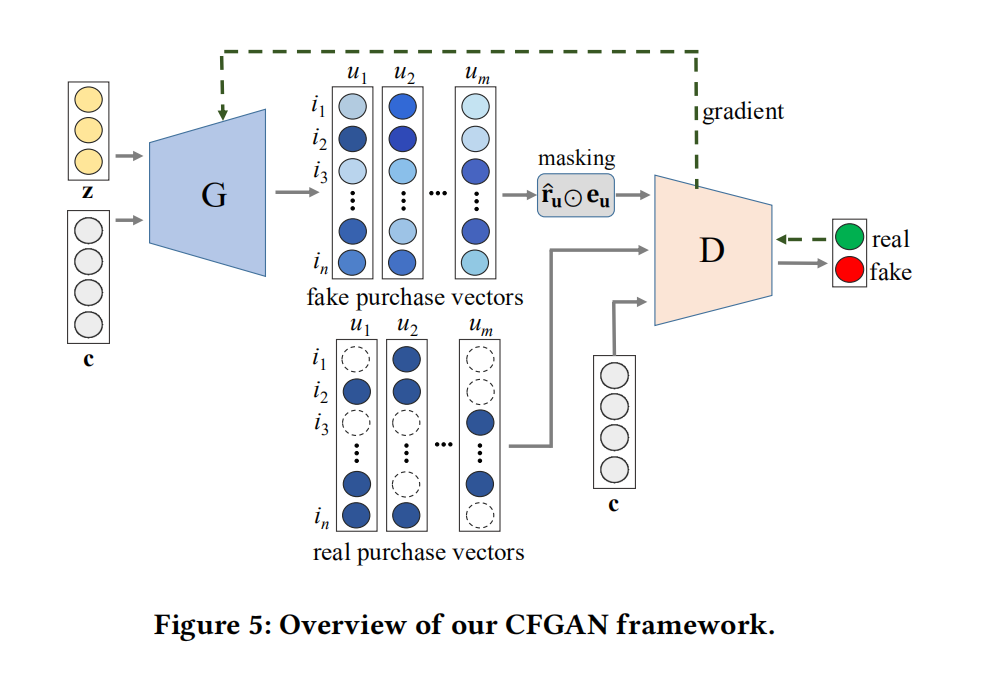
生成器G网络结构
首先我们关注生成器网络的设计:原文中提到,生成器G的输入中,c是描述用户的信息,诸如年龄等,但是原文中是使用一个用户的购买向量作为该用户的描述信息c:_In our methods, we use auser’s (or, an item’s) purchase vector to specify a user (or, an item).[1]_z在传统的GAN网络中应该是代表噪声,但是原文提到他参考了IRGAN和GraphGAN的做法,用用户的购买向量作为z了。_In addition, as in the other GAN-based CFs , we do not usethe random noise variable z since our goal is to generate a single,most plausible recommendation result to a target user rather thanmultiple outcomes.[1]_c和z经过生成器网络后,输出生成的用户购买向量,向量中的值代表的是该用户购买物品的概率。值得一提的是,生成的购买向量在放入生成器网络前,经过了masking的操作,原文的说明是为了让生成的向量和真实向量一样具有稀疏性,通过这样的操作,也就使得网络在训练的过程中 ,只会考虑在真实的购买项目上的生成的值。
class generator(nn.Module):
def __init__(self,itemCount,info_shape):
self.itemCount = itemCount
super(generator,self).__init__()
self.gen=nn.Sequential(
nn.Linear(self.itemCount+info_shape, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512,1024),
nn.ReLU(True),
nn.Linear(1024, itemCount),
nn.Sigmoid()
)
def forward(self,noise,useInfo):
G_input = torch.cat([noise, useInfo], 1)
result=self.gen(G_input)
return result
给出生成器G的目标函数: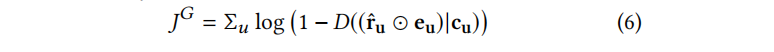
class discriminator(nn.Module):
def __init__(self,itemCount,info_shape):
super(discriminator,self).__init__()
self.dis=nn.Sequential(
nn.Linear(itemCount+info_shape,1024),
nn.ReLU(True),
nn.Linear(1024,128),
nn.ReLU(True),
nn.Linear(128,16),
nn.ReLU(True),
nn.Linear(16,1),
nn.Sigmoid()
)
def forward(self,data,condition):
data_c = torch.cat((data,condition),1)
result=self.dis( data_c )
return result
判别器D网络结构
给出判别器D的目标函数:
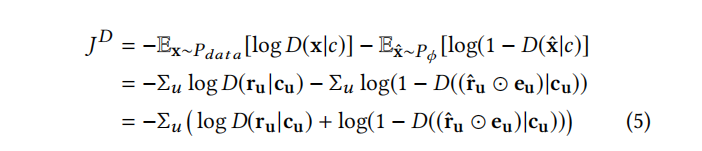
潜在问题
上面的网络设计是不是已经没有什么问题了呢?答案是否定的。
事实上,生成器大可以生成全部为1的向量,然后通过masking操作之后会让判别器无法进行判别,因为这时候的生成向量代表用户在这些项目上以概率为1产生交互,这和实际是相符合的呀,所以判别器又陷入了两难的境地。
让生成器产生全部为1的向量明显是没有意义的,如何解决这一问题?原文中 给出了以下步骤。
在每一次迭代过程中,随机选择一定比例的用户未购买的项目,假定他们是负样本项目,也就是说用户不想购买它们,或者说是给了评分,但是评分是0,而不是缺失值。接着,训练生成器网络G在这些负样本项目上的生成值接近于0。这样的话,就可以避免G产生全是1的输出了。
解决方案
围绕这一解决的步骤,论文又给出了三种解决方案,分别是CFGAN_ZR,CFGAN_PM,以及CFGAN_ZP。其中CFGAN_ZP是前两种方案的混合,因此,我们接下来仔细讲解CFGAN_ZR以及CFGAN_PM方案的细节,再给出CFGAN_ZP方案。
-
CFGAN_ZR:通过负采样得到一定比例的负样本项目,然后加入针对这些项目的正则项,希望这些负样本上的预测值接近于0,从而避免生成全1的向量。此时,生成器G的目标函数变为如下形式:
α是一个用来调节负样本项目的重要性的参数。
-
CFGAN_PM:这一方案的改动在于生成器网络生成向量之后的masking操作,这时,我们不仅仅考虑真实的购买项目上的生成值,同样还要考虑一些随机的负样本项目上的生成值。此时的生成器和判别器的目标函数:
和之前的公式对比,明显看到多了一个n维的指示向量k,k中属于负样本项目的对应值为1,其他为0。
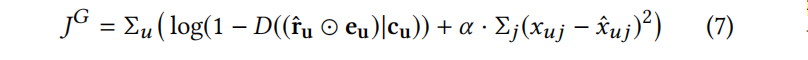 α是一个用来调节负样本项目的重要性的参数。
α是一个用来调节负样本项目的重要性的参数。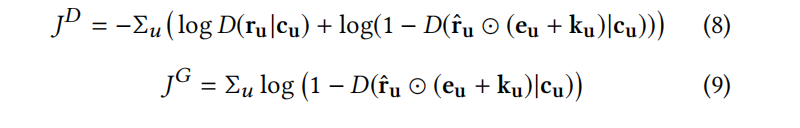 和之前的公式对比,明显看到多了一个n维的指示向量k,k中属于负样本项目的对应值为1,其他为0。
和之前的公式对比,明显看到多了一个n维的指示向量k,k中属于负样本项目的对应值为1,其他为0。d_loss = -np.mean(np.log(realData_result.detach().numpy()+10e-5) +
np.log(1. - fakeData_result.detach().numpy()+10e-5))
-
CFGAN_ZP:综合以上两种方案,最后得到的生成器的目标函数如下:!
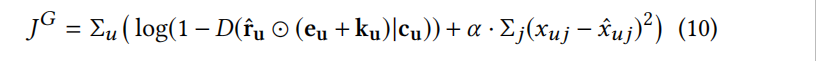
g_loss = np.mean(np.log(1.-fakeData_result.detach().numpy()+10e-5)) + alpha*regularization(fakeData_ZP,realData_zp)
判别器的目标函数和CFGAN_PM方案中的一致。
超参数和原文保持一致,训练次数为1000,训练数据集为Movielens 100K,最后结果P@5 最大为0.49。运行截图:
结果显示:
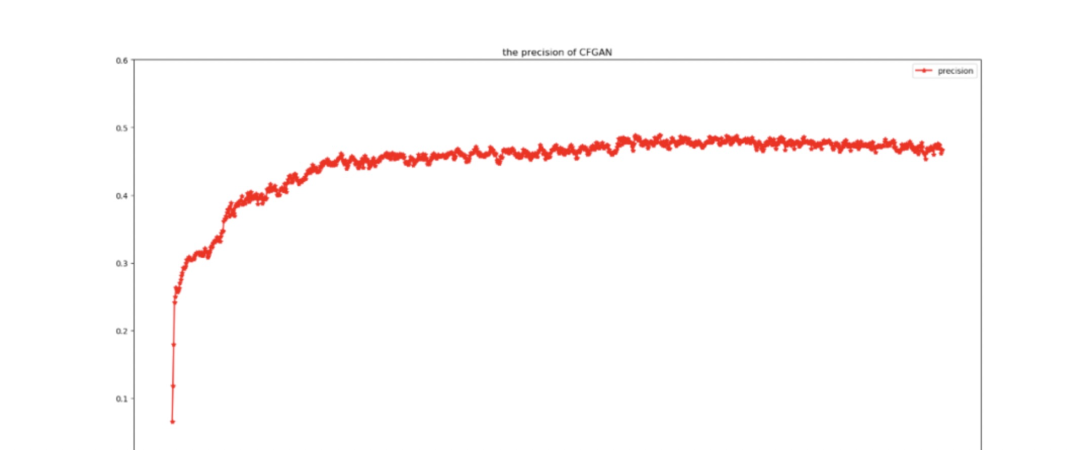
-
完整代码已收录至ARASC社区,https://github.com/ARASC/CFGAN,点击文末【阅读原文】即可访问 -
公众号后台回复【CFGAN】即可下载论文
推荐阅读
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇



