机器学习中的隐私保护


分享嘉宾:郭夏玮 第四范式 资深研究员
编辑整理:蒋瑞尧
内容来源:第四范式 | 先荐
出品平台:DataFun
注:转载请在后台留言“转载”。
导读:近年来,随着 GDPR 通用数据保护条例出台以及一些互联网公司数据隐私泄漏等事件的发生,数据隐私的保护问题在行业应用中备受关注。与数据密切相关的机器学习算法的安全性成为一个巨大挑战。本文将介绍在机器学习领域中数据隐私安全的相关工作,并介绍第四范式在差分隐私算法效果提升上所做的工作。
主要和大家分享数据隐私的3方面:
隐私保护的问题与案例
基于数据的隐私保护技术:数据匿名化
机器学习模型训练中的隐私保护技术:差分隐私
▌机器学习中的隐私保护问题
1. 信息隐私
信息隐私 ( Privacy ):指的是当一个组织内敏感数据被拥有权限的人员所使用于某些技术、过程 ( 如数据分析、训练模型 ) 时,对数据敏感信息进行保护的过程与规则。
数据的隐私 ( Privacy ) 与安全 ( Security ) 并不等价:有的时候很多人提到数据隐私时,会与数据安全混为一谈,但其实两者并不等价。数据安全通常指防止数据被非法访问;而数据隐私则一般指在数据被合法访问时,防止其中的敏感信息被访问者以某些方式"逆向"获取,避免因数据被"逆向"推导出而造成的敏感信息泄露和滥用。当然,对于企业来说,数据隐私和数据安全都非常重要。
2. 信息隐私问题
如今,在很多需要用到私人敏感数据的领域中,都存在数据隐私的问题。特别地,当机器学习技术应用在一些个人隐私数据上时,可能会暴露敏感数据,对个人造成很多负面影响。
虽然现实生活中有很多数据隐私的问题,但严格意义上,个人隐私不可能被绝对保护。
1977年,统计学家 Tore Dalenius 给出关于数据隐私的严格定义:攻击者不能从隐私数据里获取任何在没有拿到数据之前他们所不知道的个人信息。
2006年,计算机学者 Cynthia Dwork 证明上述定义的隐私保护是不存在的。有一个直观例子可以帮助理解:假设攻击者知道 Alice 的身高比 Lithuanian 女性平均身高高2英寸,这样攻击者只需要从一个数据集里获得 Lithuanian 女性身高平均值 ( 在接触数据前攻击者并不知道 ),就能准确获得 Alice 的精确身高,甚至 Alice 都不需要在这个数据集里。因此,对于一份有信息量的数据,不可能完全不暴露隐私信息。
3. 隐私泄露的危害
隐私泄露的危害,主要有:
隐私信息被应用于欺诈与骚扰:如盗刷信用卡、电话诈骗、冒用身份等
用户安全受到威胁:用户信息受到泄露,引起更多有目的犯罪
非法机构利用用户隐私信息操控用户
用户信任危机
违背相关法律
不过一般来说,对于不特别极端的情况,我们仍可以从很大程度上来保证数据在机器学习过程中不被泄露。
这里再分享一个隐私泄露的案例:
1997年,马萨诸塞州 GIC 对外公布了一组医疗数据,其中包括病人的5位邮编、性别、生日。州长 Weld 对公众保证这份数据是匿名的,因为标识特征 ( 如名字地址 ) 已经被移除。结果一位 MIT 毕业生通过结合这份数据与她花了20美元购买的选民登记数据,找到了 Weld 的医疗记录。同时,她还宣布87%的美国公民可以通过5位邮编、性别、生日进行唯一标识。
这个真实案例印证了:任何有一定信息量的数据都有可能产生隐私泄露;单纯的数据匿名方法是很难保护隐私的。接下来,我们来看一下,针对潜在的隐私泄露问题我们有哪些技术可以在很大程度上杜绝隐私的泄露。
▌数据匿名化技术 ( Data Anonymization )
数据匿名化是一个从数据层面上进行隐私保护的技术。匿名化很多时候是通过 hash 掉"姓名"等关键标识符来实现的。而在只简单 hash 掉姓名的情况下,数据访问者有很多方法通过利用其它特征的信息来反推出某人在数据表中对应的那一条数据。这时候,就需要一种技术来防止访问者能够通过结合多个特征的数据来确定人与数据间的对应关系。
1. 数据表中数据列的类别 ( 按所含隐私量分类 )
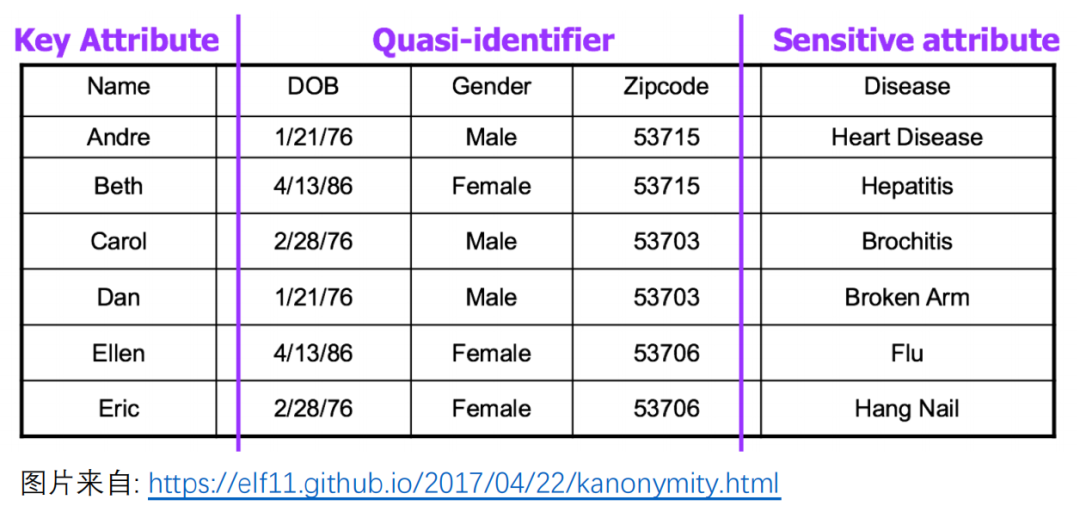
标识列 ( Key Attribute,简称 KA ):单凭其一列便能直接锁定某人的数据列,如:身份证号、姓名 ( 大多数情况下 );
半标识列 ( Quasi-identifier,简称 QID ):无法单凭其一列确定对象,但通过结合多列数据或查其它信息 ( 缩小范围 ) 可以对应到个人的数据列,如:生日、邮编等;
敏感信息列 ( Sensitive Attribute,简称 SA ):如疾病、收入等。
虽然只有标识列的数据能够直接缩小范围到单个样本,但如前文所述,仅匿名化标识列数据对于隐私保护是完全不够的。
2. 攻击方法与防护方法
① 链接攻击
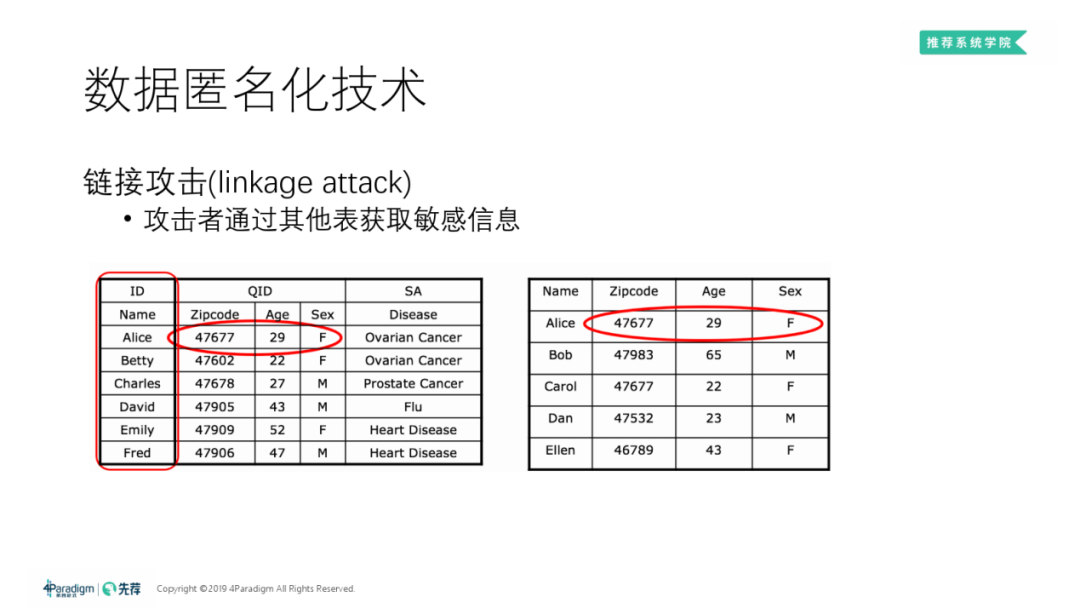
链接攻击 ( Linkage Attack ):通过获取其它渠道的信息 ( 如右表 ) 来锁定 ( 见左表 ) 当前数据表中数据所对应的个人。
② K-Anonymity
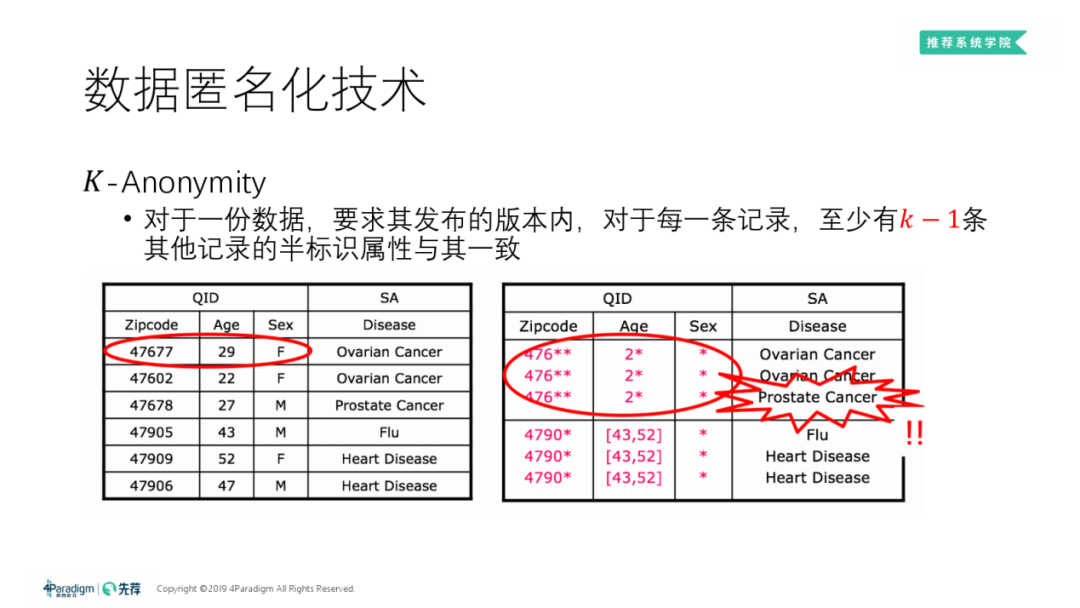
K-匿名 ( K-Anonymity ):针对链接攻击的防护方法。对于每一份数据的各版本内的每一条记录,规定至少有 K-1 条其它记录的半标识属性与其一致。
上方右表就是对上方左表做"3-匿名"之后的结果:我们可以发现,在统一对"zipcode"、"age"、"sex"三列的数据的末尾作模糊 ( 相当于匿名化 ) 处理后,含有"zipcode:47677**,age:2*,sex:*"的信息的数据共有3条 ( 这3条记录中的任一条,均满足至少有3-1=2条其它记录的半标识属性与其一致 );左表原数据中的另外3条经变换后也满足3-匿名的条件。
左表在 K-Anonymity 之后,虽然数据会有所损失,但保证了每条数据中的敏感信息无法与个人一一对应,降低了隐私泄露的风险。如何在尽可能小的数据损失的情况下做 K-Anonymity 也是一个数据隐私的研究方向。
③ Homogeneity attack
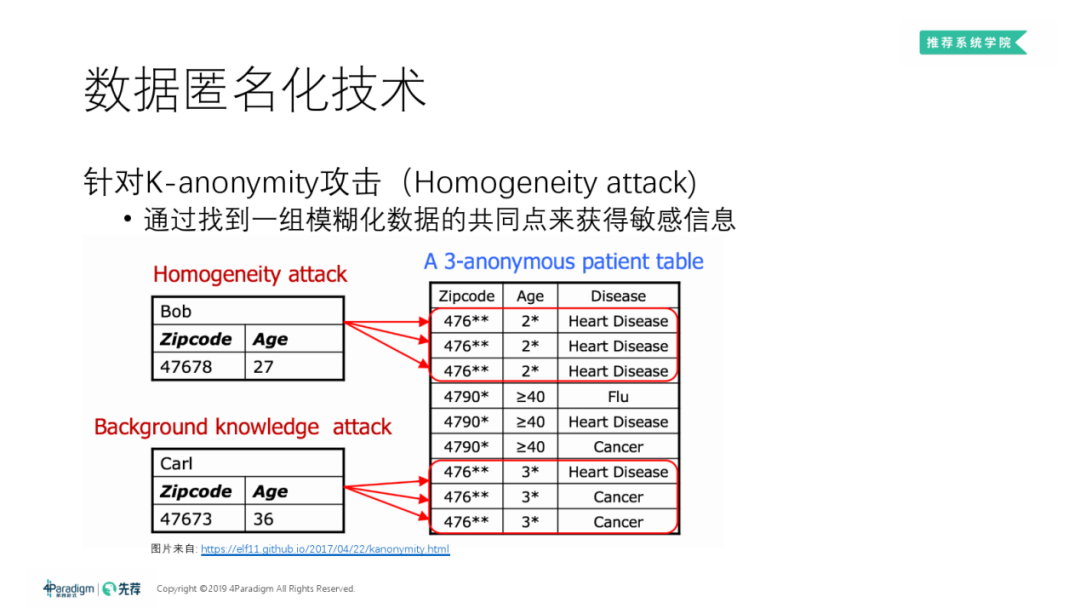
同质化攻击 ( Homogeneity Attack ):可克制 K-Anonymity 防护的攻击。某些情况下,可通过直接对比其它列信息或查找其它外部资料发现,K-Anonymity 中半标识列均相同的 ( 至多 ) K 条数据的其他列的信息其实是同质的,因而确定下来某人的隐私数据。
上方右表说明:经对比可发现 Bob 必然患有 Heart Disease;而假如能够另通过查资料发现 Carl 所在地人们普遍患有 Heart Disease,就还可以推断出 Carl 大概率是患 Heart Disease 的那例样本。
④ L-Diversity
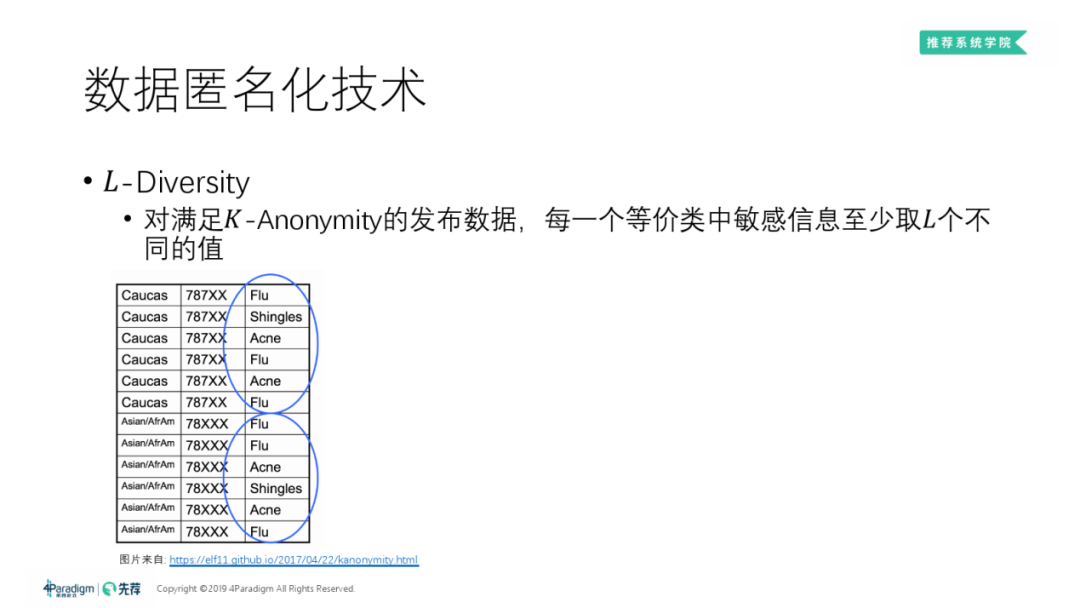
L-散度 ( L-Diversity ):对 K-Anonymity 的改进。在满足 K-Anonymity 的基础上,要求所有等价类 ( 即各半标识列信息均相同的一些样本 ) 中的敏感信息 ( 如:病史中的 Heart Disease、Flu ) 的种类/取值至少有 L 种。上表就是一个满足3-散度的数据。
⑤ 相似性攻击

相似性攻击 ( Similarity Attack ):可对满足 L-Diversity 的数据进行攻击。从外界获取个人多方面的背景信息,缩小范围以锁定目标。
⑥ T-Closeness

T-保密 ( T-Closeness ):对 L-Diversity 的拓展。对于满足 K-Anonymity 的数据,规定每一个等价类中的敏感信息的分布与数据集整体的敏感信息分布的距离 ( 可自行定义,常见的有:K-L 散度 ) 小于 T。
▌差分隐私 ( Differential Privacy ) 技术
除了数据匿名化不当以外,由数据和特定建模方法得到的模型同样有隐私泄露的风险 ( 被攻击获取到原数据中的隐私信息甚至原数据本身 )。差分隐私在机器学习模型的建模过程中应用较广。
1. 模型的隐私保护风险
未经过隐私保护处理的机器学习模型理论上可能暴露训练数据里的敏感信息。
Membership inference attack:
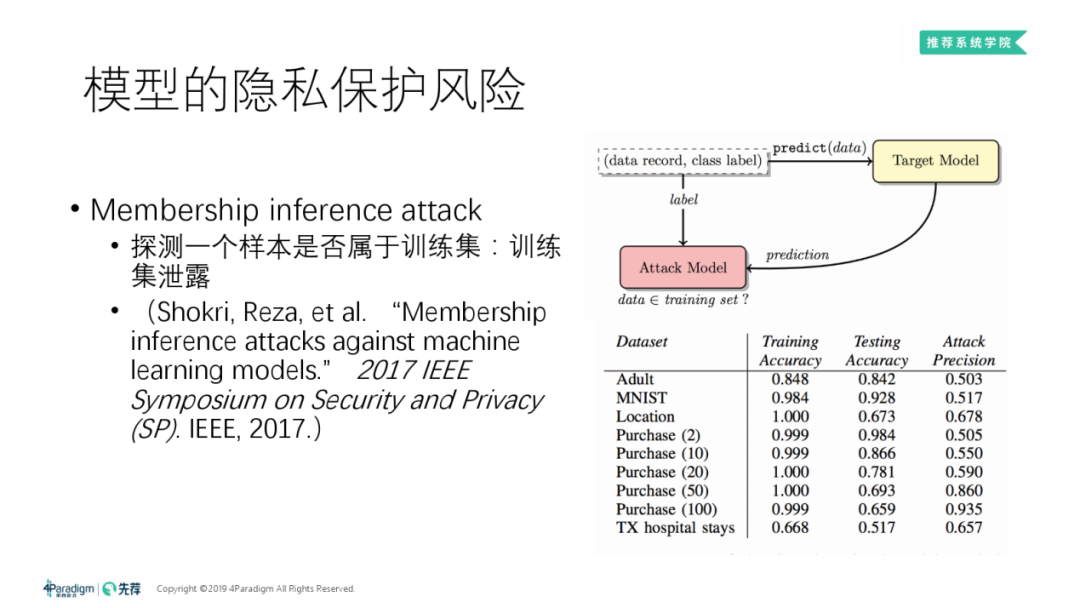
成员推断攻击 ( Membership Inference Attack ):探测一个给定样本是否属于训练某"待破解"模型 ( target model ) 的原数据集。
步骤 ( 参考论文见上图 ):
① 模拟生成和训练 target model 的原数据集分布类似的一系列数据集 ( 即shadow datasets ),用与训练 target model 相同的训练算法 ( 训练算法是什么很容易得知 ) 去训练出对应的一系列的模型,这些模型称为 "shadow models",这些 shadow models 和 target model 的特征分布是很像的;
② Attack Model 的训练。数据集构成:对于每一个 shadow datasets 中每一条数据,可以构建此条数据在某个 shadow model 上的预测结果、该数据真实 label 作为训练样本,将此条数据是否属于之该 shadow model 作为标签。通过构建的数据集再即可训练 Attack Model,能够判断任意一条给定的数据是否属于原数据集;
③ 对于一条数据,对于该数据 target model 的预测结果和真实 label 作为输入,通过判断模型就可以判断出该数据是否属于 target dataset 的。
右图为上述思路的一例实际应用,可以看出如果对训练模型的方法不加处理的话,原数据集被成员推断攻击法破解的程度还是很高的。
Model Inversion Attack:

模型逆向攻击 ( model inversion attack ):是指攻击者通过模型与某个样本的其他特征,直接推断某个敏感特征值。
2. 差分隐私技术 ( Differential Privacy )
如果对于任两个只相差1个样本的数据集 D1、D2,在通过过程 M 建模后,产生的模型与给定模型t完全相同的概率之比不大于 eε ( 其中 ε 为某非负数,为隐私预算 ),那么我们说建模过程 M 是 ε-差分隐私的。
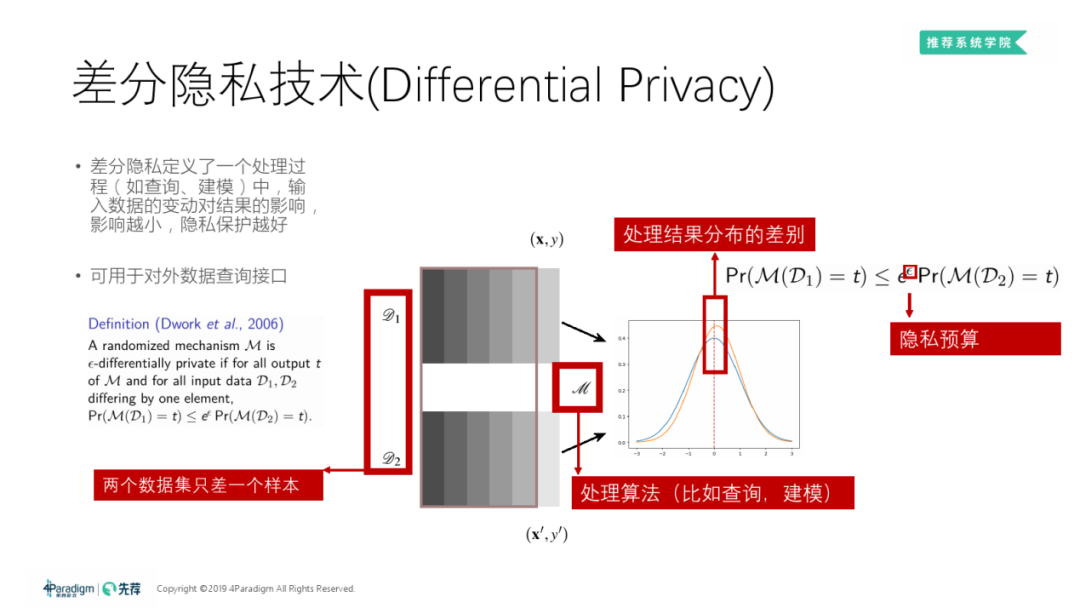
理解:如果建模过程 M 是 ε-差分隐私的,且 ε 很小,那么数据集和其训练出来的模型关系很小,即两个相差有固定上限的数据集训练出来的模型是几乎一样的,所以拿到模型的访问者即便知道大致的数据分布也并不能推断出原数据集;反之,如果 ε 很大,那么两个相差有固定上限的数据集训练出来的模型可能天差地别的,那么这种情况下,原数据集与得出的模型间一一对应的比例很高,知道训练出来的模型就很有可能能够通过模型的分布倒推出原数据集。也就是说,如果改变一条的数据对最终得到的模型影响很小,那么数据集隐私暴露的风险就很小,反之则很大。
① 差分隐私下的模型训练

对目标函数添加一定的噪声:训练出来的模型会带有一定的随机性,可证明这样的随机性可满足差分隐私。
在梯度上加噪声:深度学习比较常用,因为对于深度学习模型,如果把噪声加在目标函数或输出上,差分隐私的分析会很复杂。
在模型输出上加噪声:使得不一样的原数据集输出的模型差异变小。

不过,作为代价,数据隐私保护得越好,算法的性能下降得越多。在训练样本复杂度相同的情况下,隐私保护越好 ( ε 越小 ),泛化误差越大。
② 基于特征切分的差分隐私算法
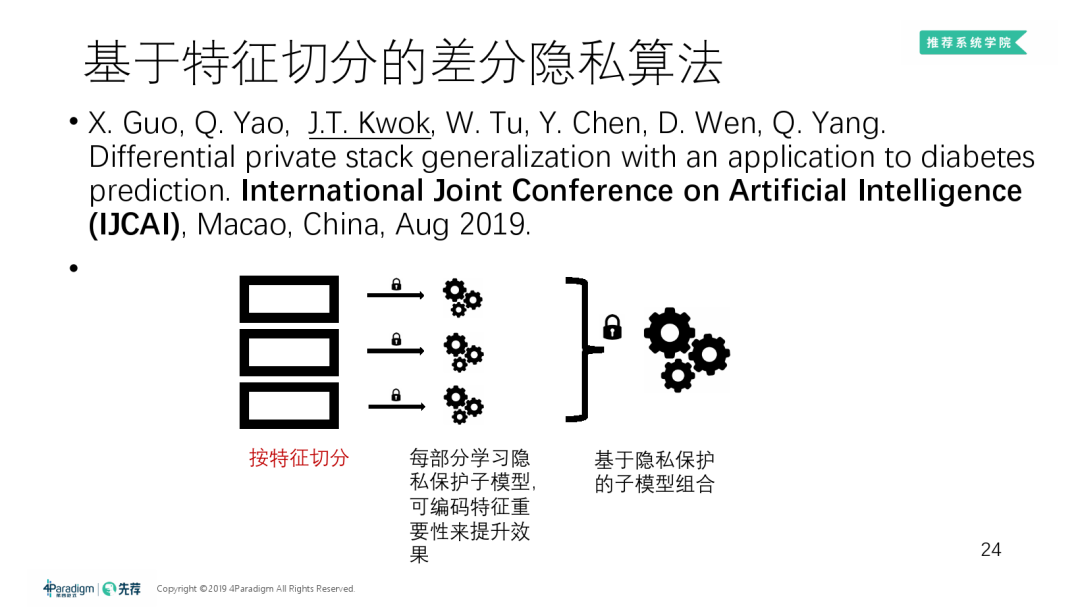
按特征来切分做差分隐私,而非做基于样本切分的差分隐私:
数据先按样本切分为上下2份,其中一份按特征切成 K 份去学 K 个子模型,这些子模型再在剩下的一半样本上用预测值去融合出新的 ( 第二层的 ) K 个子模型,其中切分和融合都是用差分隐私去做的。可证明最后总的输出是满足差分隐私的。
按特征切分的原因:

仅保证差分隐私是不够的,还需保证算法的性能。由上图公式可发现,给重要的特征分配更多隐私预算,训练样本复杂度会减小,训练出的子模型效果会更好。
③ 在迁移学习中的应用
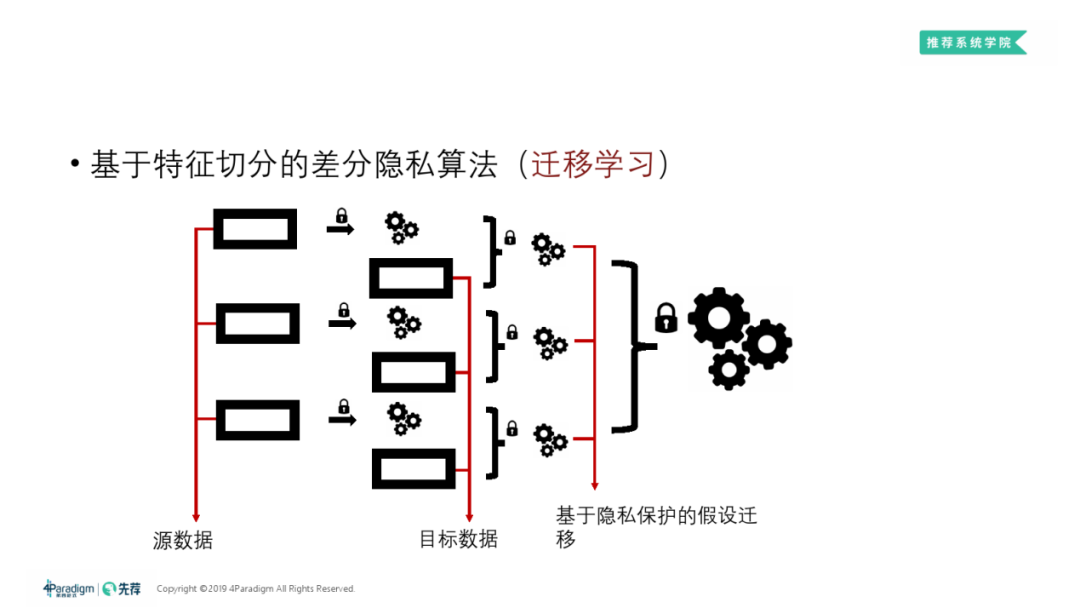
按②中所述方法做特征切分,在假设迁移部分对子模型做差分隐私保护,最后做含差分隐私的融合。
今天的分享就到这里,谢谢大家。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
社群推荐:
欢迎加入 DataFunTalk 技术交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信(微信号:DataFunTalker),回复:交流群,逃课儿会自动拉你进群。


郭夏玮
第四范式 | 资深研究员
研究方向主要为自动化机器学习、隐私保护下的机器学习等。相关研究成果发表在AAAI/IJCAI等会议上。他的团队建立了公司内自动机器学习的Benchmark平台,研发了端到端自动化机器学习产品。他也是一系列国际自动机器学习比赛的负责人。
关于我们:

一个在看,一段时光!👇



