从Facebook、百度“隐私门”看企业对用户隐私保护的责任何在

今年3月末,Facebook陷入了隐私之争。一家数据分析公司剑桥分析被曝料通过Facebook收集用户偏好信息,然后利用这些用户喜好有针对性地推送广告,最终达成的目标是影响2016年美国大选。
事件被曝光后,Facebook的用户们感到愤愤不平,在社交网络上甚至引发了一场#DeleteFacebook的运动,呼吁大家删除facebook账号。运动也受到了大量名人的响应,包括埃隆·马斯克、花花公子纷纷删除了自己的Facebook主页。
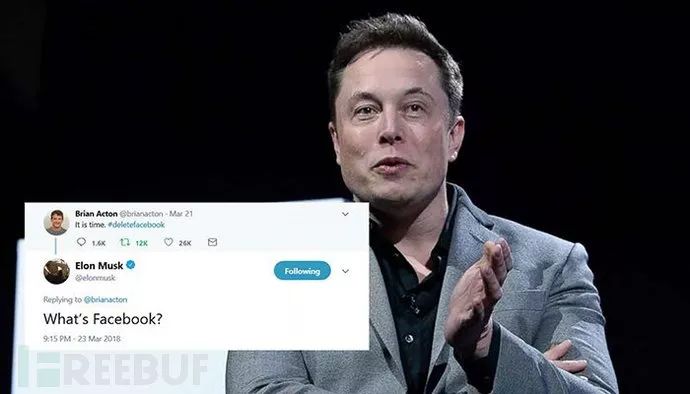
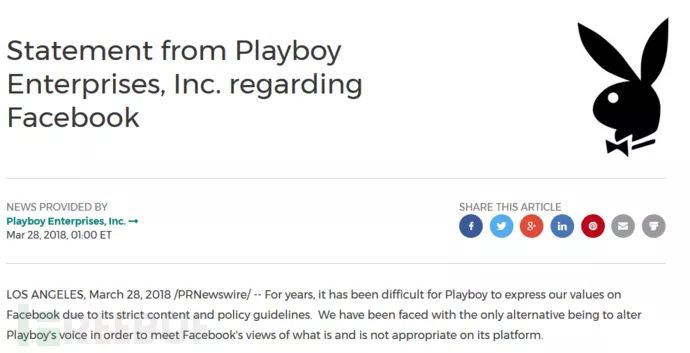
花花公子宣布删除Facebook官方主页,称价值观不同
最近的一份调查还显示,三分之一的美国科技公司雇员准备删除Facebook。
正当Facebook被接连不断的丑闻弄得焦头烂额时,中国厂商百度挺身而出,与扎克伯格在各大媒体公开道歉形成巨大反差的是百度对隐私的态度。
自愿还是无奈?
在3月26日的中国高层发展论坛上,百度CEO李彦宏表示:“中国人更加开放,或者说对于隐私问题没有那么敏感,如果说他们愿意用隐私来交换便捷性或者效率,很多情况下他们是愿意这么做的。”此番言论一出,立即遭到炮轰。

国内外互联网巨头同时面临侵犯隐私的指责时采取的态度却截然不同,这背后反映的是国内外互联网环境和公司们对于隐私意识的不同,甚至是发展阶段的不同。
正如很多网民指出的,选择百度并不是因为更加开放,而是因为没有选择。这样的“没有选择”并非自愿,而是实属无奈。
“没有选择”在我们使用很多国内产品服务的过程中都有体现,其中一个备受指责的现象就是手机应用权限的滥用,现象大多出现在安卓平台。在安装手机应用后,我们时常会看到获取权限的弹窗,基于安卓系统的设定,用户有权选择允许或者拒绝,但这种选择权到了国内大量应用开发者面前就消失了。“不给权限就退出”成了开发者对付用户的手段。

图片来源:知乎
对于这些强制申请的权限,是不是会影响app提供服务呢?大部分的情况下并不会。事实上,越界获取用户隐私权限的现象十分普遍。根据腾讯社会研究中心与DCCI互联网数据中心19日联合发布的《2017年度隐私安全及网络欺诈行为分析报告》,96.6%的Android应用会获取用户手机隐私权。
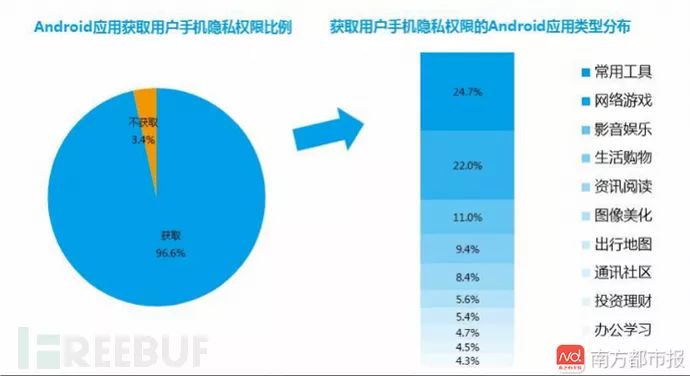
图片来源:南方周末报
除此之外,现在主流的国内网站都只支持手机号注册,不再支持邮箱注册。这带来的问题不仅是解绑换绑的不便。与邮箱不同,手机号具有更多的私人属性,也不便更换。因此我们看到了一些通过手机号码寻找注册账号的网站,通过手机号码就可以知道使用者的个人兴趣喜好。除此之外,一些网站对于手机号码及私人信息的处理方式我们也无从得知,容易造成隐患。
欧美隐私政策

在隐私保护方面,我们国家正在加紧制定相关政策,但从互联网环境来说,很多国家还是走在了我们前面,拿欧盟来说,在隐私保护数据保护方面就有完善的规范要求:
事前,在个人信息的采集环节,要正当合法地获取和处理,实行“最少采集”原则,要尽量少地采集个人信息,采集之后只能用于特定目的,不能用于非采集的目的。相关机构采集到个人信息后,要建立一套安全保护制度,采集信息的目的达到后,要在一定期限之后予以销毁。同时,欧盟很多国家都建立了个人信息处理的许可或登记制度,经过许可才能进行信息收集。
事中,欧盟实行了独立的个人信息保护执法机制,专设有信息专员。
事后,有相应的法律责任的追究和法律救济渠道。除了进行罚款,很多国家对违反法律泄漏个人信息是可以处以刑事责任。
而美国则是早在1980年就在个人信息保护八大原则中提到了收集限制原则(Collection Limitation Principle),规定数据收集要符合服务特定目的。
通过法律的限制,科技公司不得不减少信息收集,从而减少可能的滥用。
但事实证明,仅仅如此并不能完全保护好用户隐私。之所以说“国内外互联网环境和公司们对隐私保护所处的发展阶段的不同”是当我们停留在隐私保障阶段时,国外的公司在寻找策略应对数据处理带来的隐患。
就拿本次的Facebook丑闻来说,剑桥分析通过正当的Facebook用户授权获得了权限,但真正带来威胁的是之后通过数据分析带来的针对性推送。如果能够对统计数据匿名化,使得统计数据仅停留于“统计”,无法对特定用户推送广告,或许就可以避免这场事件的发生。
隐私保护攻与防

但是如果Facebook仅仅去除了用户的ID,分析公司还能不能找出相应的用户,进而推送广告呢?
2006年,Netflix公司举办了机器学习竞赛,想要改善自身推荐系统的算法。比赛过程中,Netflix向选手们提供了一个数据集,这些数据来源于真实用户的信息,但为了保护隐私,Netflix删除了这些用户的ID等身份信息。
一个月后,德克萨斯州大学奥斯汀分校的研究员Arvind Narayanan和Vitaly Shmatikov通过record linkage的方法找出了这些数据的对应用户。原理就是通过一些影评网站比如IMDb爬取用户的电影浏览记录,再与Netflix数据库中的数据进行对应,这其中,观看电影的顺序,时间都可以作为参照的标准,进而推测出数据来源于哪名用户。
这场事件引发了安全届的讨论,似乎需要更加严谨、匿名化的方案,才能保证数据在经过处理之后仍然能够保护隐私。
同一年,来自微软的Cynthia Dwork提出了差分隐私(Differential privacy)的概念。差分隐私是一种纯数学的手段,旨在提供一种当从统计数据库查询时,最大化数据查询的准确性,同时最大限度减少识别其记录的机会。
差分隐私会把随机性引入数据。举个例子,假设我们要做一个统计,统计问题是“你用iPhone吗?”在回答问题之前,受访者需要进行三个步骤:
1. 抛硬币
2. 如果是正面,如实回答问题
3. 如果是反面,就重抛硬币,如果硬币是正面,就回答“我用iPhone”;反之,回答“我不用iPhone”。
这样我们得到的统计结果里,回答“我用iPhone”的受访者中1/4并不用iPhone,3/4的用户真的用iPhone。因此我们假设iPhone用户的比例为p,通过(1/4)(1-p) + (3/4)p = (1/4) + p/2,就可以推算出p的大致数值。
差分隐私的意义在于,并不是所有的受访者都给出了真实的回答,从而避免了隐私泄露。
差分隐私技术如今被应用在很多方面,包括被美国人口普查局展示通勤模式;Google用它来分享历史流量统计信息;最出名的应用则是2016年苹果公司宣布iOS 10使用差异隐私,在收集用户使用信息的同时保障隐私。
大数据时代,用户数据成为了互联网公司的猎物,如何在收集用户数据的同时保证隐私,这不仅需要立法机构的政策,业务要企业自身的自律和在方法上的努力。
参考来源
https://www.zhihu.com/question/41542488
https://tech.slashdot.org/story/18/03/27/2010241/nearly-a-third-of-tech-workers-are-ready-to-deletefacebook
http://qimingyu.com/2017/01/06/%E5%B7%AE%E5%88%86%E9%9A%90%E7%A7%81%EF%BC%88%E4%B8%80%EF%BC%89/
http://www.aqniu.com/industry/26330.html
http://www.gooann.com/index.php?m=&c=Index&a=show&catid=12&id=235
http://www.sohu.com/a/226507961_157078
https://en.wikipedia.org/wiki/Differential_privacy
https://www.wired.com/2016/06/apples-differential-privacy-collecting-data/
https://blog.cryptographyengineering.com/2016/06/15/what-is-differential-privacy/





