ECCV oral|弱监督语义分割SOTA,高效挖掘跨图像的语义关系

新智元推荐
新智元推荐
编辑:白峰
【新智元导读】近日,由苏黎世联邦理工学院,商汤研究院和上交清源研究院共同提出的弱监督语义分割,被ECCV2020大会作为Oral论文接收,在CVPR2020 LID Challenge WSSS赛道夺冠并荣获CVPR2020 LID Workshop Best Paper。该研究创新性地提出了两种注意力机制,有效提升了弱监督语义分割效果,在PASCAL数据集上取得了多个SOTA。
近年来,基于图像标签信息(image-level label)的弱监督语义分割(WSSS)方法主要基于以下步骤:训练图像分类器,通过分类器的CAM获取每张图像在分类中被激活的区域(物体定位图),之后生成伪标签mask作为监督信号训练语义分割模型。
这种方法面临的挑战是:CAM生成的物体定位图仅关注物体中最具辨识度的区域,而不是物体整体。
最近由苏黎世联邦理工学院等研究机构共同提出的弱监督语义分割为这一问题的解决提供了新的思路。

本文设计了协同注意力分类器(co-attention classifier),在分类器中引入两种注意力模型来帮助分类器识别更多的物体区域:协同注意力(co-attention)用于帮助分类器识别一对图像之间共同的语义信息(common semantics),而且能够在物体定位图(object localization maps)的推理过程中利用上下文信息;对比协同注意力(contrastive co-attention)用于识别一对图像之间不同的语义信息(unshared semantics)。
更加注重图像间语义关系的弱监督学习
当前的研究主要关注如何通过改进分类器结构或者利用复杂多轮的训练方式,提升CAM的定位能力。尽管取得了不少进展,但这些工作一般只关注于单张图像的信息(如图1 (a)所示),却忽略了不同图像之间的语义关系。
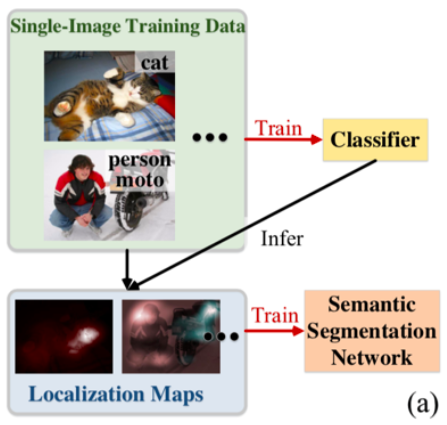
图1 传统的WSSS方法
不同于当前的主流算法,本文通过挖掘图像对(image pairs)之内的语义关系(如图2(b)所示),能够使图像中的物体有更多区域被分类器激活。
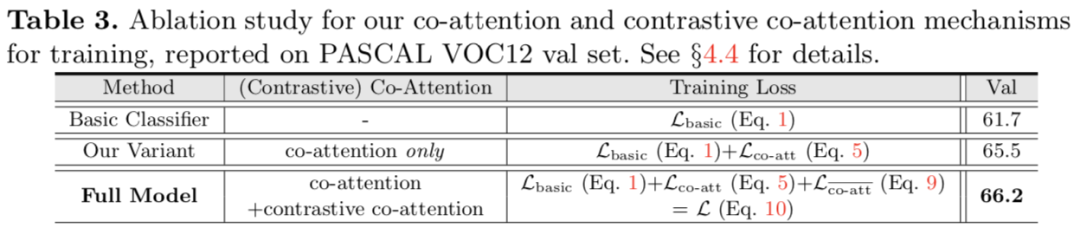
本文在传统的分类器中引入了两种注意力机制:协同注意力和对比协同注意力。前者帮助分类器发现两张图像之间共同的语义信息,后者帮助分类器关注两张图像之间不同的语义信息。
两种注意力机制相互合作并互为补充,使得分类器在学习过程中更加全面的关注图像中的物体。
除此之外,本文的注意力机制也能在获取物体定位图的过程(如图2 (c)所示)中起作用。在获取某张图像的物体定位图时,通过使用相关的图像(和该图像包含某些相同的语义类别)发现更多的相似物体区域,从而获得更高质量的物体定位图。
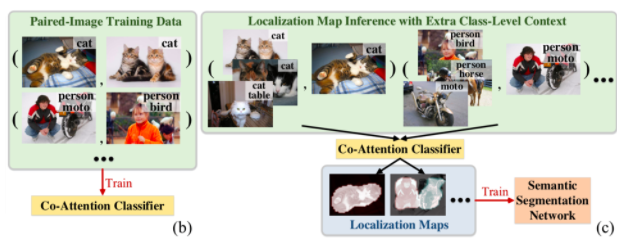
图2 基于协同注意力机制的WSSS方法
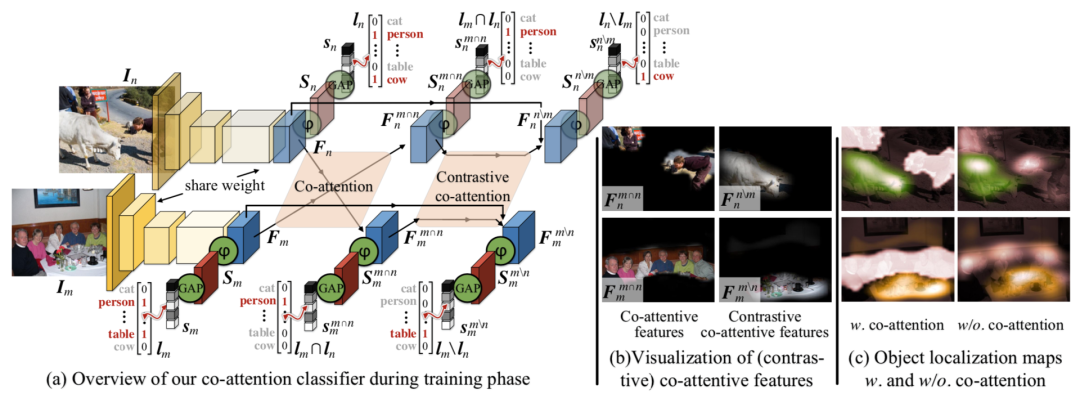 图3 本文提出的协同注意力分类器的整体框架和相关可视化中间结果。
图3 本文提出的协同注意力分类器的整体框架和相关可视化中间结果。
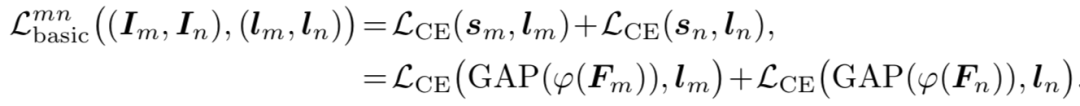
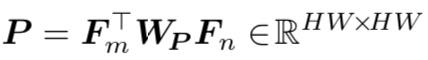

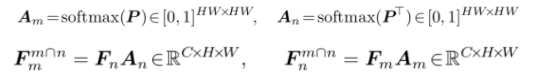
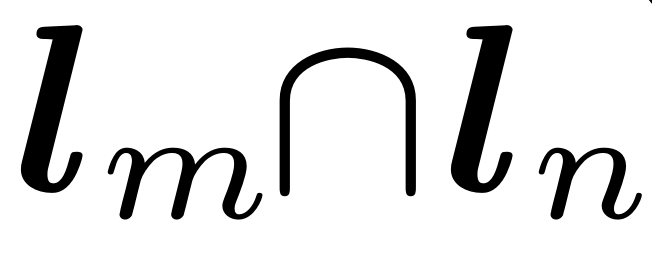 (Person)来监督该特征的学习。损失函数计算如下:
(Person)来监督该特征的学习。损失函数计算如下:
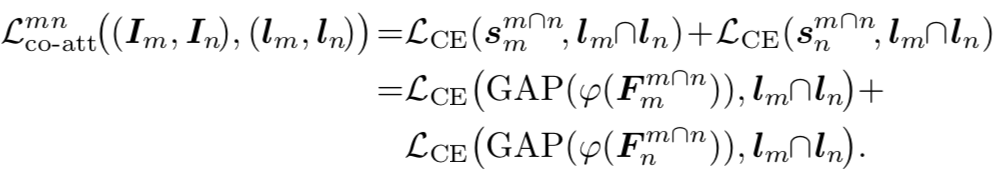 (Person)能够意识到,不仅人的脸和Person这一label相关,其它highlight出来的区域也和Person相关,从而能够将类别标签和更多的物体区域关联起来。
(Person)能够意识到,不仅人的脸和Person这一label相关,其它highlight出来的区域也和Person相关,从而能够将类别标签和更多的物体区域关联起来。
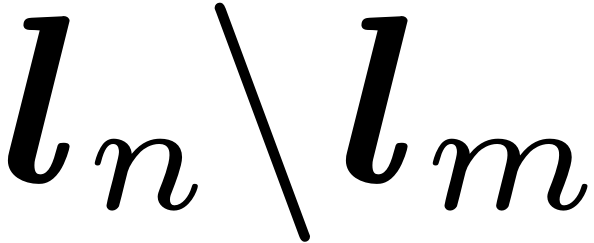 是Cow,Im的特有类
是Cow,Im的特有类
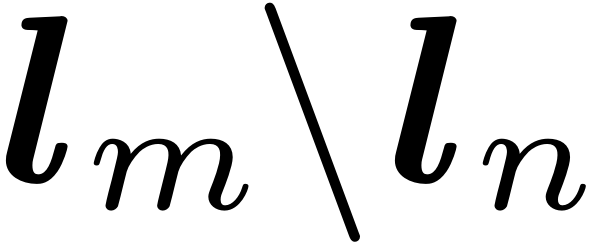 是Table。对比协同注意力特征计算如下:
是Table。对比协同注意力特征计算如下:
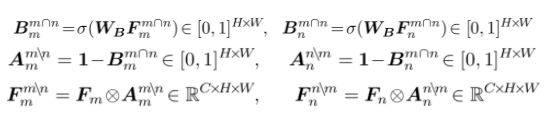

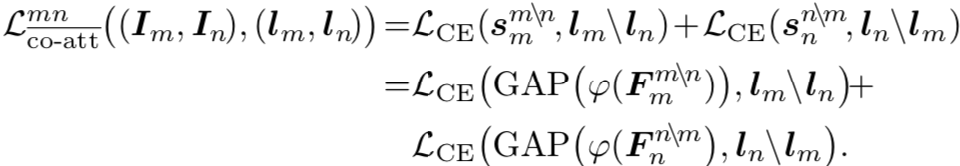
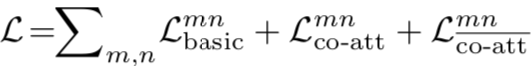
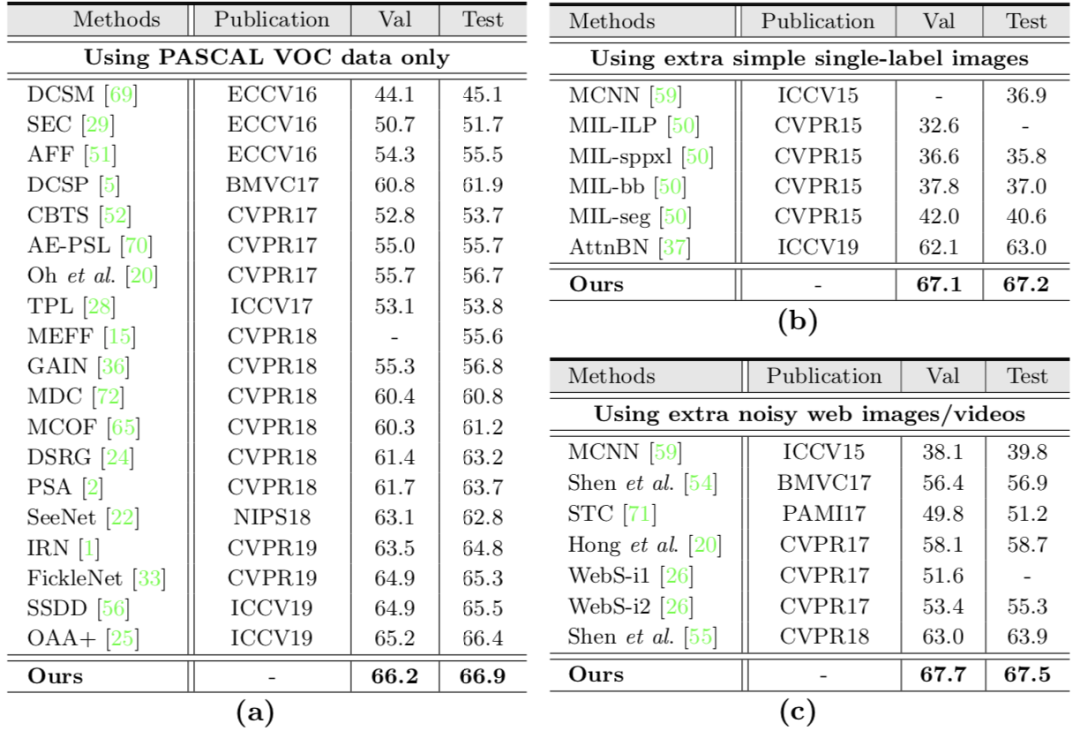
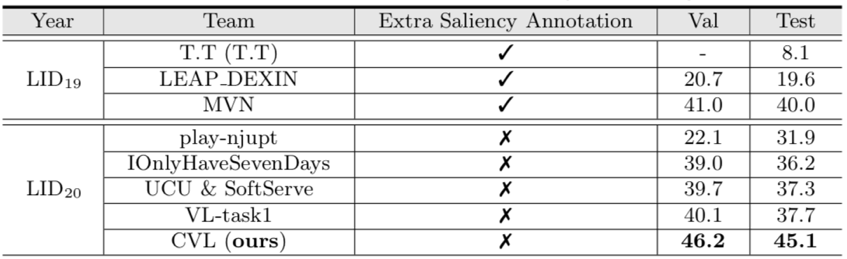
以标准设置,在PASCAL VOC 2012上进行实验,结果如下图: