模型压缩95%,MIT韩松等人提出新型Lite Transformer
作者:Zhanghao Wu等
机器之心编译
参与:小舟、魔王
Transformer 的高性能依赖于极高的算力,这让移动端 NLP 严重受限。在不久之前的 ICLR 2020 论文中,MIT 与上海交大的研究人员提出了一种高效的移动端 NLP 架构 Lite Transformer,向在边缘设备上部署移动级 NLP 应用迈进了一大步。

论文地址:https://arxiv.org/abs/2004.11886v1
GitHub 地址:https://github.com/mit-han-lab/lite-transformer
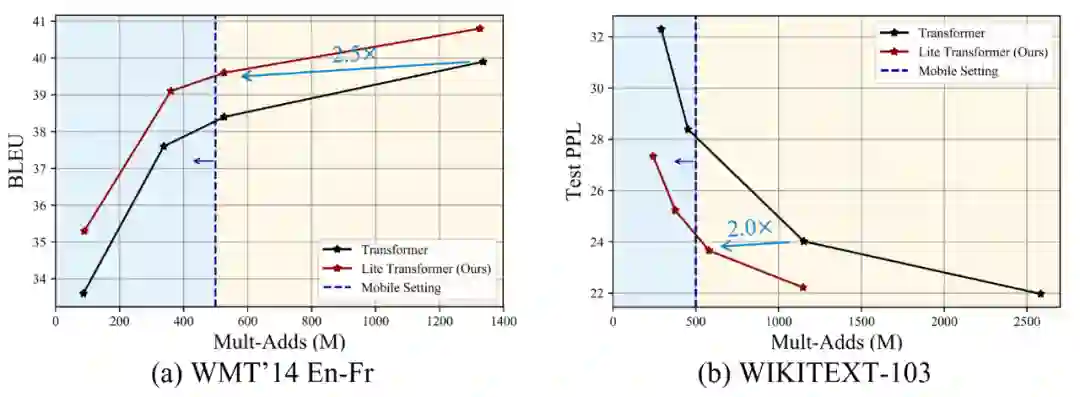
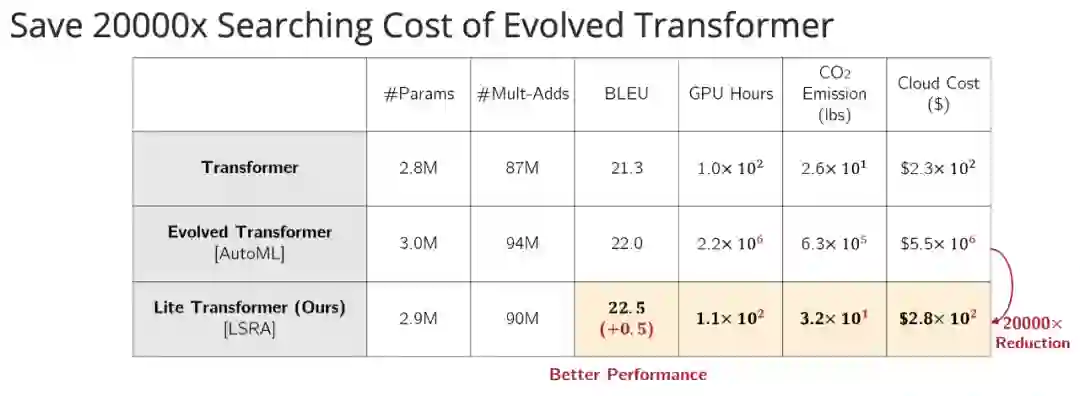
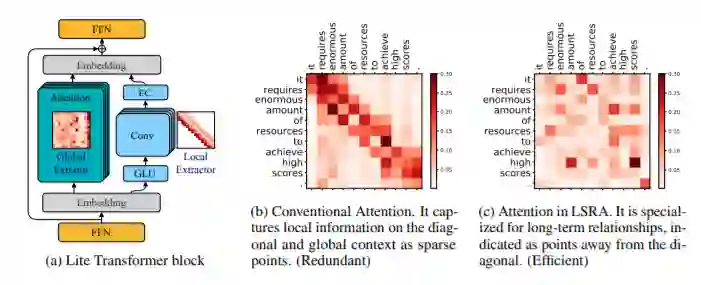
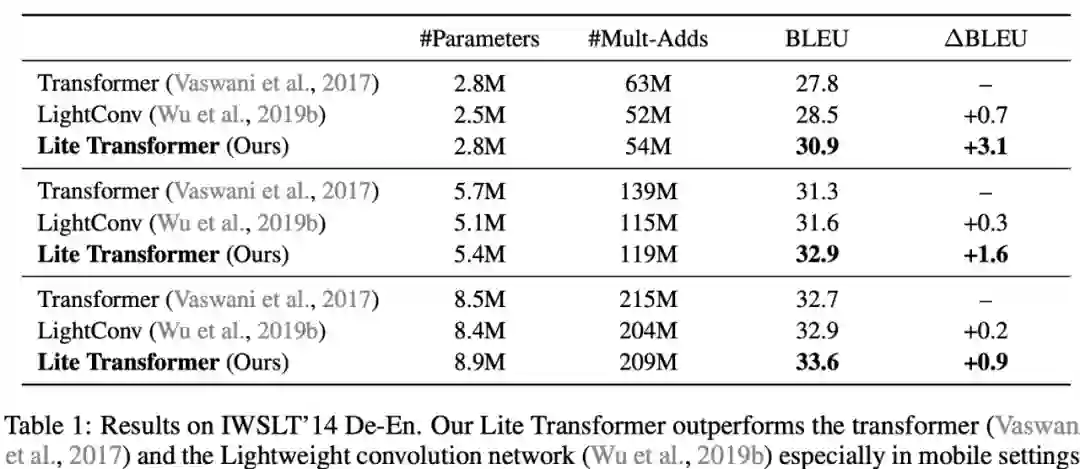
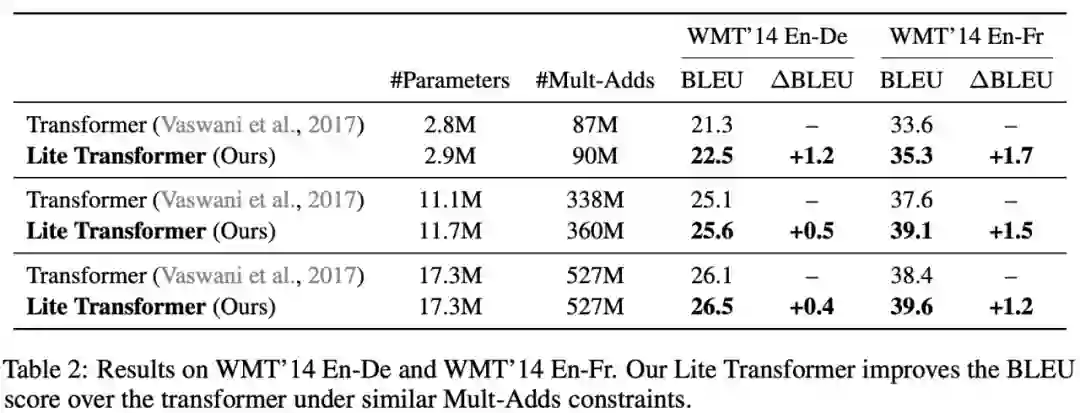
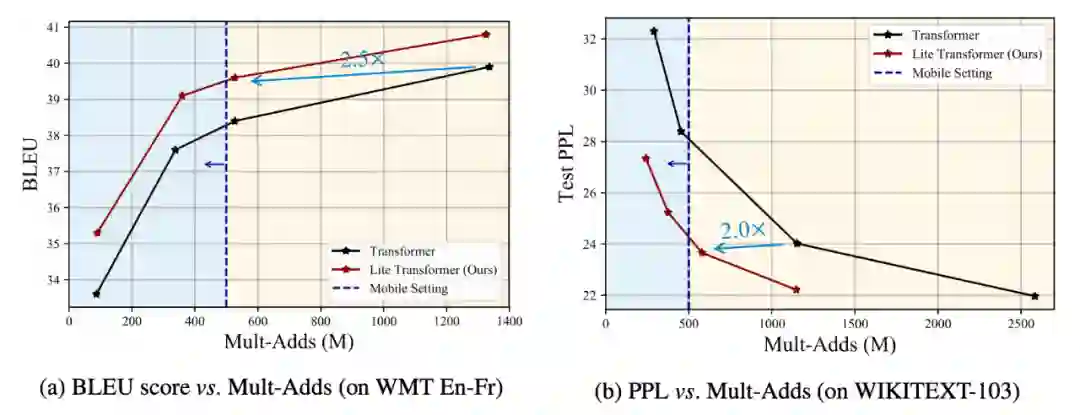
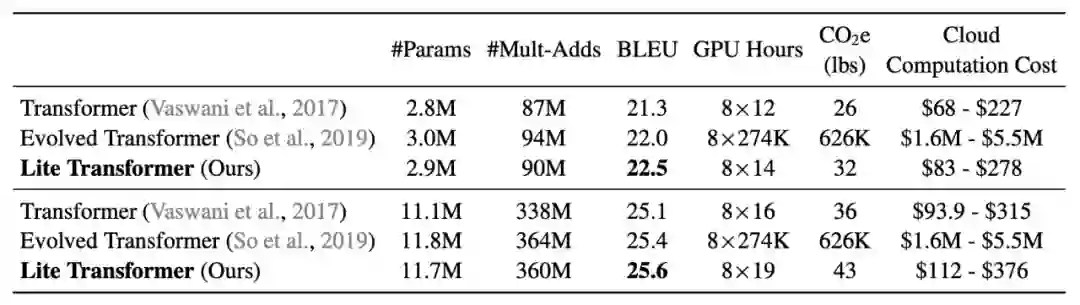



登录查看更多
相关内容
Arxiv
16+阅读 · 2019年5月24日
Arxiv
6+阅读 · 2018年6月21日





相关VIP内容
相关资讯
相关论文
Arxiv
16+阅读 · 2019年5月24日
Arxiv
6+阅读 · 2018年6月21日