Motion Selective Prediction for Video Frame Synthesis
https://www.arxiv-vanity.com/papers/1812.10157/
抽象
现有的条件视频预测方法从大型数据库训练网络并概括为先前未见过的数据。我们采取相反的立场,并引入一个模型,该模型从给定视频的第一帧中学习并扩展其内容和动作,例如,使其长度加倍。为此,我们提出了一种双网络,可以灵活地使用动态和静态卷积运动内核来预测未来的帧。我们模型的构造为我们提供了有效分析其功能和解释其输出的方法。我们通过实验证明了我们在最狂野具有挑战性的视频方法的稳健性和表明它是有竞争力的\ WRT相关的基线。
结论
我们已经从单个视频剪辑中引入了用于未来帧合成的模型。最初由视网膜中的Direction Selective细胞机制启发,我们的运动表示基于双网络:一个学习内核,另一个动态选择最佳子集用于下一帧预测。我们的帧生成与挑战视频的基线方法相比毫不逊色。作为未来的工作,我们计划调查这种双网构造对其他任务的潜力,例如运动构成或运动传递。另一个方向是提取更丰富的潜在运动表示。
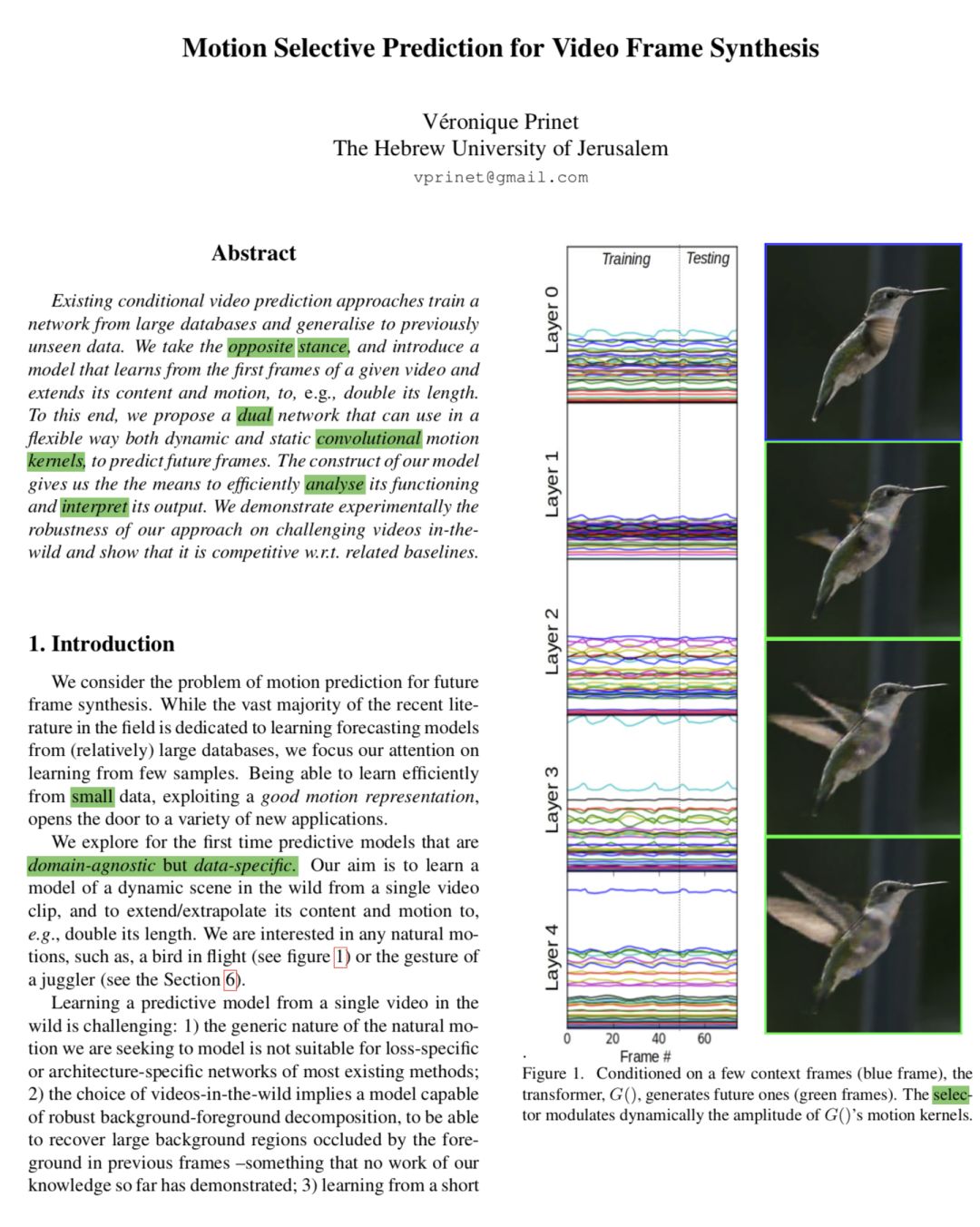




https://www.arxiv-vanity.com/papers/1812.10157/
年薪百万-骥智CreateAMind2019招聘目标:年薪百万招聘大牛50+ 推荐成功送mate20
登录查看更多
相关内容
专知会员服务
17+阅读 · 2020年3月9日
专知会员服务
136+阅读 · 2020年3月8日
专知会员服务
27+阅读 · 2020年1月17日
专知会员服务
30+阅读 · 2020年1月2日
专知会员服务
93+阅读 · 2019年11月15日
专知会员服务
85+阅读 · 2019年11月15日
Arxiv
3+阅读 · 2018年11月20日
Arxiv
4+阅读 · 2017年12月19日




相关VIP内容
专知会员服务
17+阅读 · 2020年3月9日
专知会员服务
136+阅读 · 2020年3月8日
专知会员服务
27+阅读 · 2020年1月17日
专知会员服务
30+阅读 · 2020年1月2日
专知会员服务
93+阅读 · 2019年11月15日
专知会员服务
85+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
3+阅读 · 2018年11月20日
Arxiv
4+阅读 · 2017年12月19日