NeurIPS 2019 | 中科院、武大、微软等8篇论文解读
NeurIPS 2019即将于12月8日在加拿大温哥华召开,作为机器学习顶级学术会议之一,NeurIPS 2019备受瞩目。学术君整理了NeurIPS 2019 八篇录用论文,涵盖深度机器学习领域多个方面的内容,供大家学习参考。
Dual Adversarial Semantics-Consistent Network for Generalized Zero-Shot Learning
• 作者:倪健 仉尚航 谢海永(中国科学技术大学,卡内基梅隆大学,首都医科大学等)
• 论文地址:
https://static.aminer.cn/misc/pdf/8846-dual.pdf
近年来人工智能技术研究和应用取得了诸多重要进展。然而,现有的人工智能技术和系统大多严重依赖和受限于大量的人工标注、高质量的样本数据。因此,如何减少人工在样本方面的处理工作,以及如何使模型快速适应层出不穷的新样本,成为人工智能领域内亟待解决的挑战和关键问题。为了应对这样的挑战,国际上提出了零样本学习(Zero-Shot Learning,ZSL),利用样本之间潜在的语义关系,使得模型可以处理一些之前从未处理过的样本,对于探索实现真正的人工智能具有非常重要的意义。
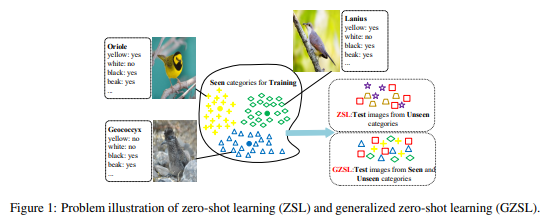
该研究成果提出了一种通用的先进零样本学习方法。现有的ZSL方法存在语义丢失严重、视觉语义交互欠缺、分类强偏置等重大问题,因而,在广义ZSL设置中部署模型后,性能很差。针对这些问题,作者提出了一种新颖的基于对偶对抗语义一致网络的新型框架。该框架通过构建两个生成对抗网络(GANs),分别负责视觉特征的生成以及语义特征的重建,并专门设计适用于ZSL的视觉-语义对抗损失函数,从而获得具有高度判别性语义特性的视觉特征,将ZSL学习问题转化为传统的监督学习问题。该模型有效地增强从已知类到未知类的知识转移,并有效缓解ZSL中固有的语义损失问题。大量的实验结果证明了该模型的优越性。
Copula Multi-label Learning
• 作者:刘威威(武汉大学)
• 论文地址:
https://static.aminer.cn/misc/pdf/8863-copula.pdf
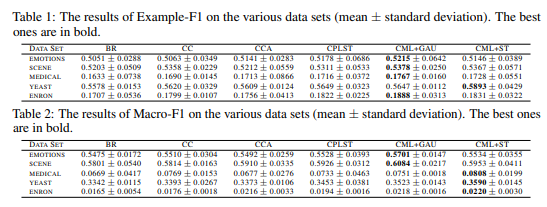
多标签学习中一个挑战性的问题是如何对标签以及特征之间的关系建模。现在有很多种方法都在尝试解决这个问题,但是人们对这些方法的统计性质还是不清楚。Copulas是建立多元数据相关性模型的有力工具,并且在金融、计量经济学和系统神经科学等广泛应用中取得巨大成功。论文提出了一个新颖的Copula多标签学习范式来对标签和特征之间的相互依赖关系建模。基于Copula的学习范式能够为多标签学习提供一个新的统计视角。特别地,本文首先利用该技术在输出空间中构造连续分布。然后对提出的模型进行半参数化估计,其中对Copula进行参数化估计,而对边际分布进行非参数化估计。理论上,论文证明了研究组提出的估计量是一个一致无偏估计量,并且证明了估计量渐近服从正态分布。此外,论文还给出了估计量的均方误差的上界。最后,不同领域的实验结果验证了该方法的优越性。
Deep Multimodal Multilinear Fusion with High-order Polynomial Pooling
• 作者:唐佳佳,张建海,孔万增,赵启斌(杭州电子科技大学,日本理化研究所AIP中心)
• 论文地址:
https://static.aminer.cn/misc/pdf/9381-deep.pdf
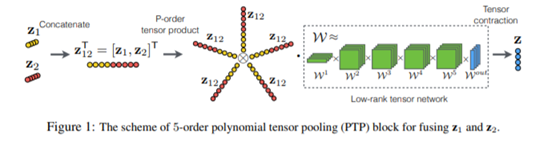
本文提出一种可以灵活变换的深度分层多元信息融合框架,所包含基础模块为高阶多项式融合块,能够在细粒度层面同时刻画多模态数据之间的局部以及全局相关性,对基于语音文本视频信号在情感计算领域的多模态融合方法进行了有效补充。
Learning to Perform Local Rewriting for Combinatorial Optimization
• 作者:Xinyun Chen ,Yuandong Tian(UC Berkeley, Facebook )
• 论文地址:
https://static.aminer.cn/misc/pdf/8858-learning.pdf

用于硬组合优化的基于搜索的方法通常由启发式方法指导,在各种条件和情况下调整启发式方法通常非常耗时。在本文中,我们建议NeuRewriter学习一个策略来选择启发式并重写当前解决方案的本地组件,以迭代地改进它直到收敛。该政策将因素归结为区域拣选和规则拣选组件,每个组件由在强化学习中使用actor-critic方法训练的神经网络参数化。NeuRewriter捕捉了组合问题的一般结构,并在三个多功能任务中表现地很强大:表达式简化、在线作业调度和车辆路径问题。NeuRewriter优于Z3中的表达式简化组件;优于在线作业调度中的DeepRM和Google OR工具;并且在车辆路径问题方面优于最近的神经基线和Google OR工具。
One ticket to win them all:generalizing lottery ticket initializations across datasets and optimizers
• 作者:Ari Morcos,Haonan Yu,Michela Paganini,Yuandong Tian(Facebook AI Research)
• 论文地址:
https://static.aminer.cn/misc/pdf/8739-one.pdf
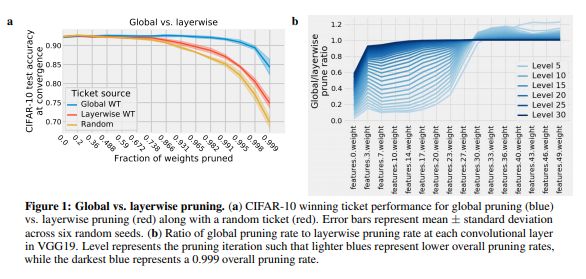
彩票初始化的成功(Frankle和Carbin,2019)表明只要网络被适当地初始化,就可以训练小型的稀疏网络。不幸的是,找到这些“中奖票”初始化在计算上是昂贵的。一种可能的解决方案是在各种数据集和优化器中重复使用相同的中奖票。然而,获奖票证初始化的一般性仍不清楚。在这里,我们尝试通过为一个训练配置(优化器和数据集)生成获胜票并在另一个配置上评估它们的性能来回答这个问题。也许令人惊讶的是,我们发现,在自然图像领域内,获胜票证初始化在各种数据集中得到推广,包括Fashion MNIST,SVHN,CIFAR-10/100,ImageNet和Places365,通常在同一数据集上可以获得接近生成中奖票的性能。此外,使用较大数据集生成的获奖票证一致地转移,比使用较小数据集生成的票证更好。我们还发现,中奖票证初始化可以在具有高性能的优化器中进行推广。这些结果表明,获胜票证初始化包含更广泛地通用于神经网络的归纳偏差,这改善了许多设置的训练,并为开发更好的初始化方法提供了希望。
Cross Attention Network for Few-shot Classification
• 作者:Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen(中国科学院计算所VIPL研究组,中国科学院大学,中国科学院脑科学与智能技术卓越创新中心)
• 论文地址:
https://static.aminer.cn/misc/pdf/8655-cross.pdf
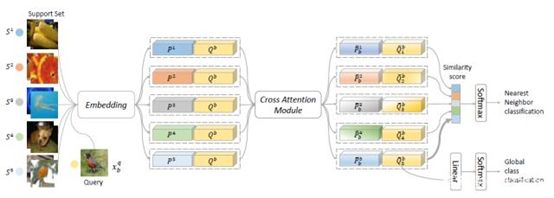
小样本分类的目标是根据少数标注的样本去识别该类别,其中未知类别(训练类别和测试类别的不一致)和少样本数据是两个关键问题。针对这两个问题,我们提出了一个新的交互注意力网络。首先,我们引进了一个交互注意力模块去处理未知类别的问题。该模块对于每个输入的图像对生成一对注意力图去强调目标物体所在的区域,从而使提取的特征更具有判别性。其次,我们引进了一个新的直推式推理算法去缓解小样本问题。我们提出的直推式算法迭代地利用未标注的数据去扩充标注的数据,从而使提取的类别特征更加鲁棒。在现有的多个数据集上,我们提出的框架都优于当前最好的方法。
Multi-label Co-regularization for Semi-supervised Facial Action Unit Recognition
• 作者:Xuesong Niu,Hu Han,Shiguang Shan,Xilin Chen(中国科学院计算所VIPL研究组,鹏城实验室,中国科学院大学,中国科学院脑科学与智能技术卓越创新中心)
• 论文地址:
https://static.aminer.cn/misc/pdf/8377-multi.pdf
面部动作单元(AUs)编码了人脸面部的各种基本动作,被广泛应用于表情识别和精神状态分析中,有着重要的应用价值。要训练一个鲁棒的面部动作单元分类器需要大量的数据,然而由于面部动作单元需要专家来进行标注,且标注十分耗时,现有的面部动作单元识别数据集规模都较小。为了解决这一问题,受传统的协同训练框架的启发,我们提出了基于多标签协同正则的半监督面部动作单元识别方法。
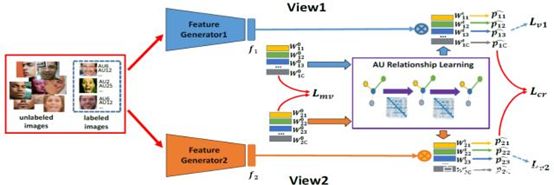
该方法能够有效利用大量网络图片和少量人工标注图片来训练面部动作单元分类器。针对所有的标注和未标注数据,我们首先使用两个不同的网络来提取多视角的特征,并且利用多视角损失来迫使两个视角所学习到的特征无关。同时,为了约束两个视角预测结果的一致性,我们提出了多标签协同正则损失来约束两个视角的面部动作单元预测概率。此外,我们还通过图卷积网络将不同面部动作单元之间的关系嵌入到分类器之中。通过在少量标注数据和大量的未标注数据上的训练,我们能获得一个有较好的泛化能力的人脸动作单元识别分类器。在多个数据集上的测试都说明了我们算法能够有效利用未标注的数据,大幅度提高了面部动作单元识别的准确性。
iSplit LBI:Individualized Partial Ranking with Ties via Split LBI
• 论文作者:Qianqian Xu, Xinwei Sun, Zhiyong Yang, Xiaochun Cao, Qingming Huang, Yuan Yao(中国科学院计算所VIPL研究组,微软亚洲研究院,鹏城实验室,中国科学院大学)
• 论文地址:
https://static.aminer.cn/misc/pdf/8645-isplit.pdf
传统的成对比较众包标注学习方法假设用户的标注结果可基本达成共识,因而直接以少量用户的标注投票结果作为真实类标进行学习。然而,在现实场景中,用户的个性化偏好往往较为显著,无法从个性化标注中获得共识结果。鉴于以上问题,本文提出一种平局可感知的偏序个性化学习统一框架以突破现有方法性能壁垒。
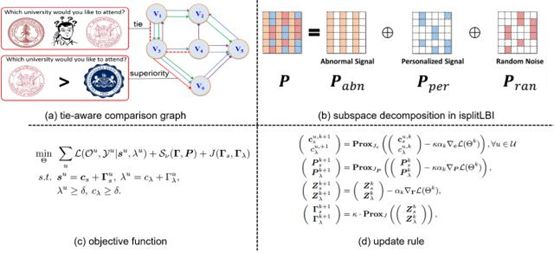
在该框架中,我们将模型参数分解为共识因子和个性化因子,并提出一种基于变量分离的模型更新算法iSplitLBI,可同时实现个性化学习以及异常用户检测。具体而言,iSplitLBI算法随迭代次数演变可生成不同稀疏程度的参数正则化路径并同时更新模型参数和正则化参数。在每次迭代中,iSplitLBI的变量分离机制可将个性化因子分解为异常分量、个性化分量以及噪声分量之和。异常分量提供模型选择的结构信息,其所非零列即对应异常用户;个性化分量提供模型预测的细粒度信息,可更好地完成个性化偏好预测任务。虚拟及真实数据集上进行的大量定性/定量实验表明,我们的方法在偏好预测及异常用户检测方面均具有良好的表现。

日前,NeurIPS2019官网已经公布了全部录用论文,我们已为大家全部下载下来,需要的同学请动动你的小手指给本篇点个“在看”,在本公号后台回复“NeurIPS2019”即可获取。

解读!北邮、西电、DeepMind等8篇NeurIPS 2019论文合集
NeurIPS 2019 | 中科院、旷视提出DetNAS框架:一种可用于目标检测的Backbone搜索
想要查看更多优秀论文,可点击阅读原文浏览!



