李庆敏:腾讯游戏大数据分析引擎实践

分享嘉宾:李庆敏 腾讯游戏
编辑整理:王璞 天津大学
出品平台:DataFunTalk
导读:大数据分析平台一直是大数据应用最基础、最核心的应用之一。相比于原有的传统BI软件和数据库提供分析能力有很多局限,例如:数据处理效率低,大数据处理能力不足以及无法和线上数据商业化应用推荐和服务打通等。iData作为游戏大数据分析系统,在服务腾讯海量的游戏产品过程中,经过多年的迭代和实践,形成iDataCharts大数据可视化和iDataEngin大数据分析引擎为核心能力的大数据分析系统。
本文主要介绍大数据分析引擎在腾讯游戏大数据的实际应用,主要内容包括:
腾讯游戏大数据分析背景
大数据分析引擎的实践经验
总结和未来的规划
首先和大家分享下腾讯游戏分析的背景。
1. 腾讯游戏分析背景
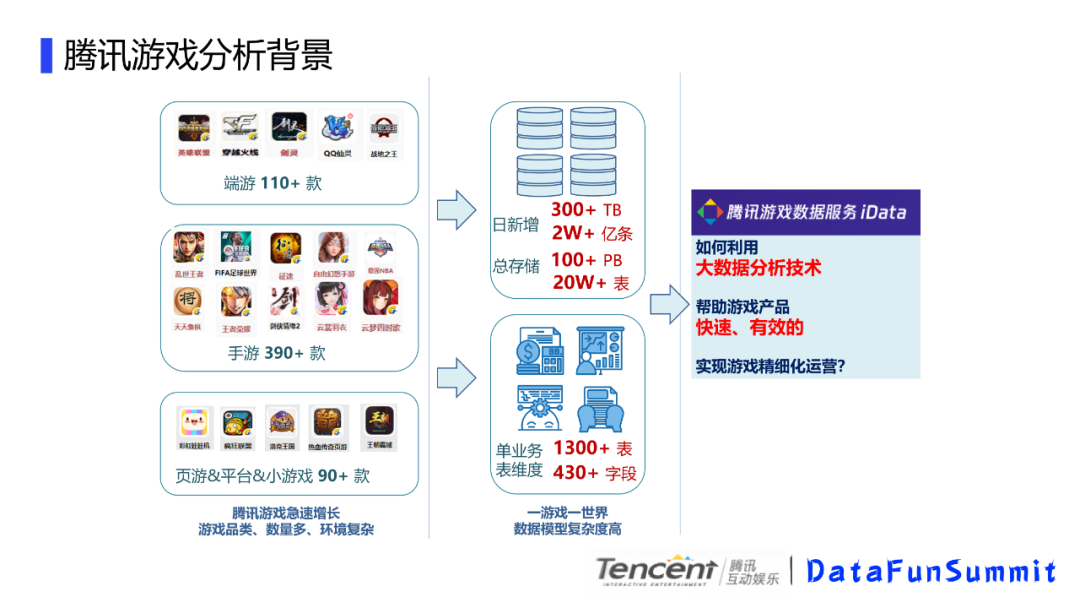
腾讯游戏分析的背景有以下几个的特点:
腾讯游戏发展的比较快,游戏品类和数量多,环境复杂。比如有端游110多款,其中存在大型游戏,比如英雄联盟,DNF。手游有390款,像王者荣耀。还有各种小游戏;
我们游戏日新增300+TB,2W+亿条数据。单个业务1300+表左右,维度430+字段;总体的数据量比较庞大;
一游戏一数据,数据模型复杂度高。
由于游戏业务之间相对独立,各个业务的数据模型复杂度还比较高,提倡精细化运营,对一些运营的需求,就需要我们使用大数据分析的技术,快速有效的帮助产品实现精细化运营,避免需求周期长,效率低的问题,进而实现精细化运营,接下来,就讲下我们的一些实践经验。
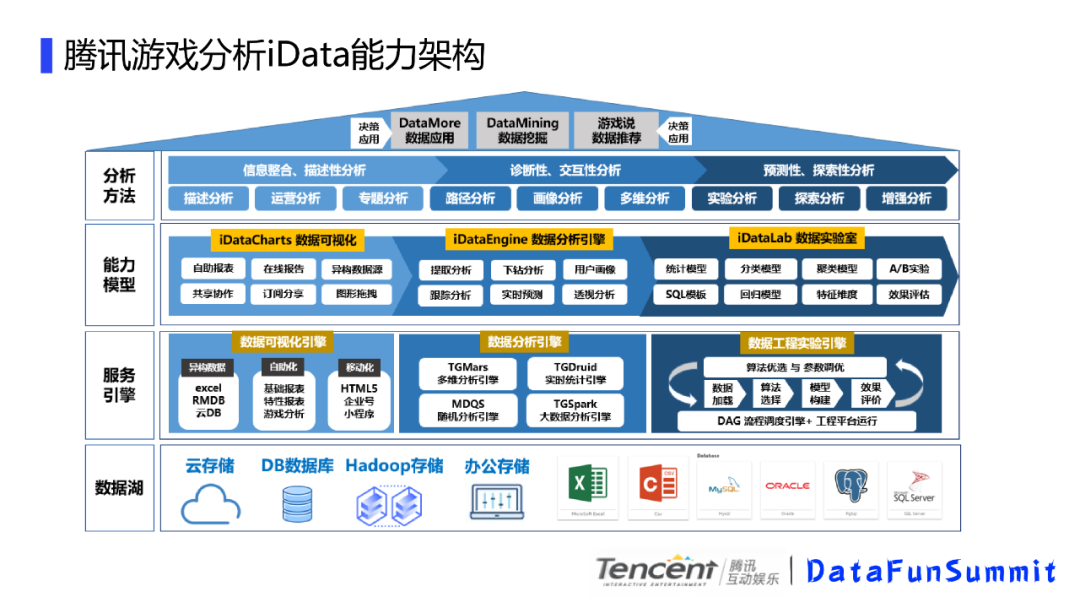
从底向上分别是数据湖,我们有云存储,常见db数据库,比如mysql,pg库等,还有hadoop存储以及办公存储。上一层是服务引擎,主要有数据可视化引擎,支撑上游的可视化服务,我们的数据分析引擎,支撑我们多维、实时以及大数据分析,还有我们的工程试验引擎支持ai方面的一些研究。在上一层是能力模型,主要是一些功能能力的提炼,再上一层是分析方法以及决策运用,具体到就是用户层面接触的东西,今天我主要会讲解数据分析引擎这一块的内容。也就是腾讯游戏大数据分析引擎的实践
腾讯游戏大数据分析能力组成由以下四个组成:
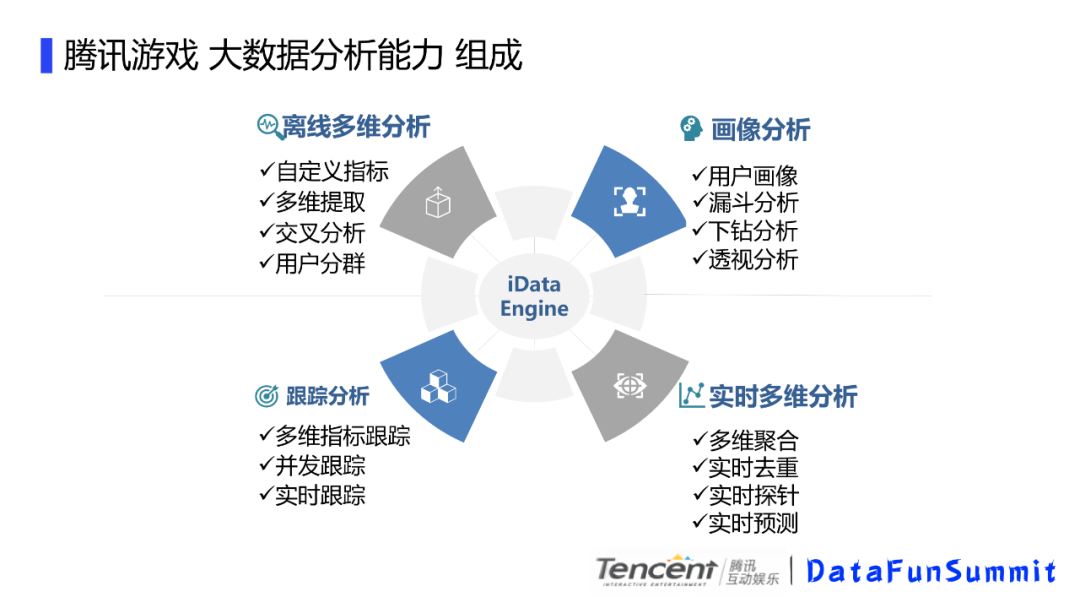
离线多维分析:自定义指标,多维提取,交叉分析,用户分群;
画像分析:用户画像,漏斗分析,下钻分析,透视分析;
跟踪分析:多维指标跟踪,并发跟踪,实时跟踪;
实时多维分析:多维聚合,实时去重,实时探针,实时预测。
主要的应用场景:
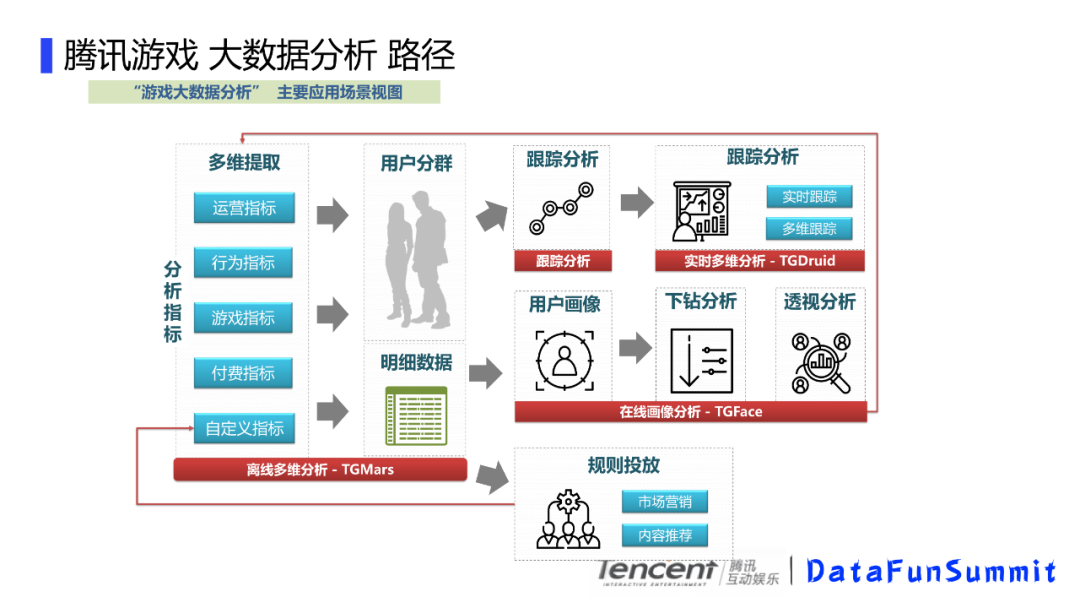
我们游戏大数据分析的一个主要应用场景是这样的,首先你可能会有一些分析指标,比如用户的行为指标,我们的活跃,付费,新增,或者是游戏内的对局情况,比如对局数,杀人数之类的,基于这些指标我们可以对用户进行分群,比如我们通过对付费额度的一个区间划分,可以有大R,中R和小R用户,比如大R用户一般是付费能力比较高的用户,也是游戏的重点用户,还有高活跃用户,比如最近一周登录次数达到一定程度。当然,你也可以是定义的一些流失付费用户,或者自己上传的用户,然后拿到这些用户,可以进行跟踪分析,比如看下这批付费流失的用户在流失前的游戏行为,这些用户的对局情况,或者是副本参与情况。这样就有助于流失用户的分析。也可以对这批用户进行画像分析,看下这些用户的一些年龄占比、性别、省份区域等,还可以对某些感兴趣的用户发起营销活动,然后这些他投放的用户又可以和自定义指标关联。对这批用户实时跟踪游戏内的表现,比如实时观察这批用户的当天在线时长区间,游戏内某些特定场景的表现情况比如对局情况、副本参与情况等。这样对营销的数据就可以及时了解到,从而形成一个数据闭环。
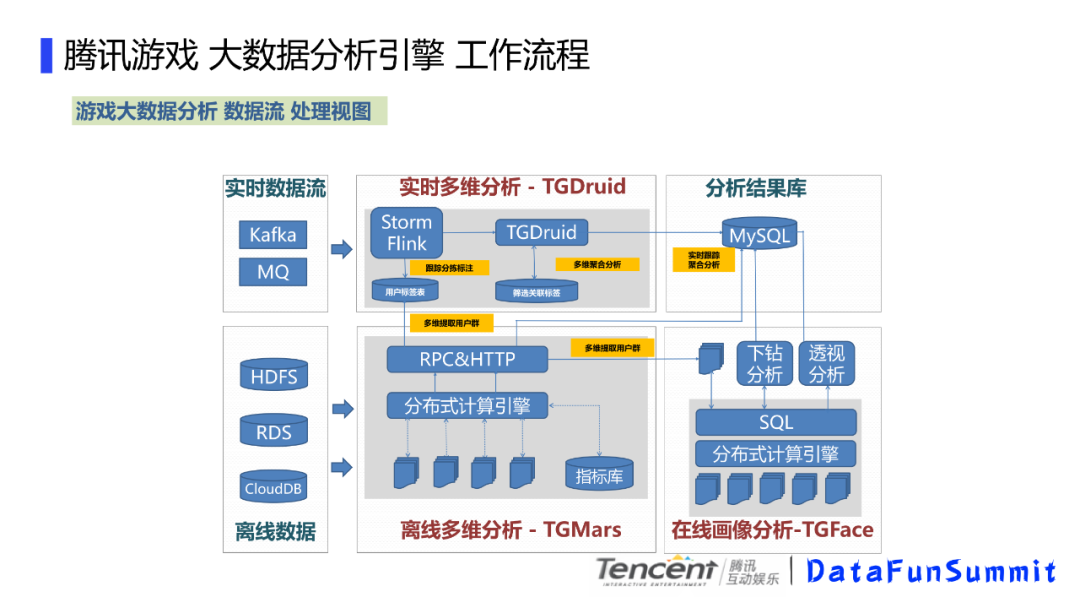
我们的数据来源有实时数据流和离线数据,比如我们有hdfs,rds,云db,离线数据通过数据接入模块接入到离线多维分析,接入的过程会创建指标库,然后根据指标库我们可以多维提取这个用户群。然后基于这个用户群,我们可以做画像分析进行下钻或者透视,然后把结果数据存储到db里面。另外,我们可以把用户包存在用户标签库里面,通过实时多维分析来跟踪这批用户的实时行为数据。并把数据落地到DB,提供给前端进行展示。这个是大体的一个数据流转,这里面就涉及到几个计算引擎,离线多维分析tgmars,在线画像tgface和实时多维分析tgdruid,只有这些引擎计算能力比较强和计算速度比较快,才能支撑好这个系统,接下来会主要讲这些引擎的相关实现技术。
1. 离线多维分析-TGMars
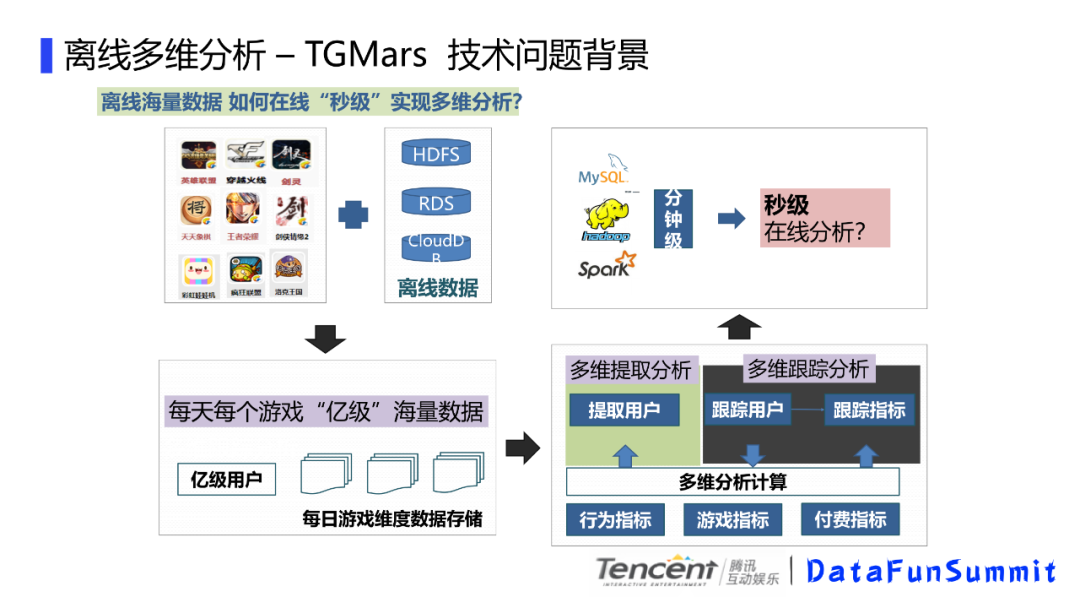
对于离线海量数据,如何进行秒级多维分析?
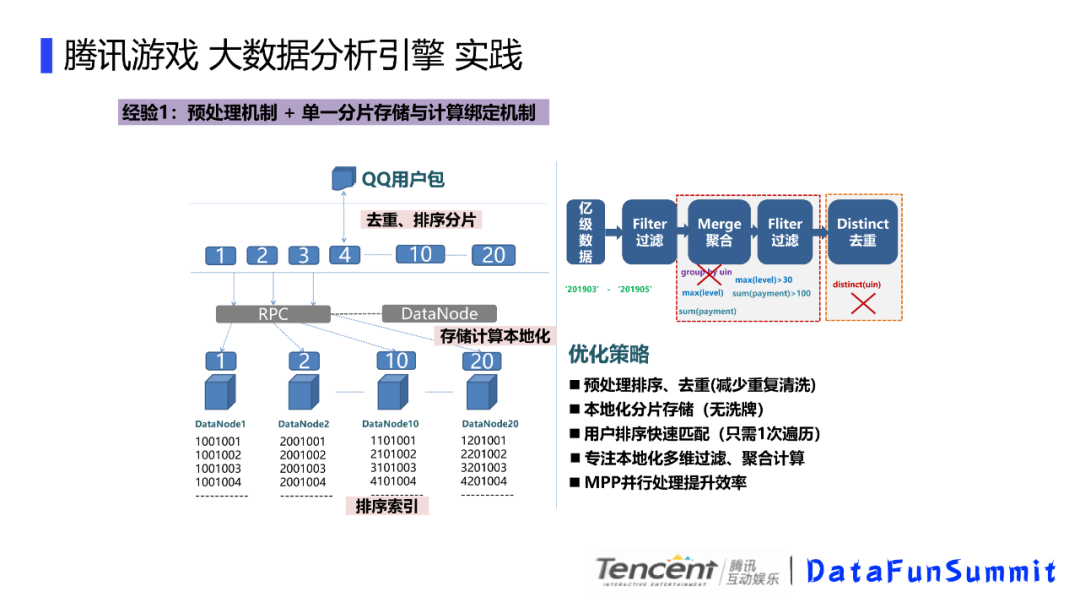
预处理机制+单一分片存储与计算绑定机制。优化策略就是先进行预处理排序,去重(减少重复清洗);本地化分片存储(无洗牌);用户排序快速匹配(只需一次遍历);专注本地化多维过滤,融合计算;MPP并行处理提高效率。
位图索引加速多维计算。80%的计算集中在某些热点数据,热点状态使用位图,流水信息序列化存储。90%的分析任务集中在1年,一般是分区,平台统计。通过按年,游戏,分区分文件,规则基于位的加速计算和处理,多维位图索引+内容文件机制,来进行加速。
物化视图。比如月度和年视图,解决时间跨度长的统计,避免扫描原始数据,通过最后时间维度状态快速判断,单指标按周,月,年来聚合计算。
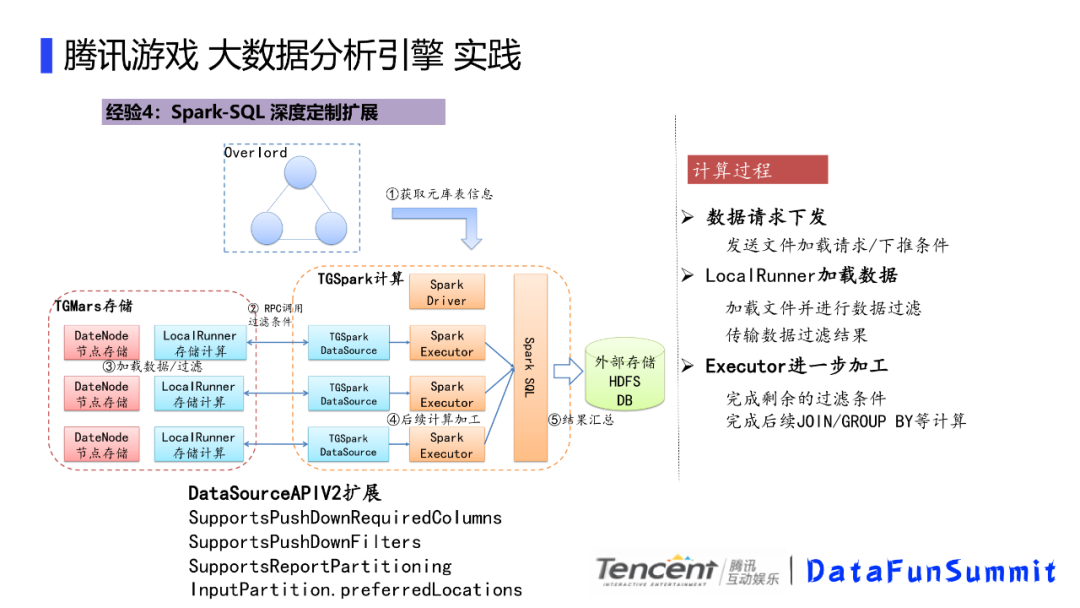
Spark-SQL深度定制扩展,主要是通过对DataSourceAPIV2扩展。计算过程包括,数据请求进行下推,本地加载文件并进行数据过滤,最后进一步加工。
2. 在线画像分析-TGFace
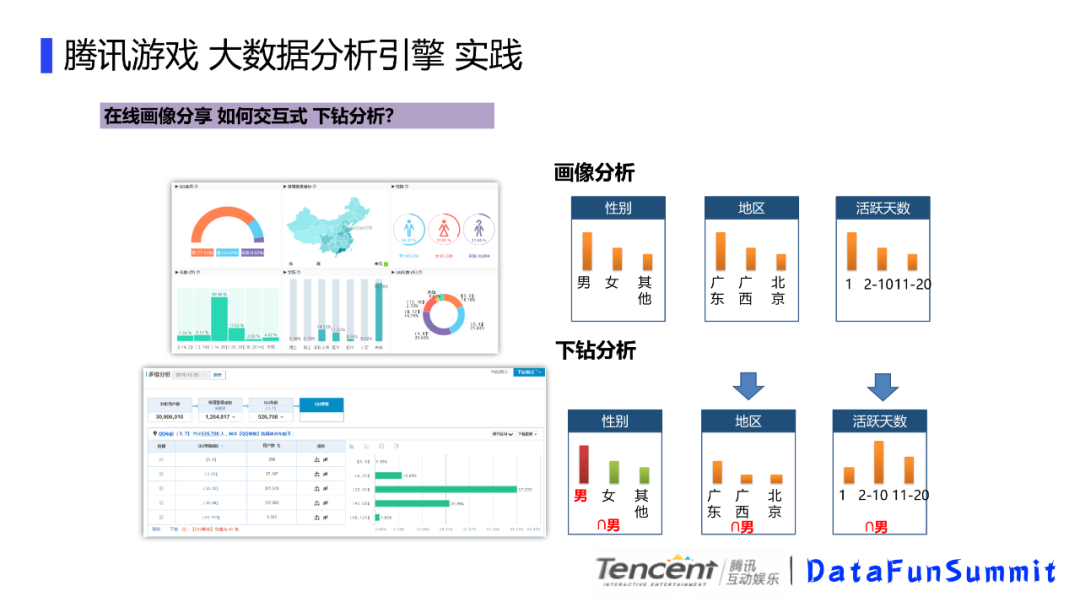
比如我们对5000w新注册用户分析流失因素,最后针对主要用户进行干预,可能会有以下步骤,先判断流失用户,这个时候需要经过5000w次判断,然后筛选出4000w流失用户,然后判断这个4000w用户的年龄分布,然后需要4000w的判断假设得到3000w的年龄分布,依次类推,分别得到角色分布,游戏时长,勇者任务,最后得到这个600w用户,总共进行了1.42亿次的判断,每次分析都是基于上次的下钻分析,总的比较次数还是比较大的,数据量大的话,性能消耗比较大,表现出来就是速度往往快不起来。下面介绍下我们的画像分析引擎实践,来解决这个效率问题。
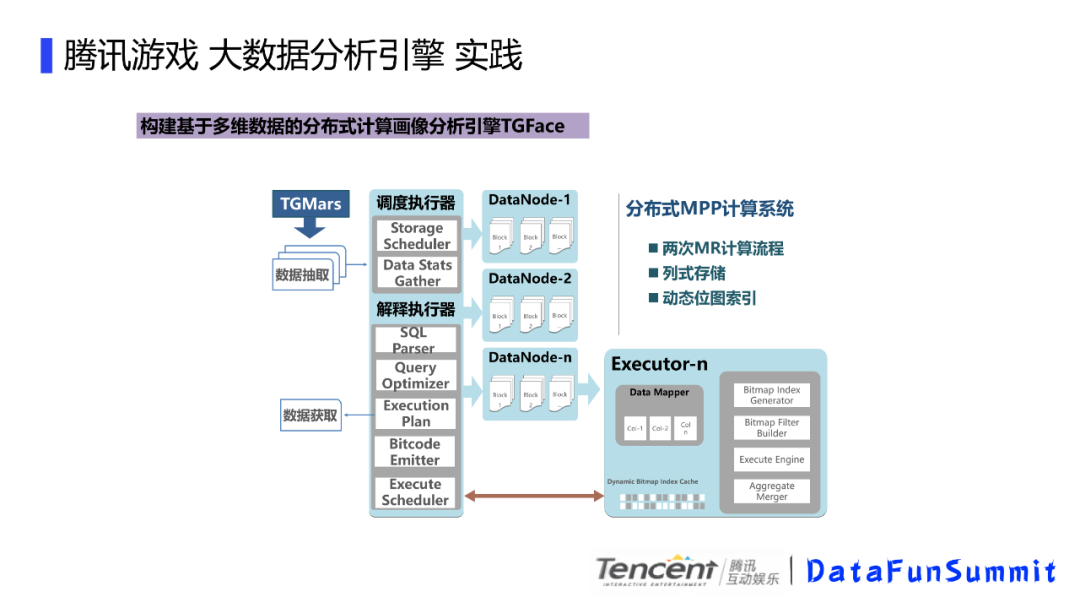
这个是我们画像分析引擎的整体处理流程,我们先是使用tgmars引擎提取原始用户包,然后把用户包的相关信息发送给调度器,然后上传到画像系统的存储Datanode中,这里的意思是只有画像包的数据才会落地到datanode而不是所有的数据,并且数据落地到datanode的时候会进行切分并转换为列式进行存储。等前端交互画像的时候,会根据条件生成sql,然后给到解析器执行,解析器会分别进行sql解析,进行一些查询优化,然后生成执行计划,然后将sql语句编译成机器代码,最后将DAG调度到各个节点去执行,节点里面会根据列式存储,进行位图生成,位图的计算。
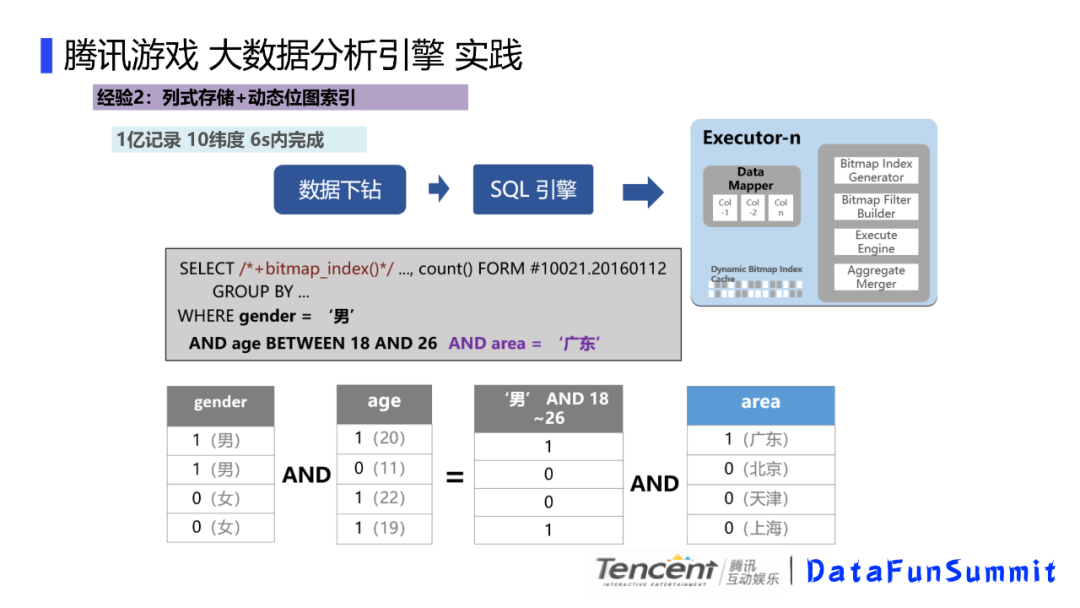
执行器执行的时候,主要是用到了列式存储和动态位图索引,比如前端筛选条件的时候,会生成一个sql,我们这个sql其实是计算男性,年纪再18到26岁间的广东用户,总结起来就是广东年轻靓仔,这里我们会解析这个sql,然后对这些条件进行按列 位图化计算,比如这里的男性标识为1女性标识为0,然后这里的年龄会根据条件对用户进行区分,比如18到26岁的,我们满足条件的标记为1,不满足条件的标记为0,同理区域也是这样,这样的话,如果要计算条件的组合就变成了位图的与操作了。速度会有很大的提升。
我们看下画像分析的效果,在3台TS5,24核cpu,64G内存,1亿条的记录,6维的下钻统计1.25s,画像分析2.7s,10个维度的透视分析大概耗费3.4s。总体来讲,这里面主要有这些经验,针对游戏分析场景定制化,画像的判断条件不会太复杂,如果太复杂,我们的jit翻译机器指令处理起来会比较麻烦。使用分布式列式MR结构,用到了列式存储以及动态位图索引,最后是JIT的sql编译加速机制。
3. 实时多维分析-TGDruid
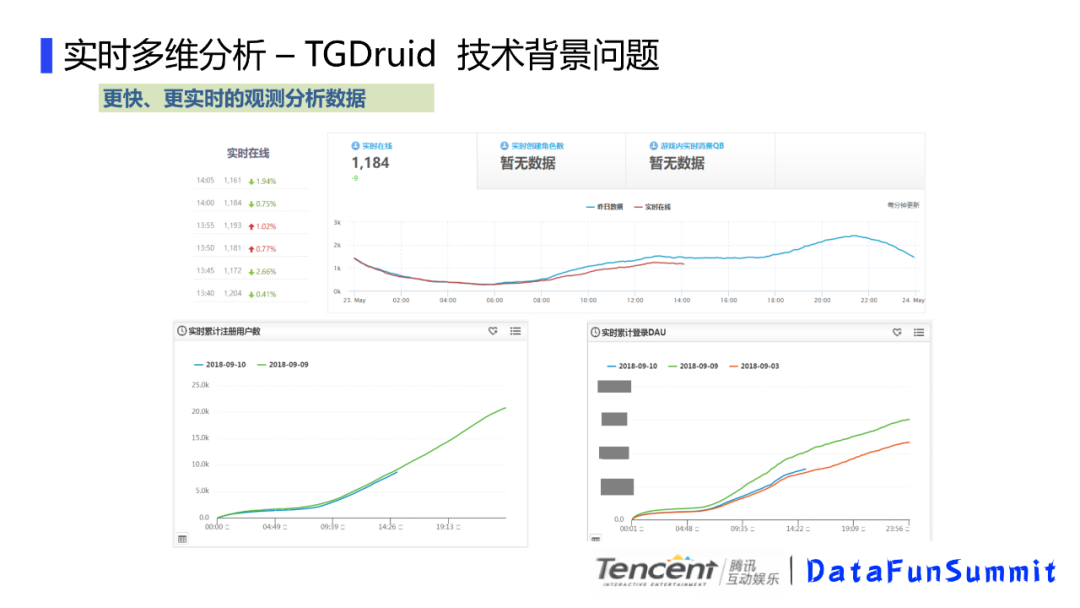
我们先看下实时多维分析的技术背景,其中一个述求就是要更快更实时的观测分析数据,比如我们的实时在线,实时创建角色数,实时DAU,实时收入,这些数据尤其是在新游戏刚刚上线,或者有活动节点的时候会比较关心。我们前面说到的一般是按照游戏整体玩家用户来看的,而另外一个述求是针对某个用户群体的一个实时数据跟踪,比如我们观察注册用户在当天的用户在线时长分布,或者针对大R用户的观察当天对局或者副本相关的实时表现,这些对也是精细化运营的一个述求。或者,我们通过实时在线或者充值,能对当天的整体数据进行实时预测,通过和目标进行对比,方便进行相关的运营决策。这些都需要涉及到实时多维分析的相关技术。
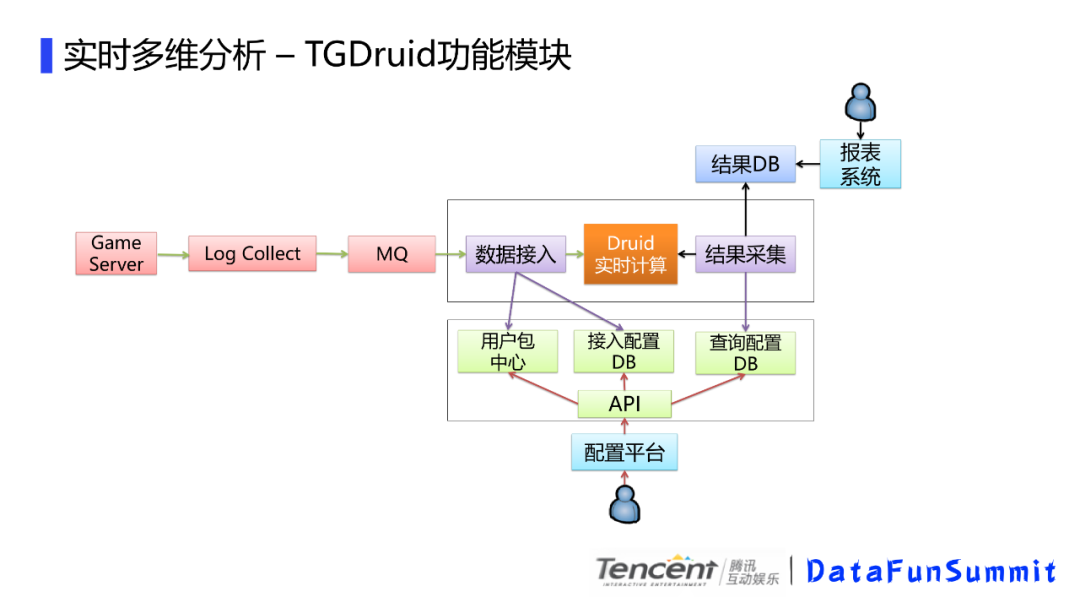
游戏服务器是上报日志的来源,通过日志采集模块,我们把实时数据会缓存到消息队列,比如kafka,pulsar,然后会经过数据接入模块,这里面主要是一些数据实时ETL,目前主要是用storm和flink来开发的,这里会去读取接入配置db,然后通过用户包中心的标签来筛选感兴趣数据输入到druid进行实时计算。druid的计算是纯内存的,如果你要查询历史数据,比如一周前的数据,你必须把一周前的segment分区加载到内存,这样的话会大大增加内存的消耗,而我们常见的查询其实都是当天的实时数据,所以,我们这里的druid内存加载限定只加载了2天的数据,那如何把历史数据也保证能查询到呢,我们这里通过定时去采集当前的数据,存储再关系型数据库,比如这里的mysql,来方便报表系统的展示,这样如果要查询一周的数据,直接去结果db查就可以了,druid的内存使用就大大降低了。
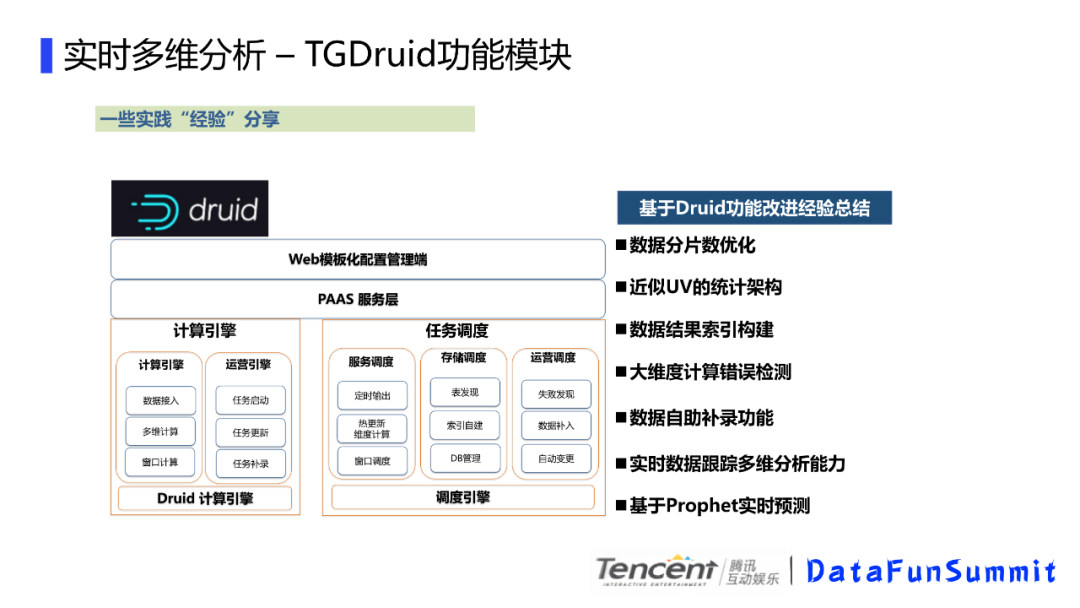
我们主要还是基于开源的那套来做,改造不是特别多,我们主要是在配置化上下功夫,不需要开发,简单的配置就可以实现实时多维计算,通过web配置可以直接启动任务的etl和调度任务,保证数据的快速接入。目前我们的接入一般在5分钟内完成,就是说,如果你需要看某个感兴趣的用户包,只需要再我们的web端配置下就好了。我们的计算引擎提供了很多服务,数据接入,任务启动更新补录等,我们的调度引擎,支持表发现,自助的维度创建,窗口调整,自动失败发现,数据补入等功能。这里有些经验和大家分享,一个是druid的数据分片的优化,我们有些数据比如天累积的用的是天分区,固定窗口的计算用的是小时分区,根据场景来调配,整体的资源消耗会有一些降低。主要是druid 的分区间的交换是有时间缓冲的,会导致时间缓冲内的内存消耗是翻倍的。我们有大维度计算错误检查,这里主要是有些数据接入的时候,如果配置错了,把对象当成了维度,数据就发散的特别厉害,这样会很容易造成OOM,这块我们接入的时候添加数据探测,这种情况会做一个提示。还有数据补录,实时计算一般是有时间窗口的,比如我们10分钟后到的数据会被舍弃,数据的晚到会导致数据统计不正确,我们提供了自助补录,可以把web下发任务重跑。以及后面的基于Prophet的实时预测,主要是基于当前实时数据,预测当天结束时间点的数据,给运营提供参考。

我们后续的一个规划是这样的,基于这三个引擎,我们进行大数据生态化和体系化改造,然后进行开源协同,再分析引擎科学化和预测决策化上下功夫,同时数据科学实验室部分我们目前也投入到增强分析和jupyter平台的一些开发中。希望在科学实验室上有些数据落地。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“大数据分析” 就可以获取《大数据分析专知资料》专知下载链接








