成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
大数据分析
关注
5514
大数据分析是指对规模巨大的数据进行分析。大数据可以概括为5个V, 数据量大(Volume)、速度快(Velocity)、类型多(Variety)、价值(Value)、真实性(Veracity)。
综合
百科
VIP
热门
动态
论文
精华
精品内容
《基于战术区块链提供数据来源以支持战场物联网和大数据分析》美海军2022最新94页论文
专知会员服务
76+阅读 · 2022年12月13日
【开放书】《经济与金融数据科学》,357页pdf,欧盟委员会联合研究中心,Data Science for Economics and Finance
专知会员服务
41+阅读 · 2022年3月24日
【WWW2021】对众包系统的数据中毒攻击和防御
专知会员服务
21+阅读 · 2021年2月22日
【调查研究】人工智能在预防与治疗新冠状病毒中起到多大作用?
专知会员服务
61+阅读 · 2020年3月10日
网络流量监测与分析大数据综述,A Survey on Big Data for Network Traffic Monitoring and Analysis
专知会员服务
65+阅读 · 2020年3月5日
【KDD2019|讲座推荐】药物发现与开发的数据挖掘方法:Data Mining Methods for Drug Discovery and Development
专知会员服务
69+阅读 · 2019年12月11日
【北京智源大会2019】活体高时空分辨率成像以及大数据分析,北京大学分子医学研究所教授陈良怡
专知会员服务
18+阅读 · 2019年11月22日
【CCF优秀博士学位论文奖-2019】大规模图数据处理系统的设计与实现,清华大学朱晓伟
专知会员服务
51+阅读 · 2019年11月8日
参考链接
父主题
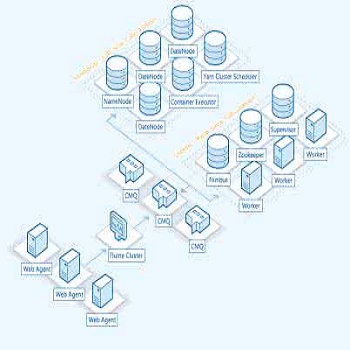
大数据
子主题
机器学习
资源管理
数据获取
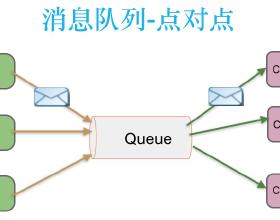
消息队列
海量数据处理
大数据相关应用
搜索引擎
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top