腾讯游戏业务竟然是这样利用低代码平台的 | ArchSummit

在 2020 年 11 月 13-14 日落地的 ArchSummit 全球架构师峰会 2021(深圳)上,我们邀请到了腾讯 IEG 数据产品开发组负责人叶鑫林来分享他们的低代码实践。此次分享中他着重介绍了低代码平台的设计理念,如接口元数据自动注册、SQL 赋能、基于 Mock 的前端快捷配置等,希望对你有所启发。
当大家谈到低代码的时候,常常只会想到逻辑可视化的平台、UI 可视化的平台,但是低代码还有更多的可能,我们还可以引入很多其他模块,例如,数据处理、接口、测试、人工智能等等。今天我将基于数据处理、接口、逻辑可视化,以及 UI 可视化这四方面来展开分享,并阐述我们案例中低代码平台中所有子平台之间是如何协作的。
低代码可以解决哪些业务问题?
假设有这样一个场景,当我们需要统计腾讯某游戏业务的城市登录人数,并且需要提供可以运营或可以检索的页面。
一般的开发流程是这样的,首先将任务派发给数据开发,基于大数据的方案统计登录人数,接着找到后台开发进行数据接口开发,然后寻找前端人员进行 Web 页面开发。
如果基于低代码的方案来实现,我们希望这些任务可以由一个非开发人员来独立完成。他可以在数据平台进行数据统计,在逻辑可视化平台完成接口开发,然后在 UI 可视化平台配置界面,最后整体交付这个需求。当然,要实现上述过程,我们还有很多问题要解决。
例如,当统计每个城市的登录人数的时候,登录信息日志一般只有 IP,并不会显示城市,这使得产品人员不得不将 IP 转换成城市,但这有很大的难度;其次,当数据平台输出数据之后,如何将它转换成接口?最后,即使有了接口,非开发人员还需要知道前端调用的接口参数、输出以及对应到的 UI 等等。
上面的这一切,对于一个非技术人员来讲比较困难。
这里一共有三个问题需要解决。
首先,是否存在强大的 SQL 可以提供给用户,这个 SQL 可以直接将 IP 转换成城市?
其次,当有了原数据之后,是否可以直接给到接口?是否可以针对传统的 CURD 的方法直接生成接口?
最后,当有了接口之后,UI 平台是否可以简化,不需要进行复制粘贴。
那么针对这三个问题,我们采用了以下这套方案。
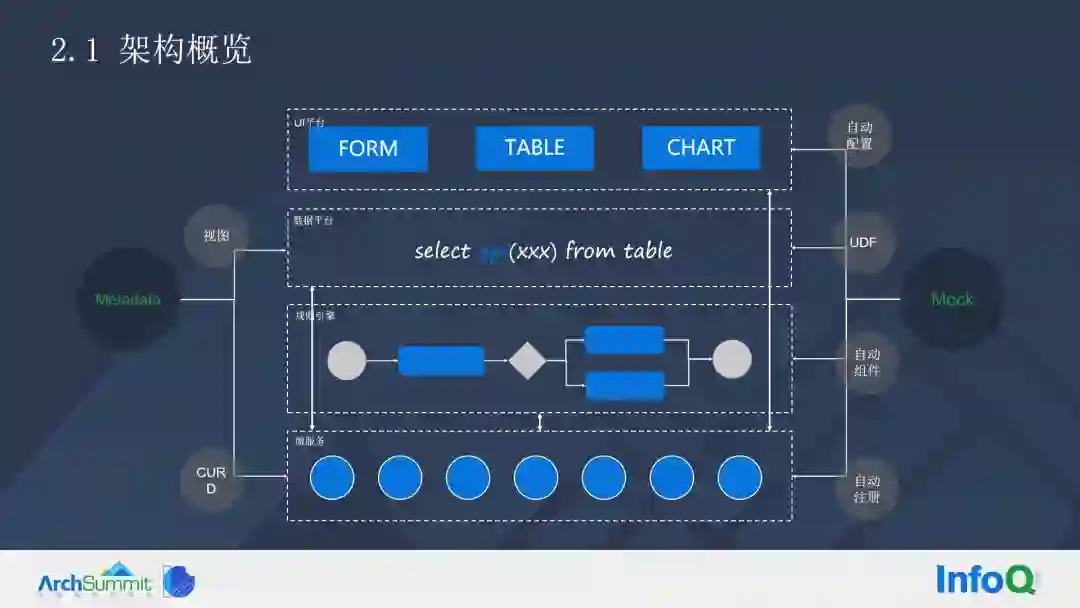
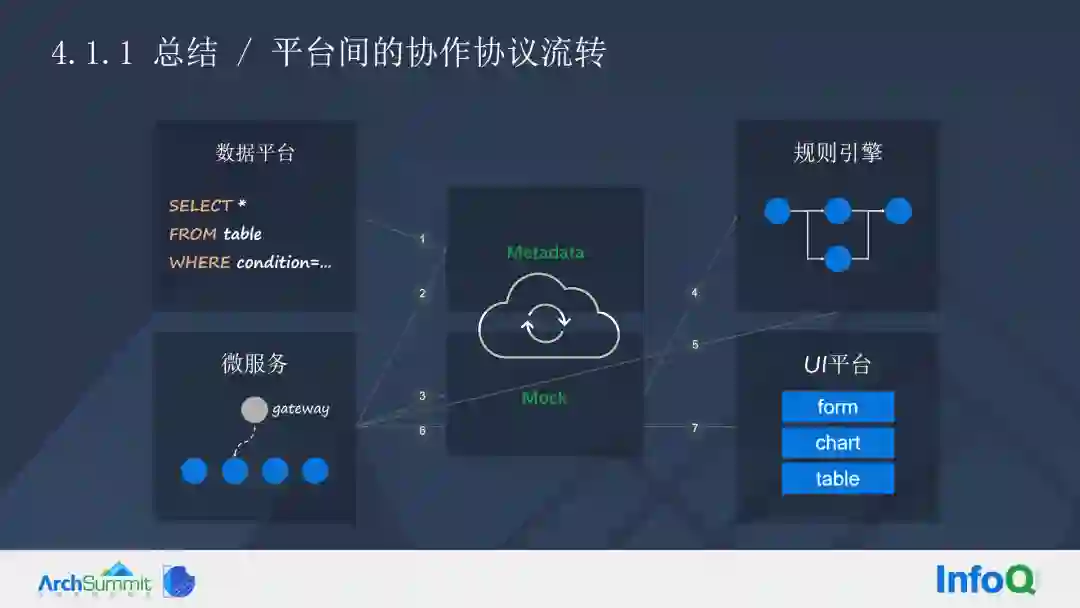
这套方案的整体架构,包含四个部分,第一层是微服务底座,中间是逻辑可视化,再向上是数据平台,最上层是 UI 平台。所有的基底都是微服务。
这里我们首先引入本方案中两个比较重要的概念——元数据和 Mock。

元数据包含了数据的存储、表、字段等元信息,大家都比较熟悉,这里不深入阐述,但是本方案中的 Mock 与业界稍微有些不同,业界通常使用 Mock 来做开发联调和单测。
比如,当后端的接口没有开发完成的时候,它可以通过 Mock 将请求打到 Mock CGI,然后将返回接口传递过来;或者是当我们并不希望触发真实的请求,可以在 CI/CD 里进行单测(如下图所示)
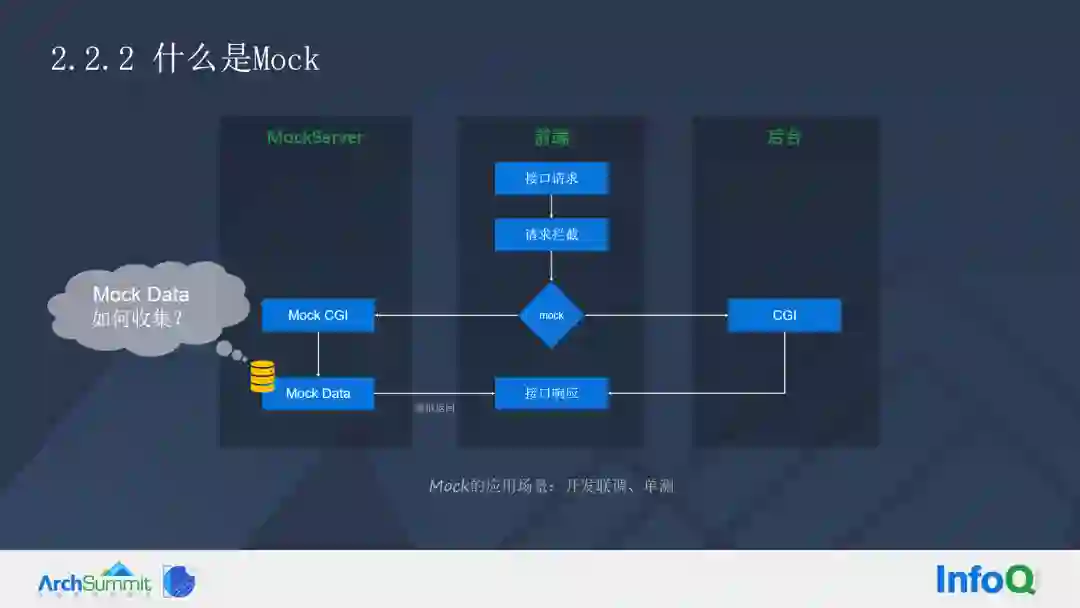
不过这将带来另外一个问题,那就是 Mock 如何进行收集,我们都知道,很多接口不可能都依靠人力输出。
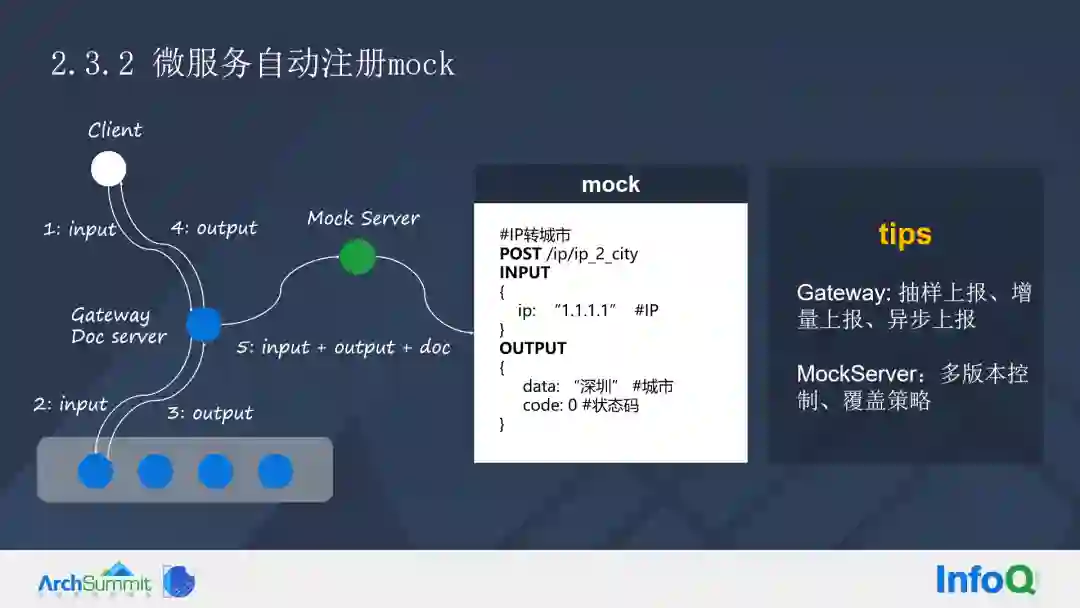
腾讯的方案是:首先用户的请求作为输入,接着经过网关,网关将 Input 传递到整个微服务,然后网关拿到返回结果,接着网关会把结果传递到客户端,这个时候请求已经完成了。
接下来将 Input、Output 以及微服务的接口注释,推荐给 Mocks server,Mocks server 会进行清洗,得到标准的 Mock 的数据(标准 Mock 数据包含用户的请求方式、地址、输入以及输出)。
这里会有一些性能相关的难点,采集任务不能影响微服务的性能,一些常见的解决方案已贴在上图 Tips 中,比如,在这个网关里面需要进行抽样上报、增量上报以及异步上报等。
假设我们需要拉取一份数据,目前开发人员已经开发了拉取数据源的接口(接口已经部署在微服务),这时候如何生成 Mock?
首先我们通过反射拿到接口的注释,接着拿到参数,然后通过注释匹配。当然我们会先对这一份注释进行清洗,然后得到字段对应中文名的 TV 对,接着尝试匹配。如果匹配不上,它会有一个单词库,再次尝试匹配,直到拿到中文名为止,最后我们会得到一个标准的 Mock 自动化的方案流程。
经过这样一套流程,所有接口一旦经过调用,我们马上经过自动化采集,得到了所有接口 Mock。接口的请求,参数的上传,以及返回的结果我们都了如指掌。
那我们该如何使用这些自动采集的 Mock 数据呢?接下来一起看看低代码的第三个问题。

首先,我们需要更强大的 SQL。
一般来讲,当 SQL 无法满足计算逻辑的时候,我们就需要找开发人员开发一个 UDF,比如一个"IP 转城市"的函数,它会注册到 SQL 的执行引擎,你便可以使用这个函数了。但这样的方案是需要开发人员进行开发支持的。
低代码的方案应该怎么设计呢?我们提供 SQL 的方案是将微服务注册进执行引擎,整个引擎是 Spark SQL 的引擎,它会代替开发人员发起微服务的调用,会上传参数,然后再调度到微服务里面。Mock 帮助人工进行了最快速的 UDF 的注册,无需要任何成本,马上便可以通过 SQL 调用微服务,
例如,当我们使用 SQL 调取微服务的时候,首先需要知道地址、输入参数、以及返回值。这个接口返回 data 和 count,为什么你接口返回城市一定是 data?这些都是一些我们在进行注册的时候需要做的工作。
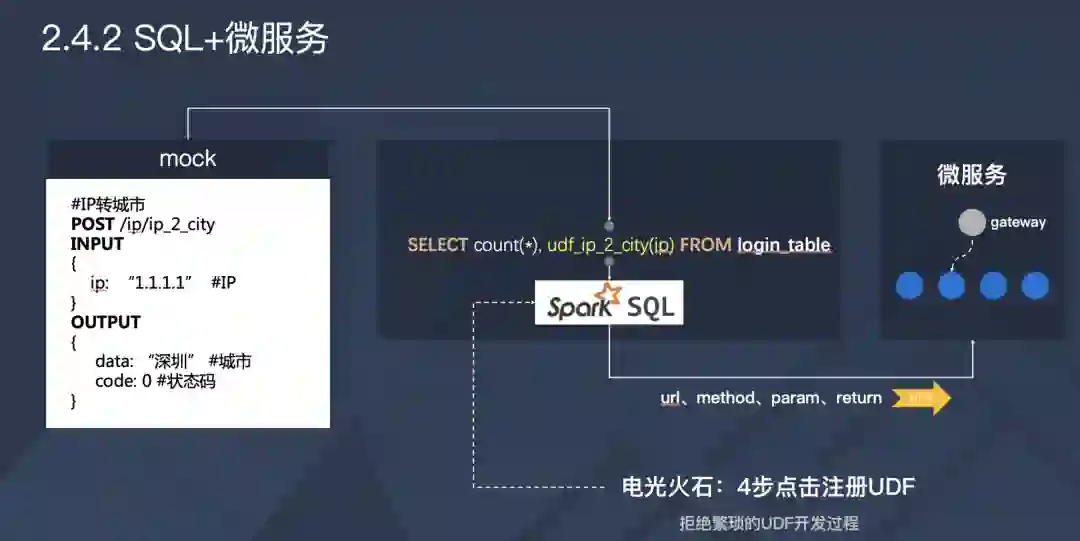
这里有个视频,大家可以看一下。
例如选择一个获取黑名单的任务,它马上注册微服务,这个 UDF 是一个微服务,它就可以被 SQL 使用,大家可以判断他是不是黑名单了。
整个过程中,用户只需要非常简单的四个步骤,SQL 马上就可以具备微服务的调度能力。
此处也会有一些性能上的挑战,当使用 Spark 调用微服务的时候,性能会出现一些问题。因为如果使用非常传统的调动方法,它是一个串行的过程,那么我们这里提了可以供大家参考的方案。
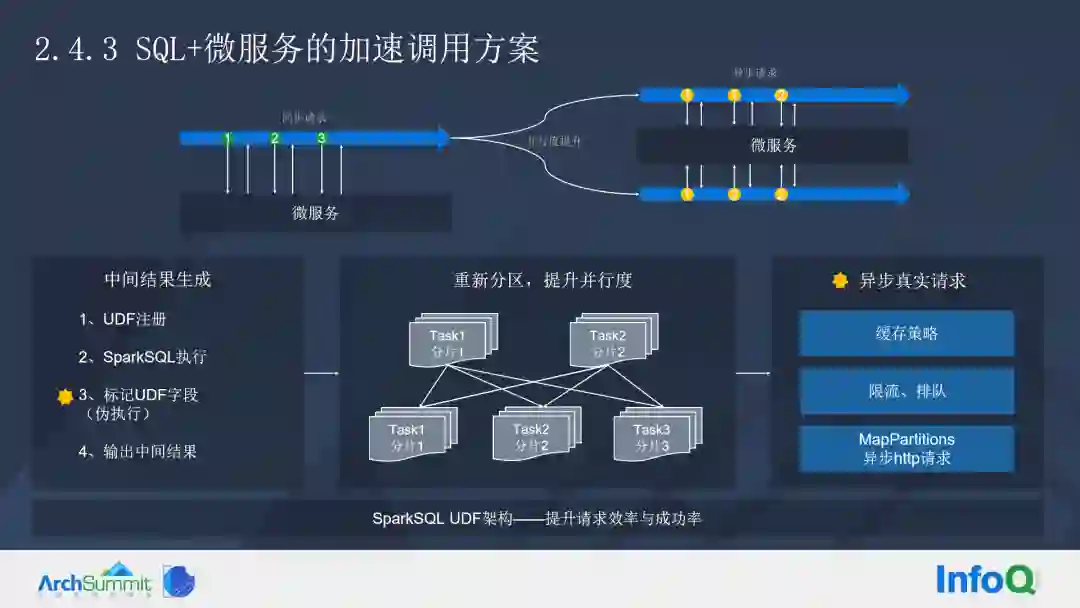
UDF 注册之后,我们会直接执行 SQL,但不会马上调用 UDF,将它标记起来,呈现出来是一个伪执行的状态,SQL(无 UDF)产生一个中间结果,我们会将这个中间结果重新分区,把它打得更散更平均,这样后续每个分区执行分派到的 UDF 任务个数将会更近平均,避免一些数据倾斜的情况。最后在我们伪标记的 UDF 的基础上,我们会启用整个的异步调度方案,使用异步 HTTP 完成微服务调用,并配套相应的缓存以及限流的策略,整体提升请求效率和成功率。
截至到这里,我们通过 SQL+ 微服务提供了更强大的 SQL,通过了 UDF 的快速注册,提供给产品人员非常简洁的操作。这个时候,第一个问题就被完美地解决了。
接下来分享第二个问题的解决方案,CURD 是否还需要开发接口?
我们通过数据平台产生的数据之后,接着需要 CURD 接口。业界有很多生产 CURD 接口的方案,腾讯的 APIJSON 开源方案,它可以做到零代码生成接口和文档,并且整个生成过程是自动化。
当企业有元数据的时候,马上就可以获得接口,不过这个接口暂时不能满足运营系统的需要。这时候需要引入规则引擎。
我们可以将接口进行简单地编排,采用了 BPMN2.0 协议实现了同步和异步双引擎,因此整个规则引擎可以做任务流的事情。
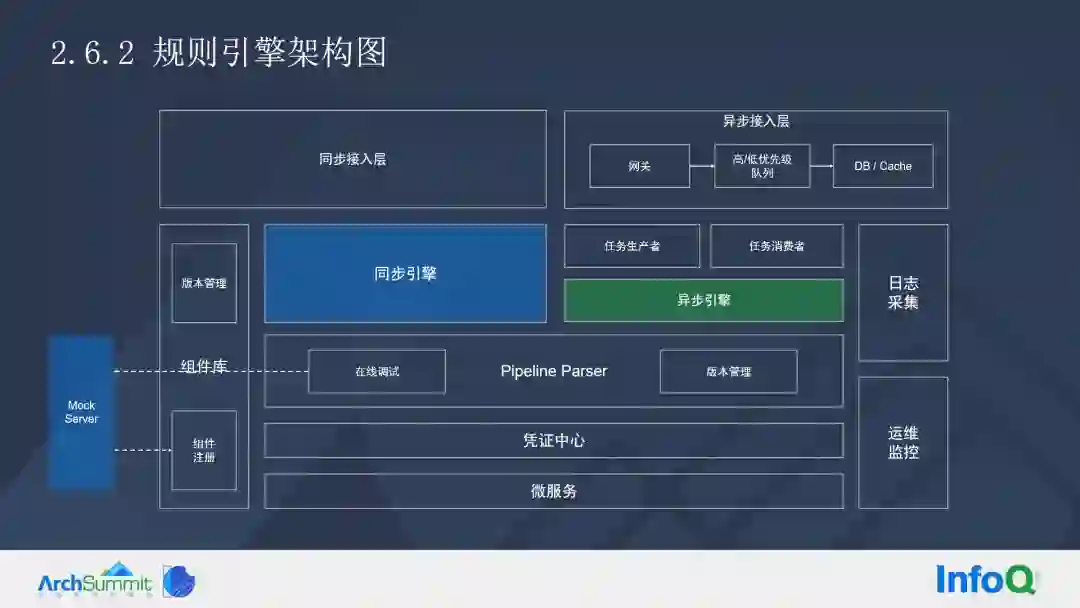
Mock 可以帮助整个组件的快速注册,因为每一个节点都是微服务,这种 Mock 节点就可以快速注册,同时整个微服务在调试的过程中,我们生成了任务工作流,当逻辑执行完之后,它也会马上去进行 Mock 注册。
当然,当我们有了简单的 CURD 过程,我们可以选择编排一些参数校验。比如,对时间做要求、对权限做要求,当然也可以做一些错误返回等的编排工作,最终通过规则引擎生成完整的查询接口。
那么经过了这一步骤,我们就具备了 SQL 和接口,这时候可以将接口放到页面呈现。
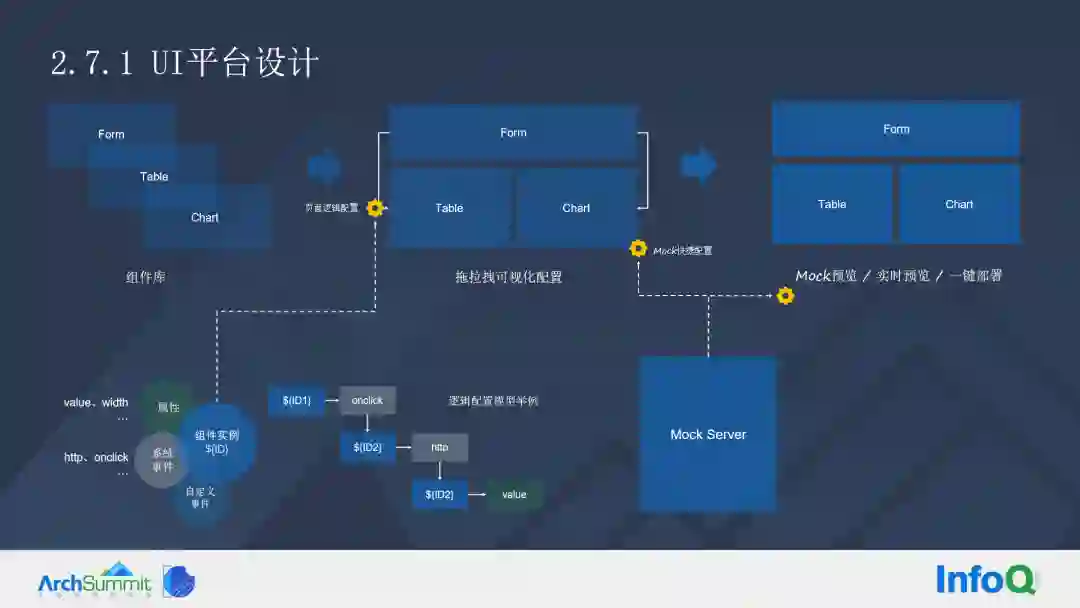
上图是我们UI平台的架构,跟常规的低代码平台大同小异,这里介绍两个点:通信逻辑模型和Mock加速前端配置
首先是通信逻辑模型,这个模型解决了组件与组件的通信与行为相应,当一个组件拖出来到页面后,会马上分配一个唯一实例 ID,每个实例都会有属性,会有系统事件或自定义事件。
比如我们现在要实现点击搜索按钮后表格组件自动从后端重新获取最新数据并呈现。
那么,我们配置的逻辑大概是这样的:按钮实例的 OnClick 事件可以配置触发表格实例的 HTTP 时事件。Table 实例的 HTTP 的事件实现拉取数据以后,将它写进 Value 里面,实现了整个 Table 的数据刷新输出。
其次是 Mock 加速前端配置,有了 Mock 之后,在配置前端的时候可以省去了很多复制粘贴的工作。当我拉取一个表格,可能有很多字段,复制粘贴将会非常崩溃,这里有 Mock server 的快捷配置以及预览,当用户配置完之后,便可以马上预览,来检查你的配置是否和你的预期。
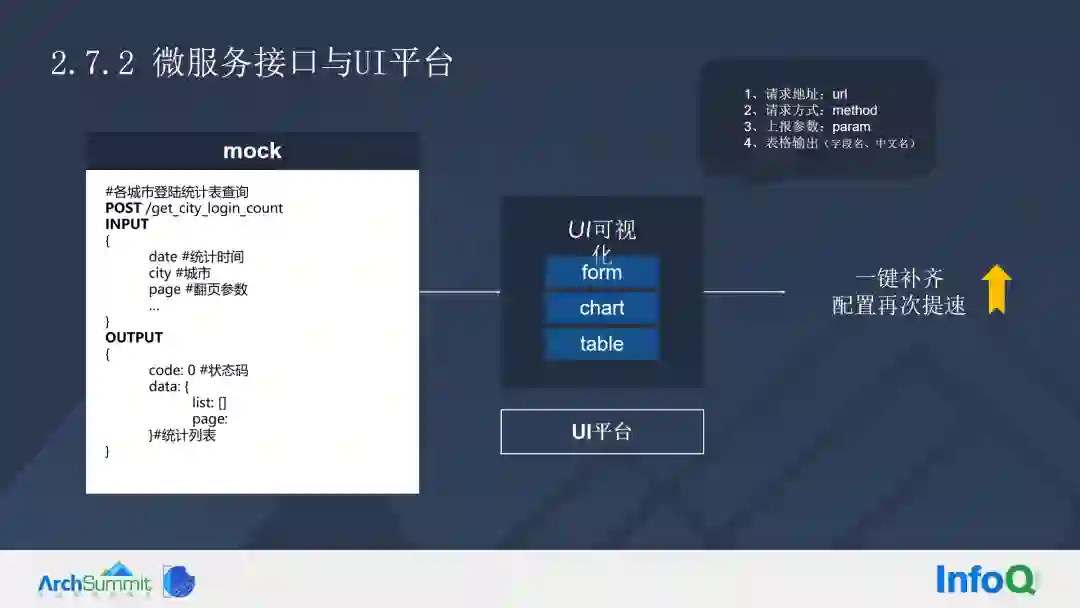
我们是如何通过 Mock 快速地配置?
例如,当我们配置表格的时候,地址、请求方式、上报参数、表格输出等均需要配置。这对于一个配置人员来讲,其实成本非常高的,尤其是当碰到非常极端的案例的时候,例如,当你碰到具备 20 多个字段的时候,它的配置工作将会非常令人崩溃。
我们的方案是这样的,一起来看一下这个视频。
首先拉取一个表格,然后选择一个微服务地址,然后自动地获取参数。
所有的上报参数,其返回都会全部自动填上,以及基于 Mock 的实时预览,马上就可以拥有。
通过使用 Mock,平台也可以透过 Mock 平台进行真实的预发布环境的预览。
今天的主要三个挑战都已经解决了,有了这样方案之后,其实对于产品人员来讲,可以搞定很多内容。
腾讯游戏低代码的整个数据平台大概支撑了 3000 个任务,后端沉淀的原子接口有 1000 个,整个逻辑可视化模板有 200 个,页面 600 个等等。
在我们的平台上层,支撑着很多的应用。比如客服系统,大家知道王者荣耀的客服系统往往非常复杂,它会有邮件赠送福利。假设用户 30 天没有领取,这个邮件就会顶替掉,但是有些人会打电话投诉要求补发福利,这个时候客服需要检查日志去检查是否已经领取?
这一系列流程之前都是依赖人工,但是现在当我们将平台传递给客服的时候,他们利用这套平台配置逻辑就可以轻松搞定。
当然,在平台的上层,我们也支持运维安全 SOAR 以及安全监控的一些事情。
说完我们的实践,谈谈我们的展望。
今天我分享的两个关键点是元数据和 Mock,我们经过这两个元素的频繁交互,达成了整个平台的融合。
回顾整个平台架构,我们发现平台的所有东西都是微服务,并且所有的微服务都可以变成 API 使用,整个 SQL 也变得非常的强大。整个数据平台输出的数据都有 CURD,也贡献回了微服务,微服务里面的 CURD 同样贡献给规则引擎。这是一种相辅相成的关系。
最后一部分是关于我对低代码未来趋势的一些思考。现在低代码百花齐放,有非常多的低代码平台,业界需要一些规范,以及如何保证低代码平台的质量。
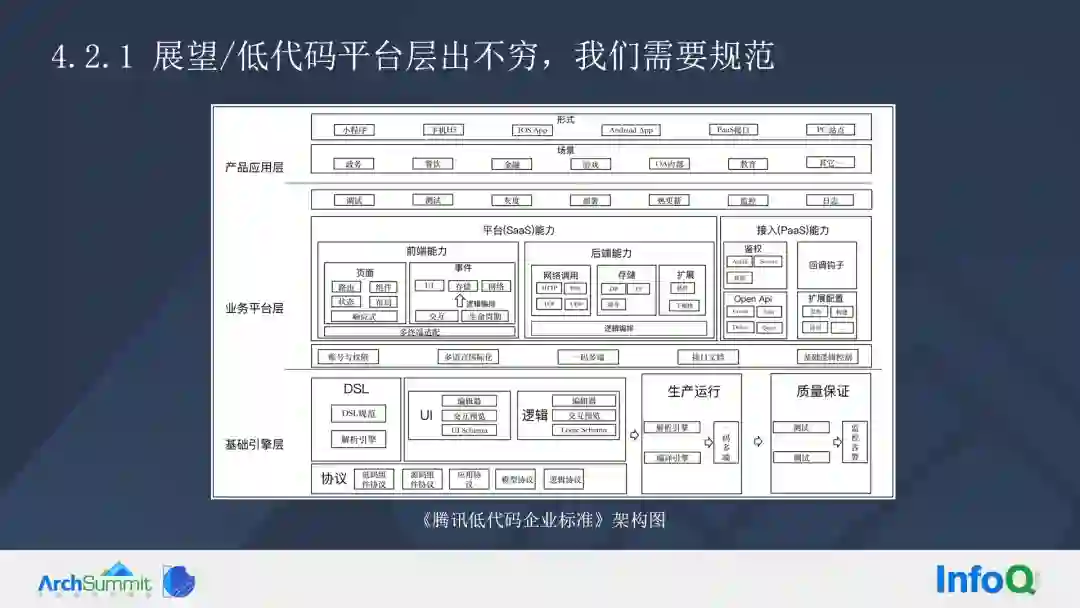
上图是我们整个的腾讯的低代码架构图。
首先,我们整个腾讯提出了一些方案——腾讯有 UI 可视化逻辑,还有 DSL 整个语言,生产环境、开发环境以后,便会有配套的前端以及后端的 SARS 的能力。整个的低代码可以用来配置 Web 和 App,可以通过提供一些 Pass 的服务,也可以通过 Open API 或者钩子做很多事情。
当然这里介绍两个执行引擎。作为低代码,我们有一个基于 Schema 的解析引擎和编译引擎。解释引擎可以用 Schema 直接执行,编译引擎更多是从性能角度考虑。编辑引擎可以根据 Schema 转成可运行的代码,希望大家可以了解一下。
其次,再谈一下 Schema 与 DSL 的这样关系,DSL 可以通过 Pass 模块转换成 Schema,Schema 是可以被解释引擎和编译引擎识别的。在面向用户的使用方式上,我们支持整个可视化编辑,也就是说,大家可以在页面进行拖拉拽。当然如果你不喜欢,也可以无风险、无损失地切换到 DSL。
最后,对于一些中小企业来说,当企业选择了低码平台时候,便马上会被这个平台绑架。因为企业的所有逻辑全部配置在了低代码平台,由于其他平台无法识别 Schema,所以根本无法迁移。
目前腾讯低代码提出了一个思想——Schema 可以不一样,因为不同的执行引擎或编译引擎是不同的,它们的 schema 规范必然也不一样。但是 DSL 是更上层的语言,就是大部分数据都支持标准的 SQL 一样,我们可以抽象 DSL,站在整个低代码的行业的角度与立场去抽象 DSL。在我的平台里面刚才我们讲了,其实 Schema 是可以转 DSL 的,当他真正地想从平台导出的时候,它其实就可以把 Schema 转成 DSL 打包带走,然后在另外一个平台里面导入。
我相信如果大家都这样做,低代码绑架业务的问题就迎刃而解,整个低代码的生态会变得更加健康。
这是我今天的分享,谢谢大家。
嘉宾介绍:
叶鑫林,腾讯 IEG/ 公共数据平台部 / 基础数据平台中心 / 数据产品开发组负责人、腾讯低码 OTeam PMC。多年大数据开发、前后端开发、算法设计经验,熟悉游戏领域的研发环境,主导了多款平台类产品(光谱、天眼、规则引擎、数据平台等)的设计与研发。目前带领团队投入低码平台的研发建设,致力提升易用性与研发效率。
在 4 月 24-25 日,ArchSummit 全球架构师峰会即将落地上海,数字化转型是大趋势,不管是金融转型,还是汽车产业数字化转型,制造业数字化转型,一定会涉及到企业的产品形态,这里面包括市场定位和可行性的诸多因素,还有 ROI 评估模型。
除了在业务上的转型,在技术上也需要底层技术支持,例如微服务架构实践,数据库管理,前端开发,质量提升等等,共同保证项目落地。基于这些需求,ArchSummit 架构师峰会上邀请了国内较有经验的专家来分享各自的案例,帮助大家少踩坑,多复用,快速解决工作中的问题,了解更多请点击阅读原文或扫描下方二维码即可参与。

点个在看少个 bug 👇



