汽车之家机器学习平台的架构与实践


文章作者:田董涛、王若愚、方矩
编辑整理:Hoh
内容来源:作者授权
出品平台:DataFunTalk
导读:汽车之家机器学习平台是为算法工程师打造的一站式机器学习服务平台,集数据导入、数据处理、模型开发、模型训练、模型评估、服务上线等功能于一体,提供一站式全方位的机器学习建模流程,快速打造智能业务。本文主要介绍汽车之家机器学习平台的架构和实现细节,以及业务在平台上的应用,希望能为大家提供一些参考。
主要内容包括:
背景介绍
机器学习平台
平台成效与应用
平台展望
01
背景介绍
汽车之家是国内最早的将互联网与汽车产业深入捆绑的汽车服务平台,在2005年成立初期以垂直互联网介入汽车行业,迅速做成国内规模最大的汽车垂直网络媒体,并逐渐发展为"车媒体+车电商"的1.0模式。2016年以"数据+技术"打造车金融、车内容、车生活以及车交易的数据平台2.0模式,以便为用户和客户之间创造更有效的连接。目前,汽车之家利用 AI、大数据及云,以流量、销售线索、内容及数据等赋能汽车生态系统中各个参与方,加速迈向智能平台3.0时代。汽车之家机器学习平台在智能平台3.0的背景下应用而生,通过广泛支持自然语言处理、图像分析、语音识别、视频分析、推荐、搜索、广告等场景的 AI 服务,有效提升了汽车之家 AI 的应用效果,扩展了 AI 的应用范围,提高了用户看车,买车,用车的体验。
机器学习领域,最重要的三个环节如下图,包括数据处理,模型训练和服务部署,每一环节包含的内容很多,都可以单独拿出来做一个平台。
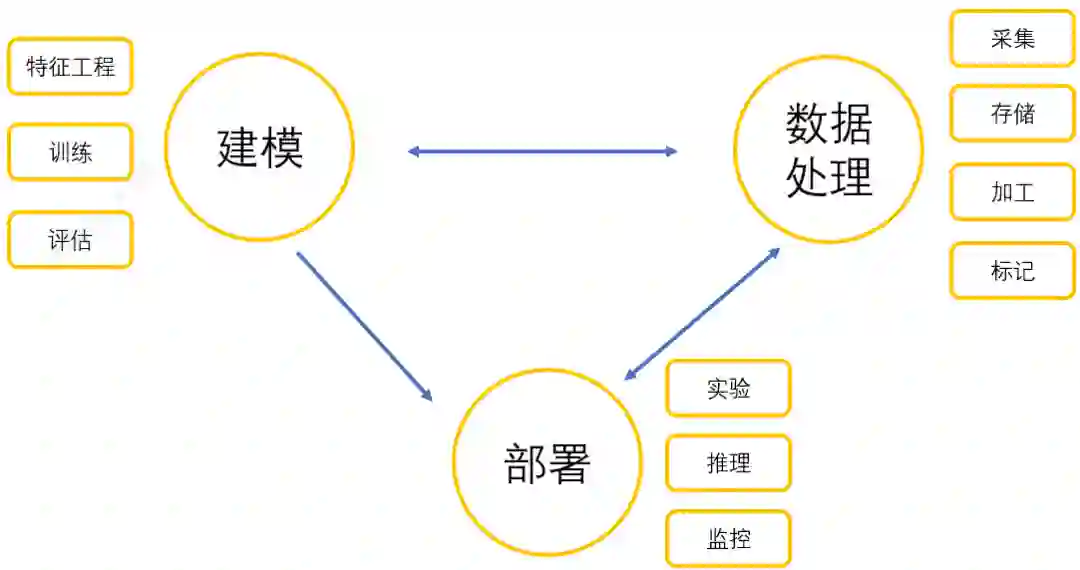
在早期,之家内部算法团队在各自的服务器上进行机器学习的训练和服务部署,造成了小作坊式的工作局面,各自重复着这三个环节来支持业务。在开始算力规模小的时候,这种小作坊方式保证了工作的灵活与创新突破,但是随着业务的增加和算力的增长,逐渐显示了这种方式的局限性。主要体现在两个方面:
昂贵的计算资源不能得到有效的调度,公司的投入产出效益越来越低。因此基于这种局面,公司急需一种平台化的方式来统一调度计算资源。
各个业务线包括团队内部,业务不同,用的数据不尽相同,大部分的工程技术人员和业务人员都聚焦在业务领域的特征提取,算法选择,参数调优和模型验证上,因此一个方便高效的可视化建模平台,对于降低用户的机器学习学习曲线、提升工作效率显得尤为重要。
由此汽车之家构建了自己的机器学习平台,该平台同时支持深度学习和传统机器学习建模、可视化建模、统一的计算资源和存储资源管理、统一的部署平台,力求达到以下目标:
开发通用化:一次开发重复使用,避免重复造轮子,提高工作效率。将算法工程师们从繁重的脚本开发工作中解放出来专注于算法效果的提升。
建模极简化:用户仅需根据自己的需求在页面上通过拖拽的形式完成数据的导入,预处理,模型建模与评估等流程。这样即使是对模型算法不甚了解的产品运营同事在经过简单的了解后也可轻松上手,依据自身需求完成简单数据处理或者建模任务。
数据可视化:可以支持输入数据可视化,数据分析可视化、计算图可视化、训练过程可视化、模型效果可视化。
02
机器学习平台
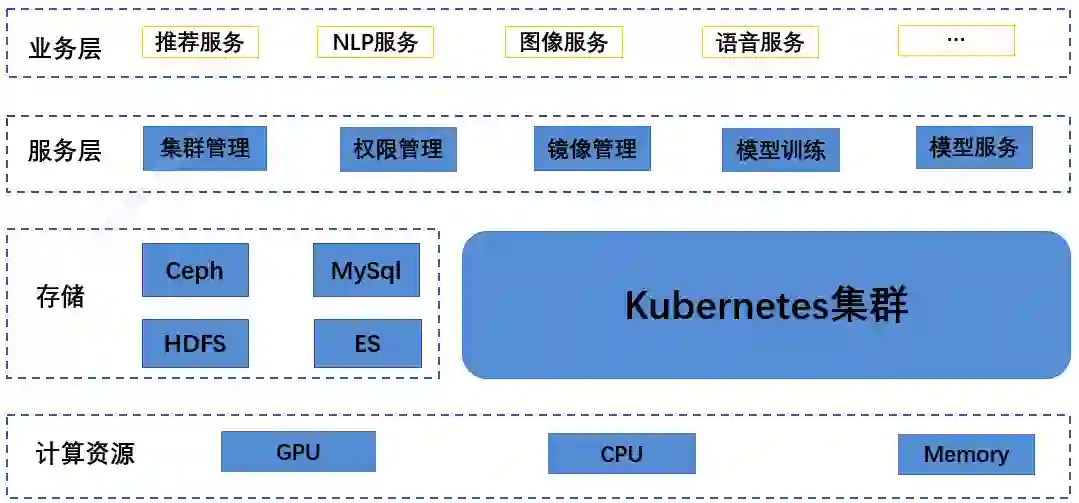
1. 整体架构
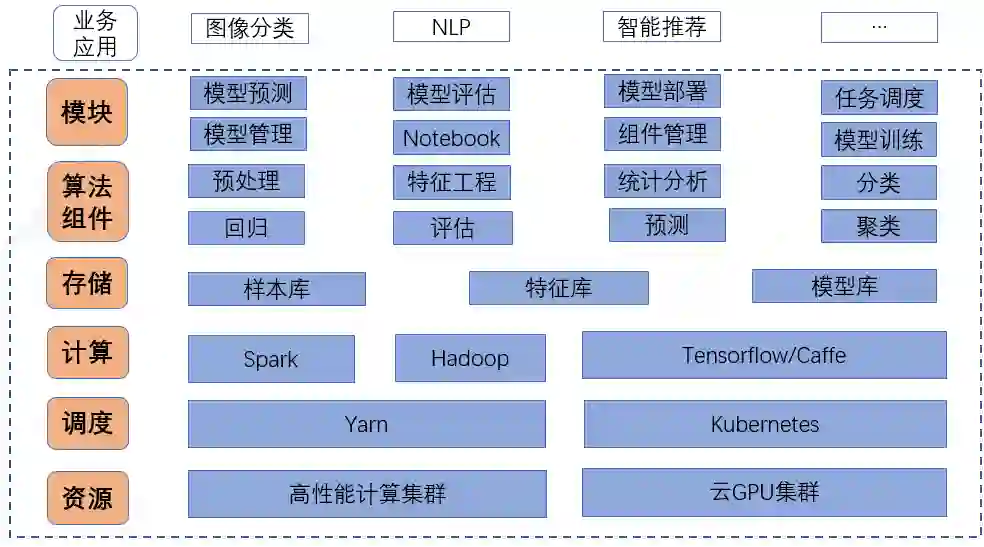
计算资源包括高性能 CPU 集群和云 GPU 集群,高性能 CPU 集群用于训练和部署传统机器学习模型,云 GPU 集群用于训练和部署深度学习模型。
基于资源的不同,机器学习和深度学习底层采用了两种不同类型的架构方式,机器学习训练使用 Spark 做计算,通过 Yarn 来调度计算资源;深度学习训练使用 K8s 做调度,支持主流的 Tensorflow、PaddlePaddle、MxNet、Caffe 等深度学习框架,并且支持单机和分布式训练。
存储层包括业务端通用的样本库、特征库和模型库,主要存放在 Hive 仓库和 HDFS 上。
平台抽象了算法组件包括机器学习的数据预处理、特征工程、统计分析、分类、聚类、回归、评估、预测等100+个组件。
模块对外提供了模型训练、模型评估、模型预测、模型管理和模型部署功能,满足了算法人员的模型训练和部署模型服务的需求,同时还提供了交互式编程 Notebook,提高了开发人员的开发效率。
2. 机器学习建模流程

算法框架:
由于 Spark 选择内存存储输入数据、处理中间结果、和存储最终结果,在大数据的场景中,很多计算都有循环往复的特点,像 Spark 这样允许在内存中缓存输入输出,上一个 job 的结果马上可以被下一个使用。因此 Spark 有着高效的分布式计算能力。
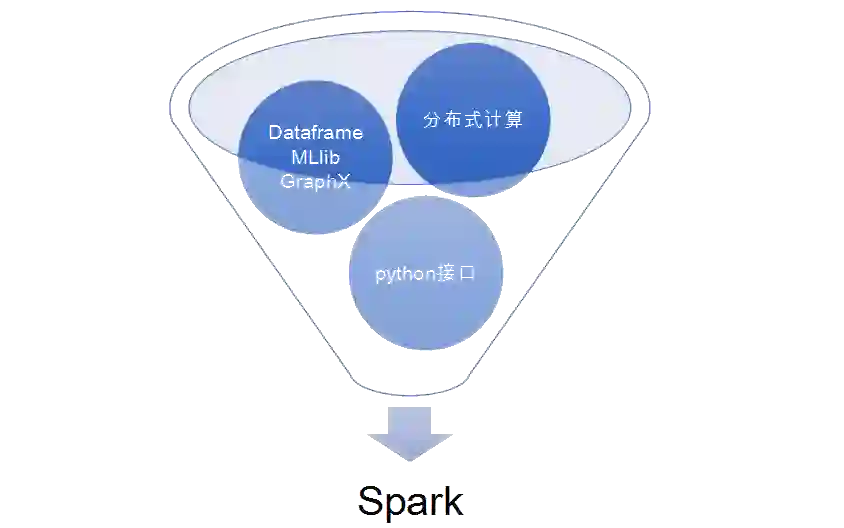
此外 Spark 提供了更多灵活可用的数据操作,比如 filter、union、join 以及各种对 key value pair 的方便操作,甚至提供了一个通用接口,让用户根据需要开发定制的数据操作。Spark 本身作为平台也开发了 streaming 处理框架 Spark streaming,SQL 处理框架 Dataframe,机器学习库 MLlib 和图处理库 GraphX。更重要的是 Spark 可以提供面向 python 的开发接口,提高了开发效率。因此我们选择 Spark 作为我们平台的算法框架。
算法端流程:
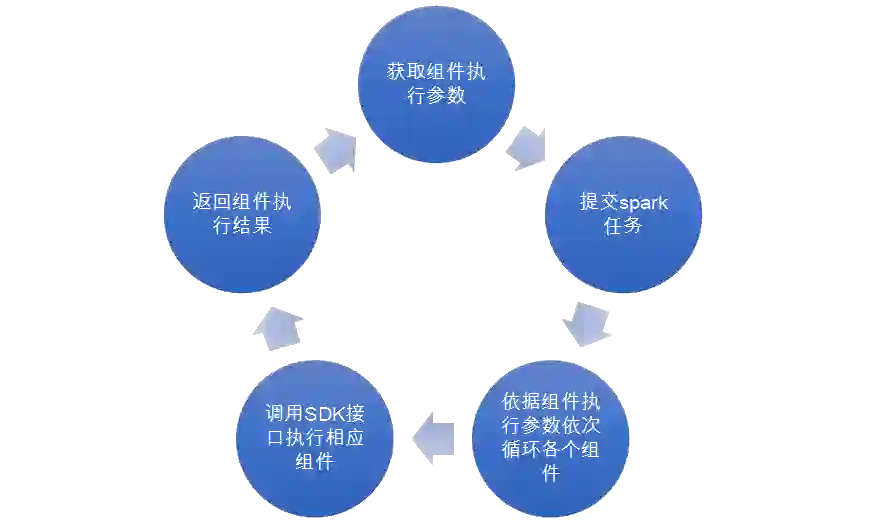
后端将用户构建的建模流程及配置的模型参数包装至 json 调用算法端接口
算法端通过 spark-submit 提交一个 Spark 任务
ML Engine 负责这个任务的执行,在 Driver 端会从 json 中获取当前试验的流程关系及对应的参数。这些组件将依次运行,涉及 RDD 相关的操作时会提交到 Spark Executor 进行并行计算
3. 深度学习训练
以上为机器学习平台-深度学习部分的逻辑架构图,平台支持了深度模型的训练和服务部署功能。为了更好的管理计算资源,需要将所有的计算资源集中起来,尤其是 GPU 机器,做到按需分配,使资源的使用率尽量接近100%,这样才能提高我们的生产力,节约公司成本。这就需要一个容器管理系统来管理我们的 GPU 集群。
① 技术选型
我们调研了 K8s 和 Yarn。Yarn 作为大数据平台标配的资源调度器,确实有很多优点并且比较成熟,但是鉴于 Yarn 对在线服务的支持较弱,新版的 Yarn 才支持 GPU 调度,存在稳定性风险。相对于 Yarn,K8s 现在社区比较强大,对 GPU 卡的调度有很好的支持,支持服务的自动化部署,服务的运维成本低,我们选择用 K8s 做为平台的容器管理系统。
存储:
模型训练的训练样本数据大多存储在 HDFS 和 Hive 表中,平台实现了与 Hadoop 集群的互通。任务在运行前需要拉取数据到容器内部,为了保证数据的持久化存储和可扩展性,需要外部存储系统来支持,我们选择了 Ceph。使用 Ceph 主要有以下几个好处:
可以支持较大的数据规模,较大的样本数据可以达到几百 G 甚至到几 T,当遇到集群节点故障,任务的 Pod 重启,还能继续访问数据进行训练。
Ceph 是一个统一的分布式存储系统,该系统拥有很好的性能、可靠性和可扩展性。在单机训练中主要用到的是 Ceph 的块存储 RBD,在多机分布式训练中需要共享训练数据用到的是 CephFS,任务运行结束,存储资源根据用户选择决定是否释放。
调度:
通过构建 K8s 的 GPU 集群,来统一调度 GPU,CPU 和内存资源,通过 Docker 保证环境完全隔离,任务之间不受影响,任务结束,占用的资源随即得到释放。同时基于 K8s 可以做灵活的调度策略。如现在集群有多种类型的 GPU 卡,用户可以根据实际情况选择卡的类型,具体做法通过对 GPU 节点打 label 的方式实现,根据节点类型标记对应的 label,启动任务配置 nodeSelector 实现卡类型的精确分配;由于 k8s 分配最大资源是整个物理机的资源,有些复杂的训练任务在单机多卡方式下,为了能分到更多的 GPU 卡进行训练,在训练集群使用 K8s 的节点亲和性调度 nodeAffinity,可以使训练任务集中调度。K8s 支持通过插件的方式进行自定义调度,如果现有的调度方式不满足需求,可以通过自定义调度实现更灵活的调度策略。
② 建模训练
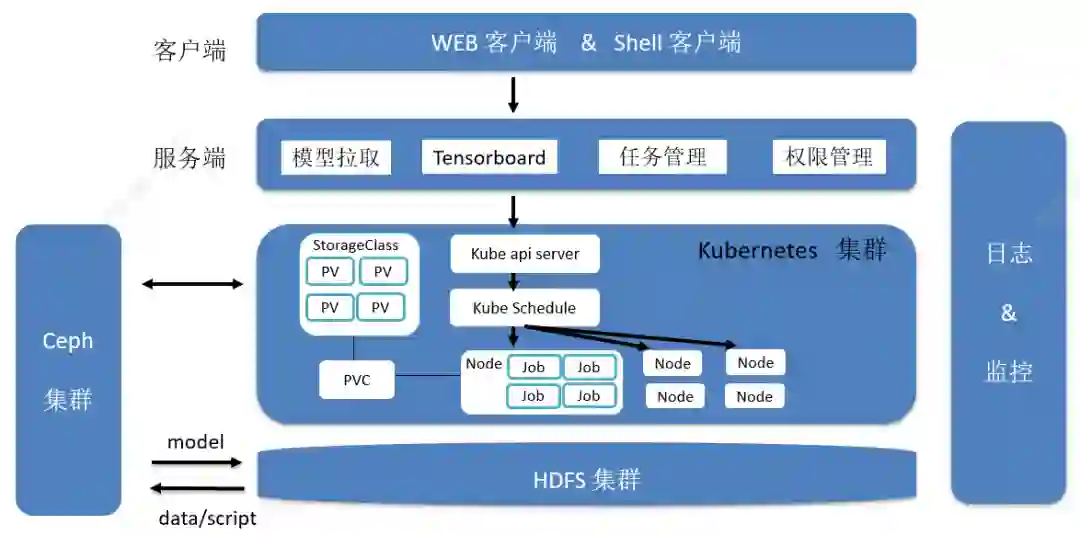
深度学习训练的细节如上图,用户通过 WEB 客户端或 Shell 客户端提交训练任务,服务端拿到用户提交参数,组装好 K8s 资源和配置 yaml 文件,提交到 K8s 集群。在启动任务之前,会通过集群里的 StorageClass 创建好 pvc 对象,作为训练任务挂盘对象,如果用户使用的 Tensorflow 框架训练,平台支持启动 Tensorboard,方便查看训练的效果和进度,此时也会创建 Tensorboard 的负载对象 Ingress 和 Service。前面准备工作做完,K8s 会根据用户指定的 GPU、CPU、内存及卡类型参数在集群里通过调度分配训练任务到合适的节点,没有资源会处于等待状态,直到有资源可以调度启动任务。启动任务后,先进行容器环境的初始化过程,主要包括配置 Hadoop 相关权限,训练数据和训练脚本的拉取,初始化工作完成后训练任务开始运行,训练过程中,平台支持导出中间的训练结果,训练结束后,最终结果会自动输出到用户指定的输出目录。
③ 深度学习分布式训练
如果训练时间长或者样本规模大,超过单台服务器能力时,需要支持分布式训练。以 Tensorflow 分布式为例,一个 TensorFlow 分布式程序对应一个抽象的集群,集群 ( cluster ) 由工作节点 ( worker ) 和参数服务器 ( parameter server ) 组成。工作节点 ( worker ) 承担矩阵乘、向量加等具体计算任务,计算出相应参数 ( weight 和 bias ),并把参数汇总到参数服务器;参数服务器 ( parameter server ) 把从众多工作节点收集参数汇总并计算,并传递给相应工作节点,由工作节点进行下一轮计算,如此循环往复。
tf.train.ClusterSpec({"worker": ["worker0.example.com:2222","worker1.example.com:2222","worker2.example.com:2222"],"ps": ["ps0.example.com:2222","ps1.example.com:2222"]})
这些内容用户不需要进行配置,只需要在 Tensorflow 组件参数中设置 ps 和 worker 的个数,在启动命令里通过获取 PS_HOSTS、WORKER_HOSTS、JOB_NAME 和 TASK_INDEX 环境变量初始化相关参数,就可以快速启动分布式训练任务,这样简化了用户使用分布式训练的工作量。
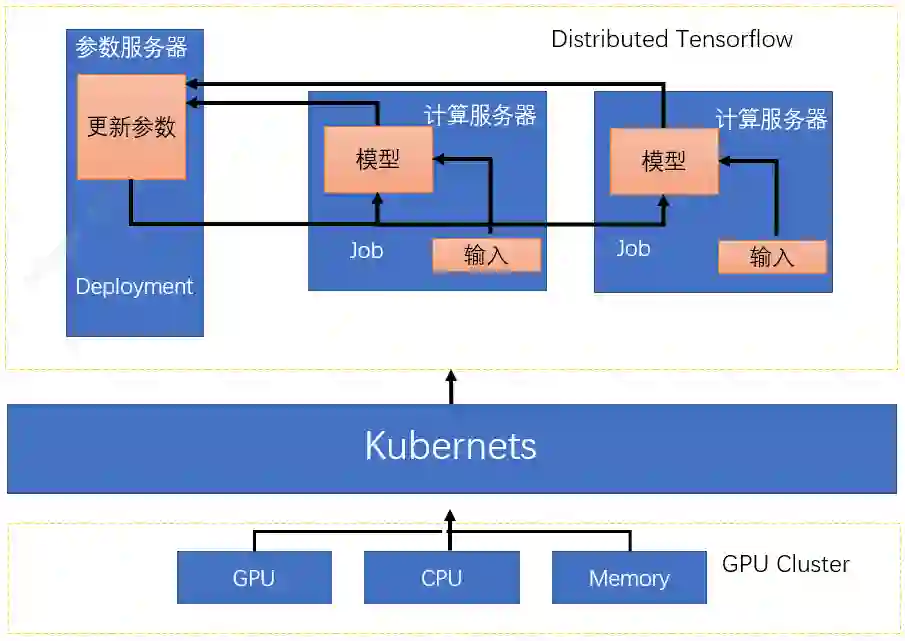
平台构建分布式任务的具体实现方式时这样的,如定义了 m 个 ps,n 个 worker,在 K8s 集群里定义 n 个 Job 对应为分布式任务的 worker,n 个 Job 共享同一份数据,然后定义 m 个 Deployment 对应为分布式任务的 ps,把每个角色的网络连接方式放置在 ps 和 worker 的环境变量中供用户初始化参数使用,任务结束后,训练结果从 worker-0 导出到 HDFS 中,计算资源释放。
4. 模型部署管理
平台上训练的机器学习模型通过 PMML 格式导出,统一存放在 HDFS 中进行维护,通过平台一键部署预测服务。对于深度学习模型,平台提供了 ModelZoo 功能,支持用户上传模型文件,通过平台提供的公共深度学习框架的 Serving 镜像启动预测服务,同时平台也支持用户用自己构建的镜像来部署预测服务,这样简化了算法工程师部署预测服务的流程,同时也不失灵活性。
借助于 K8s 对服务部署的支持,平台提供了服务的伸缩,更新,使服务流量增长时能快速实现服务的扩容,同时提供了服务的动态伸缩功能,能做到服务流量突增时实现服务的自动扩容,服务流量下降时自动缩进实例,使服务端的 GPU 得到一个合理的利用。
03
平台成效与应用
针对之家算法工程师的实际业务场景需要,深度学习平台支持了目前主流的深度学习框架 Tensorflow,Caffe,PaddlePaddle,PyTorch,Keras,Kaldi 等,涉及到图像、语音、NLP、视频、推荐、广告等多个业务领域。如语音的 DeepSpeech 模型,图像的 ResNet、AlexNet、EfficientNet 模型,NLP 的 bert 模型,推荐广告的 DeepFM、DCN、DIEN 模型。
平台上线后,机器的供需矛盾得到很好的解决,机器利用率得到很大的提升。上线前算法工程师可用的机器只有申请的有限的几台机器,上线后可用的是整个集群的资源,即来即用,不用释放,平台对集群里的机器资源使用进行了全方位的监控,能实时查看计算资源的使用情况。同时平台很好的支持了模型部署,线上环境隔离,多版本部署,快速启动,使机器学习服务上线效率得到很大提升。
1. 购车意愿模型在机器学习平台上的应用
作为全球访问量最大的汽车网站,如何从海量的用户访问浏览行为中发掘用户购车的意向或中意的车系车型,一直是汽车之家算法工程人员研究的重点课题。
下面介绍通过 GBDT 模型对用户的购车意愿进行预测建模。
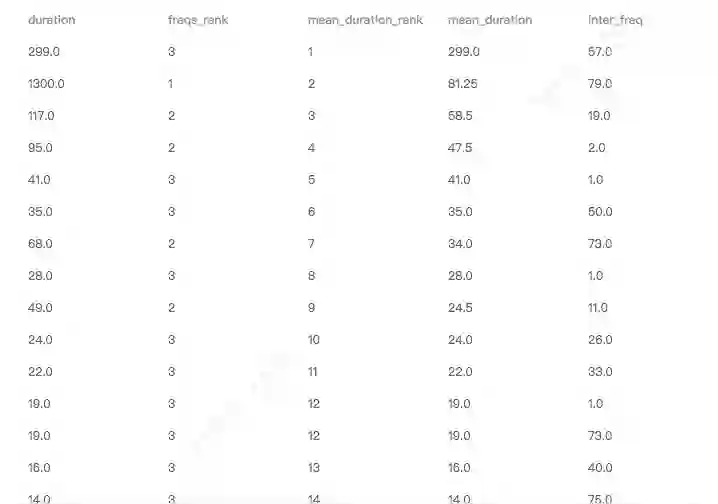
① 数据集介绍
数据截图如下:
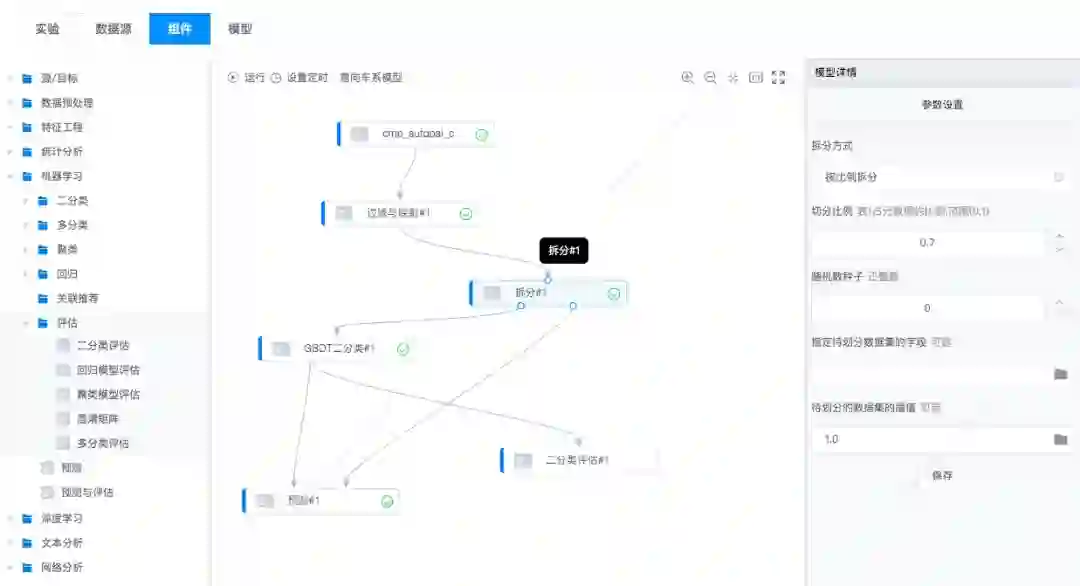
② 数据探索流程
实验流程图如下:
数据源准备
输入数据:
用户浏览行为数据集:共16503613条数据型,包括 "duration"、"freqs_rank" 等特征,"label" 为是否买车。
数据来源:汽车之家数据仓库 ( hive )
数据预处理
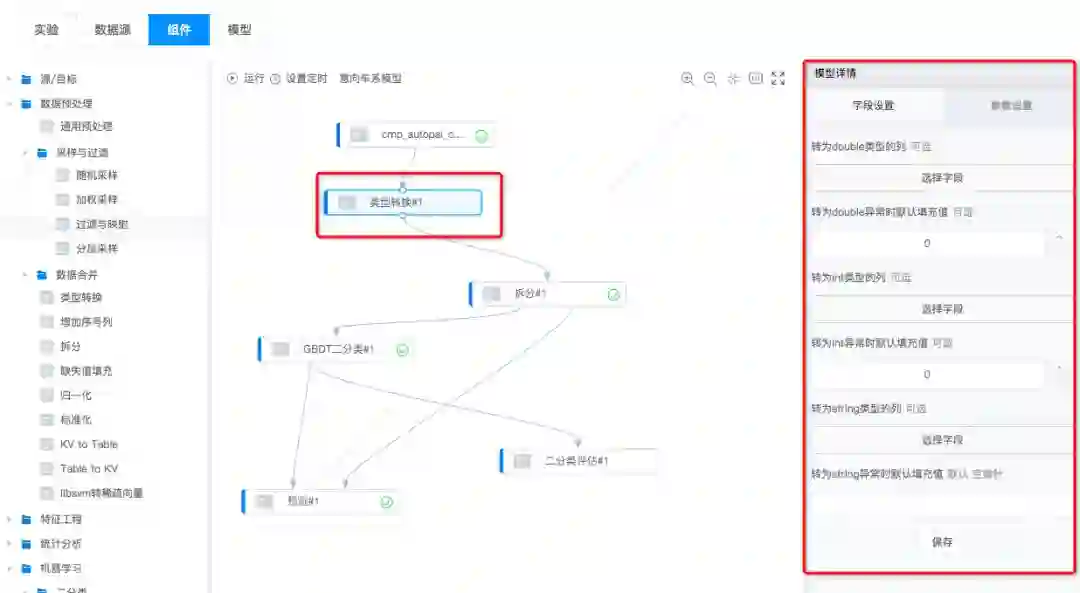
利用类型转换组建,将数据集中的 string 类型转为 float 类型方便后续的计算,再利用拆分组建将数据集划分为训练集 ( 占总数据集的85% ) 和测试集 ( 占总数据集的15% )。
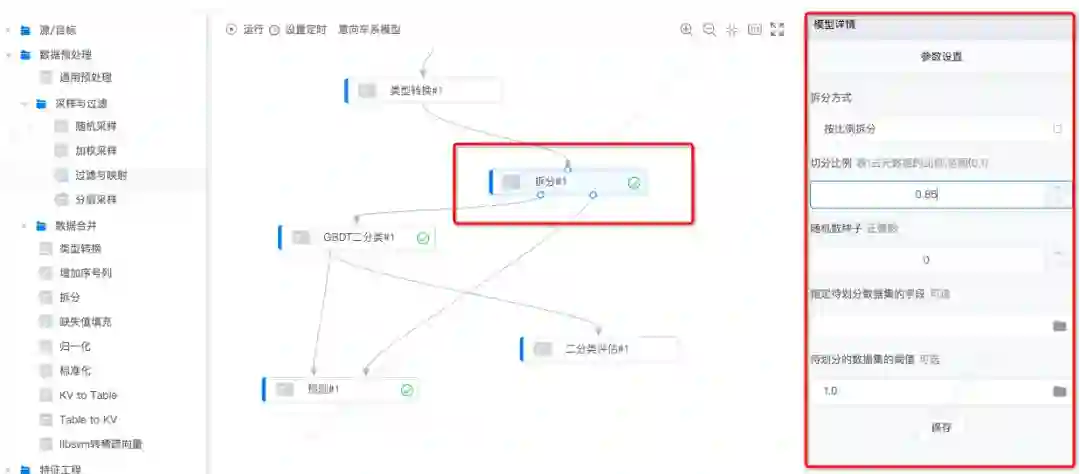
模型训练及预测
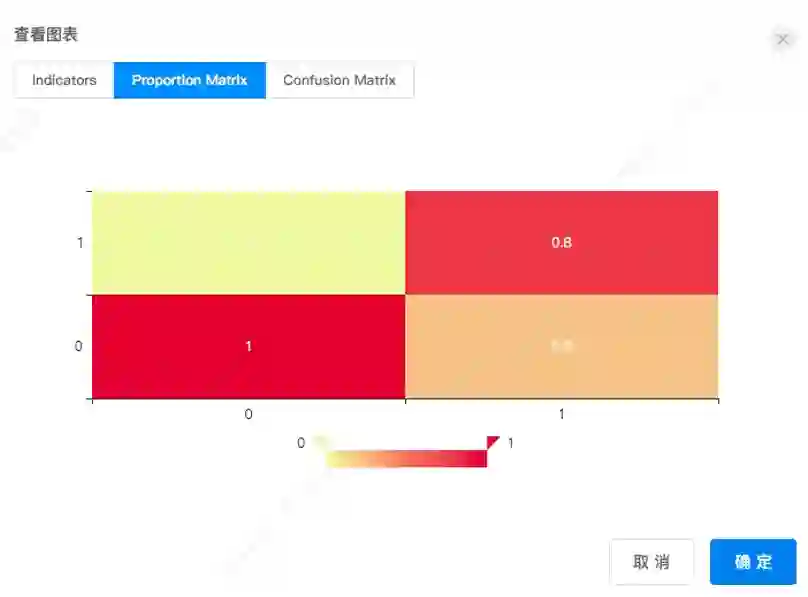
使用机器学习组建中的 GBDT 算法对数据集进行训练并生成回归模型,在预测组件中利用二分类评估组建对预测集数据进行了预测。结果如下图所示。
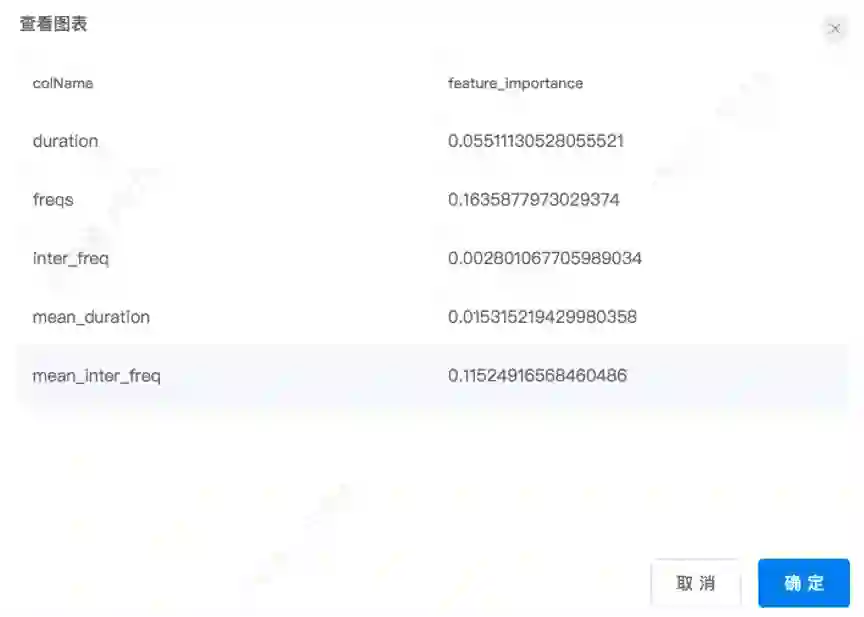
特征重要性评估
通过特征重要性评估组件对模型中的各个特征进行评估计算出该特征的重要性权重,评估结果如下图所示。
2. 推荐排序模型在机器学习平台上的应用
下面主要从推荐排序模型如何借助机器学习平台进行数据接入、数据处理、建模、训练等四个方面进行分别阐述。
① 数据接入
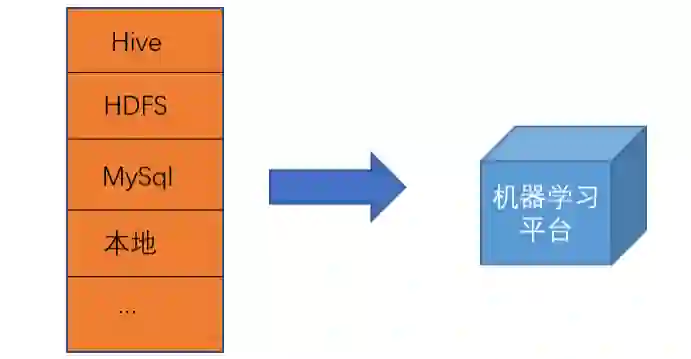
机器学习平台支持多种数据源接入,目前推荐业务的离线数据存放在 HDFS 上,实时数据通过 Flink 接入。
② 数据处理
机器学习平台对常见的数据处理方式进行了封装,不仅支持对某些特征的异常值检测、数据分析等功能,还支持对特征数据进行标准化、归一化、降维、分桶等常见的数据处理方式,同时还可以通过自定义sql的方式提供一站式的数据处理以及数据可视化分析。
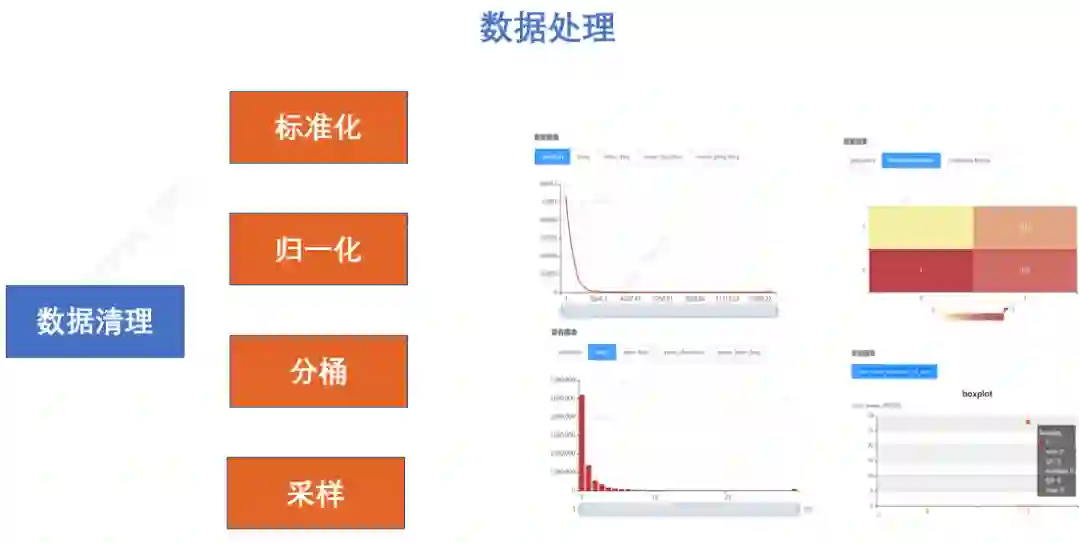
③ 建模
机器学习平台目前支持上百种组件,对推荐排序场景提供了全方位的支持。其中模型不仅支持 LR、GBDT、XGB 等传统的机器学习模型,同时还支持常见的深度学习模型,如 FM、Wide&Deep、DeepFM、DCN 等,下图将展示 online DeepFM 在机器学习上应用的实例。
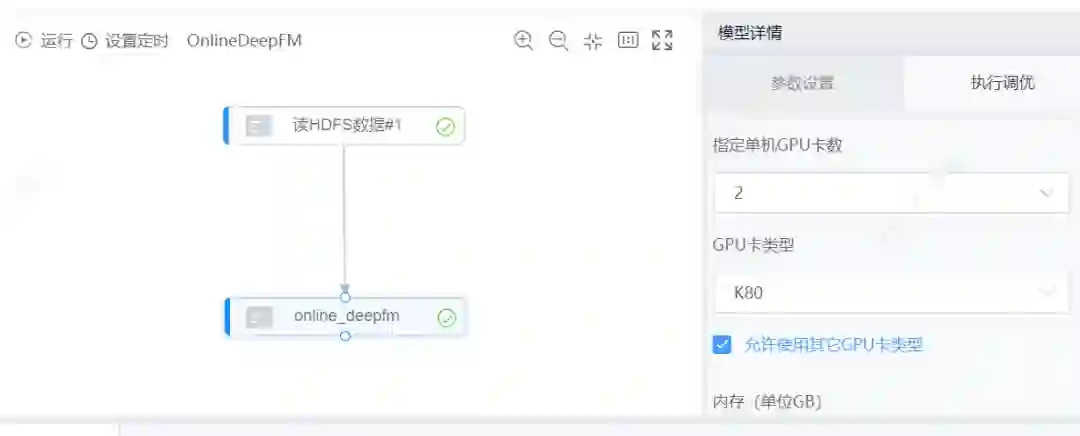
建模过程中,传统的机器学习模型可以通过自动化的调参方式进行主要参数设置,常见的深度学习模型提供了部分参数的配置,如网络层数,dense embedding 的维数,学习率衰减系数等,这为模型的训练带来很大的便利。
④ 训练
之家的推荐排序模型经历了从传统的机器学习模型 LR、xgb 到 FM 、Wide&Deep、DeepFM、DIN、MMOE 等深度学习模型的迭代演进。之家首页推荐每天会产生上亿条日志数据,经过数据清理后,训练样本数据量达到百 G 甚至 T 级别,面对如此大规模的数据,如何有效的缩短算法的训练时间成为了关键。
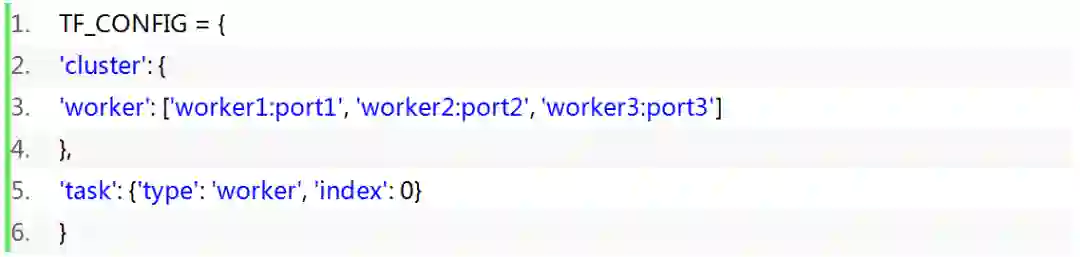
传统的机器学习模型如 LR,XGB 等基于 Spark 进行分布式的训练,训练时间在小时级别,较为可控。但是深度学习模型对于大数据量,训练时间相对较长,K80 单卡训练需要近一周的时间,V100 单卡训练需要4天。为了缩短训练时间,快速迭代模型,我们采用了多机多卡式的训练方式 ,以 Tensorflow 为例,采用 Multi Worker MirroredStrategy 的方式,Multi Worker MirroredStrategy不需要 Parameter server,只需要设置一系列的 TF_CONFIG 环境变量,这样降低了多机多卡的调试难度,实例如下:

同时机器学习平台深度学习部分可以灵活的选择训练方式以及参数设置,如下图所示:
采用多机多卡训练的方式将深度学习模型如 DeepFM、Wide&deep 等训练时间压缩在 24h 内,基本处于可接受范围内。
为了让模型能够分钟级迭代,并能实时的反馈给推荐系统,机器学习平台提供了分钟级实时训练功能,并对训练好的模型进行评估指标的验证和更新上线。实时训练的流程主要是通过 Flink 接入实时日志数据,将每十分钟收集的数据存放在 HDFS 上,然后在机器学习平台上制定定时任务,进行特征工程和模型训练,训练完毕后经过评估指标的验证判断是否进行模型更新,具体流程图如下:

机器学习平台为推荐排序提供了一站式的全流程支持,从数据处理、建模、训练、模型评估以及模型上线,实现了分钟级迭代模型。平台的建立大大提高了推荐排序模型的迭代速度,提升了算法工程师的工作效率,为之家推荐排序业务的发展提供了有力保障。
04
平台展望
1. 增加算法组件
平台经过两个版本的迭代,解决了资源利用率低和算法工作重复的问题,随着接入用户和业务的增加,对平台也提出了更高的要求。如推荐业务里,在线机器学习几乎是绕不开的话题,为了更好的支持在线机器学习,我们接下来会融入在线机器学习的组件。类似这种业务场景会越来越多,我们会根据业务需要加入更多的算法组件。
2. GPU卡共享
无论是训练任务还是服务部署,用到的 GPU 卡都是独享的,训练任务的 GPU 卡利用率一般都比较高,大部分在50%以上,部署的服务随着 TPS 的增长而增长,GPU 卡的实际利用率都不高,为了提升服务实例的 GPU 卡利用率就要提供 GPU 卡的共享。解决方式一般有两种,一种是 GPU 虚拟化,像虚拟机的 CPU 一样,目前 Nvidia 提供这种虚拟化服务,但是 License 费用昂贵;另外一种方式通过修改 K8s 的调度策略,来支持非整数卡的调度分配。后面会基于第二种方式尝试实现 GPU 卡的共享。
今天的分享就到这里,谢谢大家。
文章作者:
田董涛,汽车之家高级算法工程师。2017年加入汽车之家,汽车之家机器学习平台负责人,目前在汽车之家负责机器学习平台的架构和开发工作。
王若愚,汽车之家算法工程师。2018年加入汽车之家,目前主要从事推荐排序和机器学习平台相关工作。
方矩,汽车之家算法工程师。2018年加入汽车之家,目前主要从事推荐排序算法相关工作。