图灵奖得主 Yoshua Bengio 和 Yann LeCun 在 2020 年的 ICLR 大会上指出,自监督学习有望使 AI 产生类人的推理能力。该观点为未来 AI 领域指明了新的研究方向——自监督学习是一种不再依赖标注,而是通过揭示数据各部分之间关系,从数据中生成标签的新学习范式。
近年来,自监督学习逐渐广泛应用于计算机视觉、自然语言处理等领域。随着该技术的蓬勃发展,自监督学习在图机器学习和图神经网络上的应用也逐渐广泛起来,图自监督学习成为了图深度学习领域的新发展趋势。
本文是来自澳大利亚蒙纳士大学(Monash University)图机器学习团队联合中科院、联邦大学,以及数据科学权威 Philip S. Yu 对图自监督学习领域的最新综述,从研究背景、学习框架、方法分类、研究资源、实际应用、未来的研究方向的方面,为图自监督学习领域描绘出一幅宏伟而全面的蓝图。

全文链接:https://arxiv.org/pdf/2103.00111.pdf
1. 绪论
近年来,图深度学习广泛应用于电子商务、交通流量预测、化学分子研究和知识库等领域。然而,大多数工作都关注在(半)监督学习的学习模式中,这种学习模式主要依赖标签信息对模型进行训练,导致了深度学习模型获取标签成本高、泛化能力能力不佳、鲁棒性差等局限性。
自监督学习是一种减轻对标签数据的依赖,从而解决上述问题的新手段。具体地,自监督学习通过解决一系列辅助任务(称为 pretext task,代理任务)来进行模型的学习,这样监督信号可以从数据中自动获取,而无需人工标注的标签来对模型进行监督训练。
自监督学习目前已经被广泛应用于计算机视觉(CV)和自然语言处理(NLP)等领域,具体技术包括词嵌入、大规模语言预训练模型、图像的对比学习等。然而,与 CV/NLP 领域不同,由于图数据处于不规则的非欧几里得空间,其具有独特的特点,包括:1)需要同时考虑特征信息与不规则的拓扑结构信息;2)由于图结构的存在,数据样本(节点)间往往存在依赖关系。因此,图领域的自监督学习(graph self-supervised learning)无法直接迁移 CV/NLP 领域的代理任务设计,从而为图自监督学习带来了独有的概念定义和分类方法。
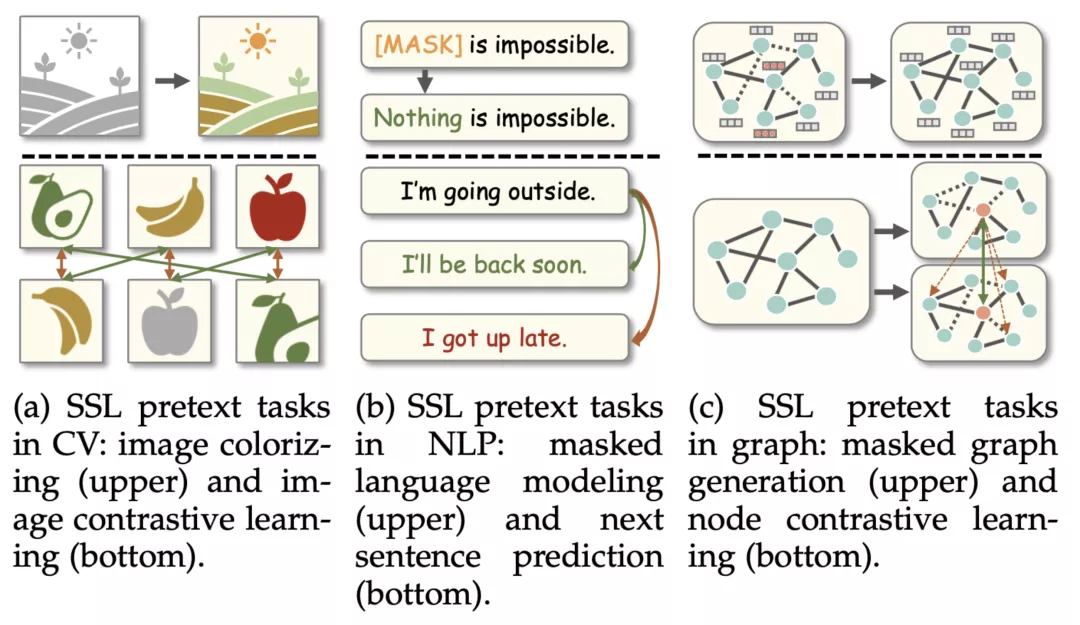
不同领域的自监督代理任务对比
图自监督学习的历史最早可追溯到经典的图嵌入方法,包括 DeepWalk、Line 等,而经典的图自编码器(GAE)模型也可被视为一种图自监督学习。自 2019 年以来,一系列新工作席卷了图自监督学习领域,涉及到的技术包括但不限于对比学习、图性质预测、图生成学习等。然而,目前缺少系统性的分类法对这些方法进行归类,同时该技术相关的框架与应用也没有得到规范化的统计与调查。
为了填补这一空缺,本文对图自监督学习领域相关工作做了综合、全面、实时的综述。本文的主要贡献有:1)以数学语言统一了的图自监督学习框架,并提供了系统的分类法;2)对现有方法进行了综合且实时更新的整理;3)统计了相关的研究资源和应用场景;4)指出了未来潜在的研究方向。
2. 核心词条与概念定义
为了便于读者理解,本文提供了以下核心词条的定义辨析:
人工标签 vs 伪标签:人工标签指需要人类专家或工作者手动标注的标签数据;伪标签指机器可以从数据中自动获取的标签数据。通常,自监督学习中不会依赖人工标签,而是依赖伪标签来进行学习。
下游任务 vs 代理任务:下游任务指具体用于衡量所学习表征和模型性能的图分析任务,比如节点分类、图分类等;代理任务指专门设计的、用于帮助模型无监督地学习更优表征从而在下游任务上取得更高性能的辅助任务。代理任务一般采用伪标签进行训练。
监督学习、无监督学习与自监督学习:监督学习指通过人工标签来训练机器学习模型的学习范式,而无监督学习是一种无需人工标签来学习的学习范式。作为无监督学习的子类,自监督学习指从数据本身获取监督信号的学习范式,在自监督学习中,模型由代理任务进行训练,从而在下游任务重获取更好的性能和更佳的泛化性。
本文主要研究图数据。图由节点集合和边集合构成,其中节点的个数计为 n,边的个数计为 m。图的拓扑结构一般用 n*n 的邻接矩阵 A 来表示,A_ij=1 表示节点 i 和节点 j 之间存在连接关系,A_ij=0 则表示二者无连接关系。对于属性图,存在一个特征矩阵 X 来包含每个点和每条边的特征向量。
对于大部分图自监督学习方法,图神经网络(GNN)作为编码器而存在。GNN 输入邻接矩阵 A 和特征矩阵 X,通过可学习的神经网络参数,生成低维的表征矩阵 H,其中每一行为对应节点的表征向量。对于图级别的任务,一般采用读出函数 R 将节点表征矩阵聚合为一个图表征向量,从而进行图级别的属性学习。
3. 图自监督学习框架与分类
本文用编码器 - 解码器(encoder-decoder)框架来规范化图自监督学习。其中编码器 f 的输入是原始图数据(A,X),输出为低维表征 H;代理解码器 p 以表征 H 为输入,输出代理任务相关的信息。在此框架下,图自监督学习可以表示为:
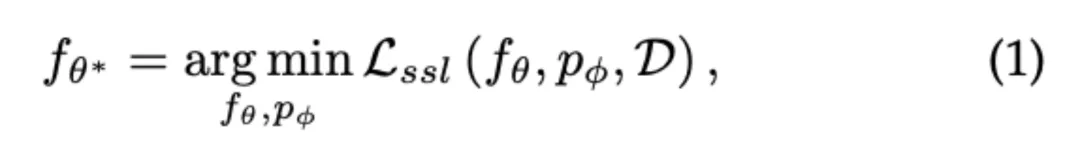
其中 D 为相关的图数据分布,L_ssl 为代理任务相关的损失函数。
利用训练好的编码器 f,所生成的表征 H 被进一步用于下游任务的学习当中。通过引入下游解码器 q,下游任务的学习可表示为:
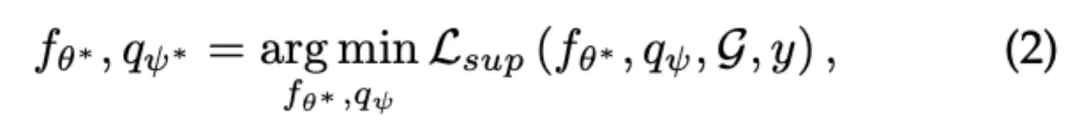
其中 L_sup 为下游任务相关的损失函数,y 为相关的人工标签。
在此框架下,本文通过以下几个维度进行分类:1)通过进一步细分公式 (1) 中的代理解码器 p 和损失函数 L_ssl,对图自监督学习方法进行分类;2)通过进一步细分代理任务和下游任务的关系,对三种自监督学习模式进行分类;3)通过进一步细分公式 (2) 中的下游解码器 q 和损失函数 L_sup,对下游任务进行分类。
本文将图自监督学习方法分为 4 个类别:基于生成的图自监督学习方法,基于属性的图自监督学习方法,基于对比的图自监督学习方法,以及混合型方法。其中,基于生成的方法(generation-based method)主要将重构图的特征信息或结构信息作为代理任务,实现自监督学习;基于属性的方法(Auxiliary Property-based method)通过预测一些可以自动获取的图相关的属性,来进行模型的训练;基于对比的方法(Contrast-based method)则是通过最大化同一样本的两个增广实体之间的互信息来进行学习;最后,混合型方法(Hybrid method)通过组合不同的上述几种代理任务,采用多任务学习的模式进行自监督学习。
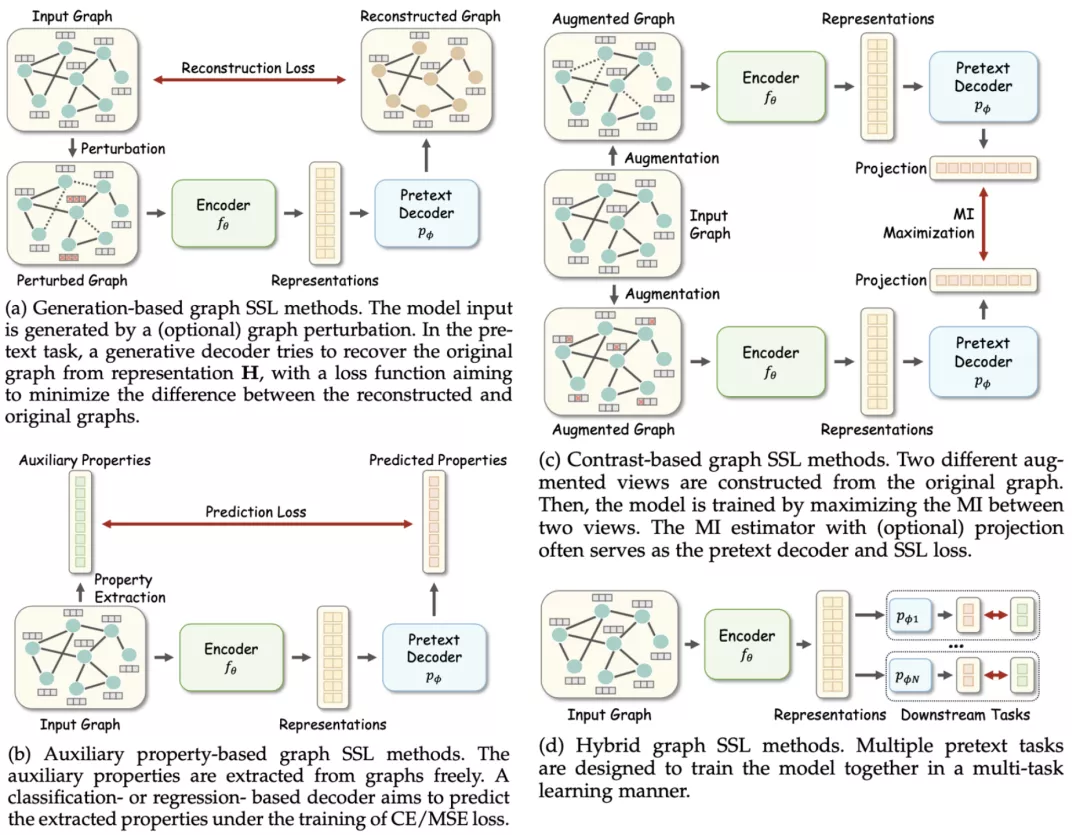
4 种图自监督学习方法分类
基于代理任务和下游任务之间的不同关系,自监督学习的模式分为以下 3 类:预训练 - 微调(Pre-training and Fine-tuning,PF)、联合学习(Joint Learning,JL)以及无监督表征学习(Unsupervised Representation Learning)。其中,PF 首先采用代理任务对编码器进行预训练,然后采用下游任务对编码器进行微调;JL 则是采用多任务学习的方式,同时利用代理任务和下游任务对编码器进行训练;URL 首先无监督地对编码器用代理任务进行训练,然后直接用得到的表征 H 来训练下游任务的解码器。
3 种自监督学习模式分类
下游任务的分类则涉及了大多数图机器学习相关的传统任务,根据其数据样本的尺度不同,本文将下游任务分类为节点级别任务(如节点分类),边级别任务(如边分类)和图级别任务(如图分类)。
4. 图自监督学习相关工作汇总
根据上述对图自监督学习方法的分类方式,本文对相关工作进行了整理、分类与汇总,分类树如下图所
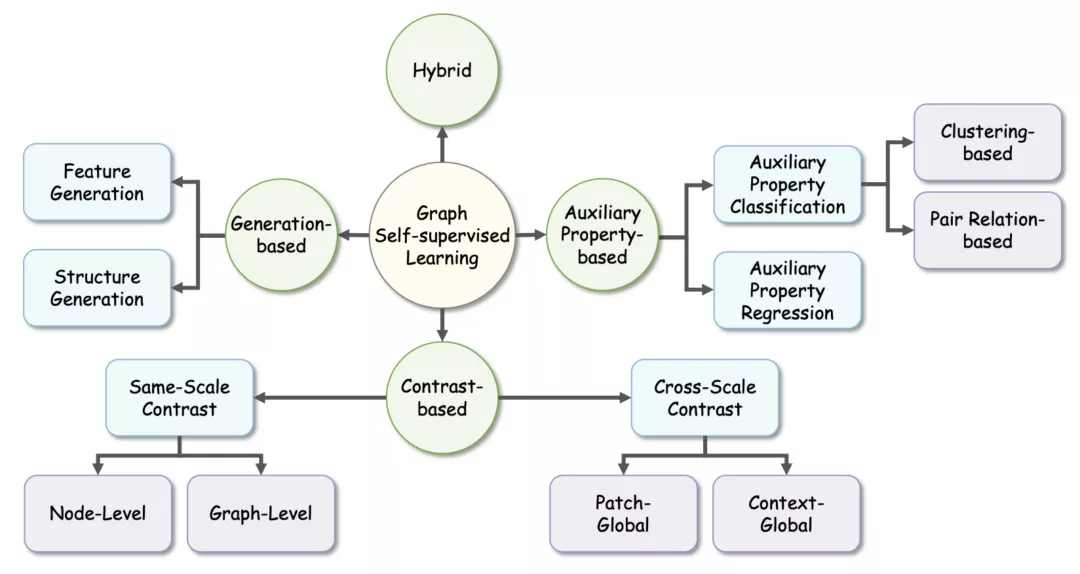
分类树
A.基于生成的图自监督学习方法
基于生成的方法主要通过重构输入数据以获取监督信号。根据重构的对象不同,本文将该类方法进一步细分为两个子类:特征生成和结构生成。
特征生成方法通过代理解码器对特征矩阵进行重构。模型的输入为原始图或者经过扰动的图数据,而重构对象可以是节点特征矩阵,边特征矩阵,或者经过 PCA 降维的特征矩阵等。对应的自监督损失函数一般为均方误差(MSE)。比较有代表性的方法为 Graph Completion,该方法对一些节点的特征进行遮盖,其代理任务的学习目标为重构这些被遮盖的节点特征。
结构生成方法起源于经典的图自编码器(GAE),一般采用基于表征相似度的解码器对图的邻接矩阵 A 进行重构。由于邻接矩阵的二值性,对应的损失函数一般为二分类交叉熵(BCE);而由于邻接矩阵的稀疏性,一般采用负采样等手段实现类别平衡。
本文对现有的基于生成的图自监督学习方法进行了总结。
B.基于属性的图自监督学习方法
基于属性的方法从图中自动获取一些有用的属性信息,以此作为监督信号对模型进行训练。这类方法在形式上与监督学习比较类似,都是采用 “样本 - 标签” 的数据模式进行学习,其区别在于这里的 “标签” 信息为伪标签,而监督学习所用的为人工标签。根据监督学习的分类模式,本文将该类方法细分为两个子类:属性分类和属性回归。
属性分类方法自动地从数据中归纳出离散的属性作为伪标签,作为代理任务的学习目标供模型学习,对应的损失函数一般为交叉熵。通过获取伪标签的手段不同,该类方法可进一步分为:1)基于聚类的属性分类:2)基于点对关系的属性分类。前者采用基于特征或结构的聚类算法的对节点赋予伪标签,而后者则是通过两个点之间的关系得到一个点对的伪标签。
属性回归方法从数据中获取连续的属性作为伪标签,对应的损失函数为均方误差(MSE)。一个典型的例子是提取节点的度(degree)作为其属性,通过代理编码器对该特性进行回归,实现对模型的自监督训练。
C.基于对比的图自监督学习方法
基于对比的方法引入了互信息最大化的概念,通过预测两个视角(view)之间的相容性来进行自监督学习。本文从三个角度对该类方法进行整理,分别是:1)图增广方式;2)图对比学习代理任务;3)互信息估计方式。
图增广技术用于从原始数据生成出增广数据,从而构成对比学习中不同的视角。图增广方法有特征增广、结构增广、混合增广。特征增广主要对图数据中的特征信息进行变换,最常见的手段是节点特征遮盖(NFM),即随机的将图中的一些特征量置为 0;此外,节点特征乱序(NFS)也是一种特征增广方法,其手段为对调不同节点的特征向量。结构增广的手段是对图结构信息进行变换,常见的结构增广为边修改(EM),包括对边的增加和删除;另一种结构增广为图弥散(Graph diffusion,GD),其对不同阶的邻接矩阵进行加权求和,从而获取更全局的结构信息。混合增广则结合了上述两种增广形式,一个典型的手段为子图采样(SS),即从原图数据中采样子结构成为增广样本。
对于对比式的代理任务,本文通过其对比样本的尺度进行进一步细分为同尺度对比学习和跨尺度对比学习。其中,同尺度对比学习通过最大化同一节点样本或者同一图样本在不同视角下的互信息来进行自监督学习,此类方法包括早期的基于随机游走的图嵌入方法,以及一系列 CV 对比学习框架(如 SimCLR 和 MoCo)在图领域的应用方法。跨尺度对比学习通过最大化 “节点样本 vs 全局样本” 或者 “节点样本 vs 邻居样本” 之间的互信息来学习,这类方法起源于 Petar 等人与 2019 年提出的 DGI,目前在异质图、动态图等数据上均有应用。
由于对比学习涉及到对互信息的估计,本文也从数学层面总结了几种互信息估计方法,包括经典的 Jensen-Shannon 散度,InfoNCE,Triplet loss function,以及前沿的 BYOL 以及 Barlow twins。
D.混合型图自监督学习方法
混合型方法结合了两种或多种不同的代理任务,以多任务学习的模式共同训练模型。常见的组合包括:结合两种生成任务(特征生成 + 结构生成)的混合方法,结合生成任务和对比任务的混合方法,结合多种对比任务的混合方法,以及三种任务共同参与的混合方法。混合型方法的总结如下表所示:
- 研究资源与实际应用
在附录内容当中,本文统计了图自监督学习相关的各种研究资源,包括:主流的数据集,常用的评估手段,不同方法的性能对比,以及各方法对开源代码总结。这些信息可以更好的帮助研究人员了解、对比和复现现有工作。
本文总结了图自监督学习在三个领域的实际应用,包括:推荐系统,异常检测,以及化学领域。此外,更多应用类工作也被总结在附录当中,涉及到的领域包括程序修复、医疗、联邦学习等。
- 未来的研究方向
针对潜在的研究热点,本文分析了图自监督学习中存在的挑战,并指出了一些旨在解决这些挑战的未来研究方向。
A. 理论基础
虽然图自监督学习在各种任务和数据集上都取得较好的性能,但其依然缺乏坚实的理论基础以证明其有效性,因为大多数工作都只是经验性地设计其代理任务,且仅采用实验手段进行评价。目前仅有的理论支持来自互信息最大化,但互信息的评估依然依赖于经验方法。我们认为,图自监督学习亟需与图理论相关的研究,潜在的理论基础包括图信号处理和谱图理论。
B. 可解释性与鲁棒性
许多图自监督学习的工作应用于风险敏感性和隐私相关的领域,因此,可解释且鲁棒的自监督框架对于适应此类学习场景具有重要意义。但是,现有工作只将下游任务性能视为其目标,而忽略了学习表示和预测结果的可解释性。此外,考虑到真实数据的不完整性以及图神经网络易受对抗攻击的特点,我们应当考虑图自监督学习的鲁棒性;然而,除个别工作外,现有的图自监督学习方法均假定输入数据是完美的。因此,探索可解释的、鲁棒的图自监督方法是一个未来的潜在方向。
C. 复杂类型图的代理任务设计
当前的大多数工作集中于属性图的自监督学习,只有少数工作集中于复杂的图类型,例如异质或时空图。对于复杂图,主要的挑战是如何设计代理任务来捕获这些复杂图的独特数据特征。现有的一些方法将互信息最大化的思想应用于复杂图的学习,其学习能力比较有限。因此,一个潜在方向是为复杂的图数据设计多种多样的代理任务,这些任务应适应其特定的数据特征。此外,将自监督技术扩展到更普遍的图类型(例如超图)将是一个可行的方向,值得进一步探索。
D. 图对比学习的增广方法
在 CV 的对比学习中,大量的数据增广策略(包括旋转、颜色扭曲、裁剪等)提供了不同的视角,从而支持了对比学习中的表征不变性。然而,由于图结构数据的性质(复杂和非欧几里德结构),图上的数据增广方案没有得到很好的探索。现有的图增广策略大多采用随机的遮盖 / 乱序节点特征、边修改、子图采样和图扩散等手段,这在生成多个图视角时无法提供丰富的多样性,同时其表征不变性也是不确定的。为了解决这个问题,自适应地执行图形增广,自动选择增广,或通过挖掘丰富的底层结构和属性信息联合考虑更强的增广样本都将是未来潜在的研究方向。
E. 通过多代理任务学习
本文统计的大部分方法仅通过解决一个代理任务来训练模型,只有少数混合方法探索多个代理任务的组合。然而,不少 NLP 领域的与训练模型和本文所汇总的少数混合方法都说明了:不同的代理任务可以从不同的角度提供监督信号,这更有助于图自监督方法学习到有用的信息表征。因此,对多种代理任务的自适应组合,以及更先进的混合方法值得进一步研究。
F. 更广泛的应用
图是许多领域中普遍存在的数据结构;然而,在大多数应用领域,获取手动标签的成本往往很高。在这种情况下,图自监督学习具有很好的前景,特别是那些高度依赖专业知识来标注数据的领域。然而,大多数现有的图自监督学习的实际应用仅集中在少数几个领域(推荐系统、异常检测和化学),这表明图自监督在大多数应用领域具有未开发的潜力。我们有望将图自监督学习扩展到更广阔的应用领域,例如,金融网络、网络安全、社区检测和联邦学习等。