为计算机视觉生成庞大的、合成的、带标注的、逼真的数据集

本文为 AI 研习社编译的技术博客,原标题 :
Generating Large, Synthetic, Annotated, & Photorealistic Datasets for Computer Vision
翻译 | Kivi·Wong、灰灰在学习 校对 | Peter_Dong 整理 | 菠萝妹
原文链接:
https://medium.com/greppy/generating-large-synthetic-annotated-photorealistic-datasets-for-computer-vision-ffac6f50a29c

我想要给大家分享一个我们在Greppy一直使用的测试版工具,其被称之为”Greepy Metaverse“,其通过快速、简便地为机器学习生成大量训练数据,来辅助计算机视觉目标识别/语义分割/对象分割(旁白:如果可以的话,我们也希望能够为你的项目提供帮助 - 给我发邮件(matt@greppy.co 或者在领英(LinkedIn)中搜索联系我))。
如果你已经做过图像识别,你应该知道数据集的数量和准确性是重要的。你的所有场景也都需要标注,这意味着有上千或者上万张图片。这时间和精力对于我们小团队来说是不可估量的。
概览
因此,我们发明了一个工具,使得创造大量带标注的数据集更加容易。我们希望,通过生成识别及对所有对象分割所需的图片,能对虚拟现实、自动驾驶、通用机器人有帮助。
我们甚至开源了我们VertuoPlus Deluxe Silver数据集,其包含1000种咖啡机的场景,所以你可以跟我们一起做!它是一个6.3GB的下载包。
为了说明其性能,我们将给你一个在Greepy的真实例子,我们需要通过因特尔Realsense D435摄像机来识别我们的咖啡机及其按钮。未来将会有更多说明我们为什么想要识别我们的咖啡机,但这足够表明我们需要咖啡因的时间多于不需要它的时间。

昔日,我们不得不手动标注!
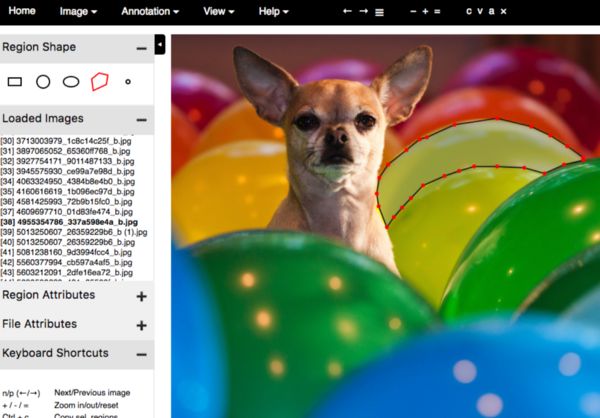
VGG图片标注工具样例,由Waleed Abdulla 的 “Splash of Color”提供。
在过去绝大多数数据集的标注任务是由人工标注完成的。正如在左边看到的,这不是一个特别有趣的活,并且由于全是人为的,其容易出现错误。
该工具也几乎不可能准确地标注其他重要的信息,如物体姿态,物体法线及深度。
合成数据:一个长达10年的想法
合成数据(计算机生成)是一种有希望替代手工标记的方法。这个想法已经产生了十多年了(此Github仓库链接了相当多这样的项目)
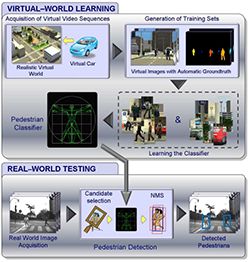
来源于Learning Appearance in Virtual Scenarios for Pedestrian Detection, 2010
我们在现有的项目中遇到了一些问题,因为其要么要求使用编程技巧,要么无法输出逼真的图像。 我们需要一些工具,帮助我们的非编程团队有效地生成大量数据以识别新目标物。当然,我们的一些物品在没有光线追踪(维基百科)的情况下,对于真实图片的生成是有挑战的,这是一种其他现存项目中没有运用的技术。
利用Greppy Metaverse制造上规模的合成数据
为了能达到我们期望数量规模的物体,我们创造了Greepy Metaverse工具。例如,我们可以使用从网站3D Warehouse预先做好的CAD模型,然后利用网页接口使它们更加逼真。或者,我们的画师可以创造自定义3D模型,而不需要担心如何编程。
让我们回到咖啡上。 利用我们的工具, 我们首先上传两个我们现有的Nespresso VertuoPlus Deluxe Silver机器非逼真的CAD模型,我们确实上传了两个CAD模型,因为我们希望在两种结构下识别机器。

由我们团队自定义的CAD模型
当CAD模型上传后,我们选择预先做好的,逼真的材料并应用到每个表面上。Greppy Metaverse 的目标之一就是组建一个开源的,逼真的材料库以供所有人使用(理想情况是能在社区的帮助下)。备注, 3D艺术家通常需要创建自定义材料。

为CAD模型选择预先做好的,逼真的材料。
为了能够识别机器的不同部分,我们需要标注机器上我们关注的部分。网页界面提供了方法去完成此操作,这样不了解3D建模软件的人就可以帮助进行标注。不需要3D画师或者程序员啦:)
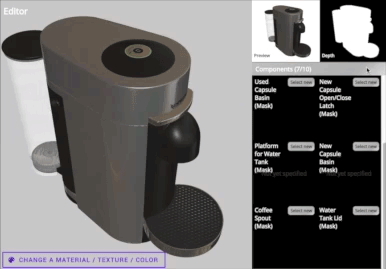
轻易地标注每个物品所有感兴趣的部分。
接下来呢……就会变成这样!我们自动生成数万个场景,并且这些场景在姿态、物体数量、相机角度和光照条件方面都不相同。它们都会被自动注释,并且精确的对应着各个像素点。在这些场景背后,该工具使用GPU运行一系列云实例,并且通过一些“渲染农场”对这些变化进行渲染。
这是一个来自 open-sourced VertuoPlus Deluxe Silver dataset的RGB图像的例子:

在许多不同光照条件,不同相机角度,不同安排对象的RGB色彩模式的场景。
对于每个场景,我们输出一些东西:基于你摄像机的选择输出单目或立体的RGB模式的图片。摄像机通过调整摄像机和拍摄对象的姿态,通常会对所看到的深度、所有对象和部分对象包括场景中物体的表面法线的像素进行完美注释。
让我再强调一下,任何场景都不需要手动做标记。
单个场景的示例输出如下:

每个场景的输出的示例
生成数据上的机器学习
当整个数据集生成之后,就可以直接使用它们来训练Mask-RCNN模型(关于Mask-RCNN的历史,这里有一份很好的资料)。在后续的文章,我们将开源Mask—RCNN的Matterport实现代码,我们用这份代码从Greppy Metaverse数据库中训练了3D实例分割模型。
同时,这里给出一个预览。下面是Intel RealSense D435摄像机的原始拍摄数据,左边是RGB图,右边是校准后深度图。(组成RGB-D 共4个通道)

拍摄自Intel RealSense D435的原始数据。没错,这是咖啡,茶和伏特加;-)
为了这个Mask-RCNN模型,我们使用大约1000个场景的开源数据集来训练。在模型训练了30个epochs之后,我们可以看到在RGB-D上运行结果。看!我们得到了几乎100%准确的mask输出,这仅仅只在合成数据上进行了训练。
当然,我们也会开源训练代码,所以你可以亲自验证这一点。

一旦我们可以确定图像中哪些像素是我们感兴趣的对象,我们就可以使用Intel RealSense 采集的帧来获取咖啡机上那些像素的深度(米制)。了解Nespresso机器具体的像素及深度也将有利于任何虚拟现实,导航规划和机器操控等应用。
结论和思考
当下,Greepy Metaverse只是在测试,并且有很多我们希望改善的地方。但是我们真的对结果感到很开心。
与此同时,如果你有项目能够从我们的工具中获益,请联系我。Email matt@greppy.co 或者在领英(LinkedIn)上联系我。
特别鸣谢 Waleed Abdulla 及 Jennifer Yip 为改进这篇生成数据上的机器学习
想要继续查看该篇文章相关链接和参考文献?
戳链接:
http://www.gair.link/page/TextTranslation/1092
AI研习社每日更新精彩内容,点击文末【阅读原文】即可观看更多精彩内容:
良心推荐:一份 20 周学习计算机科学的经验贴(附资源)
多目标追踪器:用OpenCV实现多目标追踪(C++/Python)
为计算机视觉生成大的、合成的、带标注的、逼真的数据集
悼念保罗·艾伦,除了他科技圈还有哪些大佬值得信仰?
等你来译:
自动文本提取
用 4 种卷积神经网络,轻松分类时尚图像
使用 SKIL 和 YOLO 构建产品级目标检测系统
很有启发性的25个开源机器学习项目
号外号外~
想要获取更多AI领域相关学习资源,可以访问AI研习社资源板块下载,
所有资源目前一律限时免费,欢迎大家前往社区资源中心
http://www.gair.link/page/resources 下载喔~




