158万张图像的鉴黄数据集
机器之心报道
如果你想训练一个内容审核系统过滤不合适的信息,或用 GAN 实现一些大胆的想法,那么数据集是必不可少的。但限制级图像很难收集,也很少会开源。在这个项目中,作者构建了一个大型高质量图像鉴黄数据集,它有超过 158 万张图像,共分为 159 个大类别,且每一个类别还有若干子类别。另外,今天发这篇文章和情人节完全无关,和你是不是单身狗完全无关,一切是为了探索机器学习的前沿……(笑眯眯手动摸狗头)。
项目地址:https://github.com/EBazarov/nsfw_data_source_urls
在这篇文章中,我们将介绍一个新的鉴黄图像开源项目,它的 158 万数据量足够训练一个大型分类模型或生成模型,而且充足的类别也提升了数据的质量。总体而言,我们会发现该项目的图像分类比较准确,至少我们采样的一些图像都属于 NSFW 和对应的类别。
整个项目和 nsfw_data_scrapper 项目一样提供对应的图像超链,不同类别及子类别都有对应的 TXT 文件,所有超链都储存在 TXT 文本中。如下所示为简单的数据示例,因为本文这个数据集尺度有点大,我们以 nsfw_data_scrapper 数据集为例:
数据集统计信息
raw_data 文件夹中可以找到不同类别及对应的 TXT 文本,以下是关于该数据集的一些统计信息:
159 个不同的类别
158.9331 万个 URL
下载并清洗后大约有 500GB,或者说 130 万张 NSFW 图像。
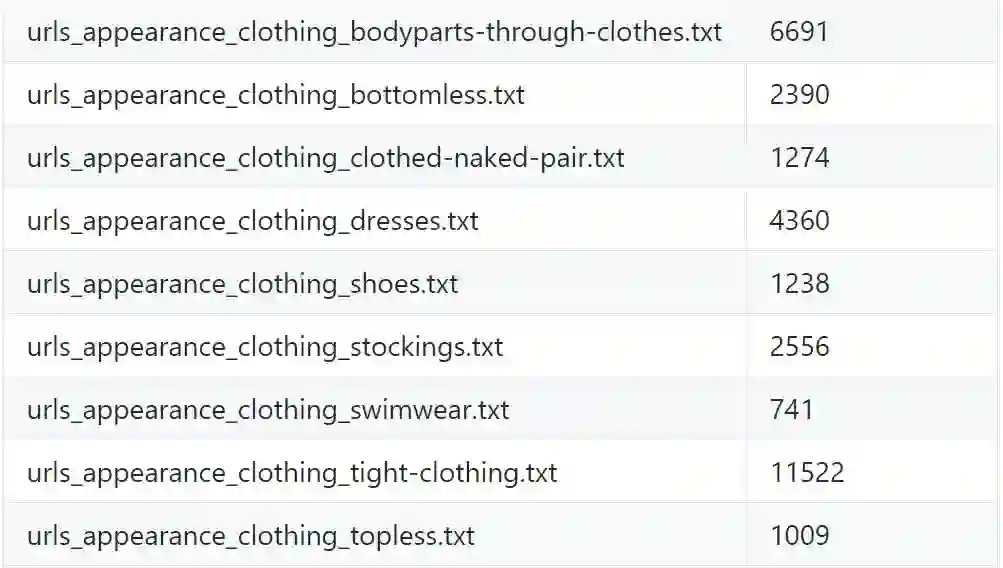
如下所示为不同类别与对应图像数,下图只截取了少量类别作为示例:

每一个类别还会有一些小类,例如在紧身衣裤(appearance_clothing_tight-clothing)的类别下,还会细分一些子类别:
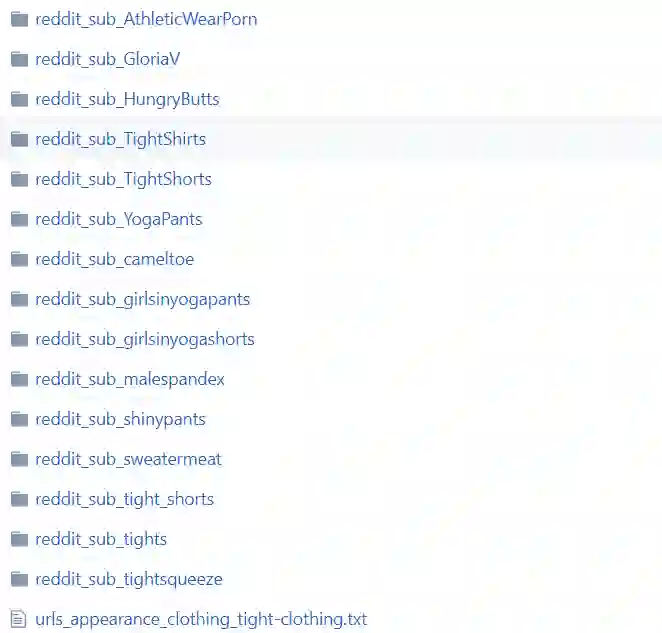
这些子类别并没有统计信息,不过在读取图像并构建标注的过程中,我们可以考虑这些子类别,也可以忽略它们。
注意事项
1. 下载之后最好清洗一下数据集,如:
删除重复图像
移除被禁止/删除的图片(它们会产生一个特殊的图像占位符)
找出损坏的数据并将其移除
2. 注意噪声,一些资源提供了 NSFW 和中性图像的高度混合的数据。
3. 该库可以帮助检索 NSFW 图像,整个项目没有针对中性图像内容的专用 URL。
推荐阅读
Python可视化神器——pyecharts的超详细使用指南!






