数据标注还能更快!谷歌发布图像标注机器学习辅助工具

参加 Meet 35 大会,请点击↑
基于深度学习的现代计算机视觉模型,其性能主要取决于的大量已标注的可用训练数据集,例如 Open Images 数据集。然而,如何获得高质量的训练数据,成为计算机视觉发展的主要瓶颈。如在无人驾驶、机器人和图像搜索之类的应用中,使用的一些像素级目标预测任务,比如语义分割任务,格外的需要更大更好的数据集。事实上,传统的手工标注工具需要标注人仔细点击图像中每个对象的边界,用来划分图像中的目标,这项工作非常乏味:COCO+Stuff 数据集中标注单个图像就需要大概 19 分钟,而标记整个数据集甚至需要 53000 个小时!
左图| COCO 数据集中的一张图片; 右图|左图的像素级语义分割结果。(来源:Image credit)
谷歌的研究人员设计了一种机器学习驱动的工具,将在 2018 年 ACM 多媒体会议的“ Brave New Ideas ”环节展示,可以用于标注图像数据中每个目标的轮廓和背景,将其应用在标注分类数据上,可以让标记数据集的生成速度提高至传统方法的 3 倍。
该方法被谷歌称之为流体标注(Fluid Annotation),从强语义分割模型的输出开始,人工标注者可以使用用户界面,通过机器辅助方法进行编辑修改。谷歌开发设计的界面允许标注者选择要改正的内容和顺序,让他们能集中精力去处理机器尚未理解和标注的图像。

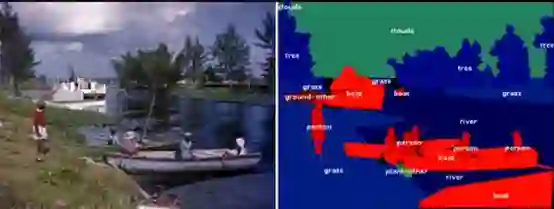
图 | 对 COCO 数据集中的图像使用流体标注的可视化界面。(来源:gamene)
为更准确的对图像进行标注,谷歌首先通过预训练的语义分割模型(Mask-RCNN)来处理图像。这一过程会生成约 1000 个图像分割区域及其标签和置信度。置信度最高的分割区域用来初始化标签,呈现给标注者。
然后标注者可以:
(1)从机器生成的候选分类标签中为当前区域选择标签。
(2)对机器未覆盖到的目标添加分割区域。机器会识别出最可能的预生成区域,标注者从中选择分割效果最好的一个。
(3)删除现有分割区域。
(4)改变重叠区域的深度顺序。
Demo 链接:
https://fluidann.appspot.com(PC 平台可用)

图 |使用传统人工标注工具(中列)和流体标注工具(右列)在 COCO 数据集的三张图像上比较标注结果。虽然使用人工标注工具时,目标的边界一般更准确,但同一对象的标注有时会存在差异,其主要是因为人类标注者通常对某一确定目标的类别有不同意见。图片来源:sneaka(上),Dan Hurt(中),Melodie Mesiano(下)。
在让图像标注变得更快、更容易这个问题上,流体标注工具的出现只是第一步。未来团队的目标是改进对目标边界的标注,进一步利用人工智能提升界面运行速度,最终可以处理以前无法识别的类别,让数据收集变得越来越高效和快捷。
-End-
编辑:李根 责编:李禹蒙
参考:
https://ai.googleblog.com/2018/10/fluid-annotation-exploratory-machine.html






