900万张标注图像,谷歌发布Open Images最新V3版

过去几年机器学习的发展使得计算机视觉有了快速的进步,系统能够自动描述图片,对共享的图片创造自然语言回应。其中大部分的进展都可归因于 ImageNet 、COCO(监督学习)以及 YFCC100M(无监督学习数据集) 这样的数据集的公开使用。
2016年,谷歌发布 Open Images,这是一个包含约 900万 张图像 URL 的数据集,里面的图片通过标签注释被分为 6000 多类。近日,谷歌又发布了 Open Images 最新的 V3 版,相比之前的版本,这次更新有哪些改变呢?
一、下载地址
https://github.com/cvdfoundation/open-images-dataset
图像 URLs 和元数据 (990 MB)
https://storage.googleapis.com/openimages/2017_11/images_2017_11.tar.gz
https://storage.googleapis.com/openimages/2017_11/annotations_human_bbox_2017_11.tar.gz
https://storage.googleapis.com/openimages/2017_11/annotations_human_2017_11.tar.gz
https://storage.googleapis.com/openimages/2017_11/annotations_machine_2017_11.tar.gz
https://storage.googleapis.com/openimages/2017_11/classes_2017_11.tar.gz
https://github.com/openimages/dataset/wiki/Importing-into-PostgreSQL
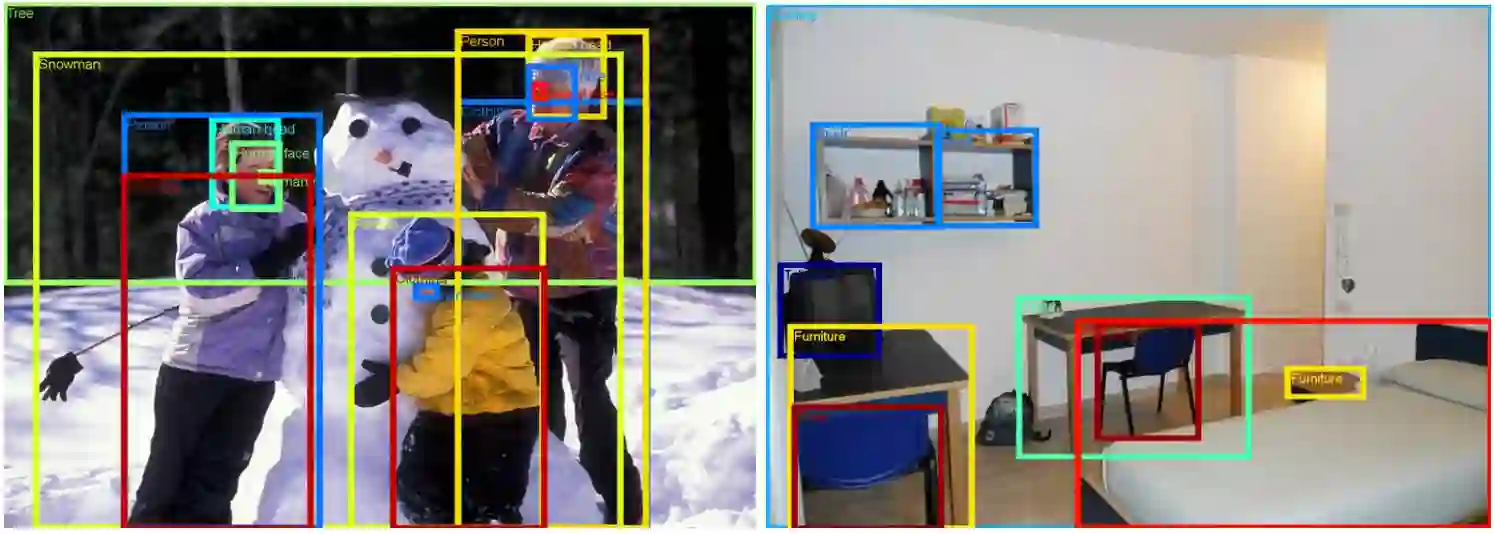
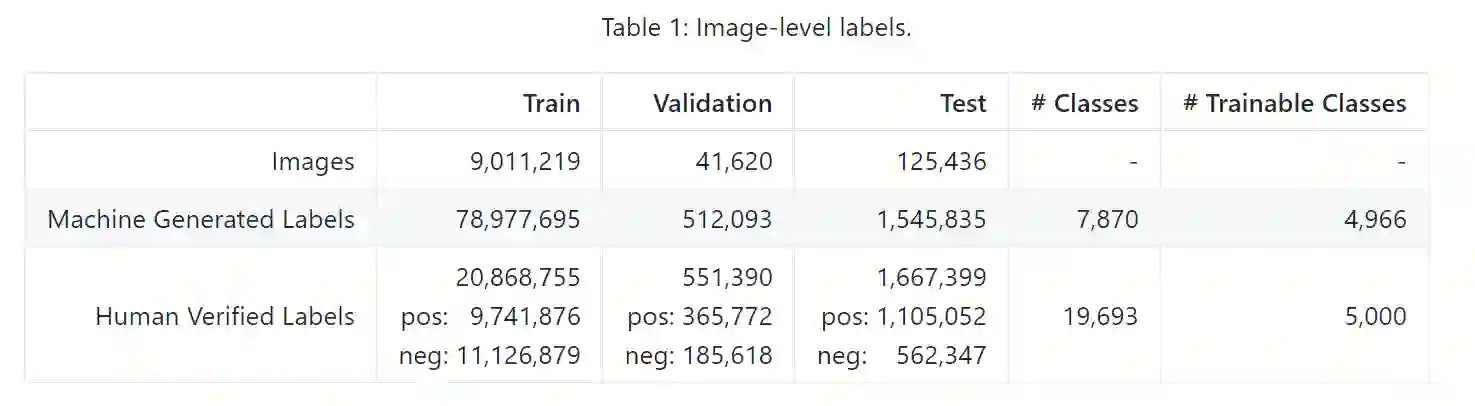
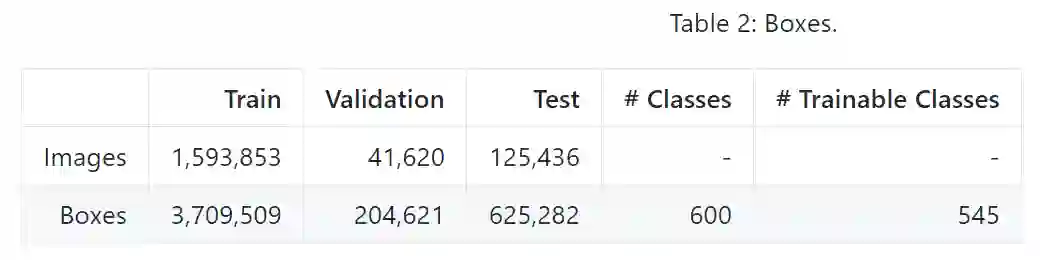
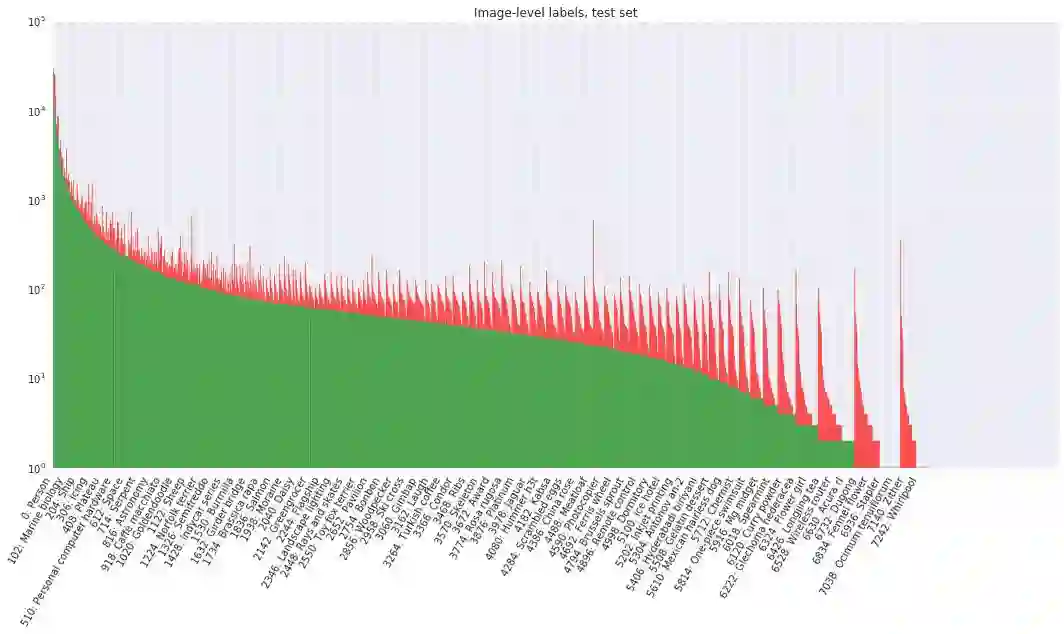
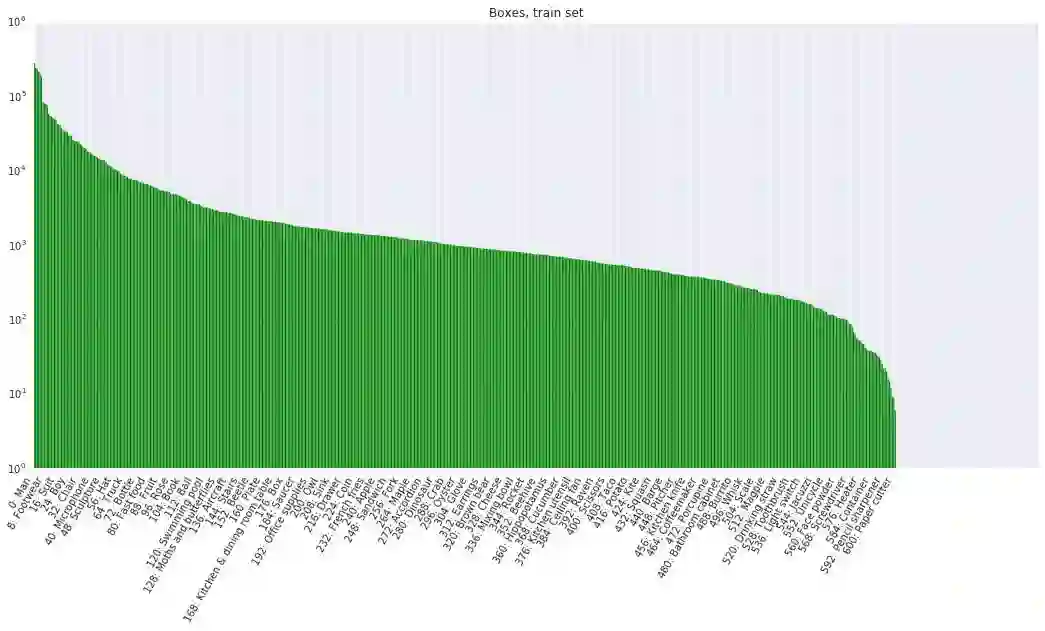
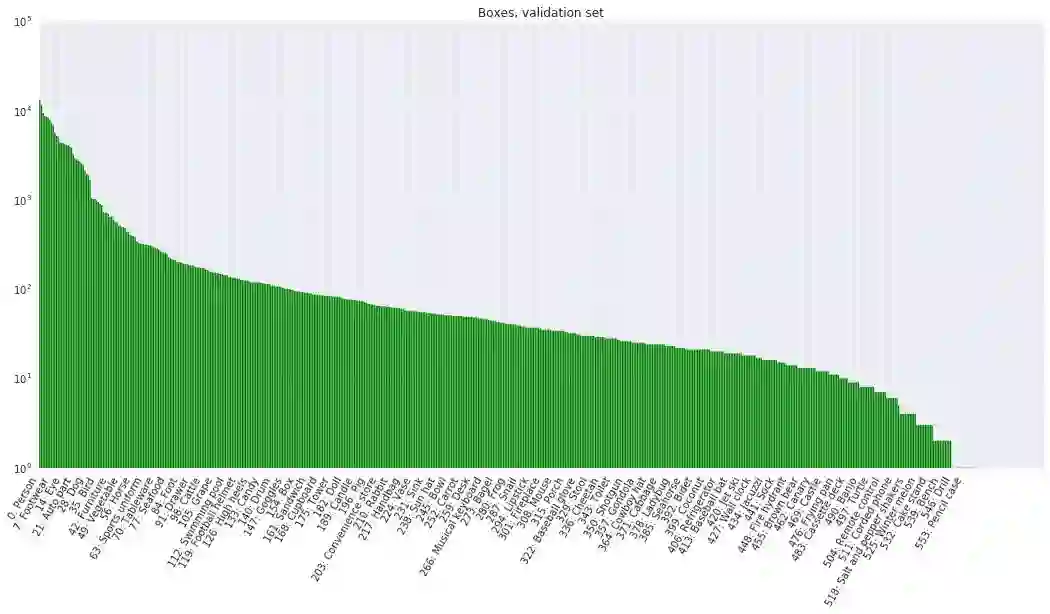
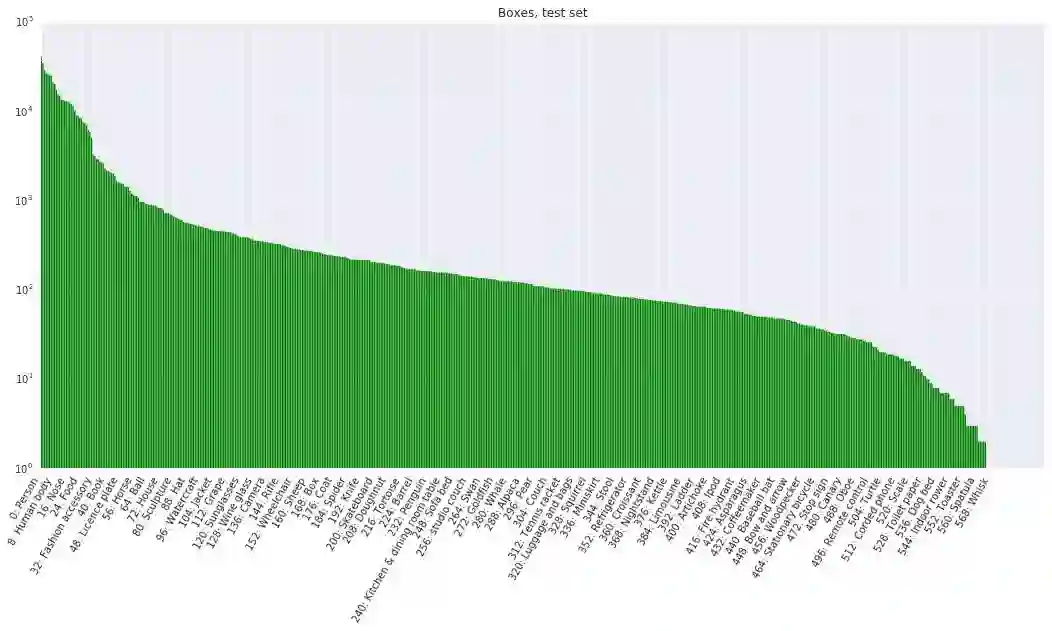
该数据集包含一个训练集(9011219张图像)、一个验证集(41620张图像)和一个测试集(125436张图像)。V1 版本里的验证集在 V2 版本中被划分为验证集和测试集,这样做是为了更好地进行评估。Open Images 中的所有图像都标注有图像级标签和边界框,如下图所示。
在训练集中,我们对 150 万张图像进行了边界框标注,并将带有最明确的肯定标签的图像作为重点标注对象。训练集中的每张图像平均大约有 2 个标注框。在整个训练集中,如果一张图像中包含多个属于同一类别的目标,通常只对一个目标进行边界框标注。
ImageID,Subset,OriginalURL,OriginalLandingURL,License,AuthorProfileURL,Author,Title,\ OriginalSize,OriginalMD5,Thumbnail300KURL ... 000060e3121c7305,train,https://c1.staticflickr.com/5/4129/5215831864_46f356962f_o.jpg,\ https://www.flickr.com/photos/brokentaco/5215831864,\ https://creativecommons.org/licenses/by/2.0/,\ "https://www.flickr.com/people/brokentaco/","David","28 Nov 2010 Our new house."\ 211079,0Sad+xMj2ttXM1U8meEJ0A==,https://c1.staticflickr.com/5/4129/5215831864_ee4e8c6535_z.jpg ...
OriginalSize 是指原始图像的下载文件大小。
OriginalMD5 是指 base64 编码的二元 MD5(参考https://cloud.google.com/storage/transfer/create-url-list#md5)
Thumbnail300KUR 是指 ~300000 像素 (~640x480) 的索引图像(thumbnail)的可选择 URL。如果没有其他更好的方法,我们可以通过这个 URL 方便地下载图像数据。如果没有这个URL,则必须使用 OriginalURL(如有需要,再将图像调整为相同的大小)。注意:这些索引图像是在运行过程中生成的,它们的内容和分辨率可能会每天都会有变化。
2)annotations-machine.csv
ImageID,Source,LabelName,Confidence 000002b66c9c498e,machine,/m/05_4_,0.7 000002b66c9c498e,machine,/m/0krfg,0.7 000002b66c9c498e,machine,/m/01kcnl,0.5 000002b97e5471a0,machine,/m/05_5t0l,0.9 000002b97e5471a0,machine,/m/0cgh4,0.8 000002b97e5471a0,machine,/m/0dx1j,0.8 000002b97e5471a0,machine,/m/039jbq,0.8 000002b97e5471a0,machine,/m/03nfmq,0.8 000002b97e5471a0,machine,/m/03jm5,0.7 ...
这些是由类似于 Google Cloud Vision API 的计算机视觉模型生成的。
3)annotations-human.csv
ImageID,Source,LabelName,Confidence 000026e7ee790996,verification,/m/04hgtk,0 000026e7ee790996,verification,/m/07j7r,1 000026e7ee790996,crowdsource-verification,/m/01bqvp,1 000026e7ee790996,crowdsource-verification,/m/0csby,1 000026e7ee790996,verification,/m/01_m7,0 000026e7ee790996,verification,/m/01cbzq,1 000026e7ee790996,verification,/m/01czv3,0 000026e7ee790996,verification,/m/01v4jb,0 000026e7ee790996,verification,/m/03d1rd,0 ...
“验证集”是经人类验证的图像级标签。
“众包验证集”是Crowdsource 应用程序中经人类验证的标签。
4)annotations-human-bbox.csv
ImageID,Source,LabelName,Confidence,XMin,XMax,YMin,YMax 000002b66c9c498e,activemil,/m/0284d,1,0.560250,0.951487,0.696401,1.000000 000002b66c9c498e,activemil,/m/052lwg6,1,0.543036,0.907668,0.699531,0.995305 000002b66c9c498e,activemil,/m/0fszt,1,0.510172,0.979656,0.641628,0.987480 000002b66c9c498e,verification,/m/01mzpv,1,0.018750,0.098438,0.767187,0.892187 000002b66c9c498e,xclick,/m/01g317,1,0.012520,0.195618,0.148670,0.588419 000002b66c9c498e,xclick,/m/0284d,1,0.528951,0.924883,0.676056,0.965571 000002b66c9c498e,xclick,/m/02wbm,1,0.530516,0.923318,0.668232,0.976526 000002b66c9c498e,xclick,/m/052lwg6,1,0.516432,0.928012,0.651017,0.985915 000002b66c9c498e,xclick,/m/0fszt,1,0.525822,0.920188,0.669797,0.971831 ...
ImageID,Source,LabelName,Confidence,XMin,XMax,YMin,YMax,IsOccluded,IsTruncated,IsGroupOf,IsDepiction,IsInside 000026e7ee790996,freeform,/m/07j7r,1,0.071905,0.145346,0.206591,0.391306,0,1,1,0,0 000026e7ee790996,freeform,/m/07j7r,1,0.439756,0.572466,0.264153,0.435122,0,1,1,0,0 000026e7ee790996,freeform,/m/07j7r,1,0.668455,1.000000,0.000000,0.552825,0,1,1,0,0 000062a39995e348,freeform,/m/015p6,1,0.205719,0.849912,0.154144,1.000000,0,0,0,0,0 000062a39995e348,freeform,/m/05s2s,1,0.137133,0.377634,0.000000,0.884185,1,1,0,0,0 0000c64e1253d68f,freeform,/m/07yv9,1,0.000000,0.973850,0.000000,0.043342,0,1,1,0,0 0000c64e1253d68f,freeform,/m/0k4j,1,0.000000,0.513534,0.321356,0.689661,0,1,0,0,0 0000c64e1253d68f,freeform,/m/0k4j,1,0.016515,0.268228,0.299368,0.462906,1,0,0,0,0 0000c64e1253d68f,freeform,/m/0k4j,1,0.481498,0.904376,0.232029,0.489017,1,0,0,0,0 ...
IsOccluded: 表示目标被图像中的另一目标遮蔽。
IsTruncated: 表示目标超出了图像的边界。
IsGroupOf: 表示边界框覆盖了一群目标(例如:一床花朵、一群人)。当图像中的实例(instances )超过 5 个并且各实例相互重叠或交叠时,我们会要求标注员使用这个标签。
IsDepiction: 表示目标是一幅画(例如:目标的卡通画或素描,不是真正的实体实例)。
IsInside: 表示是从对象内部(例如汽车内部或建筑物内部)拍摄的照片。
"freeform" 和 "xclick" 代表人类绘制的边界框。
"activemil" 代表经过 Active MIL 程序验证后被认为是重合度高(IoU > 0.7)的边界框。
"verification" 代表经过谷歌内部目标检测模型的检测后被认为是重合度高(IoU > 0.7)的边界框。
5)class-descriptions.csv
... /m/025dyy,Box /m/025f_6,Dussehra /m/025fh,Professor x /m/025fnn,Savannah Sparrow /m/025fsf,Stapler /m/025gg7,Jaguar x-type /m/02_5h,Figure skating /m/025_h00,Solid-state drive /m/025_h88,White tailed prairie dog /m/025_hbp,Mercury monterey /m/025h_m,Yellow rumped Warbler /m/025khl,Spätzle ...
/m/02wvth,"Fiat 500 ""topolino""" /m/03gtp5,Lamb's quarters /m/03hgsf0,"Lemon, lime and bitters"
6)classes.txt
/m/0100nhbf /m/0104x9kv /m/0105jzwx /m/0105ld7g /m/0105lxy5 /m/0105n86x /m/0105ts35 /m/0108_09c /m/01_097 /m/010dmf ...
7)classes-trainable.txt
8)classes-bbox.txt
9)classes-bbox-trainable.txt
通过此链接(http://www.cvdfoundation.org/datasets/open-images-dataset/vis)浏览边界框的groundtruth,由 CVDF 提供。
通过此链接(https://storage.googleapis.com/openimages/2017_07/bbox_labels_vis/bbox_labels_vis.html)查看可进行边界框标注的标签:


Inception resnet v2 目标检测模型(使用 V2 版本数据训练)。Tensorflow 目标检测API 中包含模型检测点、评估协议(protocol)以及推理和评估工具。
Resnet 101 图像分类模型(使用 V2 版本数据训练);模型检测点、检测点说明(Checkpoint readmedm) 和推理代码。
原文链接:
https://github.com//openimages/dataset
精选推荐
深度学习高手该怎样炼成?这位拿下阿里天池大赛冠军的中科院博士为你规划了一份专业成长路径





