放弃手工标记数据,斯坦福大学开发弱监督编程范式Snorkel
新智元报道
新智元报道
来源:ai.stanford.edu
编辑:肖琴
【新智元导读】手工标记大量数据始终是开发机器学习的一大瓶颈。斯坦福AI Lab的研究人员探讨了一种通过编程方式生成训练数据的“弱监督”范式,并介绍了他们的开源Snorkel框架。
近年来,机器学习 (ML) 对现实世界的影响越来越大。这在很大程度上是由于深度学习模型的出现,使得从业者可以在基准数据集上获得 state-of-the-art 的分数,而无需任何手工特征设计。考虑到诸如 TensorFlow 和 PyTorch 等多种开源 ML 框架的可用性,以及大量可用的最先进的模型,可以说,高质量的 ML 模型现在几乎成为一种商品化资源了。然而,有一个隐藏的问题:这些模型依赖于大量手工标记的训练数据。
这些手工标记的训练集创建起来既昂贵又耗时 —— 通常需要几个月甚至几年的时间、花费大量人力来收集、清理和调试 —— 尤其是在需要领域专业知识的情况下。除此之外,任务经常会在现实世界中发生变化和演变。例如,标记指南、粒度或下游用例都经常发生变化,需要重新标记 (例如,不要只将评论分类为正面或负面,还要引入一个中性类别)。
由于这些原因,从业者越来越多地转向一种较弱的监管形式,例如利用外部知识库、模式 / 规则或其他分类器启发式地生成训练数据。从本质上来讲,这些都是以编程方式生成训练数据的方法,或者更简洁地说,编程训练数据 (programming training data)。
在本文中,我们首先回顾了 ML 中由标记训练数据驱动的一些领域,然后描述了我们对建模和整合各种监督源的研究。我们还讨论了为大规模多任务机制构建数据管理系统的设想,这种系统使用数十或数百个弱监督的动态任务,以复杂、多样的方式交互。
ML 中的许多传统研究方法也同样受到对标记训练数据的需求的推动。我们首先将这些方法与弱监督方法 (weak supervision) 区分开来:弱监督是利用来自主题领域专家(subject matter experts,简称 SME) 的更高级别和 / 或更嘈杂的输入。
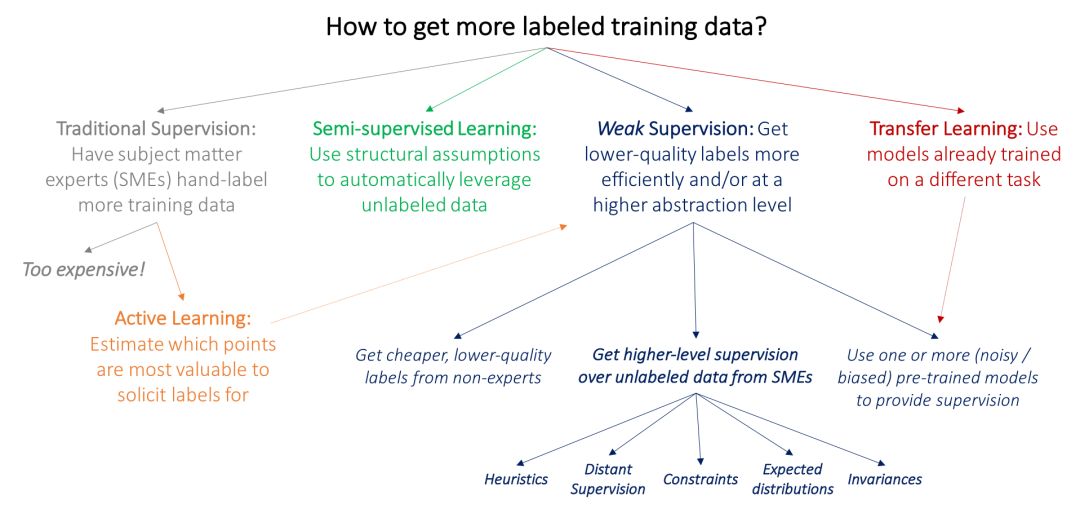
目前主流方法的一个关键问题是,由领域专家直接给大量数据加标签是很昂贵的:例如,为医学成像研究构建大型数据集更加困难,因为跟研究生不同,放射科医生可不会接受一点小恩小惠就愿意为你标记数据。因此,在 ML 中,许多经过深入研究的工作线都是由于获取标记训练数据的瓶颈所致:
在主动学习 (active learning) 中,目标是让领域专家为估计对模型最有价值的数据点贴标签,从而更有效地利用领域专家。在标准的监督学习设置中,这意味着选择要标记的新数据点。例如,我们可以选择靠近当前模型决策边界的乳房 X 线照片,并要求放射科医生仅给这些照片进行标记。但是,我们也可以只要求对这些数据点进行较弱的监督,在这种情况下,主动学习与弱监督是完美互补的;这方面的例子可以参考 (Druck, settle, and McCallum 2009)。
在半监督学习 (semi-supervised learning ) 设置中,我们的目标是用一个小的标记训练集和一个更大的未标记数据集。然后使用关于平滑度、低维结构或距离度量的假设来利用未标记数据 (作为生成模型的一部分,或作为一个判别模型的正则项,或学习一个紧凑的数据表示);参考阅读见 (Chapelle, Scholkopf, and Zien 2009)。从广义上讲,半监督学习的理念不是从 SME 那里寻求更多输入,而是利用领域和任务不可知的假设来利用未经标记的数据,而这些数据通常可以以低成本大量获得。最近的方法使用生成对抗网络 (Salimans et al. 2016)、启发式转换模型 (Laine and Aila 2016) 和其他生成方法来有效地帮助规范化决策边界。
在典型的迁移学习 (transfer learning )设置 中,目标是将一个或多个已经在不同数据集上训练过的模型应用于我们的数据集和任务;相关的综述见 (Pan 和 Yang 2010)。例如,我们可能已经有身体其他部位肿瘤的大型训练集,并在此基础上训练了分类器,然后希望将其应用到我们的乳房 X 光检查任务中。在当今的深度学习社区中,一种常见的迁移学习方法是在一个大数据集上对模型进行 “预训练”,然后在感兴趣的任务上对其进行 “微调”。另一个相关的领域是多任务学习 (multi-task learning),其中几个任务是共同学习的 (Caruna 1993; Augenstein, Vlachos, and Maynard 2015)。
上述范例可能让我们得以不用向领域专家合作者寻求额外的训练标签。然而,对某些数据进行标记是不可避免的。如果我们要求他们提供各种类型的更高级、或不那么精确的监督形式,这些形式可以更快、更简便地获取,会怎么样呢?例如,如果我们的放射科医生可以花一个下午的时间来标记一组启发式的资源或其他资源,如果处理得当,这些资源可以有效地替代成千上万的训练标签,那会怎么样呢 ?
从历史的角度来看,试图 “编程” 人工智能 (即注入领域知识) 并不是什么新鲜想法,但现在提出这个问题的主要新颖之处在于,AI 从未像现在这样强大,同时在可解释性和可控制性方面,它还是一个 “黑盒”。
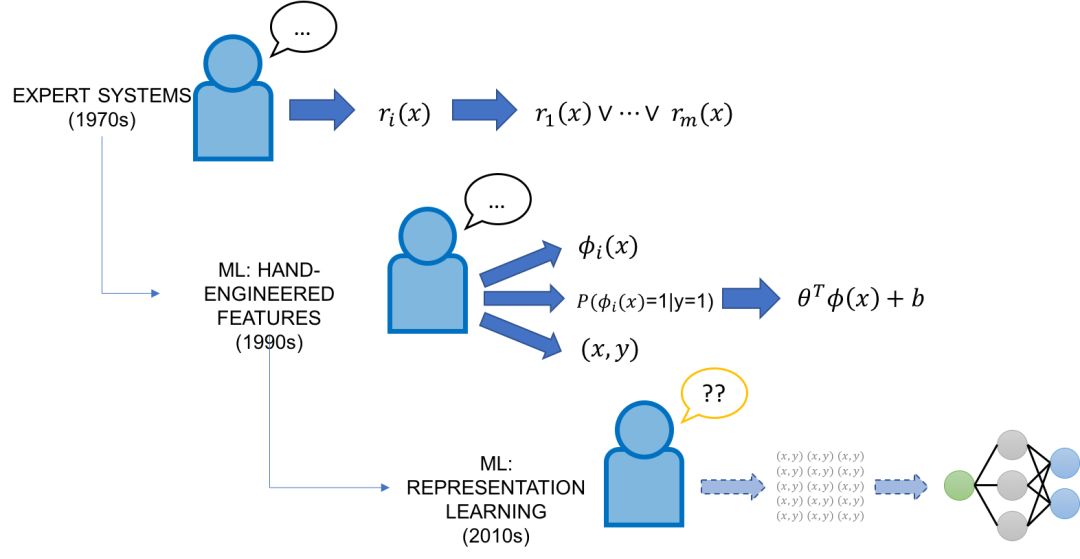
在 20 世纪 70 年代和 80 年代,AI 的重点是专家系统,它将来自领域专家的手工策划的事实和规则的知识库结合起来,并使用推理引擎来应用它们。20 世纪 90 年代,ML 开始作为将知识集成到 AI 系统的工具获得成功,并承诺以强大而灵活的方式从标记的训练数据自动实现这一点。
经典的 (非表示学习)ML 方法通常有两个领域专家输入端口。首先,这些模型通常比现代模型的复杂度要低得多,这意味着可以使用更少的手工标记数据。其次,这些模型依赖于手工设计的特性,这些特性为编码、修改和与模型的数据基本表示形式交互提供了一种直接的方法。然而,特性工程不管在过去还是现在通常都被认为是 ML 专家的任务,他们通常会花费整个博士生涯来为特定的任务设计特性。
进入深度学习模型:由于它们具有跨许多领域和任务自动学习表示的强大能力,它们在很大程度上避免了特性工程的任务。然而,它们大部分是完整的黑盒子,除了标记大量的训练集和调整网络架构外,普通开发人员对它们几乎没有控制权。在许多意义上,它们代表了旧的专家系统脆弱但易于控制的规则的对立面 —— 它们灵活但难以控制。
这使我们从一个略微不同的角度回到了最初的问题:我们如何利用我们的领域知识或任务专业知识来编写现代深度学习模型?有没有办法将旧的基于规则的专家系统的直接性与这些现代 ML 方法的灵活性和强大功能结合起来?
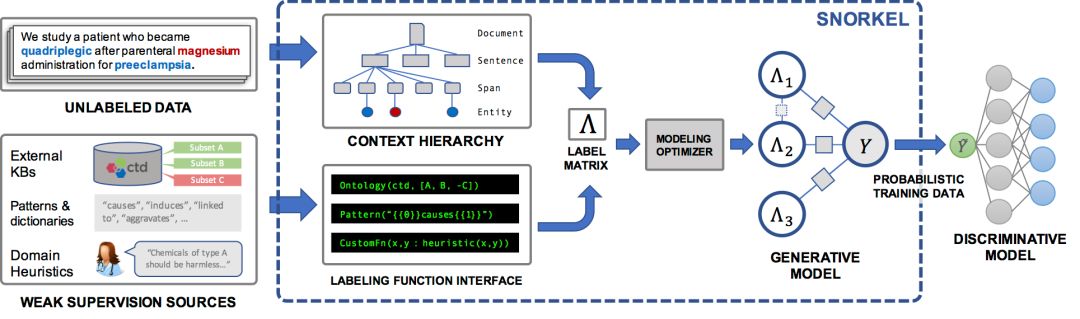
Snorkel 是我们为支持和探索这种与 ML 的新型交互而构建的一个系统。在 Snorkel中,我们不使用手工标记的训练数据,而是要求用户编写标记函数 (labeling functions, LF),即用于标记未标记数据子集的黑盒代码片段。
然后,我们可以使用一组这样的 LF 来为 ML 模型标记训练数据。因为标记函数只是任意的代码片段,所以它们可以对任意信号进行编码:模式、启发式、外部数据资源、来自群众工作者的嘈杂标签、弱分类器等等。而且,作为代码,我们可以获得所有其他相关的好处,比如模块化、可重用性和可调试性。例如,如果我们的建模目标发生了变化,我们可以调整标记函数来快速适应!
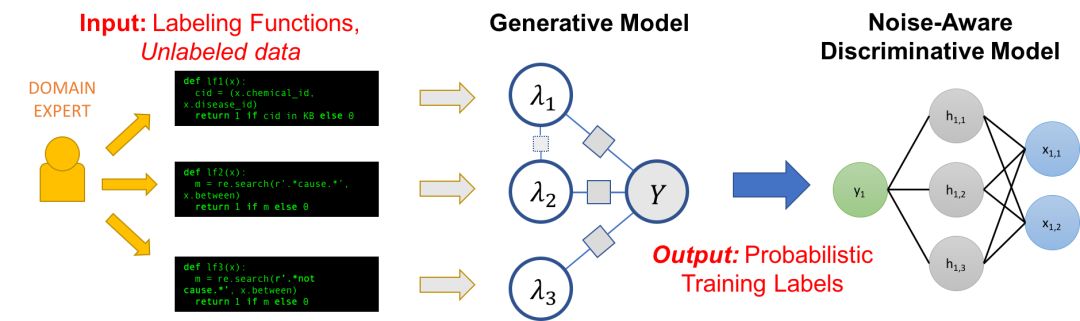
一个问题是,标记函数会产生有噪声的输出,这些输出可能会重叠和冲突,从而产生不太理想的训练标签。在 Snorkel 中,我们使用数据编程方法对这些标签进行去噪,该方法包括三个步骤:
1. 我们将标记函数应用于未标记的数据。
2. 我们使用一个生成模型来在没有任何标记数据的条件下学习标记函数的准确性,并相应地对它们的输出进行加权。我们甚至可以自动学习它们的关联结构。
3. 生成模型输出一组概率训练标签,我们可以使用这些标签来训练一个强大、灵活的判别模型 (如深度神经网络),它将泛化到标记函数表示的信号之外。
可以认为,这整个 pipeline 为 “编程”ML 模型提供了一种简单、稳健且与模型无关的方法!
从生物医学文献中提取结构化信息是最能激励我们的应用之一:大量有用的信息被有效地锁在数百万篇科学论文的密集非结构化文本中。我们希望用机器学习来提取这些信息,进而使用这些信息来诊断遗传性疾病。
考虑这样一个任务:从科学文献中提取某种化学 - 疾病的关系。我们可能没有足够大的标记训练数据集来完成这项任务。然而,在生物医学领域,存在着丰富的知识本体、词典等资源,其中包括各种化学与疾病名称数据、各种类型的已知化学 - 疾病关系数据库等,我们可以利用这些资源来为我们的任务提供弱监督。此外,我们还可以与生物学领域的合作者一起提出一系列特定于任务的启发式、正则表达式模式、经验法则和负标签生成策略。

在我们的方法中,我们认为标记函数隐含地描述了一个生成模型。让我们来快速复习一下:给定数据点 x,以及我们想要预测的未知标签 y,在判别方法中,我们直接对P(y|x) 建模,而在生成方法中,我们对 P(x,y) = P(x|y)P(y) 建模。在我们的例子中,我们建模一个训练集标记的过程 P(L,y),其中 L 是由对象 x 的标记函数生成的标签,y 是对应的 (未知的) 真实标签。通过学习生成模型,并直接估计 P(L|y),我们本质上是在根据它们如何重叠和冲突来学习标记函数的相对准确性 (注意,我们不需要知道 y!)
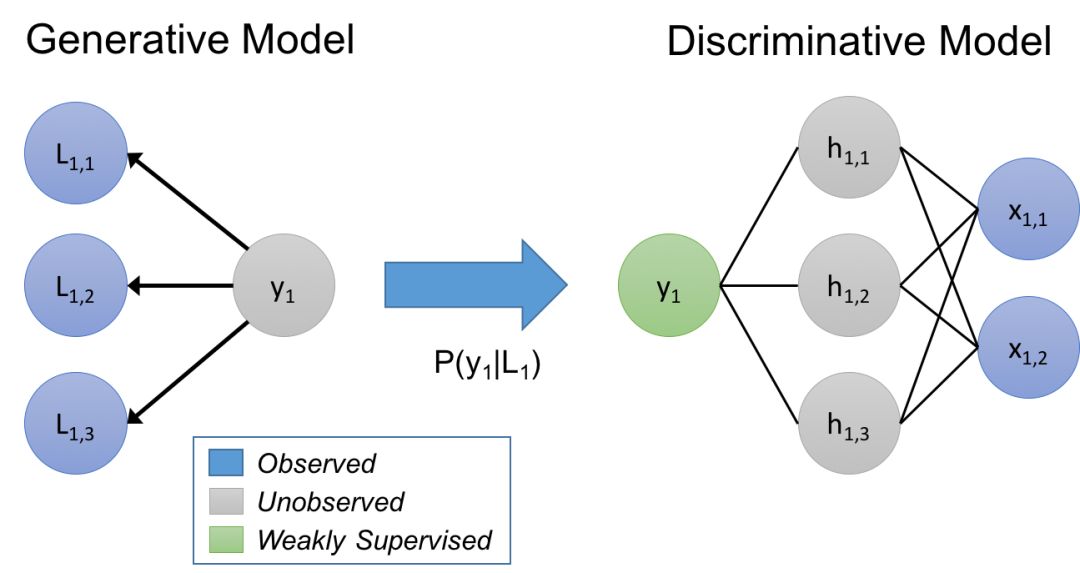
我们使用这个估计的生成模型在标签函数上训练一个噪声感知版本的最终判别模型。为了做到这一点,生成模型推断出训练数据的未知标签的概率,然后我们最小化关于这些概率的判别模型的预期损失。
估计这些生成模型的参数可能非常棘手,特别是当使用的标记函数之间存在统计依赖性时。在 Data Programming: Creating Large Training Sets, Quickly(https://arxiv.org/abs/1605.07723) 这篇论文中,我们证明了给定足够的标记函数的条件下,可以得到与监督方法相同的 asymptotic scaling。我们还研究了如何在不使用标记数据的情况下学习标记函数之间的相关性,以及如何显著提高性能。
在我们最近发表的关于 Snorkel 的论文 (https://arxiv.org/abs/1711.10160) 中,我们发现在各种实际应用中,这种与现代 ML 模型交互的新方法非常有效!包括:
1. 在一个关于 Snorkel 的研讨会上,我们进行了一项用户研究,比较了教 SMEs 使用Snorkel 的效率,以及花同样的时间进行纯手工标记数据的效率。我们发现,使用Snorkel 构建模型不仅快了 2.8 倍,而且平均预测性能也提高了 45.5%。
2. 在与斯坦福大学、美国退伍军人事务部和美国食品和药物管理局的研究人员合作的两个真实的文本关系提取任务,以及其他四个基准文本和图像任务中,我们发现,与baseline 技术相比,Snorkel 平均提高了 132%。
3. 我们探索了如何对用户提供的标记函数建模的新的权衡空间,从而得到了一个基于规则的优化器,用于加速迭代开发周期。
我们实验室正在进行各种努力,将 Snorkel 设想的弱监督交互模型扩展到其他模式,如格式丰富的数据和图像、使用自然语言的监督任务和自动生成标签函数!
在技术方面,我们感兴趣的是扩展 Snorkel 的核心数据编程模型,使其更容易指定具有更高级别接口(如自然语言) 的标记函数,以及结合其他类型的弱监督 (如数据增强)。
多任务学习 (MTL) 场景的普及也引发了这样一个问题:当嘈杂的、可能相关的标签源现在要标记多个相关任务时会发生什么?我们是否可以通过对这些任务进行联合建模来获益?我们在一个新的多任务感知版本的 Snorkel,即 Snorkel MeTaL 中解决了这些问题,它可以支持多任务弱监管源,为一个或多个相关任务提供噪声标签。
我们考虑的一个例子是设置具有不同粒度的标签源。例如,假设我们打算训练一个细粒度的命名实体识别 (NER) 模型来标记特定类型的人和位置,并且我们有一些细粒度的嘈杂标签,例如标记 “律师” 与 “医生”,或 “银行” 与 “医院”;以及有些是粗粒度的,例如标记 “人” 与 “地点”。通过将这些资源表示为标记不同层次相关的任务,我们可以联合建模它们的准确性,并重新加权和组合它们的多任务标签,从而创建更清晰、智能聚合的多任务训练数据,从而提高最终 MTL 模型的性能。
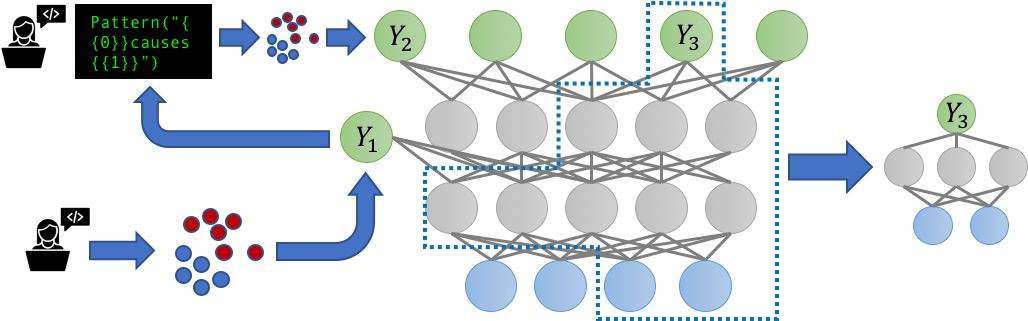
我们相信,为 MTL 构建数据管理系统最激动人心的方面将围绕大规模多任务机制(massively multi-task regime),在这种机制中,数十到数百个弱监督 (因而高度动态)的任务以复杂、多样的方式交互。
虽然迄今为止大多数 MTL 工作都考虑最多处理由静态手工标记训练集定义的少数几项任务,但世界正在迅速发展成组织 (无论是大公司、学术实验室还是在线社区) 都要维护数以百计的弱监督、快速变化且相互依赖的建模任务。此外,由于这些任务是弱监督的,开发人员可以在数小时或数天内 (而不是数月或数年) 添加、删除或更改任务 (即训练集),这可能需要重新训练整个模型。
在最近的一篇论文 The Role of Massively Multi-Task and Weak Supervision in Software 2.0 (http://cidrdb.org/cidr2019/papers/p58-ratner-cidr19.pdf) 中,我们概述了针对上述问题的一些初步想法,设想了一个大规模的多任务设置,其中 MTL 模型有效地用作一个训练由不同开发人员弱标记的数据的中央存储库,然后组合在一个中央“mother” 多任务模型中。
不管确切的形式因素是什么,很明显,MTL 技术在未来有许多令人兴奋的进展 —— 不仅是新的模型架构,而且还与迁移学习方法、新的弱监督方法、新的软件开发和系统范例日益统一。
原文:
https://ai.stanford.edu/blog/weak-supervision/
Snorkel:
http://snorkel.stanford.edu/
新智元春季招聘开启,一起弄潮AI之巅!
岗位详情请戳:
【2019新智元 AI 技术峰会倒计时12天】
2019年的3月27日,新智元再汇AI之力,在北京泰富酒店举办AI开年盛典——2019新智元AI技术峰会。峰会以“智能云•芯世界“为主题,聚焦智能云和AI芯片的发展,重塑未来AI世界格局。
同时,新智元将在峰会现场权威发布若干AI白皮书,聚焦产业链的创新活跃,评述华人AI学者的影响力,助力中国在世界级的AI竞争中实现超越。
购票二维码

活动行购票链接:http://hdxu.cn/9Lb5U
点击文末“阅读原文”,马上参会!





