【深度学习】深度学习的核心:掌握训练数据的方法

Hello World!
今天我们将讨论深度学习中最核心的问题之一:训练数据。深度学习已经在现实世界得到了广泛运用,例如:无人驾驶汽车,收据识别,道路缺陷自动检测,以及交互式电影推荐等等。
我们大部分的时间并不是花在构建神经网络上,而是处理训练数据。深度学习需要大量的数据,然而有时候仅仅标注一张图像就需要花费一个小时的时间!所以我们一直在考虑:能否找到一个方法来提升我们的工作效率?是的,我们找到了。

现在,我们很自豪的将Supervisely令人惊叹的新特性公诸于世:支持AI的标注工具来更快速地分割图像上的对象。
在本文中,我们将重点介绍计算机视觉,但是,类似的思路也可用在大量不同类型的数据上,例如文本数据、音频数据、传感器数据、医疗数据等等。
重点:数据越多,AI越智能
让我们以吴恩达非常著名的幻灯片开始,首先对其进行小小的修改。
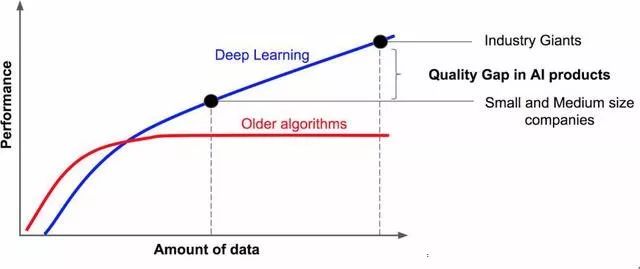
深度学习的表现优于其它机器学习算法早已不是什么秘密。从上图可以得出以下结论。
结论 0:AI产品需要数据。
结论 1:获得的数据越多,AI就会越智能。
结论 2:行业巨头所拥有的数据量远超其它企业。
结论 3:AI产品的质量差距是由其所拥有的数据量决定的。
因此,网络架构对AI系统的表现影响很大,但是训练数据的多少对系统表现的影响最大。致力于数据收集的公司可以提供更好的AI产品并获得巨大的成功。
常见错误:AI全都是关于构建神经网络的。
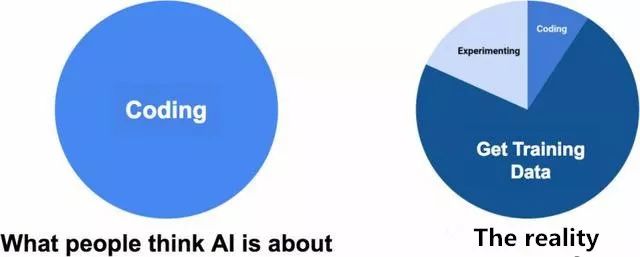
如上图所示,当人们一想到AI,就会想到算法,但是也应该考虑到数据。算法是免费的:谷歌和其他巨头更倾向于向世界分享他们最先进的(state-of-the-art)研究成果,但是他们从不会共享数据。

许多人已经跳上了人工智能炒作的列车,并且创造了极棒的构建和训练神经网络的工具,然而关注训练数据的人却少的可怜。当企业打算将人工智能转换成实际应用时,会倾尽全部工具用于训练神经网络,却没有用于开发训练数据上的工具。
吴恩达说论文已经足够了,现在让我们来构建AI吧!
好主意,我们完全赞同。目前有许多论文和开源成果论述了最先进的(state of the art )且涵盖所有的实际应用的神经网络架构。想象一下,你获得了一个价值10亿美元的新想法。首先想到的肯定不会是:我将使用哪种类型的神经网络?最有可能的是:我在哪里可以得到能建立MVP的数据?

让我们来寻找一些有效的方法训练数据,可行的方法如下:
1.开源数据集。深度神经网络(DNN)的价值是用于训练数据,在计算机视觉研究中,大多数可用数据都是针对特定研究小组所研究的课题而设计的,通常对于新研究人员来说,需要搜集更多额外的数据去解决他们自己的课题。这就是在大多数情况下开源数据集并不是一个解决方案的原因。
2.人工数据。它适用于类似OCR文字识别或者是文本检测,然而很多实例(如人脸识别,医学影像等)表明人工数据很难甚至是不可能产生,通常的做法是将人工数据和带标注的图像相结合使用。
3.Web。自动收集高质量的训练数据是很难的,通常我们会对收集的训练数据进行修正和过滤。
4.外面订购图像标注服务。一些公司提供这样的服务,我们也不例外。但其很大的缺点是不能进行快速的迭代。通常,即使是数据专家也不确定如何标注。通常的顺序是做迭代研究:标注图像的一小部分→建立神经网络架构 →检查结果。每个新的标注都将会影响后续的标注。
5.手动标注图像。仅适用于你自己的工作,领域内的专业知识是很关键的。医学影像就是个很好的例子:只有医生知道肿瘤在哪里。手动注解图像这个过程很耗时,但是如果你想要一个定制化的AI,也没有其他办法。
正如我们所看到的,其实并没有万能方法,最常见的方案是创建我们自己任务特定的训练数据,形成人工数据,如果可能的话再整合到公共数据集中。这其中的关键是,你必须为特定的任务建立自己独一无二的数据集。
让我们深入学习来构建深度学习
深度学习接近于数据匮乏,且其性能极度依赖于可供训练数据的数量。
通过实例我们可以看出标注的过程有多困难。这里是标注过程所花费时间的一些原始数据,例如使用Cityscapes数据集(用于无人驾驶),在对Cityscapes数据集中单个图像的精细像素级的标注平均需要花费1.5h,如果标注5000个图像,则需要花费5000*1.5=7500h。假设1h=$10(美国最低工资),那么仅仅是标注该数据集就需要花费约$7.5万左右(不包括其他额外的成本)。同样吃惊的是,像这样一家拥有1000名做无人驾驶图像标注员工的公司,只不过是冰山一角。
神经网络能否帮助我们提高图像标注的效率呢?我们可不是第一个试图回答这一问题的人。
半自动化实例标注很早就开始使用了, 有很多经典的方法可提高标注的效率,如超像素块算法(Superpixels),分水岭算法(Watershed),GrabCut分割算法等。近几年,研究人员试图用深度学习完成这一任务(link1, link2, link3),这些经典的算法有很多缺陷,需要很多超参数对每一幅图像进行检索,难以对结果进行标准化和修正。最新的基于深度学习的成果要好很多,但在大多情况下这些成果是不开源的。我们是第一个为每个人提供基于AI的标注工具的人,我们自己独立设计了与上边三个links概念类似的神经网络架构。它有一个很大的优势:我们的神经网络不需要对对象实例进行分类。这就意味着,可以对行人、汽车、路面上的凹陷处、医学影像上的肿瘤、室内场景、食物成分、卫星上的物体等等进行分割。
那么,它是如何工作的呢?如下图所示:

你只需要剪裁感兴趣的对象,然后神经网络将会对其进行分割。人机交互非常重要,你可以点击图像的内部和外部标签进行修正错误。
语义分割是将图像划分为多个预定义语义类别的区域,与它不同的是,我们的交互式图像分割旨在根据用户的输入提取其感兴趣的对象。
交互式分割的主要目标是根据用户最少的操作,即可精确的提取对象以改善整体的用户体验,因此我们大大提高了标注的效率。
这是我们的第一次尝试,当然在有些情况下,好的标注依然会有缺陷。我们会不断的提高质量,并做出适用于领域适应性的简单方法:在不编码的情况下,为适应内部特定的任务自定义工具。
结语
数据是深度学习的关键,训练数据是费时和高代价的。但是我们和深度学习的团体积极尝试着去解决训练数据的问题,并且成功的迈出了第一步,希望能够在以后提供更好的解决方案。
来源:北京物联网智能技术应用协会
深度图像特征在推荐和广告中的应用
机器不学习
CNN 是一个简单的网络结构,初学者一般从MNIST入手,提及CNN第一印象可能只有经典的图像分类的那个model。深入了解才会发现,学术圈和工业界是如何通过稍稍改变 Feature Map 之后的结构和目标函数等实现各种复杂任务,这其中迸发的想象力让人激动。
1.Image Feature Learning for Cold Start Problem in Display Advertising
“Image Feature Learning for Cold Start Problem in Display Advertising“ 这篇文章发表在ijcai15,是腾讯把图像特征应用到广告ctr预估的总结,同时也解答了广告中什么区域对点击率影响较大。这篇文章是较早把图像的深度特征用于点击率预估的工作之一,2015年的时候,推荐学术界里在深度学习方面起到重要影响的文章 Wide and Deep 、Youtube Rec with DNN 和一些 RNN 做推荐的方法尚未出现,高维稀疏特征的one hot encode embedding 成低维稠密特征的方法尚未被大众熟悉,所以这篇文章的做法并不是直接端到端的结构,而是通过CNN 抽取图像特征,然后用到 Logistic Regression(LR) 等常见的CTR模型中使用。
下面进入广告时间,猜猜什么因素导致左边点击率高,文末有答案。

文章主要想法分为两步,第一步,利用卷积神经网络,实现从原始像素到用户点击反馈的 end-to-end 的图像特征学习。第二步,训练好的CNN可以抽取与点击率相关的图像特征,外加广告属性的特征,这些特征综合起来训练LR等模型来预估最终点击率。
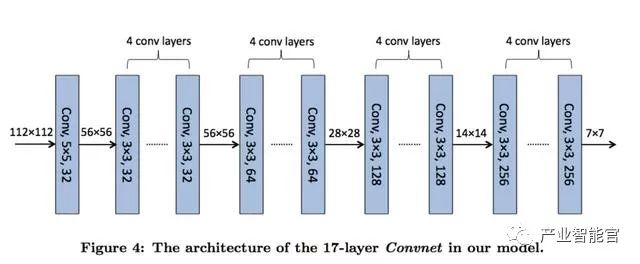
抽取图像特征的网络结构如下:
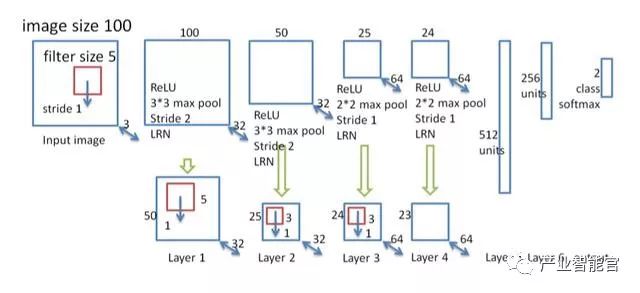
100*100像素图像输入 => 4层conv+pool => 3层FC => 二分类softmax(点击率)
视觉元素的位置重要性
传统的图像分类只关心是否包含某个视觉元素,而不关心该视觉元素在图像中的位置。对于展示面积比较大的广告图片,因为用户的视觉焦点一般在图像中心,关键的视觉元素在图像中的位置对于点击率有明显影响,因此设计的卷积神经网络的最后一层卷积输出层的feature map应该稍大,以传递原图的位置信息。
数据集
样本规模:470亿样本,样本来源于腾讯在线广告日志,包含5种类别,5 种展示位置。样本数据量太大,直接用CNN训练在时间上不可接受,因此作者吧相同的图片聚合一起,形成二维样本<未点击数,点击数>。文章没有提到的一点是,<1000,10> 和 <100, 1> 从统计上来说点击率相同,训练的时候有什么区别?我猜测对梯度应该有一定影响,样本数量越大,步长越长。
数据增强:25万张广告图片,划分为22万张训练集和3.3万张测试集。训练集缩放裁剪到 128 * 128像素大小,然后随机裁剪 100 * 100 子图作为卷积网络的输入。测试集随机裁剪 10 次,用输出概率的平均值作为最后的预测结果。
单机GPU训练 2 天
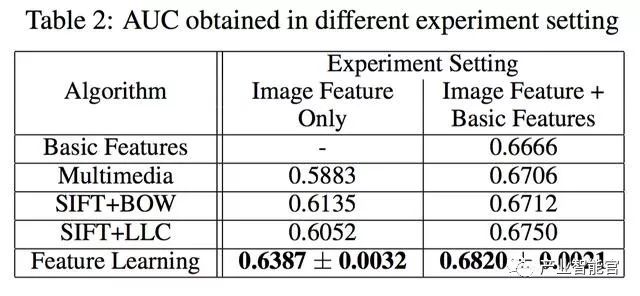
实验结果
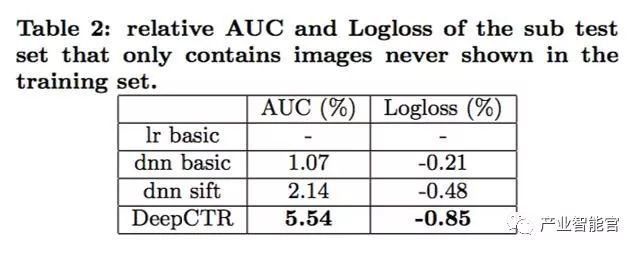
做了两种版本的比较,第一种只用图像特征,第二种包括广告id、类目id和展示位置id三个额外特征,分别用LR模型预测ctr,用AUC离线评测:
什么影响点击率
用可视化方法,可以观察d奥图片模特人脸区域和文字区域对点击率影响比较大:

2.Deep CTR Prediction in Display Advertising
这篇文章发表在 ACM MM16,是阿里当时的实习生做的,现在应该是正式员工了。与腾讯那篇“Image Feature Learning for Cold Start Problem in Display Advertising” 不同的是,这篇文章把特征提取与点击率预估整合在一起,做到了end to end的训练。
同样来看一个例子:

b 比 a 点击率低,是因为 b 的主体和背景的对比度太低;d 比 c 点击,是因为用户对多男模的图片不太喜欢,这种case 跟腾讯广告同学举得还不太一样
整体的网络架构如下:
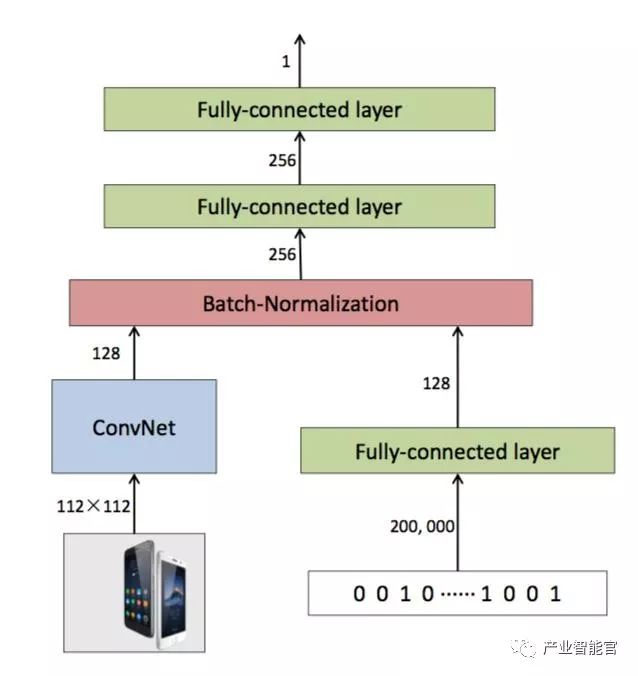
左侧的卷积网络用来提取图像特征,结构类似于 VGG16。因为上面网络结构较为复杂,可以先用图像分类任务来解决CNN的预训练问题。
右侧是全连接层,类似于embedding,区别在于全连接层有非线性变换。输入层是 one-hot-encode 形式,约 20w维,非常稀疏,在计算的时候,很多0输入节点的前向后向计算都可省略,特征存储也可以用下标的方式输入,减少计算和存储资源消耗。
广告的样本数量很大,但是CNN计算较为耗时,如果按照 PSLR 的方式去批次训练,训练过程过于漫长。作者把有相同图片的样本聚合在一起,相同图片只用计算一次CNN。举个例子,batchsize 为 5000,图片只有 10张,则CNN只用计算 10 次,右侧的全连接层非常稀疏,计算效率很高,5000个样本的计算时间可能比10张图片CNN计算时间还短。
实验对比
5千万样本,10w张图片
对比实验的结果:
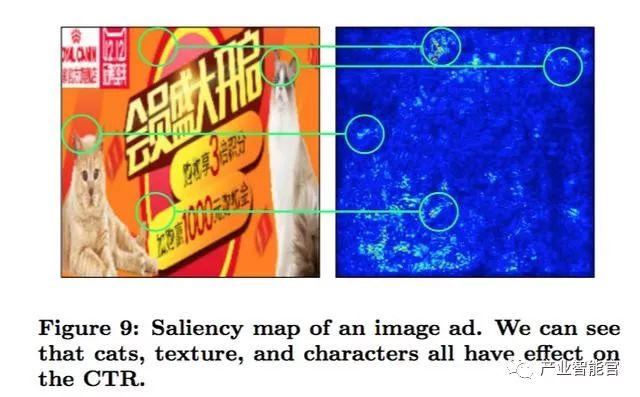
特征区域的可视化
图片中的猫、纹理、文字对点击率有影响
3.Image Matters: Jointly Train Advertising CTR Model with Image Representation of Ad and User Behavior
阿里 2017 发表在 arxiv 的文章,与前面文章的区别在于,图像不单可以表征广告,用户点过的图像集合也可以用来表征用户,比如当前图片与用户点过的某张图片很相似,用户的点击概率就会比较高。文章利用广告相关id特征、用户相关id特征、广告图像特征、用户点击过的图像特征共同建模,end-to-end训练,预测最终的ctr。这篇文章对标 youtube 那篇做推荐的文章Deep Neural Networks for YouTube Recommendations里面的 rank model部分。
点击率模型经常用到的 parameter server logistic regression(PSLR) 更擅长于记忆,而不是泛化,所以即使在rank模型中,遇到新的 id 时,还是存在冷启动问题。图像特征重要,相同的广告id用不同的图片,点击率可能完全不一样,所以图像特征其实有比较好的泛化能力,不同的广告用同一张图像,在用户无法分辨的情况下,点击率相同。
整个模型框架如下:
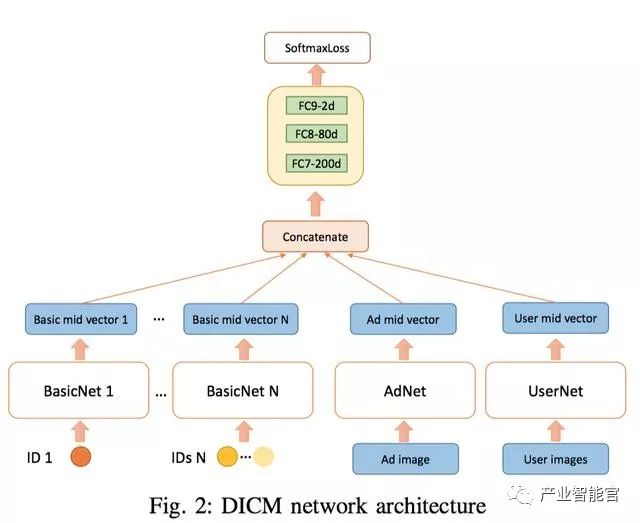
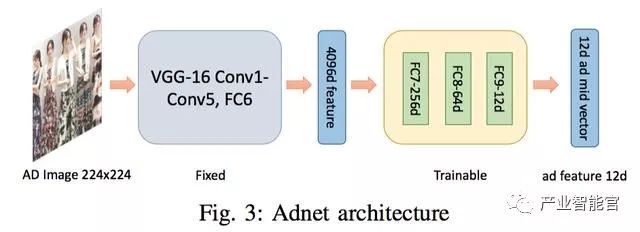
basicNet 和阿里那篇 Deep CTR Prediction in Display Advertising 一脉相承,通过全连接做 id 特征的向量化。AdNet采用VGG16的前14层,从图像提取 4096 维特征。可能是由于网络结果过于复杂,这里的卷积层是固定的,在rank部分不会调整,这样做也有一个好处,可以先把所有图片的 4096 维特征预先计算出来,CNN不用多次重复计算,也不需要更新权重,训练效率会高很多。固定CNN实际上也有不得已的地方,本文的创新点在于利用了UserNet,但是UseNet带来的一个弊端是,无法像之前两篇文章里将相同图片的样本聚合起来减少CNN部分的计算,因为UserNet的输入平均是37张图片的排列组合。在4096 维特征后面,又加入可训练的三个全连接层,把一张图像的特征降低到 12 维。
UserNet 的结构与 AdNet一致,区别在于,用户点击包含多张图片(平均37张),如何把多张图片的12维特征整合成单独的12维,其中有一些简单的做法如 sum、avg、max,也有一些复杂的 attentive方法。
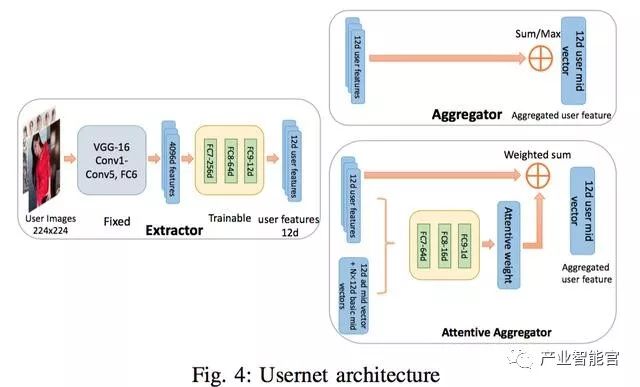
根据后面训练的attentive权重来看,用户对相似图片的权重明显大。
实验对比
39亿样本,2亿图片,20台GPU集群训练,17个小时
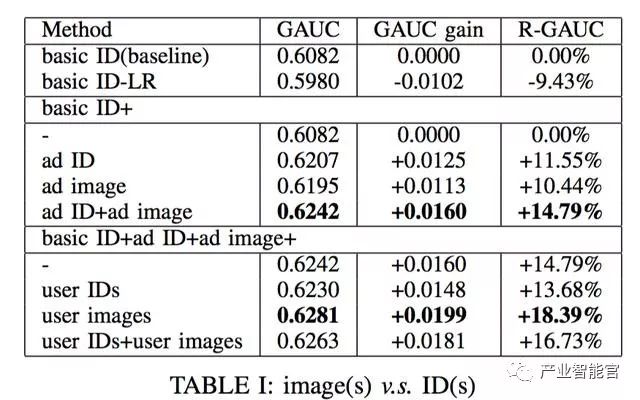
实验结果可以看到图像特征有一些提升,但是在添加用户点击行为中的图像特征,边际效益不是那么高。


人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“数据科学家”、“赛博物理”、“供应链金融”。
官方网站:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com




