金字塔卷积PyConv来了!"即插即用",提升你的网络性能
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
导读:该文参考SIFT的多尺度特征提取思路设计了一种新颖的金字塔卷积,它不用于其他类似方法的关键点在于:卷积核的多尺度。同时为了尽可能的降低整体计算复杂度,在每个group内再一次进行组卷积,以确保金字塔卷积的计算量与标准卷积的计算量相当。笔者认为这篇论文思想简单,易于实现,效果惊人。推荐各位稍微花点时间了解一下这篇文章(注:亮点在Appendix部分)
论文:https://arxiv.org/abs/2006.11538
代码:https://github.com/iduta/pyconv
Abstract
该文提出一种金字塔卷积(Pyramidal Convolution, PyConv),它可以在多个滤波器尺度对输入进行处理。PyConv包含一个核金字塔,每一层包含不同类型的滤波器(滤波器的大小与深度可变,因此可以提取不同尺度的细节信息)。除了上述提到的可以提取多尺度信息外,相比标准卷积,PyConv实现高效,即不会提升额外的计算量与参数量。更进一步,它更为灵活并具有可扩展性,为不同的应用提升了更大的架构设计空间。
PyConv几乎可以对每个CV任务都有正面影响,作者基于PyConv对四大主流任务(图像分类、视频分类、目标检测以及语义分割)进行了架构设计。相比baseline,所提方法取得了一致性的性能提升。比如在图像分类任务上,所提50层模型优于ResNet152,同时具有更少的参数量(2.39x-fewer)、计算复杂度(2.52x-fewer)以及更少的层数和;在语义分割任务上,它在ADE20K数据集上指标达到SOTA(注:好像并不如ResNeSt的指标)。
Introduction
首先,我们先来说明一下已有CNN网络架构在感受野擀面存在的两个问题:
-
尽管当前主流CNN网络架构理论具有非常大的感受野(包含输入的大部分、甚至全含整个输入),但是有研究表明:实际CNN的感受野要比理论小的多(2.7x-less); -
已有的下采样方案(如池化、stride卷积)会造成信息的损失,进而影响模型的性能。
然后,我们再来简单介绍一下实际场景中物体的尺度信息。以下图为例,包含室内与室外两个场景及其对应的语义标签。从图中可以看到:部分物体具有非常大的空间形式(比如建筑物、树以及沙发),部分物体具有非常小的空间表现形式(比如行人、书本等)。甚至同一物体具有非常大的可变的空间变现形式(比如室外场景中的汽车)。

上述这种空间变大巨大的表现形式是标准卷积所无法有效提取的,而CV的终极目标是:提取输入的多尺度信息。在这方面最为知名的当属SIFT,它可以从不同尺度提取特征描述算子。然而深度学习中的卷积却并未具有类似SIFT这种提取多尺度特征的能力。
最后,我们再来说明一下作者为解决上述挑战而提出的几点创新:
-
(1) 作者引入一种金字塔卷积(PyConv),它包含不同尺度与深度的卷积核,进而确保了多尺度特征的提取; -
(2) 作者为图像分类任务提出了两种网络架构并以极大优势优于baseline,同时具有更少的参数量与计算复杂度; -
(3) 作者为语义分割任务提出了一个新的框架:一种新颖的Head用于对backbone提取的特征可以从局部到全局进行上下文信息特征提取,并在场景解析方面取得了SOTA性能; -
(4) 作者基于PyConv而设计的网络架构在目标检测与视频分类任务上取得了性能的极大提升。
Pyramidal Convolution
下图a给出了标准卷积的示意图,它包含单一类型的核:卷积核的空间分辨率为 (应用最多的当属 ,即 )而深度则等于输入特征通道数 。那么执行 个相同分辨率与深度卷积核得到 个输出特征。因此,标准卷积的参数量与计算量分别为: , 。
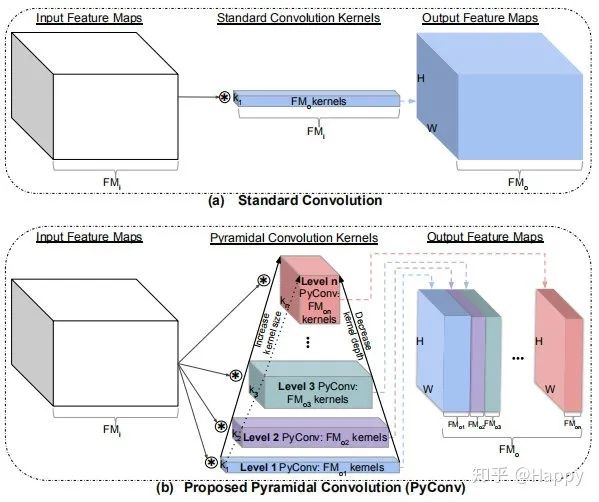
上图b给出了所提PyCOnv的示意图,它包含一个由n层不同类型核构成的金字塔。PyConv的目标是:在不提升计算复杂或参数量的前提下采用多尺度核对输入进行处理。PyConv每一层的核包含不同的空间尺寸(自下而上提升),随卷积核的提升而逐渐降低核的深度。
为使PyConv在不同层使用不同深度的卷积核,需要将输入特征划分为不同的组并独立的进行卷积计算,称之为组卷积(见下图示例)。不知各位有没有觉得这个思想跟谷歌的MixNet思想非常相似,MixNet中也是采用了类似组卷积方式进行不同尺寸卷积核计算,文末附对比分析。
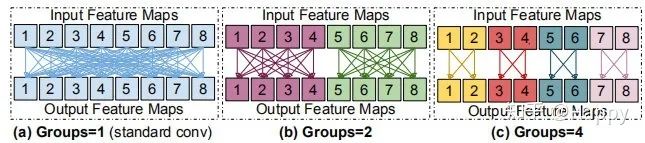
但是,需要注意哈:组卷积中每组的通道数是相同的。MixNet中的也是相同的,而PyConv则是不相同的,可以说MixNet是PyConv的一个特例。每组特征通道数上的区别构成MixConv与PyConv的最大区别所在。
假设PyConv的输入包含 个通道数,PyConv每一层的卷积核尺寸为 ,深度为 ,对应的输出特征维度为 。PyConv的参数量与计算复杂度如下:
其中 。
注:如果每一层输出的通道数相同,那么每一层的参数量与计算复杂度就会分布比较均匀。基于上述描述,可以看到:PyConv的计算复杂度与标准卷积相近。
在实际应用时,作者为PyConv添加了额外的规则:每一层的通道数应当是相同的。这也就要求了PyConv的输入通道数应当是2的幂次。
所提PyConv具有这样几个优点:
-
Multi-scale Processing. 这个特性是非常明显的,卷积核尺寸是多尺度的嘛; -
Efficiency. PyConv可以通过并行的方式进行计算,因此计算高效(组卷积在GPU上的效率好像并不高,反而更适合CPU); -
Flexibility. 由于具有与标准卷积相近的参数量和计算复杂度,那么用户可以更灵活的去调节PyConv的超参数(比如层数、不同层的输出通道数,不同深度设置不同的PyConv参数、不同层采用不同的组数)。注:这一点又跟MixNe相似了,MixNet通过NAS方式进行搜索的。
Classification
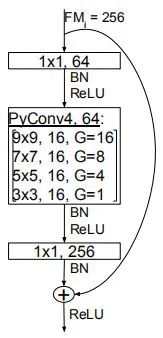
下图给出了在图像分类任务中PyConv模块示意图,它是将PyConv嵌入到Bottleneck中,这也是目前卷积改进的一种常用思路,好像没什么值得进一步深入介绍的。
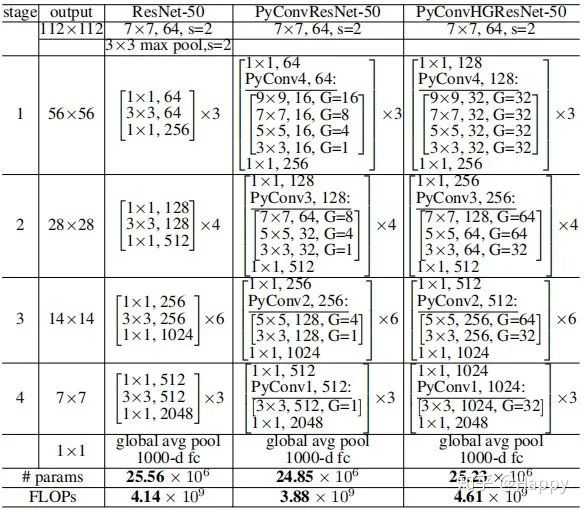
下表给出了基于上述模块构建网络的配置信息,包含PyConvResNet与PyConvHGResNet两种。配置信息还是挺详细的,好像并没有什么值得深入介绍的,表格一看就懂。PyConvHGResNet中不同层的分组数更高而已,其他基本相同。
Semantic Segmentation
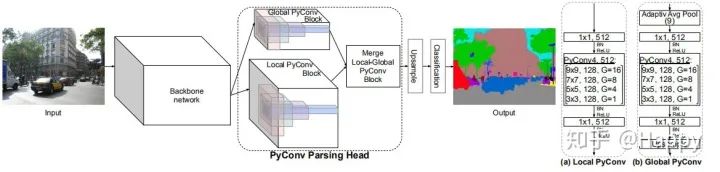
上图给出了所提PyConv在语义分割中的应用形式,作者所设计的Head同时进行局部与全局信息提取并采用了另外的一个模块进行信息集成,讲这种Head称之为PyConvPH。PyConvPH包含三个主要成分:
-
Local PyConv Block: 它主要用于小目标并进行多尺度细粒度特征提取,见上图a; -
Global PyConv Block:它主要用于捕获场景的全局信息以及大尺度目标,见上图b。 -
Merge PyConv Block:它用于对全局与局部特征融合。
Experiments
“实践是检验真理的唯一标准”,为说明所提方法的有效性。作者图像分类、语义分割、目标检测等领域进行了一系列的实验。主要结果如下:
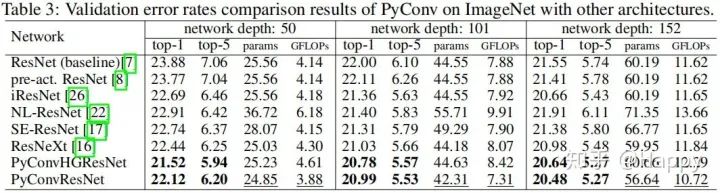
(1) 下图给出了ImageNet数据集上的指标(标准增广,未用到AutoAugment、CutMix等增广技术)。注:由于该方法主要是卷积的改进,故未与注意力等方法进行改进,加上注意力后是不是会超越ResNeSt呢?哈哈哈,甚是期待呀。
(2) 下图给出了ADE20K数据集上的指标,这个在不考虑注意力等方法的前提应当是目前最佳了吧,如果加上注意力机制应该还有提升的空间,期待各位小伙伴们去改善提升哈。

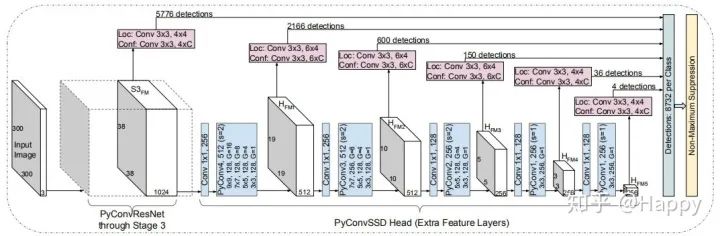
(3) 下面给出了在目标检测方面的应用与COCO数据及上的指标。更详细的实验分析,建议感兴趣的小伙伴去看原文,笔者不做过多翻译了。

Conclusion
作者提出了一种金字塔卷积,它的每一层包含不同尺度的卷积核。PyConv极大的提升了不同视觉任务的性能,同时具有高效性与灵活性。PyConv是一种“即插即用”的模块,可以轻易嵌入到不同的网络架构与应用中,比如可以尝试将其应用到图像复原(超分、降噪、增强等等)应用。
Appendix
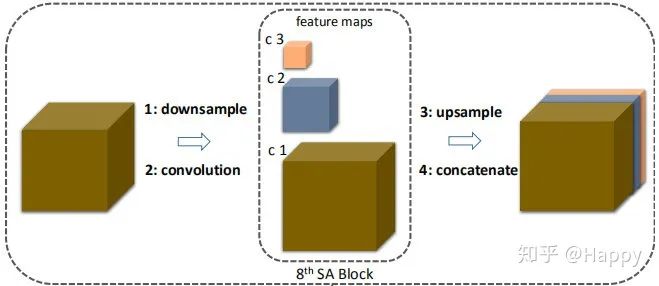
多尺度卷积并不是什么非常新颖的东西,之前已有不少论文提出了各式各样的多尺度卷积。比如商汤提出的ScaleNet,其多尺度卷积示意图如下:
再比如谷歌提出的MixConv,其多尺度卷积示意图如下:
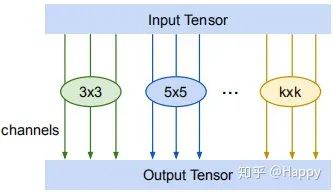
再再比如UIUC&字节跳动提出的SCN,其多尺度卷积示意图如下:
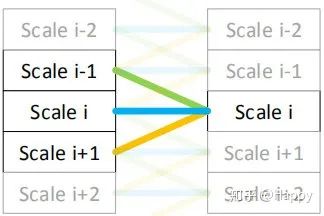
再再再比如南开大学提出的Res2Net,其实也是一种多尺度卷积,结构如下:
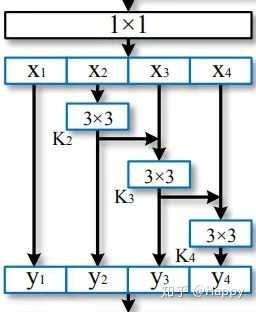
再再再再比如IBM提出的Big-LittleNet,结构如下:
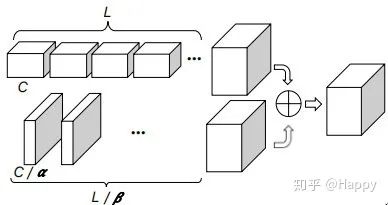
再再再再再比如Facebook提出的OctConv,不也是一种多尺度卷积吗?结构如下:
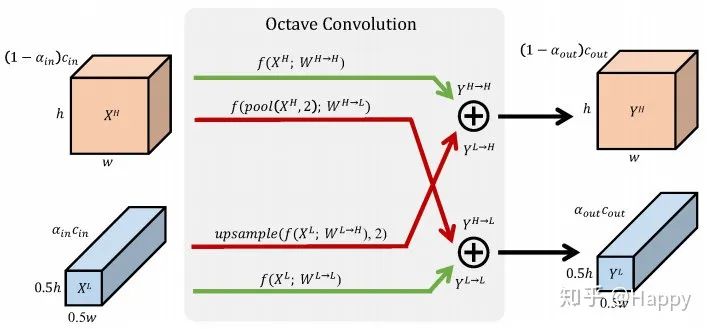
再再再再再再比如...,打住!不再比如了,看到了这里。各位小伙伴有没有发现多尺度卷积真的好多好多,知名也挺多的,比如MixNet、Res2Net、OctConv以及Big-LittleNet。那么这篇论文提出的PyConv到底跟这里提到的几种多尺度卷积有什么区别呢?
首先,第一点区别:PyConv不是通过分辨率的下采样达到感受野提升的目的,而ScaleNet、OctNet、Big-LittleNet以及SCN都是通过调整特征的分辨率方式达到提升感受野目的。这一点是与MixConv是非常相似的:通过调整卷积核的尺寸达到多尺度特征提取的目的。
然后呢,第二点区别:PyConv每一组的输入为全部输入,每组输出不同尺度的特征;这一点是与ScaleNet非常相似,而MIxConv、OctConv以及Res2Net都涉及到了输入分组。
最后一点区别:PyConv为尽可能的降低计算量,在每一组内部还进行了分组卷积。经过前述一系列的组合确保了PyConv的计算量与标准卷积相当,但实际上推理速度还是标准卷积更快,三层时推理速度,比如下图配置时,pyconv在cpu上比标准卷积慢一倍之多,呵呵。

笔者认为:PyConv的灵活性是非常巧妙的一点,它非常适合于NAS结合去搜索相关参数(层数、每一层的组卷积组数、每一层的卷积核尺寸等)。也许通过NAS搜索的网络会取得超越手工设计PyConvResNet的性能也说不定哦,这个说不定又可以水一篇paper了。O(∩_∩)O哈哈~
此外,除了PyConv与NAS结合外,还可以尝试将其嵌入到图像复原里面,虽然作者提到了会有提升,但不是还没有paper嘛,这是不是又可以水一篇paper了。O(∩_∩)O哈哈~
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~



