华为等发布《视觉Transformer转换器》综述论文,21页pdf
本文是华为诺亚联合发布的业界首个视觉变换器(Transformer)综述

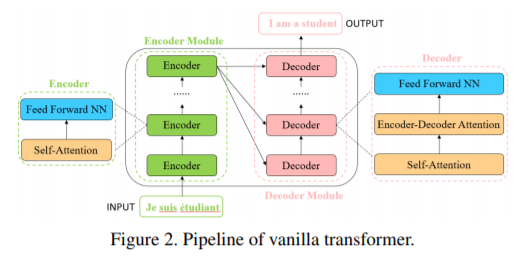
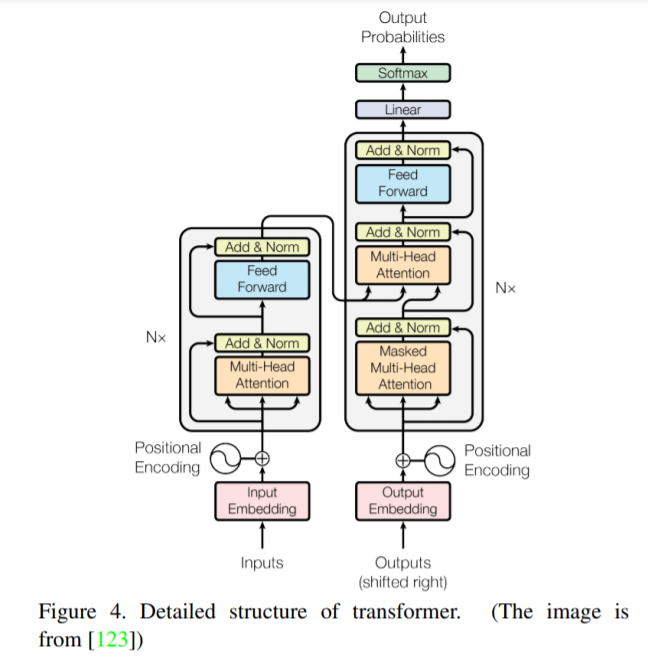
Transformer是一种主要基于自注意力机制的深度神经网络,最初应用于自然语言处理领域。受Transformer强大的表征能力的启发,研究人员提出将Transformer扩展到计算机视觉任务中。与卷积网络和循环网络等其他网络类型相比,基于Transformer的模型在各种视觉基准上都具有竞争力,甚至表现出了更好的性能。在本文中,作者对这些视觉变换器模型进行了文献综述,将它们按照不同的任务进行分类,并分析了这些方法的优缺点。具体来说,主要包括基础图像分类(basic image classification)、高级视觉(high-level vision)、低级视觉(low-level vision)和视频处理(video processing)。由于自注意力(self-attention)是变换器中的基础部件,作者简要重新审视了自注意力在计算机视觉中的位置。为变换器推向实际应用,本文包含了高效的变换器方法。最后,作者给出了视觉变换器的未来研究方向。
https://www.zhuanzhi.ai/paper/40ab7c9e9bd080f833fda87da907a6b3
深度神经网络已成为现代人工智能系统的基础设施。针对不同的任务,已经提出了不同的网络类型。多层感知(Multi-layer perception, MLP)或称全连接(full - connected, FC)网络是由多个线性层和非线性激活叠加而成的经典神经网络[104,105]。卷积神经网络(CNNs)引入了卷积层和池化层,用于处理图像等位移不变数据[68,65]。循环神经网络(RNNs)利用循环细胞来处理顺序数据或时间序列数据[106,49]。Transformer是一种新提出的神经网络,主要利用自注意力机制[5,90]来提取内在特征[123]。其中转换器网络是新近发明的一种神经网络,在人工智能方面具有广泛的应用潜力。
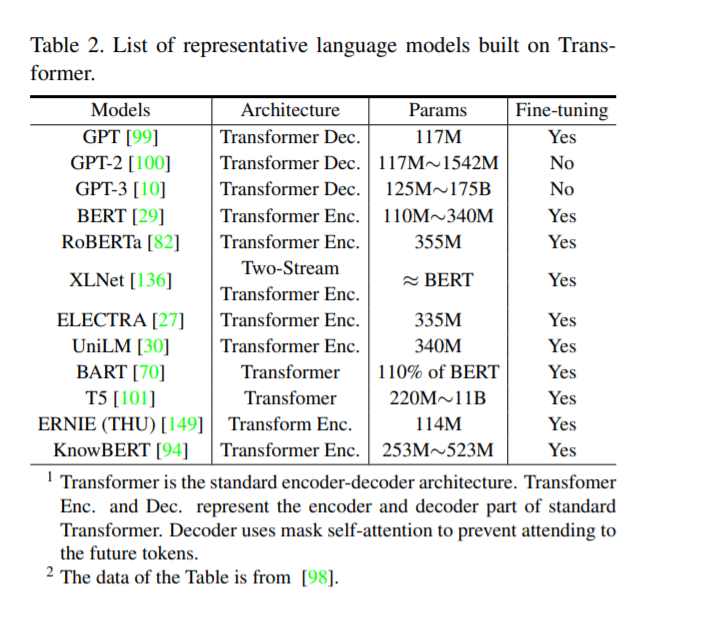
Transformer最初应用于自然语言处理(natural language processing, NLP)任务,并带来了显著的改进[123,29,10]。例如,Vaswani等人[123]首先提出了完全基于注意力机制的转换器,用于机器翻译和英语分析任务。Devlin等人[29]引入了一种新的语言表示模型,称为BERT,该模型通过联合调节左右上下文,从未标记的文本中预训练一个Transformer。BERT在当时的十一个NLP任务中获得了最先进的结果。Brown等人[10]在45TB压缩纯文本数据上预训练了一个具有1750亿参数的基于巨型Transformer的GPT-3模型,在不进行微调的情况下,在不同类型的下游自然语言任务上实现了强大的性能。这些基于Transformer的模型显示了较强的表示能力,并在自然语言处理领域取得了突破。
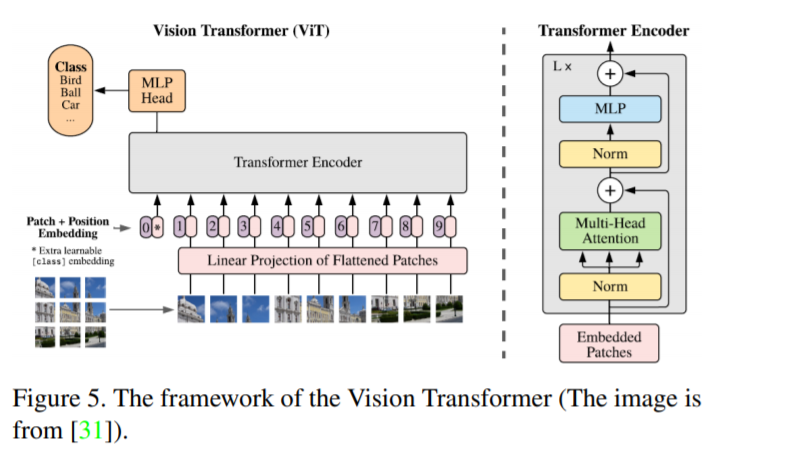
受自然语言处理中transformer 功能的启发,近年来研究人员将Transformer 扩展到计算机视觉任务中。CNN曾经是视觉应用的基础组件[47,103],但transformer作为CNN的替代品正在表现出它的能力。Chen等人[18]训练序列转换器进行自回归预测像素,实现与CNN在图像分类任务上的相匹配结果。ViT是Dosovitskiy等人[31]最近提出的一种视觉transformer 模型,它将纯transformer 直接应用于图像贴片序列,在多个图像识别基准上获得了最先进的性能。除了基本的图像分类,transformer还被用于解决更多的计算机视觉问题,如目标检测[14,155]、语义分割、图像处理和视频理解。由于其优异的性能,越来越多的基于transformer的模型被提出用于改进各种视觉任务。
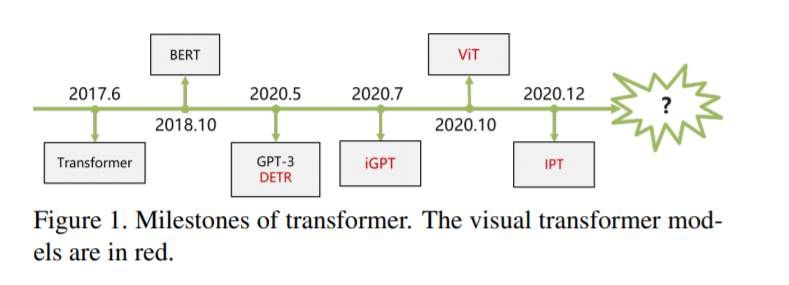
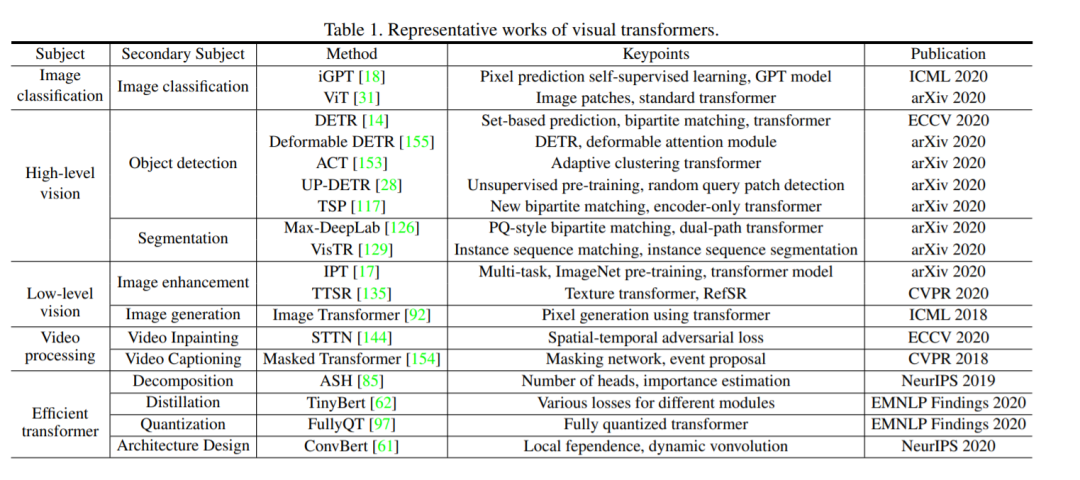
基于transformer的视觉模型如雨后春笋般涌现,这让我们很难跟上新发展的步伐。因此,对现有工作的调研是有益的,对社区是有益的。在本文中,我们对视觉transformer的最新进展进行了全面的概述,并讨论了进一步改进的潜在方向。为了获得更好的存档并方便不同主题的研究人员,我们按应用场景对transformer模型进行分类,如表1所示。具体来说,主要内容包括基本图像分类、高级视觉、低级视觉和视频处理。高级视觉处理图像中看到的东西的解释和使用[121],如对象检测、分割和车道检测。已经有许多transformer模型解决这些高级视觉任务,如DETR[14],用于目标检测的变形DETR[155]和用于分割的Max-DeepLab[126]。低级别图像处理主要涉及从图像(通常表示为图像本身)[35]中提取描述,其典型应用包括超分辨率、图像去噪和样式转换。很少有研究[17,92]在低级视觉中使用transformer,需要更多的研究。除了基于图像的任务外,视频处理也是计算机视觉的一个重要部分。由于视频的时序性,transformer自然可以应用于视频中[154,144]。与传统的CNN或RNNs相比,Transformer在这些任务上开始表现出具有竞争力的性能。本文对基于Transformer的可视化模型的研究工作进行了综述,以跟上这一领域的发展步伐。视觉Transformer的开发时间表如图1所示,我们相信会有越来越多的优秀作品被镌刻在里程碑上。
本文的其余部分组织如下。第二节首先制定了自注意力机制和标准transformer。我们在第三节中描述了在自然语言处理中transformer的方法,因为研究经验可能有助于视觉任务。接下来,第四部分是本文的主要部分,总结了图像分类、高级视觉、低级视觉和视频任务上的视觉变形模型。我们还简要回顾了CV的自注意力机制和高效Transformer方法,因为它们与我们的主题密切相关。最后,对全文进行了总结,并对今后的研究方向和面临的挑战进行了讨论。
与卷积神经网络相比,Transformer 以其优异的性能和巨大的潜力成为计算机视觉领域的研究热点。为了发现和利用Transformer的效用,正如在调研中总结的那样,近年来已经提出了一些解决方案。这些方法在基础图像分类、高级视觉、低级视觉和视频处理等视觉任务中表现出优异的性能。然而,计算机视觉Transformer的潜力还没有被充分发掘,还有一些挑战有待解决。
虽然研究者们已经提出了许多基于Transformer的模型来处理计算机视觉任务,但这些工作只是初步的解决方案,还有很大的改进空间。例如,ViT[31]的transformer 架构遵循NLP的标准transformer [123]。针对CV的改进版本还有待探索。除此之外,transformer 还需要应用在更多的任务上。
此外,现有的视觉Transformer 模型大多是针对单一任务而设计的。许多NLP模型,如GPT-3[10],都显示了Transformer在一个模型中处理多个任务的能力。在CV区域的IPT[17]还能够处理多个低分辨率的视觉任务,如超分辨率、图像去噪和去噪。我们认为,只有一种模型可以涉及更多的任务。最后,开发高效的CV转换器模型也是一个有待解决的问题。Transformer 模型通常是巨大的和计算昂贵的,例如,基本的ViT模型[31]需要180亿次浮点运算来处理一个图像。相比之下,轻量级的CNN模型GhostNet[44,45]只需约6亿次FLOPs就能达到类似的性能。虽然有几种压缩Transformer 的方法,但它们的复杂性仍然很大。而这些最初为自然语言处理设计的方法可能并不适用于CV。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“Tr21” 可以获取《华为等发布《视觉Transformer转换器》综述论文,21页pdf》专知下载链接索引






