虽然深度强化学习(RL)在机器学习领域取得了多项引人注目的成功,但由于其通常较差的数据效率和所产生的策略的有限通用性,它未能得到更广泛的采用。缓解这些限制的一个有希望的方法是,在称为元强化学习的过程中,将更好的强化学习算法的开发本身视为一个机器学习问题。元强化学习最常在问题环境中进行研究,在给定任务分布的情况下,目标是学习一种策略,该策略能够从尽可能少的数据的任务分布中适应任何新任务。**本文详细描述了元强化学习问题的设置及其主要变化。**本文讨论了如何在高层次上基于任务分布的存在和每个单独任务的可用学习预算对元强化学习研究进行聚类。使用这些聚类,综述了元强化学习算法和应用。最后,提出了使元强化学习成为深度强化学习从业者标准工具箱一部分的道路上的开放问题。
https://www.zhuanzhi.ai/paper/bbd26798bcb89638b3308c8dfc2a8e20
**1. 引言****元强化学习(Meta-reinforcement learning, meta-RL)是一种学习强化学习的机器学习(machine learning, ML)方法。**也就是说,元强化学习使用样本效率低的机器学习来学习样本效率高的强化学习算法或其组件。因此,元强化学习是元学习[225,91,94]的特殊情况,其学习算法是强化学习算法。元强化学习作为一个机器学习问题已经被研究了很长一段时间[197,199,224,198]。有趣的是,研究也显示大脑中存在meta-RL的类似物[238]。Meta-RL有潜力克服现有人类设计的RL算法的一些限制。虽然在过去几年中,深度强化学习取得了重大进展,例如掌握围棋游戏[209]、平流层气球导航[21]或机器人在挑战性地形中的运动[148]等成功故事。RL的采样效率仍然很低,这限制了它的实际应用。元强化学习可以产生比现有强化学习方法更有效的强化学习算法(组件),甚至可以为以前难以解决的问题提供解决方案。与此同时,提高样本效率的承诺伴随着两个成本。首先,元学习需要比标准学习多得多的数据,因为它训练整个学习算法(通常跨多个任务)。其次,元学习使学习算法适应元训练数据,这可能会降低其对其他数据的泛化能力。因此,元学习提供的权衡是提高测试时的样本效率,代价是训练时的样本效率和测试时的通用性。示例应用程序考虑使用机器人厨师进行自动化烹饪的任务。当这样的机器人部署在某人的厨房时,它必须学习一个特定于厨房的策略,因为每个厨房都有不同的布局和设备。由于在训练早期的随机行为,直接在一个新的厨房中从头开始训练机器人太耗时,并且有潜在的危险。一种选择是在单个训练厨房中对机器人进行预训练,然后在新的厨房中对其进行微调。然而,这种方法没有考虑到后续的微调过程。相比之下,元强化学习将在训练厨房的分布上训练机器人,以便它可以适应该分布中的任何新厨房。这可能需要学习一些参数以实现更好的微调,或者学习将部署在新厨房中的整个强化学习算法。通过这种方式训练的机器人既可以更好地利用收集的数据,也可以收集更好的数据,例如,通过关注新厨房的不寻常或具有挑战性的特征。这种元学习过程需要比简单的微调方法更多的样本,但它只需要发生一次,当部署在新的测试厨房时,由此产生的适应过程可以显著提高样本效率。这个例子说明,通常情况下,当需要频繁地进行有效的自适应时,元强化学习可能特别有用,因此元训练的成本相对较小。这包括但不限于安全关键的强化学习领域,在这些领域中,有效的数据收集是必要的,探索新行为的成本过高或危险。在许多情况下,大量的样本投资低效的前期学习(在监督下,在实验室中,或在模拟中)是值得的,以实现后续改进的适应行为。
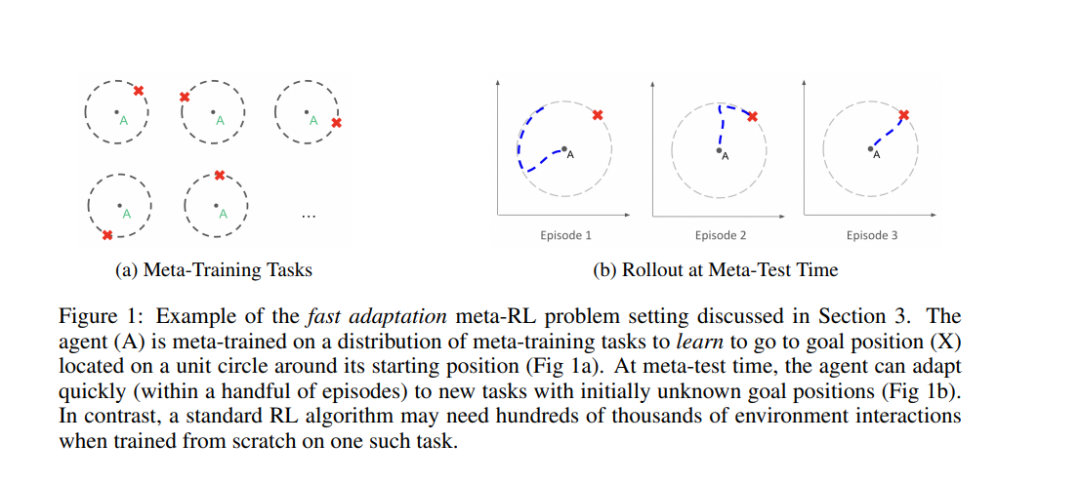
本综述的目的是提供一个元强化学习的入口,以及对该领域和开放研究领域的现状的反思。在第2节中,我们定义了元强化学习和它可以应用的不同问题设置,以及两个示例算法。在第3节中,我们考虑了元强化学习中最普遍的问题设置:少样本元强化学习。本文的目标是学习能够快速自适应的RL算法,即在少量的情节中学习任务。这些算法通常是在给定的任务分布上进行训练的,并且元学习如何有效地适应该分布中的任何任务。图1展示了一个简单的例子来说明这个设置。在这里,智能体经过元训练,以学习如何导航到2D平面上不同的(最初未知的)目标位置。在元测试时,该智能体能够有效地适应目标位置未知的新任务。在第4节中,我们考虑多样本的设置。这里的目标是学习通用的RL算法,而不是特定于狭窄的任务分布,类似于目前在实践中使用的算法。有两种方式:如上所述的对任务分布进行训练,或者对单个任务进行训练,但同时进行元学习和标准强化学习训练。接下来,第5节介绍了元强化学习的一些应用,如机器人。最后,我们在第6节讨论开放问题。这些包括对少样本元强化学习的更广泛任务分布的泛化,多样本元强化学习中的优化挑战,以及元训练成本的减少。