【数据科学家】数据科学家成长指南
数据科学家成长指南(上)


作者:秦路,天善智能特约专家。资深数据分析师,数据化运营专家。擅长结合运营和数据,建立数据化运营体系。
个人公众号:秦路(微信ID:tracykanc)。
少年,你渴望力量么?

这才是真正的力量,年轻人!
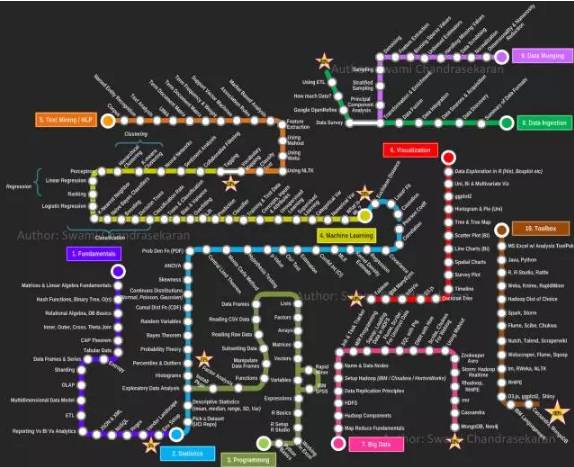
这是Swami Chandrasekaran所绘制的一张地图。名字叫MetroMap to Data Scientist(数据科学家之路),别称怎么死都不知道的。
数据科学家是近年火爆兴起的职位,它是数据分析师的后续进阶,融合了统计、业务、编程、机器学习、数据工程的复合型职位。
该地图一共十条路线,分别是基础原理、统计学、编程能力、机器学习、文本挖掘/自然语言处理、数据可视化、大数据、数据获取、数据清理、常用工具。条条路线都不是人走的。因为网上只有英文版,我将其翻译成中文,并对内容作一些解释和补充。
该指南主要涉及硬技能,数据科学家的另外一个核心业务能力,这里没有涉及,它并不代表不重要。

Fundamentals原理
算是多学科的交叉基础,属于数据科学家的必备素质。
Matrices & Linear Algebra
矩阵和线性代数
矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合。涉及到的机器学习应用有SVD、PCA、最小二乘法、共轭梯度法等。
线性代数是研究向量、向量空间、线性变换等内容的数学分支。向量是线性代数最基本的内容。中学时,数学书告诉我们向量是空间(通常是二维的坐标系)中的一个箭头,它有方向和数值。在数据科学家眼中,向量是有序的数字列表。线性代数是围绕向量加法和乘法展开的。
矩阵和线性代数有什么关系呢?当向量进行线性变换时,这种变换可以想象成几何意义上的线性挤压和拉扯,而矩阵则是描述这种变换的信息,由变换后的基向量决定。
矩阵和线性代数是一体的,矩阵是描述线性代数的参数。它们构成了机器学习的庞大基石。
Hash Functions,Binary Tree,O(n)
哈希函数,二叉树,时间复杂度
哈希函数也叫散列函数,它能将任意的数据作为输入,然后输出固定长度的数据,这个数据 叫哈希值也叫散列值,用h表示,此时h就输入数据的指纹。
哈希函数有一个基本特性,如果两个哈希值不相同,那么它的输入也肯定不相同。反过来,如果两个哈希值是相同的,那么输入值可能相同,也可能不相同,故无法通过哈希值来判断输入。
哈希函数常用在数据结构、密码学中。
二叉树是计算机科学的一个概念,它是一种树形结构。在这个结构中,每个节点最多有两个子树(左子树和右子树),子树次序不能颠倒。二叉树又有多种形态。
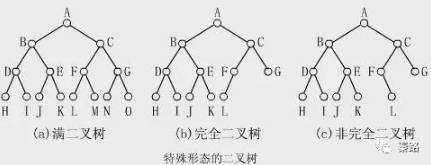
二叉树是树这类数据结构的第一种树,后续还有红黑树等,很多语言的set,map都是用二叉树写的。
时间复杂度是编程中的一个概念,它描述了执行算法需要的时间。不同算法有不同的时间复杂度,例如快排、冒泡等。
简便的计算方法是看有几个for循环,一个是O(n),两个是O(n^2),三个是O(n^3)。当复杂度是n^3+n^2时,则取最大的量级n^3即可。
与之相对应的还有空间复杂度,它代表的是算法占用的内存空间。算法通常要在时间和内存中取得一个平衡,既内存换时间,或者时间换内存。
Relational Algebra
关系代数
它是一种抽象的查询语言。基本的代数运算有选择、投影、集合并、集合差、笛卡尔积和更名。
关系型数据库就是以关系代数为基础。在SQL语言中都能找到关系代数相应的计算。
Inner、Outer、Cross、Theta Join
内连接、外连接、交叉连接、θ连接
这是关系模型中的概念,也是数据库的查询基础。
内连接,只连接匹配的行,又叫等值连接。
外连接,连接左右两表所有行,不论它们是否匹配。
交叉连接是对两个数据集所有行进行笛卡尔积运算,比如一幅扑克牌,其中有A集,是13个牌的点数集合,集合B则是4个花色的集合,集合A和集合B的交叉链接就是4*13共52个。
θ连接使用where子句引入连接条件,θ连接可以视作交叉连接的一个特殊情况。where 可以是等值,也可以是非等值如大于小于。
不同数据库的join方式会有差异。
CAP Theorem
CAP定理
指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容错性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
数据系统设计必须在三个性能方便做出取舍,不同的数据库,CAP倾向性不同。
tabular data
列表数据
即二维的表格数据,关系型数据库的基础。
DataFrames & Series
Pandas数据结构
Series是一个一维数据对象,由一组NumPy的array和一组与之相关的索引组成。Python字典和数组都能转换成数组。Series以0为开始,步长为1作为索引。
x = Series([1,2,3,4,5])
x
0 1
1 2
2 3
3 4
4 5
DataFrames是一个表格型的数据,是Series的多维表现。DataFrames即有行索引也有列索引,可以看作Series组成的字典。
Sharding
分片
分片不是一种特定的功能或者工具,而是技术细节上的抽象处理,是水平拓展的解决方法。一般数据库遇到性能瓶颈,采用的是Scale Up,即向上增加性能的方法,但单个机器总有上限,于是水平拓展应运而生。
分片是从分区(Partition)的思想而来,分区通常针对表和索引,而分片可以跨域数据库和物理假期。比如我们将中国划分南北方,南方用户放在一个服务器上,北方用户放在另一个服务器上。
实际形式上,每一个分片都包含数据库的一部分,可以是多个表的内容也可以是多个实例的内容。当需要查询时,则去需要查询内容所在的分片服务器上查询。它是集群,但不同于Hadoop的MR。
如果能够保证数据量很难超过现有数据库服务器的物理承载量,那么只需利用MySQL5.1提供的分区(Partition)功能来改善数据库性能即可;否则,还是考虑应用Sharding理念。另外一个流传甚广的观点是:我们的数据也许没有那么大,Hadoop不是必需的,用sharding即可。
OLAP
联机分析处理(Online Analytical Processing)
它是数据仓库系统主要的应用,主要用于复杂的分析操作。
针对数据分析人员,数据是多维数据。查询均是涉及到多表的复杂关联查询,为了支持数据业务系统的搭建,OLAP可以想象成一个多维度的立方体,以维度(Dimension)和度量(Measure)为基本概念。我们用到的多维分析就是OLAP的具象化应用。
OLAP更偏向于传统企业,互联网企业会灵活变动一些。另外还有一个OLTP的概念。
Multidimensional Data Model
多维数据模型。
它是OLAP处理生成后的数据立方体。它提供了最直观观察数据的方法。
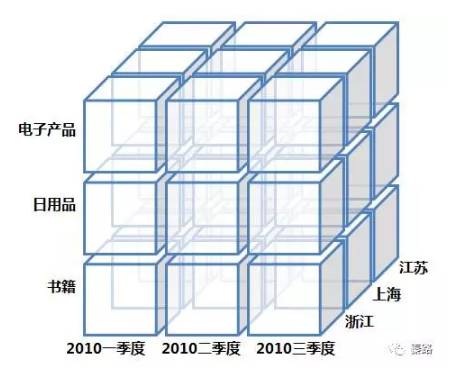
涉及钻取,上卷,切片,切块,旋转等操作,就是把上面的立方体变变变啦。
ETL
ETL是抽取(extract)、转换(transform)、加载(load)的过程。常用在数据仓库。
整个流程是从数据源抽取数据,结果数据清洗和转换,最终将数据以特定模型加载到数据仓库中去。
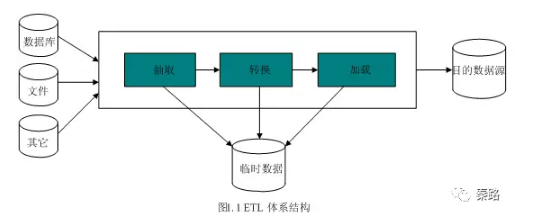
ETL是一个古老的概念,在以前SQL数据仓库时代和OLAP伴随而生,在现在日新月异的技术生态圈,会逐步演进到Hadoop相关的技术了。
Reporting vs BI vs Analytics
报表与商业智能与分析
这是BI的三个组成部分。Reporting是数据报表。利用表格和图表呈现数据。报表通常是动态多样的。数个报表的集合统称为Dashboard。
BI是商业智能,是对企业的数据进行有效整合,通过数据报表快速作出决策。
Analytics是数据分析,基于数据报表作出分析。包括趋势的波动,维度的对比等。
JSON & XML
JSON是一种轻量级的数据交换格式,易于阅读和编写,也易于机器解析和生成。
JSON的语法规则是:
{ }保存对象;
[ ]保存数组;
数据由逗号分隔;
数据在键值对中;
下面范例就是一组JSON值
{
"firstName": "John",
"lastName": "Smith",
"age": 25,
"address": {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021"
}
}
XML是可拓展标记语言,被设计用来传输和存储数据,与之对应的HTML则是显示数据。XML和HTML服务于不同目的,XML是不作为的。
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
上面的范例,纯粹就是用来传输的一段信息,没有任何意义。
NoSQL
泛指非关系型的数据库,意为Not Only SQL。
NoSQL是随着大数据时代发展起来的,传统的关系数据库在高并发大规模多数据类型的环境下力不从心,而NoSQL就是为了解决这些问题而产生的。
NoSQL主要分为四大类:
键值KeyValue数据库
这类数据库会使用哈希表,哈希表中有一个特定的键指向一个特定的值,KeyValue的特点是去中心化,不涉及业务关系。代表Redis。
列数据库
这类数据库用于分布式海量存储,和KeyValue的区别在于这里的Key指向的是列。横向拓展性好,适合大数据量高IO。代表HBase,Cassandra
文档型数据库
属于KeyValue数据库的升级版,允许嵌套键值。文档是处理信息的基本单位,一个文档等于一个关系数据库的一条记录。
因为文档的自由性,文档型数据库适合复杂、松散、无结构或半结构化的数据模型,和JSON类似,叫做BSON(MongoDB的存储格式)。代表MongoDB
图形数据库
基于图论算法的数据库,将数据集以图形元素(点、线、面)建立起来。这种数据库常应用在社交网络关系链,N度关系等。代表Neo4j
Regex
正则表达式(Regular Expression)
正则表通常被用来检索、替换那些符合某个模式(规则)的字符串。通过特定字符的组合,对字符串进行逻辑过滤。例如注册账号时检查对方邮件格式对不对啊,手机号格式对不对啊。
学起来靠记,记了也会忘,每次用得查,查了还得检验。网上记忆口诀一堆图表,相关网站也不少,仁者见仁了。
Vendor Landscape
不懂,供应商风景?
Env Setup
环境安装
想了半天,Env应该是环境安装的意思,IDE啊,GUI啊等等全部安装上去,再调各种路径啥的。针对数据科学家,Anaconda + Rstudio用的比较多。

Statistics 统计
统计是数据科学家的核心能力之一,机器学习就是基于统计学原理的,我不算精通这一块,许多内容都是网络教科书式的语言。都掌握后再重写一遍。
Pick a Dataset(UCI Repo)
找数据(UCI数据集)
UCI数据库是加州大学欧文分校(University of CaliforniaIrvine)提出的用于机器学习的数据库,这个数据库目前共有335个数据集,其数目还在不断增加,可以拿来玩机器学习。网上搜的到。另外的数据来源是Kaggle竞赛等。
最经典的数据莫过于Iris了。
Descriptive Statistics(mean, median, range, SD, Var)
描述性统计(均值,中位数,极差,标准差,方差)
均值也叫平均数,是统计学中的概念。小学学习的算数平均数是其中的一种均值,除此以外还有众数和中位数。
中位数可以避免极端值,在数据呈现偏态的情况下会使用。
极差就是最大值减最小值。
标准差,也叫做均方差。现实意义是表述各数据偏离真实值的情况,反映的是一组数据的离散程度。平均数相同的两组数据,如[1,9]和[4,6],平均数相同,标准差不一样,前者的离散程度更大。
方差,是标准差的平方。方差和标准差的量纲是一致的。在实际使用过程中,标准差需要比方差多一步开平方的运算,但它在描述现实意义上更贴切,各有优劣。
Exploratory Data Analysis
探索性数据分析
获得一组数据集时,通常分析师需要掌握数据的大体情况,此时就要用到探索性数据分析。
主要是两类:
图形法,通过直方图、箱线图、茎叶图、散点图快速汇总描述数据。
数值法:观察数据的分布形态,包括中位数、极值、均值等,观察多变量之间的关系。
探索性数据分析不会涉及到复杂运算,而是通过简单的方式对数据有一个大概的了解,然后才去深入挖掘数据价值,在Python和R中,都有相关的summary函数。
Histograms
直方图
它又称质量分布图,是一种表示数据分布的统计报告图。
近似图表中的条形图,不过直方图的条形是连续排列,没有间隔、因为分组数据具有连续性,不能放开。
正常的直方图是中间高、两边低、左右近似对称。而异常型的直方图种类过多,不同的异常代表不同的可能情况。
Percentiles & Outliers
百分位数和极值
它们是描述性统计的元素。
百分位数指将一组数据从小到大排序,并计算相遇的累积百分值,某一百分位所对应数据的值就称为这一百分位的百分位数。比如1~100的数组中,25代表25分位,60代表60分位。
我们常将百分位数均匀四等分:第25百分位数,叫做第一四分位数;第50百分位数,称第二四分位数,也叫中位数;第75百分位数,叫做第三四分位数。通过四分位数能够简单快速的衡量一组数据的分布。它们构成了箱线图的指标。
极值是最大值和最小值,也是第一百分位数和第一百百分位数。
百分位数和极值可以用来描绘箱线图。
Probability Theory
概率论,统计学的核心之一,主要研究随机现象发生的可能性。
Bayes Theorem
贝叶斯定理
它关于随机事件A和B的条件概率的定理。
现实世界有很多通过某些信息推断出其他信息的推理和决策,比如看到天暗了、蜻蜓低飞了,那么就表示有可能下雨。这组关系被称为条件概率:用P(A|B)表示在B发生的情况下A发生的可能性。
贝叶斯公式:P(B|A) = P(A|B)*P(B) / P(A)
现实生活中最经典的例子就是疾病检测,如果某种疾病的发病率为千分之一。现在有一种试纸,它在患者得病的情况下,有99%的准确判断患者得病,在患者没有得病的情况下,有5%的可能误判患者得病。现在试纸说一个患者得了病,那么患者真的得病的概率是多少?
从我们的直觉看,是不是患者得病的概率很大,有80%?90%?实际上,患者得病的概率只有1.9%。关键在哪里?一个是疾病的发病率过低,一个是5%的误判率太高,导致大多数没有得病的人被误判。这就是贝叶斯定理的作用,用数学,而不是直觉做判断。
最经典的应用莫过于垃圾邮件的过滤。
Random Variables
随机变量
表示随机试验各种结果的实际值。比如天气下雨的降水量,比如某一时间段商城的客流量。
随机变量是规律的反应,扔一枚硬币,既有可能正面、也有可能反面,两者的概率都是50%。扔骰子,结果是1~6之间的任何一个,概率也是六分之一。虽然做一次试验,结果肯定是不确定性的,但是概率是一定的。随机变量是概率的基石。
Cumul Dist Fn(CDF)
累计分布函数(Cumulative Distribution Function)
它是概率密度函数的积分,能够完整描述一个实数随机变量X的概率分布。直观看,累积分布函数是概率密度函数曲线下的面积。

上图阴影部分就是一个标准的累积分布函数F(x),给定任意值x,计算小于x的概率为多大。实际工作中不会涉及CDF的计算,都是计算机负责的。记得在我大学考试,也是专门查表的。
现实生活中,我们描述的很多概率都是累积分布函数,我们说考试90分以上的概率有95%,实际是90分~100分所有的概率求和为95%。
Continuos Distributions(Normal, Poisson, Gaussian)
连续分布(正态、泊松、高斯)
分布有两种,离散分布和连续分布。连续分布是随机变量在区间内能够取任意数值。
正态分布是统计学中最重要的分布之一,它的形状呈钟型,两头低,中间高,左右对称。
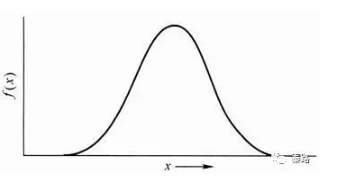
正态分布有两个参数,期望μ和标准差σ:μ反应了正态分布的集中趋势位置,σ反应了离散程度,σ越大,曲线越扁平,σ越小,曲线越窄高。
自然届中大量的现象都按正态形式分布,标准正态分布则是正态分布的一种,平均数为0,标准差为1。应用中,都会将正态分布先转换成标准正态分布进行计算。很多统计学方法,都会要求数据符合正态分布才能计算。
泊松分布是离散概率分布。适合描述某个随机事件在单位时间/距离/面积等出现的次数。当n出现的次数足够多时,泊松分布可以看作正态分布。
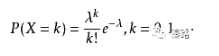
高斯分布就是正态分布。
Skewness
偏度
它是数据分布倾斜方向和程度的度量,当数据非对称时,需要用到偏度。
正态分布的偏度为0,当偏度为负时,数据分布往左偏离,叫做负偏离,也称左偏态。反之叫右偏态。
ANOVA
方差分析
用于多个变量的显著性检验。基本思想是:通过分析研究不同来源的变异对总变异的贡献大小,从而确定可控因素对研究结果影响力的大小。
方差分析属于回归分析的特例。方差分析用于检验所有变量的显著性,而回归分析通常针对单个变量的。
Prob Den Fn(PDF)
概率密度函数
PDF是用来描述连续型随机变量的输出值。概率密度函数应该和分布函数一起看:

蓝色曲线是概率密度函数,阴影部分是累积分布函数。我们用概率密度函数在某一区间上的积分来刻画随机变量落在这个区间中的概率。概率等于区间乘概率密度,累积分布等于所有概率的累加。
概率密度函数:f(x) = P(X=x)
累积分布函数:F(x) = P(X<=x)
概率密度函数是累积分布函数的导数,现有分布函数,才有密度函数。累积分布函数即可以离散也可以连续,而密度函数是用在连续分布中的。
Central Limit THeorem
中心极限定理
它是概率论中最重要的一类定理。
自然届中很多随机变量都服从正态分布,中心极限定理就是理解和解释这些随机变量的。我们有一个总体样本,从中取样本量为n的样本,这个样本有一个均值,当我们重复取了m次时,对应有m个均值,如果我们把数据分布画出来,得到的结果近似正态分布。
这就是中心极限定理,它神奇的地方就在于不管总体是什么分布。我们很多推导都是基于中心极限定理的。
Monte Carlo Method
蒙特卡罗方法
它是使用随机数来解决计算问题的方法。
蒙特卡罗是一个大赌场,以它命名,含义近似于随机。我们有时候会因为各种限制而无法使用确定性的方法,此时我们只能随机模拟,用通过概率实验所求的概率来估计我们感兴趣的一个量。最知名的例子有布丰投针试验。
18世纪,布丰提出以下问题:设我们有一个以平行且等距木纹铺成的地板,木纹间距为a,现在随意抛一支长度l比木纹之间距离a小的针,求针和其中一条木纹相交的概率。布丰计算出来了概率为p = 2l/πa。
为了计算圆周率,人们纷纷投针,以实际的试验结果来计算。
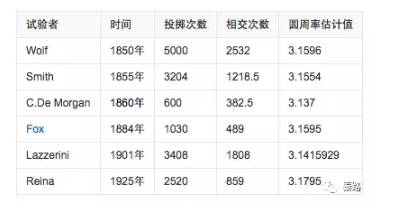
下图则是计算机模拟的结果
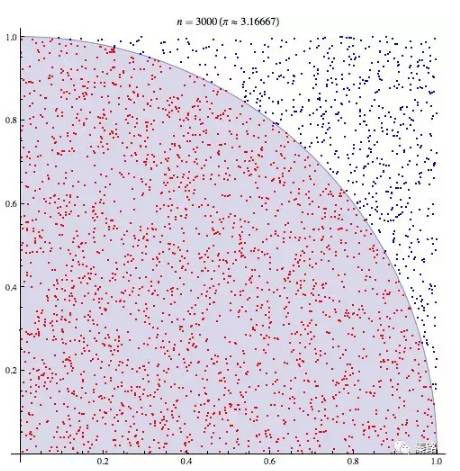
这就是蒙特卡罗方法的实际应用。它的理论依据是大数定理和中心极限定理。
Hypothesis Testing
假设检验
它是根据一定的假设条件由样本推断总体的方法。
首先根据实际问题作出一个假设,记作H0,相反的假设称为备择假设。它的核心思想是小概率反证法,如果这个假设发生的概率太小以至于不可能发生,结果它发生了,那么我们认为假设是不成立的。
假设检验是需要容忍的,因为样本会存在波动,这个波动范围不会太严格,在这个范围内出现的事件我们都能接受。但是我们都这么容忍了,还是出现了违背原假设的小概率事件,那么说明原假设有问题。不能容忍的范围即拒绝域,在拒绝域发生的概率我们都认为它是小概率事件。
假设检验容易犯两类错误,第一类错误是真实情况为h0成立,但判断h0不成立,犯了“以真为假”的错误。第二类错误是h0实际不成立,但判断它成立,犯了“以假为真”的错误。
假设检验有U检验、T检验、F检验等方法。
p-Value
P值
它是进行假设检验判定的一个参数。当原假设为真时样本观察结果(或更极端结果)出现的概率。P值很小,说明原假设发生的概率很小,但它确实发生了,那么我们就有理由拒绝原假设。
至于P值的选择根据具体情况,一般是1%,5%几个档次。
然而,P值在统计学上争议很大,P值是否是接受原假设的标准,都是统计学各种流派混合后的观点。P值从来没有被证明可以用来接收某个假设(所以我上文的说明并不严谨),它只是仅供参考。现在统计学家们也开始倡导:应该给出置信区间和统计功效,实际的行动判读还是留给人吧。
Chi2 Test
卡方检验
Chi读作卡。通常用作独立性检验和拟合优度检验。
卡方检验基于卡方分布。检验的假设是观察频数与期望频数没有差别。
独立性检验:卡方分布的一个重要应用是基于样本数据判断两个变量的独立性。独立性检验使用列联表格式,因此也被称为列联表检验。原假设中,列变量与行变量独立,通过每个单元格的期望频数检验统计量。
拟合优度检验:它依据总体分布状况,计算出分类变量中各类别的期望频数,与分布的观察频数进行对比,判断期望频数与观察频数是否有显著差异。目的是判断假设的概率分布模型是否能用作研究总体的模型。
独立性检验是拟合优度检验的推广。
Estimation
估计
统计学里面估计分为参数估计和非参数估计。
参数估计是用样本指标估计总体指标,这个指标可以是期望、方差、相关系数等,指标的正式名称就是参数。当估计的是这些参数的值时,叫做点估计。当估计的是一个区间,即总体指标在某范围内的可能时,叫做区间估计,简单认为是人们常说的有多少把握保证某值在某个范围内。
参数估计需要先明确对样本的分布形态与模型的具体形式做假设。常见的估计方法有极大似然估计法、最小二乘法、贝叶斯估计法等。
非参数估计则是不做假设,直接利用样本数据去做逼近,找出相应的模型。
Confid Int(CI)
置信区间
它是参数检验中对某个样本的总体参数的区间估计。它描述的是这个参数有一定概率落在测量结果的范围程度。这个概率叫做置信水平。
以网上例子来说,如果在一次大选中某人的支持率为55%,而置信水平0.95以上的置信区间是(50%,60%),那么他的真实支持率有95%的概率落在和50~60的支持率之间。我们也可以很容易的推得,当置信区间越大,置信水平也一定越大,落在40~70%支持率的可能性就有99.99%了。当然,越大的置信区间,它在现实的决策价值也越低。
置信区间经常见于抽样调研,AB测试等。
MLE
极大似然估计
它是建立在极大似然原理的基础上。
如果试验如有若干个可能的结果A,B,C…。若在仅仅作一次试验中,结果A出现,则一般认为试验条件对A出现有利,也即A出现的概率很大。
此时我们需要找出某个参数,参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
Kernel Density Estimate
核密度估计
它是概率论中估计未知的密度函数,属于非参数检验。
一般的概率问题,我们都会假定数据分布满足状态,是基于假定的判别。这种叫参数检验。如果如果数据与假定存在很大的差异,那么这些方法就不好用,于是便有了非参数检验。核密度估计就是非参数检验,它不需要假定数据满足那种分布。
Regression
回归
回归,指研究一组随机变量(Y1 ,Y2 ,…,Yi)和另一组(X1,X2,…,Xk)变量之间关系的统计分析方法,又称多重回归分析。通常Y1,Y2,…,Yi是因变量,X1、X2,…,Xk是自变量。
回归分析常用来探讨变量之间的关系,在有限情况下,也能推断相关性和因果性。而在机器学习领域中,它被用来预测,也能用来筛选特征。

回归包括线性回归、非线性回归、逻辑回归等。上图就是线性回归。
Convariance
协方差
用于衡量两个变量的总体误差,方差是协方差的一种特殊情况,即两个变量相同。
协方差用数据期望值E计算:cov(x,y) = E[XY]-E[X][Y]。
如果XY互相独立,则cov(x,y)=0.此时E[XY] = E[X][Y]。
Correlation
相关性
即变量之间的关联性,相关性只涉及数学层面,即一个变量变化,另外一个变量会不会变化,但是两个变量的因果性不做研究。
相关关系是一种非确定性的关系,即无法通过一个变量精确地确定另外一个变量,比如我们都认为,一个人身高越高体重越重,但是不能真的通过身高去确定人的体重。
Pearson Coeff
皮尔逊相关系数
它是度量两个变量线性相关的系数,用r表示,其值介于-1与1之间。1表示完全正相关,0表示完全无关,-1表示完全负相关。
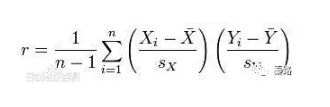
Causation
因果性
和相关性是一堆好基友。相关性代表数学上的关系,但并不代表具有因果性。
夏天,吃冷饮的人数和淹死的人数都呈现正相关。难道是吃冷饮导致了淹死?不是的,是因为天热,天热吃冷饮的人多了,游泳的人也多了。
《大数据时代》曾经强调,我们应该重视相关性而不是因果性,这是存疑的,因为对数据科学家来说,对业务因果性的了解往往胜于相关性,比如你预测一个人是否会得癌症,你不能拿是否做过放疗作为特征,因为放疗已经是癌症的果,必然是非常强相关,但是对预测没有任何帮助,只是测试数据上好看而已。
Least2 fit
最小二乘法
它是线性回归的一种用于机器学习中的优化技术。
最小二乘的基本思想是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。它是基于欧式距离的。
Eculidean Distance
欧氏距离
指在m维空间中两个点之间的真实距离。小学时求的坐标轴轴上两个点的直线距离就是二维空间的欧式距离。很多算法都是基于欧式距离求解的。
二维:

Programming 编程
数据科学家是需要一定的编程能力,虽然不需要程序员那么精通,注重的是解决的能力,而不是工程化的能力。作者从内容看更推崇R,我个人是推崇Python的。
Python Basics
Python基础知识。
人生苦短,我用Python。
Python的基础内容比R丰富的多,近几年,Python有作为第一数据科学语言的趋势。基础内容就不多复述了。
Working in Excel
Excel干活
掌握常用函数,懂得数据分析库,会Power系列加分。VBA这种就不用学了。
R Setup, RStudio R
安装R和RStudio
R是一门统计学语言。下列的内容,都是R语言相关。
R Basics
R的基础,不多作陈述了。
Varibles
变量
变量是计算机语言中的抽象概念,可以理解成我们计算的结果或者值,不同计算语言的变量性质不一样。主要理解R和Python的变量就行。大数据那块可能还会涉及到Java和Scala。
R 用 <- 给变量赋值,=也能用,但不建议。
Vectors
向量
向量是一维数组,可以存储数值型、字符型或逻辑型数据的一维数组。R里面使用函数c( )创建向量。
v <- c(1,2,3,4)
向量中的数据必须拥有相同的数据类型,无法混杂。
Matrices
矩阵
矩阵是一个二维数组,和向量一样,每个元素必须拥有相同的数据类型。当维度超过2时,我们更建议使用数组
m <- matrix(1:20,nrow=5,ncol=4)
Arrays
数组
数组与矩阵类似,但是维度可以大于2,数据类型必须一样。
a <- array(1:20,c(4,5))
Factors
因子
因子是R中的有序变量和类别变量。
类别变量也叫做名义变量,它没有顺序之分,比如男女,虽然编码中可能男为1,女为2,但不具备数值计算含义。有序变量则表示一种顺序关系,少年、青年、老年则是一种有序变量。
f <- factor(c("type1","type2","type1))
在factor函数中加入参数ordered = True,就表示为有序型变量了。
Lists
列表
它是R最复杂的数据类型,它可以是上述数据结构的组合。
l <- list(names = v,m,a,f )
上述例子就包含了向量、矩阵、数组、因子。我们可以使用双重方括号[[ ]]选取列表中的元素。R中的下标不从0开始,所以list[[1]] 选取的是v。
Data Frames
数据框
在R和Python中为常用的数据结构。
R语言中为data.frame,Python中为Pandas的DataFrame。这里以R语言举例。
数据框可以包含不同数据类型的列,它是比矩阵更广泛的概念,也是R中最常用的数据结构。每一列的数据类型必须唯一。
x <- data.frame(col1,col2,col3)
Reading CSV Data
读取CSV
这一块比较坑的地方是中文,R语言对中文编码的支持比较麻烦。
Reading Raw Data
读取原始数据
不清楚这和CSV的区别。
Subsetting Data
构建数据集
R提供了常用函数方便我们构建数据集(反正来去都那几个英文)。
数据集合并使用merge函数。
添加数据行使用rbind函数。
dataframe选取子集用[ row,column]。
删除变量可以通过 <- Null。
复杂查询则使用subset函数。
如果已经习惯SQL函数,可以载入library(sqldf)后用sqldf函数。
Manipulate Data Frames
操作数据框
除了上面的构建数据集的技巧,如果我们需要更复杂的操作,加工某些数据,如求变量和、计算方差等,则要用到R语言的其他函数。
R本身提供了abs(x),sort(x),mean(x),cos(x)等常用的统计方法,如何应用在数据框呢?我们使用apply函数,可将任意一个函数应用在矩阵、数组、数据框中。
apply(dataframe,margin,fun)
Functions
函数
R语言自带了丰富的统计函数,可以通过官方/第三方文档查询,R也可以自建函数。
myfunction <- function(arg1,arg2,……){
statements
return(object)
}
函数中的对象只在函数内部使用。如果要调试函数,可以使用warning( ),messagr( ),stop( )等纠错。
Factor Analysis
因子分析
我不知道这块的编程基础内容为什么要加入因子分析。R语言的因子分析函数是factanal()
Install Pkgs
调包侠
R的包非常丰富(Python更是),可以通过cran下载,包括爬虫、解析、各专业领域等。函数library可以显示有哪些包,可能直接加入包。RStudio则提供了与包相关的丰富查询界面。
Machine Learning机器学习
数据科学的终极应用,现在已经是深度学习了。这条路也叫从调包到科学调参。这里的算法属于经典算法,但是向GBDT、XGBoost、RF等近几年竞赛中大发异彩的算法没有涉及,应该是写得比较早的原因。
What is ML?
机器学习是啥子哟
机器学习,区别于数据挖掘,机器学习的算法基于统计学和概率论,根据已有数据不断自动学习找到最优解。数据挖掘能包含机器学习的算法,但是协同过滤,关联规则不是机器学习,在机器学习的教程上看不到,但是在数据挖掘书本能看到。
Numerical Var
数值变量
机器学习中主要是两类变量,数值变量和分量变量。
数值变量具有计算意义,可用加减乘除。数据类型有int、float等。
在很多模型中,连续性的数值变量不会直接使用,为了模型的泛化能力会将其转换为分类变量。
Categorical Var
分类变量
分类变量可以用非数值表示,它是离散变量。
有时候为了方便和节省存储空间,也会用数值表示,比如1代表男,0代表女。但它们没有计算意义。在输入模型的过程中,会将其转变为哑变量。
Supervised Learning
监督学习
机器学习主要分为监督学习和非监督学习。
监督学习是从给定的训练集中学习出一个超级函数Y=F(X),我们也称之为模型。当新数据放入到模型的时候,它能输出我们需要的结果达到分类或者预测的目的。结果Y叫做目标,X叫做特征。当有新数据进入,能够产生新的准确的结果。
既然从训练集中生成模型,那么训练集的结果Y应该是已知的,知道输入X和输出Y,模型才会建立,这个过程叫做监督学习。如果输出值是离散的,是分类,如果输出值是连续的,是预测。
监督学习常见于KNN、线性回归、朴素贝叶斯、随机森林等。
Unsupervied Learning
非监督学习
无监督学习和监督学习,监督学习是知道结果Y,无监督学习是不知道Y,仅通过已有的X,来找出隐藏的结构。
无监督学习常见于聚类、隐马尔可夫模型等。
Concepts, Inputs & Attributes
概念、输入和特征
机器学习包括输入空间、输出空间、和特征空间三类。特征选择的目的是筛选出结果有影响的数据。
Traning & Test Data
训练集和测试集
机器学习的模型是构建在数据集上的,我们会采用随机抽样或者分层抽样的将数据分成大小两个部分,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,通过小样本的预测结果和真实结果做对比,来判断模型优劣。这个叫做交叉验证。
交叉验证能够提高模型的稳定性,但不是完全保险的,依旧有过拟合的风险。
通常用80%的数据构建训练集,20%的数据构建测试集
Classifier
分类
监督学习中,如果输出是离散变量,算法称为分类。
输出的离散变量如果是二元的,则是二元分类,比如判断是不是垃圾邮件{是,否},很多分类问题都是二元分类。与之相对的是多元分类。
Prediction
预测
监督学习中,如果输出是连续变量,算法称为预测。
预测即可以是数值型,比如未来的销量,也可以是介于[0,1]间的概率问题。
有些算法适合分类、有些则是预测,也有算法可以两者都能做到。
Lift
Lift曲线
它是衡量模型性能的一种最常用的度量,它考虑的是模型的准确性。它核心的思想是以结果作导向,用了模型得到的正类数量比不用模型的效果提升了多少?
比如某一次活动营销,1000个用户会有200个响应,响应率是20%。用了模型后,我通过算法,讲用户分群,挑出了最有可能响应的用户200个,测试后的结果是有100个,此时的响应率变成了50%。此时的Lift值为5。
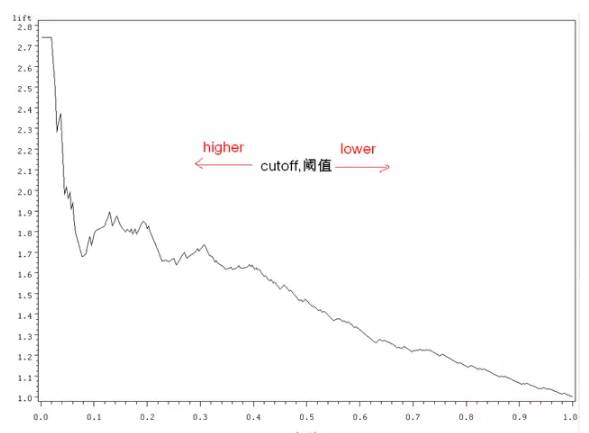
上图就是按Lift值画出曲线的范例。纵坐标是lift值,横坐标是挑选的的阀值。阀值越低,说明挑选的越严格,按上文的例子理解,挑选的就是最有可能响应的用户。当没有阀值时,lift就为0了。阀值通常是根据预测分数排序的。
还有一种常用的叫ROC曲线。
Overfitting
过拟合
过拟合是机器学习中常碰到的一类问题。主要体现在模型在训练数据集上变现优秀,而在真实数据集上表现欠佳。造成的原因是为了在训练集上获得出色的表现,使得模型的构造如此精细复杂,规则如此严格,以至于任何与样本数据稍有不同的文档它全都认为不属于这个类别。
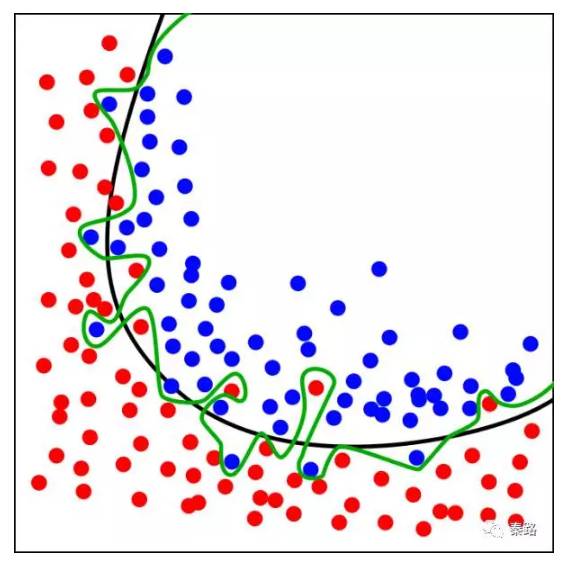
上图,黑色的线条是正常模型,绿色的线条是过拟合模型。
不同的机器学习算法,是否容易拟合的程度也不仅相同。通常采用加大样本数据量、减少共线性、增加特征泛化能力的方法解决过拟合。
与之相反的是欠拟合。
Bias & Variance
偏差和方差
偏差和方差除了统计学概念外,它们也是解释算法泛化能力的一种重要工具。
算法在不同训练集上得到的结果不同,我们用偏差度量算法的期望预测和真实结果的偏离程度,这代表算法本身的拟合能力,方差则度量了算法受数据波动造成的影响。
偏差越小、越能够拟合数据,方差越小、越能够扛数据波动。
Trees & Classification
树分类
树分类是需要通过多级判别才能确定模式所属类别的一种分类方法。多级判别过程可以用树状结构表示,所以称为树分类器。最经典的便是决策树算法。
Classification Rate
分类正确率
为了验证模型的好坏,即最终判断结果的对错,我们引入了分类正确率。
分类正确率即可以判断二分类任务,也适用于多分类任务。我们定义分类错误的样本数占总样本的比率为错误率,精确度则是正确的样本数比率。两者相加为1。
为了更好的判断模型,主要是业务需要,我们还加入了查准率(precision),查全率(recall),查准率是预测为真的数据中有多少是真的。查全率是真的数据中有多少数据被预测对了。
这个有点绕,主要是为了业务判断,假如我们的预测是病人是否患了某个致死疾病,假设得病为真,我们显然希望把全部都得病的患者找出来,那么此时查全率(得病的患者有多少被准确预测出来)比查准率(预测得病的患者有多少真的得病了)更重要,因为这个会死人,那么肯定是选择有杀错无放过。此时更追求查全率。
算法竞赛就是基于上述指标评分的。
Decision Tress
决策树
它是基本的分类和回归方法。可以理解成If-Then的规则集,每一条路径都互斥且完备。决策树分为内部节点和叶节点,内部节点就是If-Then的规则,叶节点就是分类结果。
决策树主流有ID3、C4.5(C5.0也有了)、CART算法。
因为决策树形成的结构是根据树形递归产生,它对训练数据表现良好,但是会产生过拟合现象。为了避免这一现象,会进行减枝。剪纸通过损失函数或代价函数实现。
决策树的优点是:高校简单、可解释性强、在大型数据库有良好表现、适合高维数据。
缺点是:容易过拟合、并且分类结果会倾向拥有更多数值的特征(基于信息增益)。
随机森林算法是基于决策树的。
Boosting
提升方法
属于集成学习的一种。提升方法Boosting一般是通过多个弱分类器组成一个强分类器,提高分类性能。简而言之是三个臭皮匠顶一个诸葛亮。
通过对训练集训练出一个基学习器,然后根据基学习器的分类表现跳转和优化,分类错误的样本将会获得更多关注,以此重复迭代,最终产生的多个基分类器进行加强结合得出一个强分类器。
主流方法是AdaBoost,以基分类器做线性组合,每一轮提高前几轮被错误分类的权值。
Naive Bayes Classifiers
朴素贝叶斯分类
它基于贝叶斯定理的分类方法。朴素贝叶斯法的使用条件是各条件互相独立。这里引入经典的贝叶斯定理:

在算法中,我们的B就是分类结果Target,A就是特征。意思是在特征已经发生的情况下,发生B的概率是多少?
概率估计方法有极大似然估计和贝叶斯估计,极大似然估计容易产生概率值为0的情况。
优点是对缺失数据不太敏感,算法也比较简单。缺点是条件互相独立在实际工作中不太成立。
K-Nearest Neighbour
K近邻分类。
K近邻分类的特点是通过训练数据对特征向量空间进行划分。当有新的数据输入时,寻找距离它最近的K个实例,如果K个实例多数属于某类,那么就把新数据也算作某类。
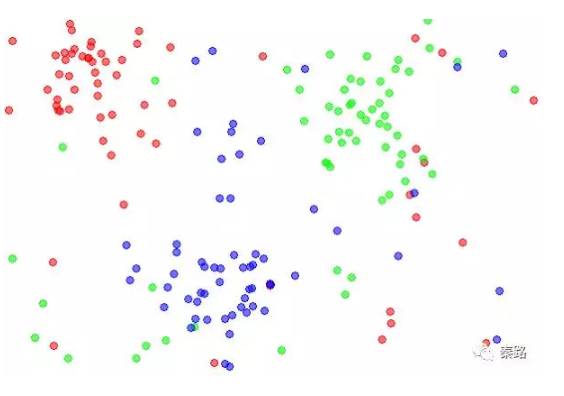
特征空间中,每个训练数据都是一个点,距离该点比其他点更近的所有点将组成一个子空间,叫做单元Cell,这时候,每个点都属于一个单元,单元将是点的分类。
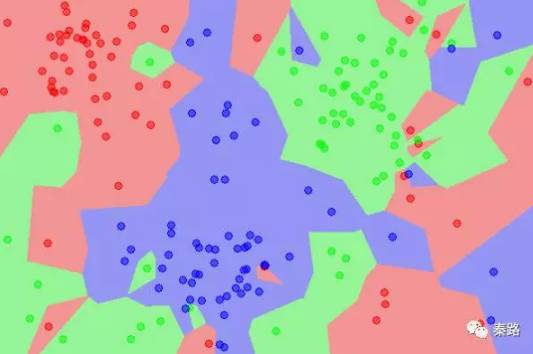
k值的选择将会影响分类结果,k值越小,模型越复杂,容易过拟合,不抗干扰。K值越大,模型将越简单,分类的准确度会下降。上图是K=1时的子空间划分,下图是K=5时的子空间划分,从颜色很直观的看到影响。

K近邻的这类基于距离的算法,训练的时间复杂度低,为O(n),适用范围范围广。但是时间复杂度低是通过空间复杂度换来的,所以需要大量的计算资源和内存。另外样本不平衡问题解决不了。
Logistic Regression
逻辑斯谛回归,简称逻辑回归。
逻辑回归属于对数线性模型,虽然叫回归,本质却是分类模型。如果我们要用线性模型做分类任务,则找到sigmoid函数将分类目标Y和回归的预测值联系起来,当预测值大于0,判断正例,小于0为反例,等于0任意判别,这个方法叫逻辑回归模型。
模型参数通过极大似然法求得。逻辑回归的优点是快速和简单,缺点是高维数据支持不好,容易钱拟合。
Ranking
排序,PageRank
这里应该泛指Google的PageRank算法。
PageRank的核心思想有2点:
如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是pagerank值会相对较高;
如果一个pagerank值很高的网页链接到一个其他的网页,那么被链接到的网页的pagerank值会相应地因此而提高。
PageRank并不是唯一的排名算法,而是最为广泛使用的一种。其他算法还有:Hilltop 算法、ExpertRank、HITS、TrustRank。
Linear Regression
线性回归
线性回归是机器学习的入门级别算法,它通过学习得到一个线性组合来进行预测。
一般写成F(x) = wx +b,我们通过均方误差获得w和b,均方误差是基于欧式距离的求解,就是最小二乘法啦。找到一条线,所有数据到这条线的欧式距离之和最小。
线性回归容易优化,模型简单,缺点是不支持非线性。
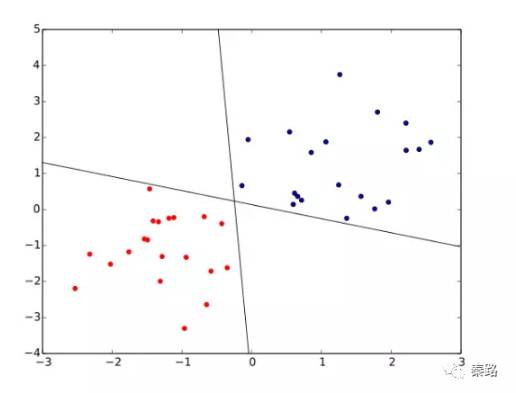
Perceptron
感知机
它是二类分类的线性分类模型。

它通过一个wx+b的超平面S划分特征空间。为了找出这个超平面,我们利用损失函数极小化求出。超平面的解不是唯一的,采取不同初值或误分类点将会造成不同结果。
Hierarchical Clustering
层次聚类
层次聚类指在不同层次对数据集进行划分,从而形成树形的聚类结构。
它将样本看作一个初始聚类簇,每次运算找出最近的簇进行合并,该过程不断合并,直到满足预设的簇的个数。

上图就是所有样本重复执行最终K=1时的结果。横轴是聚类簇之间的距离,当距离=5时,我们有两个聚类簇,当距离=3时,我们有四个聚类簇。
K-means Clusterning
K聚类
全称K均值聚类,无监督学习的经典算法。物以类聚人以群分的典型代表。
K聚类需要将原始数据无量纲化,然后设置聚类点迭代求解。K聚类的核心是针对划分出的群簇使其最小化平方误差。直观说,就是让样本紧密围绕群簇均值。
设置多少个聚类点多少有点主观的意思,这也是K聚类唯一的参数,考察的是外部指标,即你聚类本身是想分出几类,通过对结果的观察以及E值判断。
K聚类不适合多维特征,一般3~4维即可,维度太多会缺乏解释性,RFM模型是其经典应用。因为物以类聚,所以对偏离均值点的异常值非常敏感。
Neural Networks
神经网络
神经网络是一种模仿生物神经系统的算法,神经网络算法以神经元作为最基础的单位,神经元通过将输入数据转换为0或1的阀值,达到激活与否的目的,但是0和1不连续不光滑,对于连续性数据,往往用sigmoid函数转换成[0,1] 间的范围。
将这些神经单元以层次结构连接起来,就成了神经网络。因为这个特性,神经网络有许多的参数,可不具备可解释性。多层神经网络,它的输入层和输出层之间的层级叫做隐层,就是天晓得它代表什么含义。
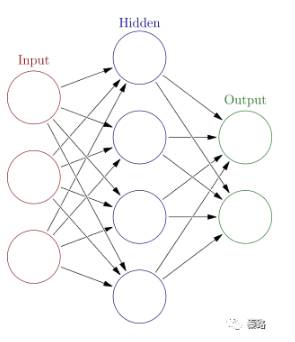
神经网络的层数一般是固定的,但我们也能将网络层数作为学习的目标之一,找到最适合的层数。
另外,层数越多,参数越多的神经网络复杂度越高,深度学习就是典型的层数很多的神经网络。常见的有CNN、DNN、RNN等算法。
Sentiment Analysis
情感分析
比较前沿的一个领域。包括情感词的正面负面分类,标注语料,情感词的提取等。
情感分析可以通过情感关键词库计算,比如汇总开心、悲伤、难过的词汇,计算情感值,再加入表示情感强烈程度的维度,如1~5的数值进行打分。用户对商品评论的分析就是一个常见的情感分析:这手机太TM破了,就是5分愤怒。
然而情感词典需要维护,构建成本较高,我们也可以用机器学习的方法将其看待为分类问题。讲关键词特征向量化,常用词袋模型(bag-of-words )以及连续分布词向量模型(word Embedding),特征化后,往往用CNN、RNN或者SVM算法。
Collaborative Fitering
协同过滤
简称CF算法。协同过滤不属于机器学习领域,所以你在机器学习的书上看不到,它属于数据挖掘。
协同过滤的核心是一种社会工程的思想:人们更倾向于向口味比较类似的朋友那里获得推荐。协同过滤主要分为两类,基于用户的user-based CF以及基于物体的item-based CF。虽然协同过滤不是机器学习,但它也会用到SVD矩阵分解计算相似性。
优点是简单,你并不需要基于内容做内容分析和打标签,推荐有新颖性,可以发掘用户的潜在兴趣点。
协同过滤的缺点是无法解决冷启动问题,新用户没行为数据,也没有好友关系,你是最不到推荐的;推荐会收到稀疏性的约束,你的行为越多,才会越准;随着数据量的增大,算法会收到性能的约束,并且难以拓展。
协同过滤可以和其他算法混合,来提高效果。这也是推荐系统的主流做法。
Tagging
标签/标注
这里稍微有歧义、如果是标签,间接理解为用户画像,涉及到标签系统。用户的男女、性别、出生地皆是标签,越丰富的标签,越能在特征工程中为我们所用。
如果是分类标签/标注,则是数据标注。有监督学习需要训练集有明确的结果Y,很多数据集需要人工添加上结果。比如图像识别,你需要标注图像属于什么分类,是猫是狗、是男是女等。在语音识别,则需要标注它对应的中文含义,如果涉及到方言,则还需要将方言标注为普通话。
数据标注是个苦力活。
个人水平一般,内容解读不算好,可能部分内容有错误,欢迎指正。
因为微信文章最多2W字,所以该指南需要拆分成三篇。本文写的是基础原理、统计学、编程能力和机器学习。请大家期待后续。

数据科学家成长指南(中)
作者:秦路,天善智能特约专家。资深数据分析师,数据化运营专家。擅长结合运营和数据,建立数据化运营体系。
个人公众号:秦路(微信ID:tracykanc)。
在《 数据科学家成长指南(上) 》中已经介绍了基础原理、统计学、编程能力和机器学习的要点大纲,今天更新后续的第五、六、七条线路:自然语言处理、数据可视化、大数据。
准备好在新的一年,学习成为未来五年最性感的职位么。
Text Mining / NLP
文本挖掘,自然语言处理。这是一个横跨人类学、语言学的交叉领域。中文的自然语言处理更有难度,这是汉语语法特性决定的,英文是一词单词为最小元素,有空格区分,中文则是字,且是连续的。这就需要中文在分词的基础上再进行自然语言处理。中文分词质量决定了后续好坏。
Corpus
语料库
它指大规模的电子文本库,它是自然语言的基础。语料库没有固定的类型,文献、小说、新闻都可以是语料,主要取决于目的。语料库应该考虑多个文体间的平衡,即新闻应该包含各题材新闻。
语料库是需要加工的,不是随便网上下载个txt就是语料库,它必须处理,包含语言学标注,词性标注、命名实体、句法结构等。英文语料库比较成熟,中文语料还在发展中。
NLTK-Data
自然语言工具包
NLTK创立于2001年,通过不断发展,已经成为最好的英语语言工具包之一。内含多个重要模块和丰富的语料库,比如nltk.corpus 和 nltk.utilities。Python的NLTK和R的TM是主流的英文工具包,它们也能用于中文,必须先分词。中文也有不少处理包:TextRank、Jieba、HanLP、FudanNLP、NLPIR等。
Named Entity Recognition
命名实体识别
它是确切的名词短语,如组织、人、时间,地区等等。命名实体识别则是识别所有文字中的命名实体,是自然语言处理领域的重要基础工具。
命名实体有两个需要完成的步骤,一是确定命名实体的边界,二是确定类型。汉字的实体识别比较困难,比如南京市长江大桥,会产生南京 | 市长 | 江大桥 、南京市 | 长江大桥 两种结果,这就是分词的任务。确定类型则是明确这个实体是地区、时间、或者其他。可以理解成文字版的数据类型。
命名实体主要有两类方法,基于规则和词典的方法,以及基于机器学习的方法。规则主要以词典正确切分出实体,机器学习主要以隐马尔可夫模型、最大熵模型和条件随机域为主。
Text Analysis
文本分析
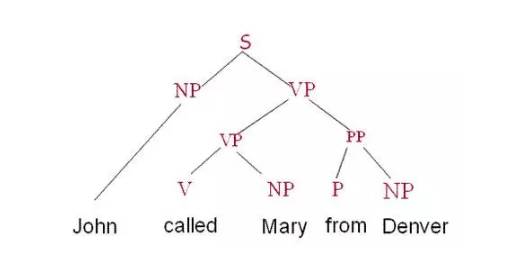
这是一个比较大的交叉领域。以语言学研究的角度看,文本分析包括语法分析和语义分析,后者现阶段进展比较缓慢。语法分析以正确构建出动词、名词、介词等组成的语法树为主要目的。
如果不深入研究领域、则有文本相似度、预测单词、困惑值等分析,这是比较成熟的应用。
UIMA
UIMA 是一个用于分析非结构化内容(比如文本、视频和音频)的组件架构和软件框架实现。这个框架的目的是为非结构化分析提供一个通用的平台,从而提供能够减少重复开发的可重用分析组件。
Term Document Matrix
词-文档矩阵
它是一个二维矩阵,行是词,列是文档,它记录的是所以单词在所有文档中出现频率。所以它是一个高维且稀疏的矩阵。
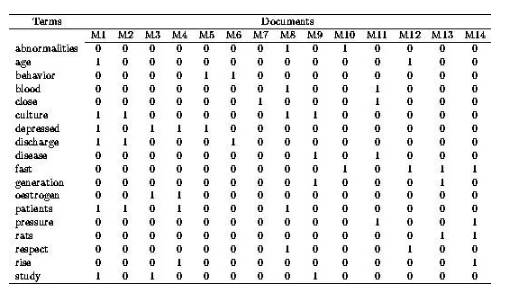
这个矩阵是TF-IDF(term frequency–inverse document frequency)算法的基础。TF指代的词在文档中出现的频率,描述的是词语在该文档的重要数,IDF是逆向文件频率,描述的是单词在所有文档中的重要数。我们认为,在所有文档中都出现的词肯定是的、你好、是不是这类常用词,重要性不高,而越稀少的词越重要。故由总文档数除以包含该词的文档数,然后取对数获得。
词-文档矩阵可以用矩阵的方法快速计算TF-IDF。
它的变种形式是Document Term Matrix,行列颠倒。
Term Frequency & Weight
词频和权重
词频即词语在文档中出现的次数,这里的文档可以认为是一篇新闻、一份文本,甚至是一段对话。词频表示了词语的重要程度,一般这个词出现的越多,我们可以认为它越重要,但也有可能遇到很多无用词,比如的、地、得等。这些是停用词,应该删除。另外一部分是日常用语,你好,谢谢,对文本分析没有帮助,为了区分出它们,我们再加入权重。
权重代表了词语的重要程度,像你好、谢谢这种,我们认为它的权重是很低,几乎没有任何价值。权重既能人工打分,也能通过计算获得。通常,专业类词汇我们会给予更高的权重,常用词则低权重。
通过词频和权重,我们能提取出代表这份文本的特征词,经典算法为TF-IDF。
Support Vector Machines
支持向量机
它是一种二类分类模型,有别于感知机,它是求间隔最大的线性分类。当使用核函数时,它也可以作为非线性分类器。
它可以细分为线性可分支持向量机、线性支持向量机,非线性支持向量机。
非线性问题不太好求解,图左就是将非线性的特征空间映射到新空间,将其转换成线性分类。说的通俗点,就是利用核函数将左图特征空间(欧式或离散集合)的超曲面转换成右图特征空间(希尔伯特空间)中的的超平面。
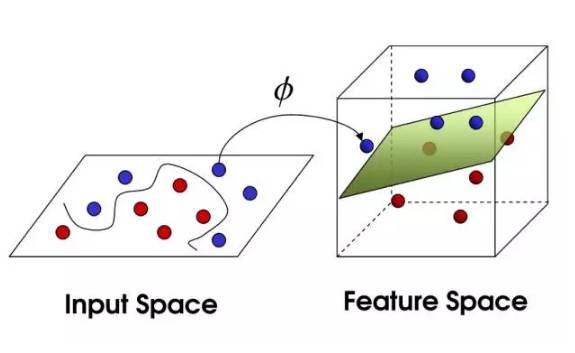
常用核函数有多项式核函数,高斯核函数,字符串核函数。
字符串核函数用于文本分类、信息检索等,SVM在高维的文本分类中表现较好,这也是出现在自然语言处理路径上的原因。
Association Rules
关联规则
它用来挖掘数据背后存在的信息,最知名的例子就是啤酒与尿布了,虽然它是虚构的。但我们可以理解它蕴含的意思:买了尿布的人更有可能购买啤酒。
它是形如X→Y的蕴涵式,是一种单向的规则,即买了尿布的人更有可能购买啤酒,但是买了啤酒的人未必会买尿布。我们在规则中引入了支持度和置信度来解释这种单向。支持度表明这条规则的在整体中发生的可能性大小,如果买尿布啤酒的人少,那么支持度就小。置信度表示从X推导Y的可信度大小,即是否真的买了尿布的人会买啤酒。
关联规则的核心就是找出频繁项目集,Apriori算法就是其中的典型。频繁项目集是通过遍历迭代求解的,时间复杂度很高,大型数据集的表现不好。
关联规则和协同过滤一样,都是相似性的求解,区分是协同过滤找的是相似的人,将人划分群体做个性化推荐,而关联规则没有过滤的概念,是针对整体的,与个人偏好无关,计算出的结果是针对所有人。
Market Based Analysis
购物篮分析,实际是Market Basket Analysis,作者笔误。
传统零售业中,购物篮指的是消费者一次性购买的商品,收营条上的单子数据都会被记录下来以供分析。更优秀的购物篮分析,还会用红外射频记录商品的摆放,顾客在超市的移动,人流量等数据。
关联规则是购物篮分析的主要应用,但还包括促销打折对销售量的影响、会员制度积分制度的分析、回头客和新客的分析。
Feature Extraction
特征提取
它是特征工程的重要概念。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。而很多模型都会遇到维数灾难,即维度太多,这对性能瓶颈造成了考验。常见文本、图像、声音这些领域。
为了解决这一问题,我们需要进行特征提取,将原始特征转换成最有重要性的特征。像指纹识别、笔迹识别,这些都是有实体有迹可循的,而表情识别等则是比较抽象的概念。这也是特征提取的挑战。
不同模式下的特征提取方法不一样,文本的特征提取有TF-IDF、信息增益等,线性特征提取包括PCA、LDA,非线性特征提取包括核Kernel。
Using Mahout
使用Mahout
Mahout是Hadoop中的机器学习分布式框架,中文名驱象人。
Mahout包含了三个主题:推荐系统、聚类和分类。分别对应不同的场景。
Mahout在Hadoop平台上,借助MR计算框架,可以简便化的处理不少数据挖掘任务。实际Mahout已经不再维护新的MR,还是投向了Spark,与Mlib互为补充。
Using Weka
Weka是一款免费的,基于JAVA环境下开源的机器学习以及数据挖掘软件。
Using NLTK
使用自然语言工具包
Classify Text
文本分类
将文本集进行分类,与其他分类算法没有本质区别。假如现在要将商品的评论进行正负情感分类,首先分词后要将文本特征化,因为文本必然是高维,我们不可能选择所有的词语作为特征,而是应该以最能代表该文本的词作为特征,例如只在正情感中出现的词:特别棒,很好,完美。计算出卡方检验值或信息增益值,用排名靠前的单词作为特征。
所以评论的文本特征就是[word11,word12,……],[word21,word22,……],转换成高维的稀疏矩阵,之后则是选取最适合的算法了。
垃圾邮件、反黄鉴别、文章分类等都属于这个应用。
Vocabulary Mapping
词汇映射
NLP有一个重要的概念,本体和实体,本体是一个类,实体是一个实例。比如手机就是本体、iPhone和小米是实体,它们共同构成了知识库。很多文字是一词多意或者多词一意,比如苹果既可以是手机也可以是水果,iPhone则同时有水果机、苹果机、iPhone34567的诸多叫法。计算机是无法理解这么复杂的含义。词汇映射就是将几个概念相近的词汇统一成一个,让计算机和人的认知没有区别。

Visualization数据可视化
这是难度较低的环节,统计学或者大数据,都是不断发展演变,是属于终身学习的知识,而可视化只要了解掌握,可以受用很多年。这里并不包括可视化的编程环节。
Uni, Bi & Multivariate Viz
单/双/多 变量
在数据可视化中,我们通过不同的变量/维度组合,可以作出不同的可视化成果。单变量、双变量和多变量有不同作图方式。
ggplot2
R语言的一个经典可视化包
ggoplot2的核心逻辑是按图层作图,每一个语句都代表了一个图层。以此将各绘图元素分离。
ggplot(...) +
geom(...) +
stat(...) +
annotate(...) +
scale(...)
上图就是典型的ggplot2函数风格。plot是整体图表,geom是绘图函数,stat是统计函数,annotate是注释函数,scale是标尺函数。ggplot的绘图风格是灰底白格。
ggplot2的缺点是绘图比较缓慢,毕竟是以图层的方式,但是瑕不掩瑜,它依旧是很多人使用R的理由。
Histogram & Pie(Uni)
直方图和饼图(单变量)
直方图已经介绍过了,这里就放张图。
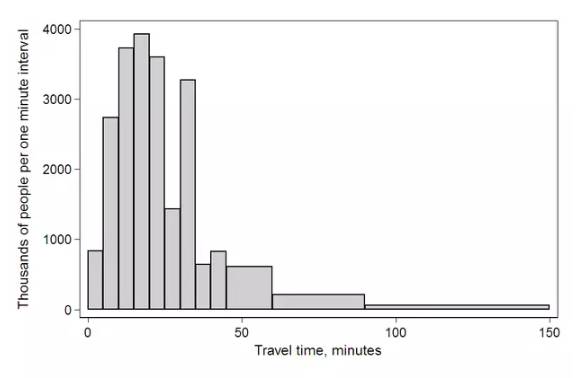
饼图不是常用的图形,若变量之间的差别不大,如35%和40%,在饼图的面积比例靠肉眼是分辨不出来。
Tree & Tree Map
树图和矩形树图
树图代表的是一种结构。层次聚类的实例图就属于树图。
当维度的变量多大,又需要对比时,可以使用矩形树图。通过面积表示变量的大小,颜色表示类目。

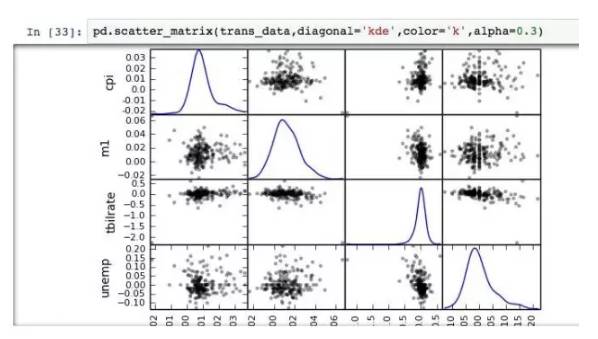
Scatter Plot (Bi)
散点图(双变量)
散点图在数据探索中经常用到,用以分析两个变量之间的关系,也可以用于回归、分类的探索。
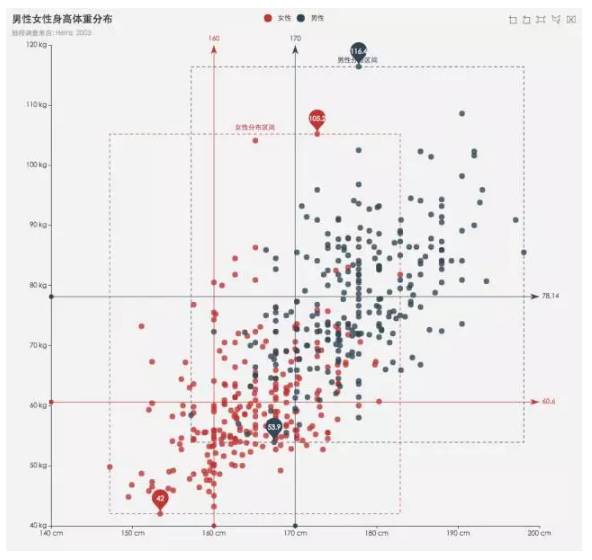
利用散点图矩阵,则能将双变量拓展为多变量。
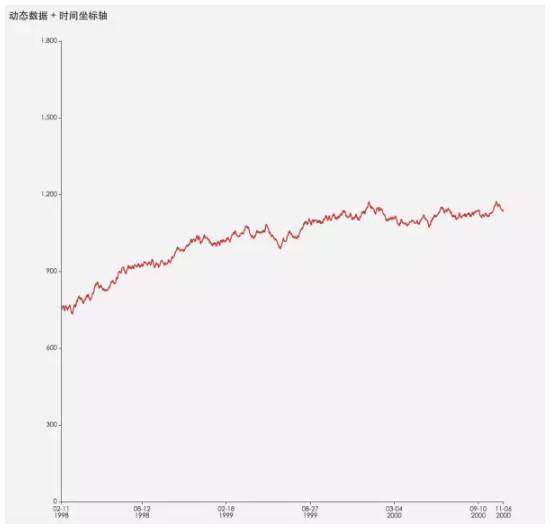
Line Charts (Bi)
折线图(双变量)
它常用于描绘趋势和变化,和时间维度是好基友,如影随形。
Spatial Charts
空间图,应该就是地图的意思
一切涉及到空间属性的数据都能使用地理图。地理图需要表示坐标的数据,可以是经纬度、也可以是地理实体,比如上海市北京市。经纬度的数据,常常和POI挂钩。
Survey Plot
不知道具体的含义,粗略翻译图形探索
plot是R中最常用的函数,通过plot(x,y),我们可以设定不同的参数,决定使用那种图形。
Timeline
时间轴
当数据涉及到时间,或者存在先后顺序,我们可以使用时间轴。不少可视化框架,也支持以时间播放的形式描述数据的变化。

Decision Tree
决策树
这里的决策树不是算法,而是基于解释性好的一个应用。
当数据遇到是否,或者选择的逻辑判断时,决策树不失为一种可视化思路。
D3.js
知名的数据可视化前端框架
d3可以制作复杂的图形,像直方图散点图这类,用其他框架完成比较好,学习成本比前者低。
d3是基于svg的,当数据量变大运算复杂后,d3性能会变差。而canvas的性能会好不少,国内的echarts基于后者。有中文文档,属于比较友好的框架。
R语言中有一个叫d3NetWork的包,Python则有d3py的包,当然直接搭建环境也行。
IBM ManyEyes
Many Eyes是IBM公司的一款在线可视化处理工具。该工具可以对数字,文本等进行可视化处理。应该是免费的。图网上随便找的。

Tableau
国外知名的商用BI,分为Desktop和Server,前者是数据分析单机版,后者支持私有化部署。加起来得几千美金,挺贵的。图网上随便找的。

——————
Big Data 大数据
越来越火爆的技术概念,Hadoop还没有兴起几年,第二代Spark已经后来居上。 因为作者写的比较早,现在的新技术没有过多涉及。部分工具我不熟悉,就略过了。
Map Reduce Fundamentals
MapReduce框架
它是Hadoop核心概念。它通过将计算任务分割成多个处理单元分散到各个服务器进行。
MapReduce有一个很棒的解释,如果你要计算一副牌的数量,传统的处理方法是找一个人数。而MapReduce则是找来一群人,每个人数其中的一部分,最终将结果汇总。分配给每个人数的过程是Map,处理汇总结果的过程是Reduce。
Hadoop Components
Hadoop组件
Hadoo号称生态,它就是由无数组建拼接起来的。
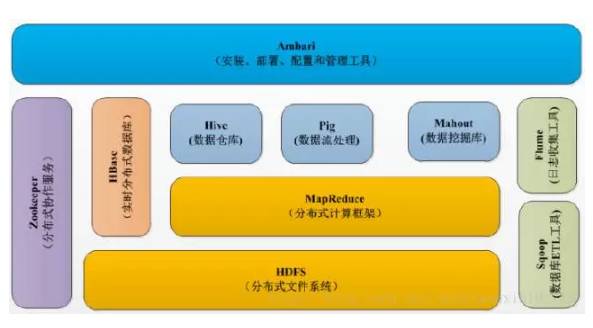
各类组件包括HDFS、MapReduce、Hive、HBase、Zookeeper、Sqoop、Pig、Mahout、Flume等。最核心的就是HDFS和MapReduce了。
HDFS
Hadoop的分布式文件系统
HDFS的设计思路是一次读取,多次访问,属于流式数据访问。HDFS的数据块默认64MB(Hadoop 2.X 变成了128MB),并且以64MB为单位分割,块的大小遵循摩尔定理。它和MR息息相关,通常来说,Map Task的数量就是块的数量。64MB的文件为1个Map,65MB(64MB+1MB)为2个Map。
Data Replication Principles
数据复制原理
数据复制属于分布式计算的范畴,它并不仅仅局限于数据库。
Hadoop和单个数据库系统的差别在于原子性和一致性。在原子性方面,要求分布式系统的所有操作在所有相关副本上要么提交, 要么回滚, 即除了保证原有的局部事务的原子性,还需要控制全局事务的原子性; 在一致性方面,多副本之间需要保证单一副本一致性。
Hadoop数据块将会被复制到多态服务器上以确保数据不会丢失。
Setup Hadoop (IBM/Cloudera/HortonWorks)
安装Hadoop
包括社区版、商业发行版、以及各种云。
Name & Data Nodes
名称和数据节点
HDFS通信分为两部分,Client和NameNode & DataNode。
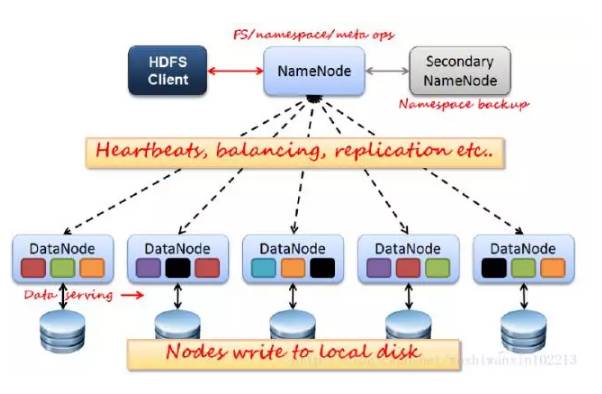
NameNode:管理HDFS的名称空间和数据块映射信息,处理client。NameNode有一个助手叫Secondary NameNode,负责镜像备份和日志合并,负担工作负载、提高容错性,误删数据的话这里也能恢复,当然更建议加trash。
DataNode:真正的数据节点,存储实际的数据。会和NameNode之间维持心跳。
Job & Task Tracker
任务跟踪
JobTracker负责管理所有作业,讲作业分隔成一系列任务,然而讲任务指派给TaskTracker。你可以把它想象成经理。
TaskTracker负责运行Map任务和Reduce任务,当接收到JobTracker任务后干活、执行、之后汇报任务状态。你可以把它想象成员工。一台服务器就是一个员工。
M/R Programming
Map/Reduce编程
MR的编程依赖JobTracker和TaskTracker。TaskTracker管理着Map和Reduce两个类。我们可以把它想象成两个函数。
MapTask引擎会将数据输入给程序员编写好的Map( )函数,之后输出数据写入内存/磁盘,ReduceTask引擎将Map( )函数的输出数据合并排序后作为自己的输入数据,传递给reduce( ),转换成新的输出。然后获得结果。
网络上很多案例都通过统计词频解释MR编程:
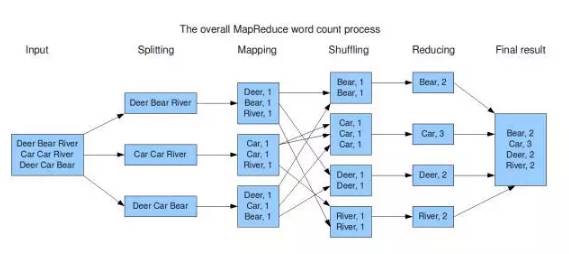
原始数据集分割后,Map函数对数据集的元素进行操作,生成键-值对形式中间结果,这里就是{“word”,counts},Reduce函数对键-值对形式进行计算,得到最终的结果。
Hadoop的核心思想是MapReduce,MapReduce的核心思想是shuffle。shuffle在中间起了什么作用呢?shuffle的意思是洗牌,在MR框架中,它代表的是把一组无规则的数据尽量转换成一组具有一定规则的数据。
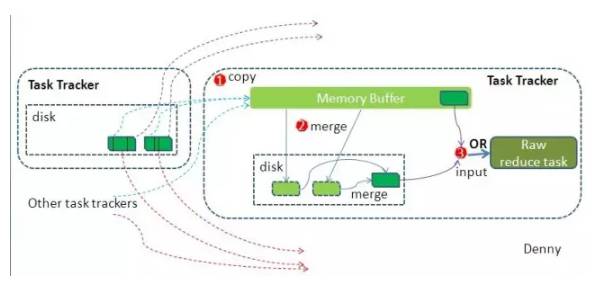
前面说过,map函数会将结果写入到内存,如果集群的任务有很多,损耗会非常厉害,shuffle就是减少这种损耗的。图例中我们看到,map输出了结果,此时放在缓存中,如果缓存不够,会写入到磁盘成为溢写文件,为了性能考虑,系统会把多个key合并在一起,类似merge/group,图例的合并就是{"Bear",[1,1]},{"Car",[1,1,1]},然后求和,等Map任务执行完成,Reduce任务就直接读取文件了。
另外,它也是造成数据倾斜的原因,就是某一个key的数量特别多,导致任务计算耗时过长。
Sqoop: Loading Data in HDFS
Sqoop是一个工具,用来将传统数据库中的数据导入到Hadoop中。虽然Hadoop支持各种各样的数据,但它依旧需要和外部数据进行交互。
Sqoop支持关系型数据库,MySQL和PostgreSQL经过了优化。如果要连其他数据库例如NoSQL,需要另外下载连接器。导入时需要注意数据一致性。
Sqoop也支持导出,但是SQL有多种数据类型,例如String对应的CHAR(64)和VARCHAR(200)等,必须确定这个类型可不可以使用。
Flue, Scribe: For Unstruct Data
2种日志相关的系统,为了处理非结构化数据。
SQL with Pig
利用Pig语言来进行SQL操作。
Pig是一种探索大规模数据集的脚本语言,Pig是接近脚本方式去描述MapReduce。它和Hive的区别是,Pig用脚本语言解释MR,Hive用SQL解释MR。
它支持我们对加载出来的数据进行排序、过滤、求和、分组(group by)、关联(Joining)。并且支持自定义函数(UDF),它比Hive最大的优势在于灵活和速度。当查询逻辑非常复杂的时候,Hive的速度会很慢,甚至无法写出来,那么Pig就有用武之地了。
DWH with Hive
利用Hive来实现数据仓库
Hive提供了一种查询语言,因为传统数据库的SQL用户迁移到Hadoop,让他们学习底层的MR API是不可能的,所以Hive出现了,帮助SQL用户们完成查询任务。
Hive很适合做数据仓库,它的特性适用于静态,SQL中的Insert、Update、Del等记录操作不适用于Hive。
它还有一个缺点,Hive查询有延时,因为它得启动MR,这个时间消耗不少。传统SQL数据库简单查询几秒内就能完成,Hive可能会花费一分钟。只有数据集足够大,那么启动耗费的时间就忽略不计。
故Hive适用的场景是每天凌晨跑当天数据等等。它是类SQL语言,数据分析师能直接用,产品经理能直接用,拎出一个大学生培训几天也能用。效率快。
可以将Hive作通用查询,而用Pig定制UDF,做各种复杂分析。Hive和MySQL语法最接近。
Scribe, Chukwa For Weblog
Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到的应用。
Chukwa是一个开源的用于监控大型分布式系统的数据收集系统。
Using Mahout
已经介绍过了
Zookeeper Avro
Zookeeper,是Hadoop的一个重要组件,它被设计用来做协调服务的。主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
Avro是Hadoop中的一个子项目,它是一个基于二进制数据传输高性能的中间件。除外还有Kryo、protobuf等。
Storm: Hadoop Realtime
Storm是最新的一个开源框架
目的是大数据流的实时处理。它的特点是流,Hadoop的数据查询,优化的再好,也要基于HDFS进行MR查询,有没有更快的方法呢?是有的。就是在数据产生时就去监控日志,然后马上进行计算。比如页面访问,有人点击一下,我计算就+1,再有人点,+1。那么这个页面的UV我也就能实时知道了。
Hadoop擅长批处理,而Storm则是流式处理,吞吐肯定是Hadoop优,而时延肯定是Storm好。
Rhadoop, RHipe
将R和hadoop结合起来2种架构。
RHadoop包含三个包(rmr,rhdfs,rhbase),分别对应MapReduce,HDFS,HBase三个部分。
Spark还有个叫SparkR的。
rmr
RHadoop的一个包,和hadoop的MapReduce相关。
另外Hadoop的删除命令也叫rmr,不知道作者是不是指代的这个……
Classandra
一种流行的NoSql数据库
我们常常说Cassandra是一个面向列(Column-Oriented)的数据库,其实这不完全对——数据是以松散结构的多维哈希表存储在数据库中;所谓松散结构,是指每行数据可以有不同的列结构,而在关系型数据中,同一张表的所有行必须有相同的列。在Cassandra中可以使用一个唯一识别号访问行,所以我们可以更好理解为,Cassandra是一个带索引的,面向行的存储。

Cassandra只需要你定义一个逻辑上的容器(Keyspaces)装载列族(Column Families)。
Cassandra适合快速开发、灵活部署及拓展、支持高IO。它和HBase互为竞争对手,Cassandra+Spark vs HBase+Hadoop,Cassandra强调AP ,Hbase强调CP。
MongoDB, Neo4j
MongoDB是文档型NoSQL数据库。
MongoDB如果不涉及Join,会非常灵活和优势。举一个我们最常见的电子商务网站作例子,不同的产品类目,产品规范、说明和介绍都不一样,电子产品尿布零食手机卡等等,在关系型数据库中设计表结构是灾难,但是在MongoDB中就能自定义拓展。
再放一张和关系型数据库对比的哲学图吧:

Neo4j是最流行的图形数据库。
图形数据库如其名字,允许数据以节点的形式,应用图形理论存储实体之间的关系信息。
最常见的场景是社交关系链、凡是业务逻辑和关系带点边的都能用图形数据库。
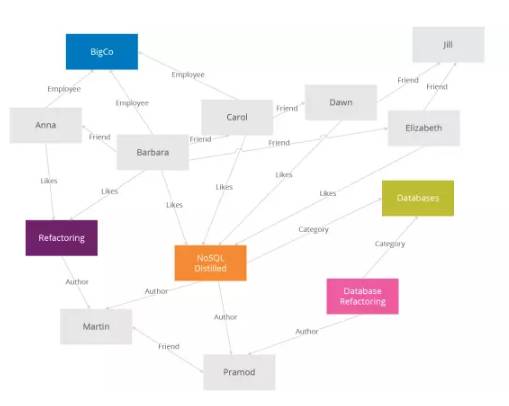
跟关系数据库相比,图形数据库最主要的优点是解决了图计算(业务逻辑)在关系数据库上大量的join操作,比如让你查询:你妈妈的姐姐的舅舅的女儿的妹妹是谁?这得写几个Join啊。但凡关系,join操作的代价是巨大的,而GraphDB能很快地给出结果。
个人水平一般,内容解读不算好,可能部分内容有错误,欢迎指正。
本文写的是文本挖掘、数据可视化和大数据。后续还只有一篇了。
数据科学家成长指南(下)
作者:秦路,天善智能特约专家。资深数据分析师,数据化运营专家。擅长结合运营和数据,建立数据化运营体系。
个人公众号:秦路(微信ID:tracykanc)。
本文是数据科学家学习路径的的完结篇,算上《数据科学家成长指南(上)》和《数据科学家成长指南 (中)》,总篇幅应该五万字多一点。今天更新数据获取、数据清洗、工具三条线路的内容,文字较少。
Data Ingestion 数据获取
这一块的概念比较混乱,主要是涉及太多的名词概念,很混淆,我大致粗略的翻译一下。不保证一定对。
Summary of Data Formats
数据格式概要
在进行数据工程或者数据工作前,数据科学家应该针对数据格式有一个全面的了解。
数据格式各种各样,既有结构化数据,也有非结构化数据。既有文本数据,数值数据,也有时间日期数据。哪怕同一类,如时间日期,也会因为时区的不同而有差异。
对数据格式的了解有助于后续工作的开展。
Data Discovery
数据发现
这是一个挺大的问题,我也不清楚作者的真实含义,姑妄言之。
从大目标看,是了解自己拥有哪些数据,因为对数据科学家来说,问题不是数据少,而是数据太大了,导致无法确定分析主题而无从下手。我应该用哪些数据?哪些数据有帮助哪些无用?哪些数据有最大的利用价值?哪些数据又真实性存疑?现阶段最需要解决的数据问题是哪个?我想都是摆在数据科学家面前的问题。Discovery即是发现,也是探索。
从小细节看,是针对数据进行探索性研究,观察各变量的分布、范围。观察数据集的大小。主要目的是了解数据的细节。
这们把这一过程理解为,在挖掘到数据金矿前,得先知道哪一个地方会埋藏有金矿。
Data Sources & Acquisition
数据来源与采集
当你知道这块地方有金矿时,你得准备好自己的工具了:确定自己需要的数据源。比如要进行用户行为分析,那么就需要采集用户的行为数据。采集什么时间段、采集哪类用户、采集多少数据量。如果这些数据不存在,则还需要埋点进行收集。
Data Integration
数据集成
数据集成指代的是将不同来源的数据集成在一起成为一个统一的视图。即可以是数据战略层面,比如两家公司合并(滴滴和Uber,美团和点评),为了业务层面的统一和规范,就需要将用户数据业务数据都汇总到一起,这个过程就叫做数据集成。
也可以是将某一次分析所需要的数据源汇总。比如上文的用户行为分析,如果来源于不同数据、则需要确定主键,采集后放在一起便于我们使用。
除此以外,第三方数据接入,DMP应也从属于这个概念。
Data Fusion
数据融合
数据融合不同于数据集成,数据集成属于底层数据集上的合并。而数据融合接近模型层面,我们可以想成SQL的Join(不确定)。
Transformation & Enrichament
转换和浓缩
这一块,在地图上和另外一条分支【数据转换Data Munging】有了交集。两条支线合并后就是完整的数据特征工程。这一步骤是将我们采集的数据集进行统计学意义上的变换,成为数据输入的特征。
Data Survey
数据调查
我也不了解已经完成数据工程后,为什么还需要数据调查…
Google OpenRefine
Google发布的开源的数据处理软件。
How much Data
多大的数据
一句比较偏概念的话,数据量级决定了后续方方面面,比如抽样和置信度,比如适用的算法模型,比如技术选型。
Using ETL
使用ETL,已经介绍过了
Data Munging 数据清理/数据转换
数据清洗过程,机器学习中最耗费时间的过程。
Dimensionality & Numerosity Reduction
维度与数值归约
虽然我们有海量数据,但是我们不可能在海量数据上进行复杂的数据分析和挖掘。所以要应用数据规约技术。它的目的是精简数据,让它尽可能的小,又能保证数据的完整性,使得我们在海量数据集和小数据集上获得相近的结果。
主要是删除不重要或不相关的特征,或者通过对特征进行重组来减少特征的个数。其原则是在保留、甚至提高原有判别能力的前提下进行。
Normalization
数据规范化
在机器学习过程中,我们并不能直接使用原始数据,因为不同数值间的量纲不一样,无法直接求和和对比。我们会将数据标准化,使之落在一个数值范围[0,1]内。方便进行计算。
常见的数据标准化有min-max,z-score,decimal scaling等。
最小-最大规范化(min-max)是对原始数据进行线性变换,新数据 = (原数据-最小值)/(最大值-最小值)。
z-score 标准化是基于均值和标准差进行计算,新数据=(原数据-均值)/标准差。
小数定标标准化(decimal scaling)通过移动数据的小数点位置来进行标准化,小数点移动多少取决于最大绝对值。比如最大值是999,那么数据集中所有值都除以1000。
温馨提示,标准化会改变数据,所以标准化应该在备份原始数据后进行操作,别直接覆盖噢。
Data Scrubbing
数据清洗
数据挖掘中最痛苦的工作,没有之一。数据一般都是非规整的,我们称之为脏数据,它是无法直接用于数据模型的,通过一定规则将脏数据规范活着洗掉,这个过程叫做数据清洗。
常见问题为:
缺失数据,表现为NaN,缺失原因各有不同,会影响后续的数据挖掘过程。
错误数据,如果数据系统不健全,会伴随很多错误数据,例如日期格式不统一,存在1970错误,中文乱码,表情字符等等。思路最好是从错误根源上解决。
非规范数据,如果大平台没有统一的数据标准和数据字典,数据会有不规范的情况发生。比如有些表,1代表男人,0代表女人,而有些表则反过来,也可能是上海和上海市这类问题。通常通过mapping或者统一的字典解决。
重复数据。将重复数据按主键剔除掉就好,可能是Join时的错误,可能是抽样错误,等等。
数据清洗是一个长期的过程。很多情况下都是靠人肉解决的。
Handling Missing Values
缺失值处理
数据获取的过程中可能会造成缺失,缺失影响算法的结果。
缺失值的处理有两类思路:
第一种是补全,首先尝试其他数据补全,例如身份证号码能够推断出性别、籍贯、出生日期等。或者使用算法分类和预测,比如通过姓名猜测用户是男是女。
如果是数值型变量,可以通过随机插值、均值、前后均值、中位数、平滑等方法补全。
第二种是缺失过多,只能剔除这类数据和特征。或者将缺失与否作为新特征,像金融风险管控,关键信息的缺失确实能当新特征。
Unbiased Estimators
无偏估计量
无偏估计指的是样本均值的期望等于总体均值。因为样本均值永远有随机因素的干扰,不可能完全等于总体均值,所以它只是估计,但它的期望又是一个真实值,所以我们叫做无偏估计量。
机器学习中常常用交叉验证的方法,针对测试集在模型中的表现,让估计量渐进无偏。
Binning Sparse Values
分箱稀疏值,两个合起来我不知道具体意思
分箱是一种常见的数据清洗方法,首先是将数据排序并且分隔到一些相等深度的桶(bucket)中,然后根据桶的均值、中间值、边界值等平滑。常见的分隔方法有等宽划分和等深划分,等宽范围是根据最大值和最小值均匀分隔出数个范围相同的区间,等深则是样本数近似的区间。
稀疏是统计中很常见的一个词,指的是在矩阵或者特征中,绝大部分值都是0。叫做稀疏特征或稀疏矩阵。协同过滤就用到了稀疏矩阵。
Feature Extraction
特征提取/特征工程
前面已经有过这个了,这里概念再扩大些。我们知道:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。说的再通俗一点,好算法+烂特征是远比不上烂算法+好特征的。
特征提取的过程主要分为:
数据预处理:将已经清洗过的数据进行转换,包括去量纲化、归一化、二元化、离散化、哑变量化、对数变换指数变换等。
特征选择:利用各类统计学选择特征,主要有Filter过滤法、Wrapper包装法、Embedded嵌入法。核心目的是找出对结果影响最大的特征。通常是从业务意义出发,好的业务专家能够直接挑选关键特征。另外有时候会遇到具备重要业务意义,但是非强特征的情况,这时候需要依据实际情况做抉择。
特征选择过程中需要考虑模型的泛化能力,避免过拟合。
降维:如果特征维度过大,会直接影响计算性能,需要降维。常用的降维方法有主成分分析法(PCA)和线性判别分析(LDA)。
当然暴力些也能直接选择全部变量,扔进RF或者XGBoost模型中跑一个晚上,直接根据Gini指数查看重要性。
Denoising
去噪
在机器学习和数据挖掘中,数据往往由很多噪声,去除噪声的方法有多种多样,一般说来,数据量越大,噪声造成的影响就越少。
噪声是非真实的数据,如果一个用户某些信息没有填写,为缺失值,它不应该属于噪声,真正的噪声应该是测试人员、机器人、爬虫、刷单黄牛、作弊行为等。这类数据没有业务意义,加入模型会影响结果,在早期就该排除掉。
另外一种噪声是无法解释的数据波动,和其他数据不相一致。因为数据会受一些客观条件影响造成波动,去噪是使异常波动消除。
去噪在数据清洗过程。
Sampling
抽样
很多时候统计不可能计算整体,比如中国平均工资就是拿14亿人口一个个计算过来的么?数据科学中,如果拿全样本计算,可能单机的内存吃不消,或者没有服务器资源。那么只能抽取部分样本作为数据分析。
抽样有简单随机抽样、系统抽样、分层抽样、整群抽样等。无论怎么样抽样,都要求样本有足够的代表性,即满足一定数量,又满足随机性。
Stratified Sampling
分层抽样
是抽样的一种。将抽样单位以某种特征或者规律划分成不同的层,然后从不同的层中抽样,最后结合起来作为总样本。
为什么需要分层抽样?如果整群符合随机性倒还好,如果不是会造成统计上的误差。我要做社会调研,各类人都需要,那么就必须有男有女、有老有少、有城市有农村,而不是呆在一个商场门口做调研。前者就属于分层抽样。
分层抽样可以降低样本量,效率高。
Principal Component Analysis
主成分分析
简称PCA,是一种统计方法。在实际工作中,我们会遇到很多变量数据(比如图像和信号),而我们又不可能一一列举所有的变量,这时候我们只能拿出几个典型,将这些变量高度概括,以少数代表多数的方式进行描述。这种方式就叫做主成分分析。
如果变量完全独立,那么主成分分析没有意义。PCA前提条件是存在一定相关性。
通过去均值化的m维原始矩阵乘以其协方差矩阵的特征向量获得k维投影,这里的k维就叫做主成分,用来代表m维。因为PCA的核心是少数代表多数,我们从k个主成分中选择n个作为代表,标准是能代表80%的原数据集。
在机器学习中,主要用来降维,简化模型。常见于图像算法。
ToolBox工具箱
最后内容了,这一块作者有拼凑的嫌疑,都是之前已经出现的内容。数据科学的工具更新换代非常快,好工具层出不穷,所以该篇章的工具就仁者见仁,写的简略一些。
MS Excel / Analysis ToolPak
微软的Excel,不多说了。
后者是Excel自带的分析工具库,可以完成不少统计操作。
Java, Python
两种常见编程语言,请在这里和我念:人生苦短,快用Python。
R, R-Studio, Rattle
R语言不再多介绍了。
RStudio是R的IDE,集成了丰富的功能。
Rattle是基于R的数据挖掘工具,提供了GUI。
Weka, Knime, RapidMiner
Weka是一款免费的,基于JAVA环境下开源的机器学习以及数据挖掘软件。
KNIME是基于Eclipse环境的开源商业智能工具。
RapidMiner是一个开源的数据挖掘软件,提供一些可扩展的数据分析挖掘算法的实现。
Hadoop Dist of Choice
选择Hadoop的哪个发行版
Hadoop的发行版除了社区的Apache hadoop外,很多商业公司都提供了自己的商业版本。商业版主要是提供了专业的技术支持,每个发行版都有自己的一些特点。
Spark, Storm
Hadoop相关的实时处理框架
作者写的时候比较早,现在后两者已经非常火了。是对Hadoop的补充和完善。它们自身也发展出不少的套件,SparkML,SparkSQL等
Flume, Scribe, Chukwa
Flume是海量日志采集、聚合和传输的系统。
Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到的应用。
chukwa是一个开源的用于监控大型分布式系统的数据收集系统。
Nutch, Talend, Scraperwiki
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
Talend是一家专业的开源集成软件公司,提供各类数据工具。
ScraperWiKi是一个致力于数据科学领域维基百科网站,帮助个人和企业获得最专业的可视化数据,并支持对数据进行分析和管理。
Webscraper, Flume, Sqoop
Webscraper是网页爬虫。
Flume是海量日志采集、聚合和传输的系统。
Sqoop是Haddop套件。
tm, RWeka, NLTK
tm是R语言的文本挖掘包。
RWeka是R的软件包,加载后就能使用weka的一些算法。
NLTK是自然语言工具包。
RHIPE
R与Hadoop相关的开发环境。
D3.js, ggplot2, Shiny
前两个不多说了。
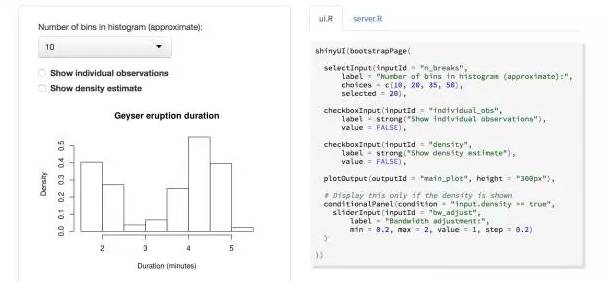
Shiny是RStudio团队开发的一款在线网页交互可视化工具。可以将R语言作为半个BI用。
IBM Languageware
IBM的自然语言处理。
Cassandra, MongoDB
2种NoSql数据库。
读完这里,三篇文章总共七十年的功力我都已经传给你们了。
这是最费时费力的三篇文章,当初翻译它,有巩固和学习的目的,只是内容远超我的预计。零散加起来前后耗时有两周,导致运营方向的内容长期处于停滞,现在可以恢复了。春节计划再写一篇数据化运营,如果时间充裕,还能再有两篇用户分层和数据库入门,现在看来,还是有希望的。

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“特色小镇”、“赛博物理”、“供应链金融”。
点击“阅读原文”,访问AI-CPS OS官网
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com




