一周论文 | 基于知识图谱的问答系统关键技术研究 #01
作者简介:
崔万云,复旦大学知识工场实验室博士生,研究方向为问答系统和知识图谱。
第一章 绪论
第 1 节 问答系统背景介绍
2011 年 10 月 14 日,苹果公司在其 iPhone 4S 发布会上隆重推出新一代智能个人助理 Siri。Siri 通过自然语言的交互形式实现问答、结果推荐、手机操作等功能,并集成进 iOS 5 及之后版本。2012 年 7 月 9 日,谷歌发布智能个人助理 Google Now,通过自然语言交互的方式提供页面搜索、自动指令等功能。2014 年 4 月 2 日,微软发布同类产品 Cortana,2014 年 10 月,亚马逊发布同类产品 Alexa。在此之前的 2011 年 9 月,由 IBM 研发的 Watson 机器人参加智力问答节目“Jeopardy!”,并战胜该节目的前冠军 Brad Rut- ter 和 Ken Jennings,豪取一百万美金大奖。
问答系统(Question Answering system, QA system)是用来回答人提出的自然语言问题的系统。问答系统的实现涉及到自然语言处理、信息检索、数据挖掘等交叉性领域。问答系统的历史最早可以追溯到 1960 年代的 BASEBALL [40]和 1970 年代的 LUNAR [101]。自那时起,有大量的问答系统涌现 [107, 22]。
智能时代,人类期望有更简单自然的方式与机器进行交互。因此以自然语言为交互方式的智能机器人广受青睐,受到各大 IT 厂家追捧。而其底层核心技术之一,即为自然语言问答系统。问答系统提供了自然语言形式的人与产品交互,降低了产品使用门槛,大幅提成用户体验。同时,问答系统可以帮助企业极大节省呼叫中心的投入。这些应用已经印证了问答系统的商业价值和社会价值。
问答系统的应用仍然具有新的潜力。人对于互联网的核心诉求之一是知识获取。从更长的时间窗口看,问答系统及聊天机器人,有着成为互联网知识获取新入口的优势。搜索引擎依然是现阶段最重要的互联网入口,也缔造了谷歌、百度等巨头企业。然而,基于关键字的搜索方式,缺乏语义理解,存在着与人的自然需求表达的隔阂,同时其返回结果需要人消耗大量时间剔除无意义的信息。随着人工智能、自然语言理解技术的进步,当问答系统足够智能,使人类的监督最小的时候,人就可以用问答从互联网完成知识获取。
问答系统的研究,是语义计算和自然语言处理的综合性应用。它包含了多种典型自然语言处理的基本模型,例如实体识别、短文本理解、语义匹配等。传统的单一模型研究往往仅关注某一具体问题的效果,而忽视在系统整体中的实用性。问答系统由于其复杂性,需要不同模型间的联通,才能带来综合性、实用性的技术突破。因此问答系统的研究为不同语义理解模型的整合提供了应用出口,为不同模型的关联分析、数据共享、参数共享等提出了实际需求,为多个自然语言语义理解技术模型的整体突破带来了技术愿景。
另一方面,问答系统研究的核心在于问题语义和知识语义的理解和相似度计算。这是计算机理解人类语言和知识表达的关联,跨越语义鸿沟的关键。这条横亘在计算机面前的语义鸿沟,其关键是计算机和人类在语义表达方式上的不同。人类倾向于使用多样化、非结构化的表达来描述问题和知识,而计算机则偏爱唯一化、结构化的知识。问答系统的研究,直接作用于缩短和跨越这一语义鸿沟,将多样而模糊的问题语义,映射到具体而唯一的计算机知识库中。
优秀的问答系统有两个关键点:精确的问题理解和高质量的知识来源。近年来随着大数据的发展,这两点纷纷迎来了数据层面的发展契机。
问题理解 由于问题的多样性和复杂性,很难人工制定一套规则完成问题理解。因此从数据中进行问题语义学习是必要的。社交类问答网站的兴起,包括Yahoo! Answers,Stack Overflow,百度知道等。由用户在上面进行提问和回答。这些网站包含了大量的问答对数据集,这成为了问题理解的优质语料。海量的问答语料为问题理解的学习提供了数据基础。
知识来源 由于知识表述的多样性,以及知识关联的复杂性,需要优质而大量的知识来源。近年来,一批高准确率、海量规模的知识图谱涌现,为问答系统提供了结构化、关联化的知识来源。这也为高效的问题回答提供了知识基础。
在数据发展的契机下,如何设定恰当模型学习并使用这一批数据就显得尤为重要。传统的基于规则的模型 [72]无法合理利用海量语料;基于关键词的模型 [98] 则没有进行深入的语义理解。而一些复杂的图模型等 [116, 112],则由于时间复杂度很难直接应用在如此大规模的语料中。本文的研究,即旨在寻求一种优秀的、系统性的问答系统表示和学习模型,并进行成功应用。
1.1. 知识图谱简介
2012 年 5 月份,Google 花重金收购 Metaweb 公司,并向外界正式发布其知识图谱(knowledge graph)。自此,知识图谱正式走入公众视野。开放领域大规模知识图谱纷纷出现,包括 NELL [15],Freebase [10],Dbpedia [6],Probase [103]等。
知识图谱本质上是一种语义网络。其结点代表实体(entity)或者概念(concept),边代表实体/概念之间的各种语义关系。知识图谱的出现是信息技术发展、时代发展的必然结果。语义的本质是关联。只有基于语义的数据互联才能发挥数据集成的非线性效应,才能获取大数据的特有语义。在这一背景下,数据互联(Linked Data)成为了一种运动,在全世界范围内方兴未艾。而数据互联的出现从深层次上来说是由时代精神所决定的。2011 年的 Science 曾经以“互联” 为题,出版专刊阐述了一个基本观点:我们身处在一个“互联”的时代。各种网络,诸如互联网、物联网、社会网络、语义网络、生物网络等等,将各类实体、概念加以互联。网络已经成为刻画复杂性的基本形态。管理、理解和使用各种网络数据,包括知识图谱,已经成为征服复杂性的基本手段。
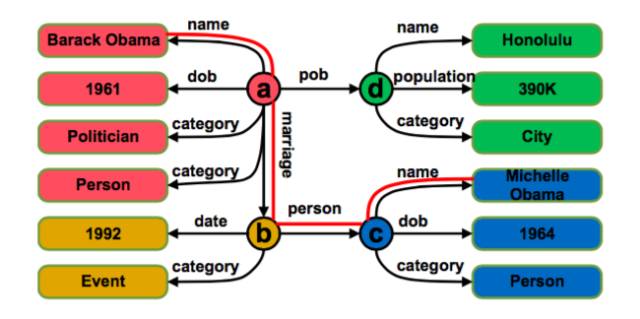
图 1.1:一个 RDF 知识图谱示例。 这里的“dob”和“pob”分别表示“出生日期”和“出生地”。注意到“spouse”关系是由多条边表示的name - marriage - person - name
大部分这样的知识图谱采用了 RDF 作为数据格式,它们包含数以百万记甚至亿记的 SPO 三元组(Sub ject,Predicate,Object 分别表示主语,属性,宾语)。图1.1 是一个奥巴马及其相关实体构成的知识图谱的示例。可以看到,知识图谱具有明显格式化特征,其值往往是一个实体名字或者一个数字、一个日期。这保证了基于知识图谱的问答系统的回答简洁性。另一方面,不同于基于信息检索的问答系统需要考虑数据真实性的问题,知识图谱的高数据质量保证了答案的准确性。
1.2. 知识图谱在问答系统上的数据优势
问答系统有多种可能的数据来源。传统的数据来源包括网页文档、搜索引擎、百科描述、问答社区等。无一例外,这些数据来源都是非结构化的纯文本数据。有大量基于信息检索的方法致力于研究从纯文本数据中进行知识抽取和回答。而近年来,基于知识图谱的问答系统则成为学术界和工业界的研究和应用热点方向。相较于纯文本,知识图谱在问答系统中具有以下优势。这些优势都促使本文使用知识图谱来作为问答系统的知识来源。
数据关联度-语义理解智能化程度问题 语义理解程度是问答系统的核心指标。对于纯文本数据,语义理解往往建立在问句与文本句子的相似度计算。然而语义理解和知识的本质在于关联,这种一对一的相似度计算忽视了数据关联。在知识图谱中,所有知识点被具有语义信息的边所关联。从问句到知识图谱的知识点的匹配关联过程中,可以用到大量其关联结点的关联信息。这种关联信息无疑更为智能化的语义理解提供了条件。
数据精度-回答准确率 知识图谱的知识来自专业人士标注,或者专业数据库的格式化抓取,这保证了数据的高准确率。而纯文本中,由于同类知识容易在文本中多次提及,会导致数据不一致的现象,降低了其准确率。
数据结构化-检索效率 知识图谱的结构化组织形式,为计算机的快速知识检索提供了格式支持。计算机可以利用结构化语言如 SQL、SPARQL 等进行精确知识定位。而对于纯文本的知识定位,则往往包含了倒排表等数据结构,需要用到多个关键词的倒排表的综合排名,效率较低。
1.3. 基于知识图谱的问答系统工作方式
通过知识图谱为知识源回答问题时,一个问题对应于知识图谱的一个子结构。所以其问答过程的核心在于将自然语言问题映射为知识图谱上的结构化查询。例如对于图 1.1 中的知识图谱,表 1.1 展示了一些它可以回答的问题,以及对应的子结构。

表 1.1:自然语言问题及其在知识图谱中的属性对应。
基于知识图谱的问答系统,需要解决两个核心问题:(1)如何理解问题语义,并用计算机可以接受的形式进行表示(问题的理解和表示);(2)以及如何将该问题表示关联到知识图谱的结构化查询中(语义关联)。
问题理解和表示:知识图谱中有数以千计的关系,而一种关系可以有数以千计的问法。例如,表 1.1 中的问题 ○a 和问题 ○b 都询问了檀香山市的人口,尽管它们的表达方式大相径庭。对于不同的问题形式,问答系统使用不同的表示方法。这些问题表示必须满足(1)归一具有相同语义的问题;(2)区分不同意图的问题。 所使用的问答语料库最终找到了 2782 种问题意图的约 2700 万种问题形式。所以问题表示形式设计就是一个巨大的挑战。
语义关联:在获取一个问题的表现示之后,系统需要将这一表现示映射为结构化查询。结构化查询主要依赖于知识库中的属性。由于属性和表现模型之间的跨越,寻找这样的匹配并非直接。例如,在表 1.1 中,系统需要知道问题 ○a 与属性 population 有着相同的语义。此外,在 RDF 图中,许多二元关系并不仅仅对应一条边,而是某种复杂的结构:在图 1.1 中,“配偶”关系由 marriage → person → name 的路径表示。对于本文使用的知识库,超过 98% 的关系对应于类似的复杂结构。
第 2 节 研究架构与模块关联
2.1. 研究架构
本文研究架构见图 1.2。依据其理解语义的粒度从小到大,从具体技术到上层应用,主要分为以下五个部分。

图 1.2:研究架构图
1. 实体层:语义社团搜索 实体是自然语言的基本单位之一,基于知识图谱的实体语义理解为上层语义计算,特别是问题中的实体语义,提供基本支持。本文研究了面向实体的语义社团搜索模型,特别是从模型的表达性、有效性等方面研究不同社团定义的合理性。其次,语义社团搜索作为语义理解的原子操作,需要保证在大图上的实时回答。为此,本文研究了大图上的高效社团搜索方法,特别是基于大图的局部性的高效搜索方法。
2. 短文本层:动词理解和实体概念化 短文本是自然语言的最常见形式之一,起到对实体和更复杂文本单元(如问句)的承接作用。短文本上已经有了句法结构特征和上下文关系。知识图谱的作用,则可以使系统更精确表示句法结构和上下文信息。本文提出了动词模板,用来表示细粒度的动词语义。并且基于动词模板,优化了基于上下文的实体概念化方法。
3. 问题层:问题语义理解和表示 问题的表示学习,是计算机理解问题的核心步骤。本文提出了问题的模板表示方法,将问题的实体映射到其对应概念,用以表示问题语义。此外,本文还利用问题模板的思路,解决了复杂问句的解析问题。
4. 问答系统层:问题与知识图谱的语义关联 基于问题的模板表示,需要将其映射为知识图谱的结构化查询,最终实现问答。这一映射主要取决于知识库中的属性。本文提出了基于真实问答语料的学习方法,利用概率图建模问题模板到答案的生成,并进行语义关联的参数估计。同时,本文利用属性扩展,研究知识图谱中的多步属性这一复杂知识表示形式,学习问题模板到复杂知识图谱结构的映射。
5. 应用层:面向应用的领域问答适配 由于通用人工智能依然是非常困难的,出于具体应用场景需要,大部分真实应用中的问答系统是面向具体领域的。例如 IBM 的 Watson 专注于医疗和财经领域,亚马逊的 Alexa 专注于智能家庭和零售领域,微软的 Cortana 专注于操作系统助手。为了对问答系统作领域适配,本文有两方面的工作,第一,将开放领域的自然语言模型(例如 POS tagging),适配到具体领域,使得问答系统相关自然语言处理模块在特定领域正常运行。第二,从自然语言文本中,为特定领域进行自动化领域相关的知识抽取。
2.2. 研究系统性
整个研究强调整个研究的系统性,即不同层级之间的关联。一般来说,低层的结果被使用作为高层模型输入的一部分。其具体系统性关联如下:
1. 从实体到短文本 实体层为短文本中的实体提供了语义社团。利用该语义社团,短文本层可以得到实体的相关概念,以进行实体语义消岐。从而帮助短文本层得到更精确的实体概念信息和语义信息。
2. 从短文本到问题 短文本层为问题层提供动词语义以及实体概念信息。这为问题层的问题模板表示学习过程中的实体概念化提供了支持。
3. 从问题到问答系统 问题层的输出,即问题模板,是整个问答系统语义关联的基础。问答系统以问题模板为输入,学习问题模板到知识图谱结构的映射。
4. 从问答系统到领域应用 本文会将利用迁移学习将系统的自然语言处理模块应用到领域问答系统中。同时将应用层抽取的领域知识作为问答系统的知识源,以使问答系统可以适应领域问答。
第 3 节 本文组织结构
本文按照架构(图 1.2)中自底向上的顺序具体介绍每一项研究内容。第三章介绍实体层的语义社团搜索。第四章介绍短文本层的动词模板,并在应用中讲述如何利用动词模板提升基于上下文的实体概念化效果。第五章提出了问答系统 KBQA,包括对问题的模板化理解,以及问题模板到知识图谱的映射学习。在第六章和第七章,本文分别介绍了两个用于问答系统领域适配的技术:自言语言处理模型的领域迁移,和领域知识抽取。第八章给出了一个基于 Freebase 的具体系统展示。最后的第九章进行了总结和展望。
第四章 基于知识图谱的短文本动词理解
动词理解在自然语言的语义理解中至关重要。对于动词的理解,有助于问答系统在短文本层面理解问题语义,进而帮助实现上下文相关的实体概念化。传统的动词表示,如 FrameNet、PropBank、VerbNet 等,专注于动词的角色。但是动词角色过于粗粒度,无法表示和区分动词的语义。本章将介绍基于动词模板的动词语义表示模式。每个动词模板对应于动词的单个语义。首先本文分析了动词模板的原则:一般性和特殊性原则。然后提出一个非监督的最小描述长度模型来建模此问题。实验结果证明了模型的有效性。论文进一步将动词模板应用在上下文相关的实体概念化问题上。
第 1 节 引言
动词对句子的理解是至关重要的 [30, 104]。动词理解的一个主要问题是歧义性 [77],即当同一动词和不同宾语相结合时,会表示不同的语义。本文只考虑和宾语相结合的动词,即及物动词。就像例 4.1 中展示的那样,大部分动词都是具有歧义的。因此需要一个好的动词语义表示方式,来表示其奇异性。
例 4.1. eat 具有以下几种意思:
把食物在嘴里咀嚼并吞咽,例如 eat apple,eat hot dog。
吃一顿饭,例如 eat breakfast,eat lunch,eat dinner。
其他俗语。例如 eat humbie pie 表示承认错误。
许多典型的动词表示方式,包括 FrameNet [7],PropBank [52]和 VerbNet [82],侧重描述动词的语义角色(例如“eat”的摄食者和被进食物)。但是,语义角色是一种非常粗糙的表示,无法区分动词细粒度的语义。不同短语中的同一动词,可以在具有同样语义角色的同时表达不同的语义。在例 4.1 中,无论是“eat apple”还是“eat breakfast”,都具有摄食者等角色。但是这些 eat 具有有不同的语义。
由于无法表达动词的歧义性,传统动词表示形式方式无法完整的表示动词语义。在句子“I like eating pitaya”,人直接可以推断“pitaya”大概是一种食物,因为食物是最常见的“eat”的对应语义。这就可以让人利用上下文相关的概念化技术将“pitaya”理解为食物。而传统动词表示形式只理解“pitaya”是一个被进食物,而无法知道它是一顿饭还是一种食物。
动词模版 本文认为,动词模版可以用来表示一个动词更细粒度的语义。动词模版基于语言学家对单词结合的两个原则设计 [84]:俗语原则(idiom principle)和开放选择原则(open-choice principle)。基于这两个原则,本文设计了两种类型的动词模版:
概念化模版:根据开放选择原则,一个动词可以和任何宾语搭配。这些宾语具有特定的概念,可以用于语义表示和消岐 [103]。这促使本章使用宾语的概念来表示动词语义。在例 4.1 中,eat breakfast 和 eat lunch 具有相似的语义,因为这些宾语对应同样的概念 meal。因此,本章将动词短语中的宾语替换为它的概念,从而组成概念化动词模板动词 $C 概念(例如 eat $Cfood)。根据宾语的概念,每个开放选择原则中的动词短语会被关联到一个概念化模板中。
俗语模版:根据俗语原则,有些动词短语的具体语义是和宾语概念无关的。本章在宾语前增加 $I 标记来表示此俗语模板(即动词 $I 宾语)。
根据上述定义,本文使用动词模板来表示动词的不同的语义。分配到相同的动词模板的动词短语,其动词具有相似的语义,而分配到不同动词模板的动词具有不同的语义。通过动词模版,可以将“eat pitaya”对应到模板“eat $Cfood”,从而得到“I like eating pitaya”中的“pitaya” 是一种食品。另一方面,俗语模版表示哪些短语不应被概念化。表 4.1 中列出了例 4.1 中的短语的对应模板。
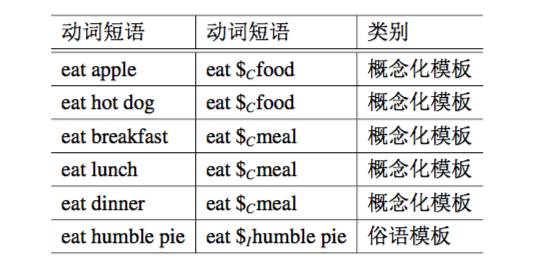
表 4.1:动词短语及其动词模板
这样,本文的核心问题在于如何对动词产生概念化模板或俗语模板。为了做到这一点,实验使用了两个公开数据集:Google Syntactic N-Grams 和 Probase [103]。Google Syntactic N-Grams 包含了百万级别的动词短语,提供了动词短语的丰富语料。Probase 包含了丰富的实体-概念信息,帮助算法将宾语映射到其概念。这样问题就变为给定动词 v 以及其对应的动词短语集合,对每个动词短语产生一个动词模板(概念化模板或者俗语模板)。然而,这个模板生成的过程是具有挑战性的。一般来说,在此过程中的最严重问题在于一般性和特殊性之间的取舍。本文在下边具体说明。
第 2 节 相关工作
传统的动词理解 在此讨论比较动词模板与传统的动词理解 [73] 方法。FrameNet[7] 建立在大多数词汇可以被很好的通过语义框架[32] 理解的思想上。语义框架是对于一类事件,关系,或者在其中实体与参与者的描述。每一个语义框架使用了框架元素(FEs)来进行简单的注解。PropBank [52] 使用了人工标注的谓词和语义对象变量,来获取准确的谓词-变量结构。谓词这里指动词,变量是动词的其他对象。为了使 PropBank 更加形式化,变量通常包含施动者,受动者,工具,起始点和终止点等。VerbNet[82] 将动词根据它们基于 Levin classes[60] 的句法模板来分类。所有的动词理解都关注于动词的不同角色而不是它的语义。然而动词的不同语义可能有相同的角色,现有的理解并不能完整的表述动词的语义。
实体概念化 本章工作的典型应用就是基于上下文的实体概念化理解。实体概念化决定了对于一个实体最适合的概念。传统的基于文本检索的方法利用 NER[92] 来进行实体概念化。但是 NER 经常只含有一些粗糙的预定义概念。Wu 等人建立了一个有大量词汇信息的知识库 Probase[103],来提供丰富的 IsA 关系。对于 IsA 关系,基于上下文的实体概念化理解[50]会更有效。Song 等人[87]提出了一种利用 Naive Bayes 的实体概念化方法。Wen 等人[46]提出了主流的联合共现网络,IsA 网络和概念聚类的模型。
语义构成 本章利用动词模板来表示动词短语。然而语义构成的工作致力于将任意的短语表示为向量或树结构。基于向量空间的模型被广泛地被用来表示单个单词的语义。因此,一个直接的表示词汇的语义的方法就是将这些出现在短语中的单词的向量取平均值[105]。但是这个方法却忽略了词之间的句法关系 [57]。Socher 等人[85]将句法关系表示为一棵二叉树,并且将它与单词的向量利用 recursive neural network 同时训练。目前,word2vec[67] 显示了它在单词表示方面的优势。 Mikolov 等人[68]进行了更深层次的研究并使 word2vec 可以表示短语向量。总之,这些工作并没有使用有关动词的俗语短语和动词的对象的概念来表示动词的语义。
2.1. 一般性和特殊性的取舍问题
本节试着问答问题:“什么样的动词模板可以很好的总结一个动词短语集合”。由于每个动词短语都有若干候选动词模板,这个问题的回答是很困难的。直觉上,一个好的动词模板需要兼备一般性和特殊性。
一般性:本章希望用较少的模板个数来覆盖一个动词的所有语义。否则,抽取出的动词模板会变得琐碎。考虑极端的情况:所有的动词短语都被考虑为俗语模板。这些俗语模板显然大部分都是没意义的,因为大部分动词短语需要被概念化。
例 4.2. 在图 4.1 中,模(eat $Cmeal)显然比三个模板(eat $Ibreakfast + eat $Ilunch+eat $Idinner)要好。前者提供了一个更一般的模板表示。
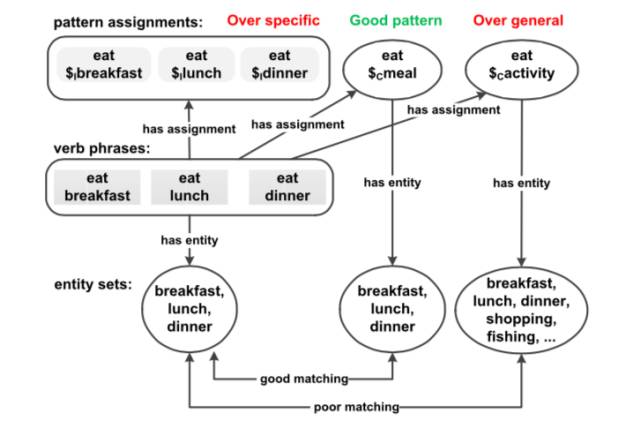
图 4.1:模板分配的例子
特殊性:另一方面,本章期望产生的动词模板具备特殊性,否则结果可能会变得非常模糊。就像例 4.3 展示的那样,算法可以将任意宾语都概念化到某些非常高层的概念上,例如 activity,thing,item 等。这样概念化的模板就会变得特别模糊而无法精确描述一个动词的语义。
例 4.3. 对于图 4.1 中的动词短语,eat $Cactivity 是比 eat $Cmeal 更一般性的动词模板。这样,一些错误的动词模板,例如 eat shopping 或 each fishing 也会被识别为 eat 的有效例子或短语。相反,eat $Cmeal 具有更好的特殊性。因为 breakfast、lunch、dinner 是三个典型的 meal 的实例。而 meal 几乎不再具有其它典型实例。
贡献 一般性和特殊性显然是相互矛盾和制约的。因此如何在一般性和特殊性之间做取舍构成了本文的主要挑战。本文使用最小描述长度(minimum description length,MDL)作为调和这两个目标的基本框架。更具体的,本章的贡献可以被总结如下:
本章提出了动词模板——一种新型的动词语义表现形式。本章提出了两类动词模板:概念化模板和俗语模板。动词模板可以表示动词的歧义性,因此可以用来识别动词的不同语义。
本章提出了关于动词模板抽取的两个原则:一般性和特殊性原则。本章阐述了这两个原则间的互相制约,并提出了一个基于最小描述长度的无监督模型来产生高质量动词模板。
本章进行了多样的实验。其结果证实了模型和算法的有效性。
第 3 节 问题模型
本节形式化定义从动词短语中提取动词模板的问题。此模板提取过程中要计算两个值:(1)每个动词短语的动词模板分配;(2)每个动词的动词模板分布。接下来,本文将首先给一些基本的定义。接着提出了一种基于最小描述长度的问题模型,并证明了该模型的合理性。请注意,不同动词的模板是独立的,在问题和算法描述中可以单独考虑每一个动词。因此在以下的说明中,将只讨论针对某一给定动词的解法。
3.1. 初步定义
首先给出动词短语、动词模板、模板分配的标准定义。
定义 4.4(动词短语) 一个动词短语 p 在自然语言中是一个动词及其对应宾语。本文把短语 p 中的宾语表示为 op。
定义 4.5 (动词模板)。动词模板是一个或若干个动词短语的总结。每个动词短语只有一个动词模板对应。对应于同一动词模板的动词短语,其动词语义是相似的。本文用 a 表示动词模板。考虑两种动词模板:
俗语模板是“verb $object”的形式。只有动词短语“verb object”可以对应模板“verb$object”。
概念化模板是“verb$concept”形式。动词短语“verbobject”可以对应于“verb$con- cept”,仅当 object 和 concept 具有 isA 关系。将概念化模板 a 中的概念表示为 ca 。
定义 4.6(模板分配)。模板分配是一个函数 f : P → A,它将任意一个动词短语映射到其对应动词模板模板。 f ( p) = a 表示 p 的模板是 a。注意每个模板可以有任意数量的对应的动词短语。
表 4.1 中展示了一些动词短语、动词模板和模板分配的例子。
短语的分布是已知的(在本章的实验中,其动词短语分布是从 Google Syntactic Ngam 数据库中抽取的)。所以本文中模板抽取的目标倾在于找到 f 函数。有了 f 函数,就可以很容易的计算模板分布 P(A):
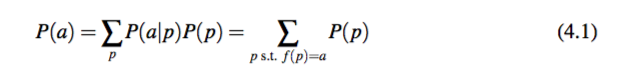
这里 P(p) 是给定动词的短语分布。注意这里的第二个等式是成立的,因为当f(p) =a 时,P(a|p) = 1。P(p) 可以直接由 p 的频率得到,见公式 4.14。
3.2. 模型
这一小节提出了一种基于最小描述长度的模型,它可以精确地建模模板分配中的一般性和特殊性原则。使用最小描述长度的出发点:最小描述长度(minimum descrip- tion length,MDL)[9]是基于数据压缩程度的数据复杂度描述方法。而在动词模板分配问题中,一个动词模板可以被视为一组动词短语的压缩。对于概念化的模板,直觉上来说,如果一个模板分配是一个对于动词短语的简短描述,那么这个分配方案就抓住了底层的动词语义特征。
给定动词短语集合,寻找一个模板分配函数 f,使得这些动词短语的描述长度最短。假设 L( f )表示 f 的描述长度,那么可以将动词短语模板分配问题形式化表示为:
问题定义 4.7(模板分配)。给定动词短语分布 P(P),找到模板分配 f,使得 L(f) 最小化:

对于每个短语 p,它的编码方式包含两部分:左侧部分编码它的对应模板 f(p)(表示为 l(p, f )),右侧部分编码在给定模板时的动词短语(表示为 r(p, f ))。这样可以得到:
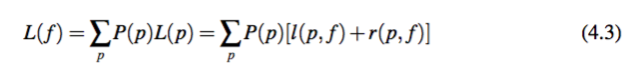
这里 L(p) 表示 p 的整体描述长度,包括左侧编码长度和右侧编码长度。l(p, f):模板编码长度为了编码p的模板 f(p),需要的编码长度为:

这里 P( f ( p)) 可以被公式 4.1 计算得到。
r(p, f):给定模板的短语编码长度在得到其模板 f(p) 之后,使用从模板 f(p) 到动词短语 p 的转移概率 PT (p|f(p)) 来编码 p。PT (p|f(p)) 是通过 Probase[103] 计算得来的,并在本文计算中视为先验概率。因此,对 p 的编码需要的编码长度是−logPT (p|f(p))。为 了计算 PT (p|f(p)),考虑两种情况:
情况一:f (p) 是一个俗语模板。这样由于俗语模板只有一个对应的动词短语,有PT (p|f(p))=1。
情况二:f(p) 是一个概念化模板。在这种情况下,只需要编码给定概念的动词宾语 op。使用从概念 cf(p) 到实体 op 的转移概率 PT (op|cf(p))(通过 Probase 得到)。实验部分会给出关于此概率的更明确的计算方法。
这样得到:

总长度 通过将所有动词短语的描述长度相加,得到模板分配 f 下的总描述长度 L:
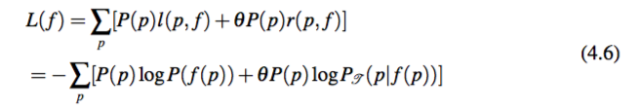
请注意这里公式引入了超参数 θ 来控制 l(p, f ) 和 r(p, f ) 的相对重要程度。后文将会解释 θ 是如何具体影响动词模板在一般性和特殊性中的取舍。
合理性分析 接下来,本文会通过证明该模型对于动词模板的两个原则(即一般性和特殊性原则)的体现,来说明模型的合理性。为了简单起见,定义 LL( f ) 和 LR( f ) 分别用来表示对于动词模板部分的编码总长度,和给定模板编码具体动词短语的编码长度。具体计算如下:
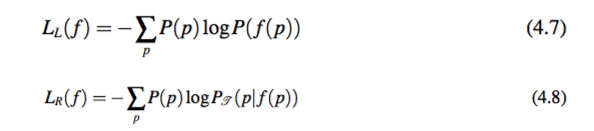
一般性 通过最小化 LL( f ),模型可以找到具有一般性的模板。假设 A 表示所有在分配 f 下的模板,Pa 表示 a ∈ A 对应的动词短语集合,即满足 f(p) = a 的动词短语集合。根据公式 4.1 和 公式 4.7,有:
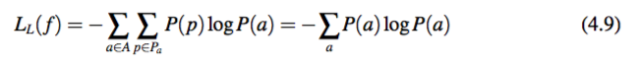
所以 LL( f ) 即为动词模板的熵(entropy)。最小化熵将使得模型选择并使用较少的动词模板。这体现了模板的一般性原则。
特殊性 通过最小化 LR( f ),模型可以找到具有特殊性的模板。公式 4.10 的内部实际上是 P(P|a) 和 PT (P|a) 的交叉熵。因此最小化 LR( f ) 会使得模型找到使 P(P|a) 和 PT (P|a) 尽量接近的分布。这体现了特殊性原则。
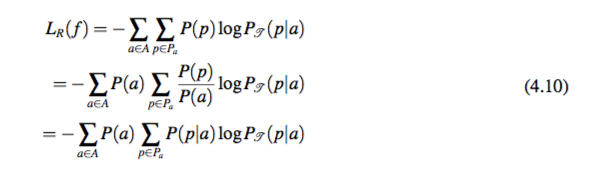
3.3. 算法
本节提出了一种基于模拟退火的算法来解决问题 4.7,并展示了如何利用外部知识来优化俗语模板。本章使用模拟退火算法来计算最好的动词模板分配 f 。算法流程如下。首先选取随机的分配作为初始值(初始温度)。然后,算法生成并评估一个新的分配,如果它是一个更好的分配,用这个分配替换掉之前的分配;否则,算法以一定的概率接受这个分配(温度降低)。重复生成以及替换的步骤直到最后的 β 轮结果没有出现变化(终止条件)。
候选分配生成:显然,候选分配的生成对于算法的效用和效率来说非常关键。接下来首先介绍一个直接生成候选分配的方法。然后对候选动词模板作典型性的改进。
直接生成方法:模板分配 f 的最基本的单元是对一个动词短语的模板分配。直接生成方法会随机选择一个动词短语 p 并将它分配给一个随机的模板 a。产生一个有效的模板。算法需要确保(1)a 是一个 p 的俗语模板,或者(2)a 是一个实体概念化模板并且 ca 是 op 的上位词。然而,因为很难达到最优状态,这个方法效率很低。对于一个动词,假设它有 n 个动词短语并且每一个动词短语都有平均 k 个候选模板。达到最优状态的最小轮数平均是 kn,这在大语料库上是不可接受的。
利用典型性的生成方法:注意到对于每一个确定的动词词组,一些模板会因为它们更高的典型性而比其他模板更有效。例 4.8 介绍了这种情况。这使算法倾向于将动词短语分配给具有更高典型性的动词模板。
例 4.8. 对于 eat breakfast,eat lunch。eat $Cmeal 显然比 eat $Cactivity 更好。因为对于一个真实的人来说,他更容易想到 eat $Cmeal 而不是 eat $Cactivity。换句话说 eat $Cmeal 相比 eat $Cactivity 具有更高的典型性。
更形式化的,对于一个确定的动词短语 p,定义 t(p,a) 衡量模板 a 相对于动词短语 p 的典型性。如果 a 是俗语模板,t(p,a) 被设置成一个常数 γ。如果 a 是实体概念化模板,使用 op 相对于 ca 的典型性定义 t(p,a),这里 ca 是模板 a 的概念。特别的有:

这里 PT (op|ca) 和 PT (ca|op) 可以从 Probase [103] 通过式 4.15 推导出。在这个计算中,公式同时考虑从 ca 到 op 的概率,和从 op 到 ca 的概率,以获得它们相互之间的影响。
3.3.1. 流程
现在将介绍解决方案的详细流程:
1. 通过将每一个 p 分配给它的俗语模板来初始化 f(0)。
2. 随机选择新的动词模板 a。对于每一个动词短语 p,
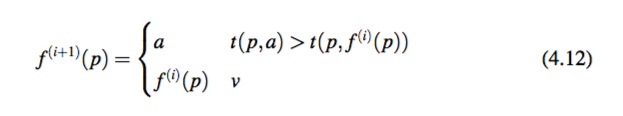
这里 f (i) 是第 i 轮产生的分配。
3. 以如下概率接受 f(i+1):

这里 L(f(i+1)) 是 f(i+1) 的描述长度,S 是 SA 算法进行的轮数,A 是控制冷却速度的常数。
4. 重复步骤 2 和步骤 3,直到最后 β 轮结果不发生变化。
步骤 2 和步骤 3 使算法不同于一般的基于 SA 的解决方法。在步骤 2 中,对于每一 个随机选择的动词模板 a,算法计算它的典型性。如果它的典型性大于当前分配的动词模板,则将这个动词短语分配给动词模板 a。在步骤 3 中,当一个新的分配的描述长度比上一轮的分配更小时,算法接受这个新的分配。否则,算法以 (L( f (i)) −L( f (i+1)))/SA 的概率接受原有的分配。它的合理性是显然的:L( f (i+1)) 相对于 L( f (i)) 的偏离越大,f (i+1) 被接受的概率越小。
复杂性分析 假设有 n 动词短语。在每一轮循环中,算法随机选择一个动词模板,然后计算它对于所有 n 个动词短语的典型性,这需要 O(n) 的时间来实现。然后,算法通过加和所有 n 个动词短语的编码长度来计算 f (i+1) 的描述长度。这个步骤同样需要 O(n) 时间。假设算法在 S 轮后终止,则整体的复杂度将是 O(Sn)。
利用俗语的先验知识 可以从外部词典中直接找到许多动词的俗语。如果在字典中,一个动词短语被认定为俗语,它应该被直接分配到俗语模板。特别的,本章工作中首先从线上字典中爬取了 2868 个动词短语。然后在步骤 2 中,当 p 是其中一个俗语短语时,将它排除在分配更新的过程之外。
第 4 节 实验
4.1. 设置
动词短语数据 模板分配会使用动词短语的分布 P(p)。为了计算 P(p),实验使用在 Google Syntactic N-Grams 的“English All”数据集。该数据集包含从 Google Books 英文语料库中提取的统计句法 ngrams 的信息。它包含 22,230 个不同的动词,和 147,056 个动词短语。对于一个固定的动词,计算动词短语 p 的概率为:

这里 n(p) 时 p 在语料库中的出现的次数,分母部分是对于所有动词短语的次数加和。
IsA 关系 本章使用 Probase 来计算给定概念的情况下实体出现的概率 PT (e|c),同时
也计算给定实体概念出现的概率 PT (c|e):
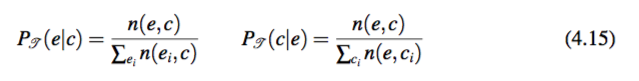
这里 n(e, c) 是 c 和 e 同时出现在 Probase 的频数。
测试数据 实验使用两个数据集来验证方法在长文本和短文本上上的有效性。短文本数据集包含来自于 Twitter [38] 的 160 万个 tweets 数据。长文本数据集包含来自于 Reuters [5] 的 21,578 个新闻文章。
4.2. 动词模板的统计信息
现在简要介绍本文提取的动词模板。对于所有的 22,230 个动词,实验列举最频繁的 100 个动词的统计信息。在过滤掉出现次数 n(p) < 5 的噪声动词短语后,每一个动词平均有 171 个不同的动词短语和 97.2 个不同的动词模板。53% 的动词短语有实体概念化模板。47% 的动词短语有俗语模板。表格 4.2 列举了 5 个有代表性的动词与它们出现最频繁的模板。这个案例分析表明(1)有关动词模板的定义反映了动词的一词多义性;(2)大多数算法得到的动词模板是有意义的。
4.3. 有效性
为了评估动词模板的效果,实验使用了两个评测指标:(1)coverage,表示方法可以找到多少对应于自然语言中的动词短语的模板;(2)precision,表示有多少动词短语和它对应的模板正确匹配。实验通过以下的公式来计算这两个指标:
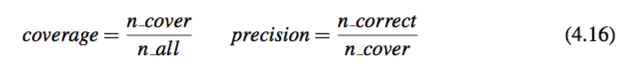
这里 n cover 是在测试数据中找到的对应有模板的动词短语的数量,n all 是动词短语的总数,n correct 是对应的动词模板正确的动词短语的数量。为了评估 precision,实验从测试数据中随机选择了 100 个动词短语并让志愿者去标注被分配模板的正确性。当一个模板太过具体或者太过一般,实验认为它是一个不正确的动词短语-模板匹配(见图 4.1 中的例子)。为了比较算法好坏,实验同样列出了模板总结的两种基准方法的结果。

表 4.2:一些提取的动词模板。在括号中的数字是动词短语在 Google Syntactic N-Gram 数据中出现的频数。 #phrase 表示这个动词的不同动词短语的个数。
Idiomatic Baseline (IB) 每一个动词短语是一个俗语。
Conceptualized Baseline (CB) 对于每一个动词短语,它被分配给一个实体概念化模板。对于宾语 op,基准算法选择最高出现概率的概念,即 argmaxc P(c|op),来构建这个模板。
在 Tweets 和 News 数据集上,动词模板分别覆盖了 64.3% 和 70% 的动词短语。考虑到在 Google N-Gram 数据中的拼写错误以及解析错误,这样的覆盖率是可以接受的。图 4.2 展示了本章方法以及基准方法提取的动词模板(VP)的查准率。结果显示本章方法相比于基准方法在精确度方面有很大的提升。结果同时显示了对于动词的语义理解来说实体概念化模板与俗语模板都是必要的。
第 5 节 应用:基于上下文的实体概念化
如同在引言中所提及的,动词模板可以用来优化基于上下文的实体概念化任务(通过考虑实体的上下文来提取一个实体的概念)。本节将动词模板与主流的基于实体的方法 [87] 相结合来优化这一问题。
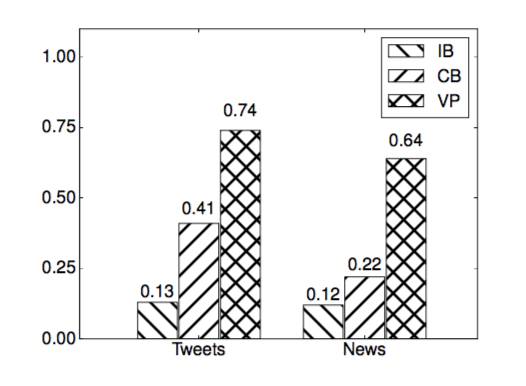
图 4.2: 准确率
基于实体的方法 此方法利用在上下文中出现过的实体来概念化一个实体 e。令 E 是上下文中的所有实体的集合。定义在给定上下文 E 下 c 是实体 e 的概念的概率为 P(c|e,E)。通过假设所有的实体在给定概念下是独立的,可以得到以下公式来计算 P(c|e, E ):
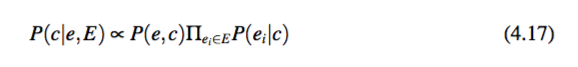
本节的方法 本节在上下文中增加了动词作为附加信息来实体概念化 e。当 e 是一个动词的对象的时候,利用动词模板可以推导出 P(c|v),即在给定动词 v 的动词短语下观察到有关概念 c 的实体概念化模板的概率。因此,在给定上下文 E 和实体 e 还有动词 v 的情况下,概念 c 出现的概率是 P(c|e,v,E)。类似于等式 4.17,P(c|e,v,E) 可以通过以下公式来计算:
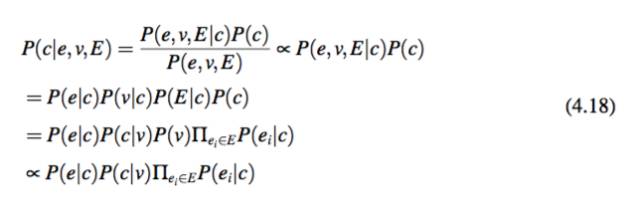
注意到如果 v + e 在 Google Syntactic N-Grams 数据中被观察到,这意味着算法已经学习到了这个模板,可以使用这些模板来进行实体概念化。也就是说,如果 v + e 被映射到了一个实体概念化模板,则使用模板的概念作为实体概念化的结果。如果 v + e 是一个俗语模板,则停止实体概念化。
设置与结果 对于在实验部分使用的两个数据集,本实验同时利用上述两个方法来概念化在动词短语中的宾语。然后,选择概率最大的概念作为对象的概念标签。本实验随机选取了两种方法所对应标签不同的 100 个短语。对于每一个不同,使用人工标注其结果是否好于(better)等于(equal)或差于(worse)不适用动词模板的方法的结果。结果显示在图片 4.3 中。在这两个数据集上,利用了动词模板后,精确度都显著的被提高了。这表明了动词模板对于语义理解任务是有意义的。
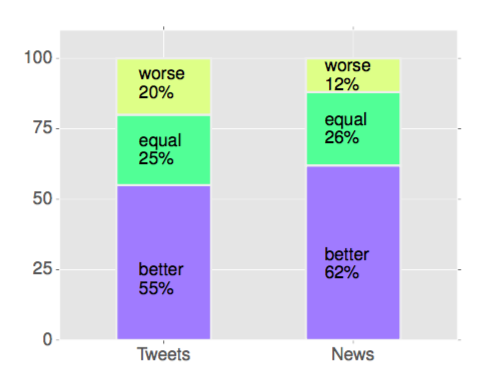
图 4.3:实体概念化结果
第 6 节 小结
动词的语义对于文本理解来说非常的重要。本章提出了动词模板,用来区分动词的不同语义。论文建立了基于最小描述长度的模型,来平衡动词模板的一般性与特殊性。同时本章提出了一个基于模拟退火的算法来获得动词模板。算法使用了模板的典型性来使候选模板产生的过程收敛速度加快。实验验证了模板的高精确度与覆盖率。本章还展示了动词模板在基于上下文的实体概念化中的成功应用。