技术动态 | 人工智能开源软件发展现状连载——知识图谱开源软件
本文转载自公众号:中国人工智能开源软件发展联盟,欢迎大家点击文末二维码关注。
知识图谱 (Knowledge Graph)是一种基于图的数据结构,由节点(Point)和边(Edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”,实体和关系又有其自身的“属性”。实体、关系和属性构成知识图谱的核心三要素。
概述
知识图谱本质上是语义网络(Semantic Network)。目前知识图谱这个概念最早由Google在2012年提出,主要是用来优化现有的搜索引擎。最近,知识图谱慢慢地被泛指各种大规模的知识库。知识图谱的构建属于知识工程的范畴,其发展历程如图1所示。
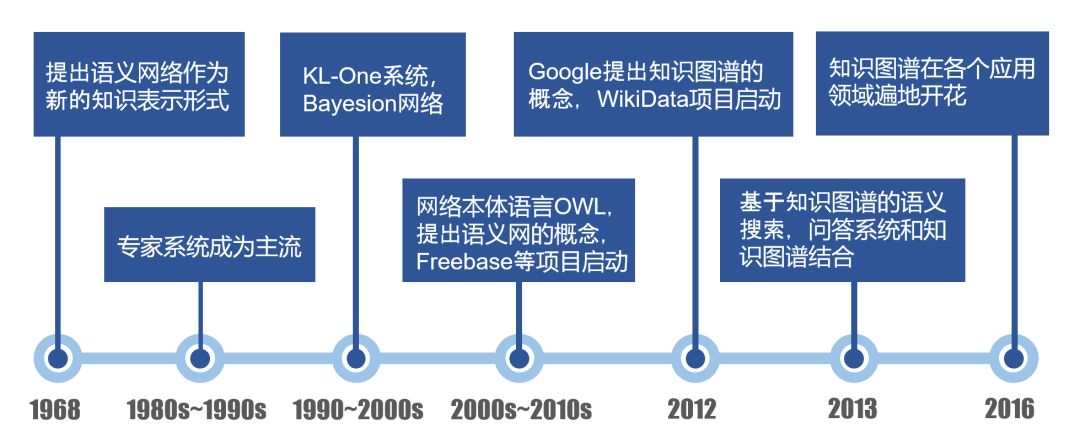
图1知识图谱的发展历程
知识图谱从其知识的覆盖面来看可以分为开放域知识图谱和垂直领域知识图谱,前者主要是百科类和语义搜索引擎类的知识基础,后者在金融、教育、医疗、汽车等垂直领域积累行业内的数据而构成。
知识图谱相关的关键技术包括构建和使用。知识图谱的构建有自顶向下和自底向上两种方法,现在大部分情况会混合使用这两种方法。知识图谱的构建应用了知识工程和自然语言处理的很多技术,包括知识抽取、知识融合、实体链接和知识推理。知识的获取是多源异构的,从非结构化数据中抽取知识是构建时的难点,包括实体、关系、属性及属性值的抽取。对不同来源的数据需要做去重、属性归一及关系补齐的融合操作。同时,根据图谱提供的信息可以推理得到更多隐含的知识,常用知识推理方法有基于逻辑的推理和基于图的推理。知识图谱的使用需要自然语言处理和图搜索算法的支持。
知识图谱在语义搜索、百科知识及自动问答等方面有着很典型的应用。在语义搜索领域,基于知识图谱的语义搜索可以用自然语言的方式查询,通过对查询语句的语义理解,明确用户的真实意图,从知识图谱中获取精准的答案,并通过知识卡片等形式把结果结构化地展示给用户,目前具体应用有Google、百度知心、搜狗知立方等。在百科知识领域,知识图谱构建的知识库与传统的基于自然文本的百科相比,有高度结构化的优势。在自动问答和聊天机器人领域,知识图谱的应用包括开放域、特定领域的自动问答以及基于问答对(FAQ)的自动问答。比如IBM的Watson,Apple的Siri,Google Allo,Amazon Echo,百度度秘以及各种情感聊天机器人、客服机器人、教育机器人等。
Freebase是一个大规模链接数据库,是由硅谷创业公司MetaWeb于2005年启动的基于Creative Commons Attribution协议的语义网项目。Freebase主要采用社区成员协作方式构建,其数据源主要包括Wikipedia、NNDB、Fashion Model Directory、MusicBrainz和社区用户贡献等。Freebase基于RDF三元组模型,共有19亿条三元组,底层采用图数据库进行存储。2010年,Freebase被Google收购作为其知识图谱数据来源之一。2016年,Google宣布将Freebase的数据和API服务都迁移至Wikidata,并正式关闭了Freebase。
WikiData是免费开放、多语言、任何人或机器都可以编辑修改的大规模链接知识库,是由维基百科于2012年启动的基于Creative Commons Attribution协议的项目。WikiData继承了Wikipedia的众包协作构建机制,但与Wikipedia不同,WikiData基于以三元组为基础的知识条目的自由编辑,目前已经有超过4667万条知识条目。
DBPedia是由OpenLink Virtuoso托管和发布的基于GPL协议的开源知识库。DBpedia以互联网挖掘的方式从各种维基媒体项目创建的信息中提取结构化内容,以机器可读的形式存储知识,并提供信息收集、组织、共享、搜索和利用的手段。DBpedia 2014年发布的版本包含30亿条三元组。DBpedia知识库与现有的知识库相比有几个优点:涵盖领域多、代表真实的社区协议、会随着维基百科的变化而自动演变、多语言。DBpedia知识库的用例非常广泛,包括企业知识管理、Web搜索以及维基百科搜索的革命。
YAGO是一种基于链接数据库的开放语义知识库,是由德国马普研究所与巴黎电讯科技大学于2007开始的基于Creative Commons Attribution协议的联合项目。YAGO主要集成了Wikipedia、WordNet和GeoNames三个来源的数据,包含1.2亿条三元组知识,其功能包括作为一个分类单元直接连接到DBpedia云知识库。目前YAGO在SUMO Ontology项目、DBpedia计划、UMBEL Ontology项目以及Freebase等项目中提供相关知识库支持,同时它也是IBM Watson的后端知识库之一。
其他的开放知识图谱有:ConceptGraph、BabelNet、CN-DBPeidia、OpenKG等。
开源构建工具
Protege是基于Java语言开发的本体编辑和知识获取软件,是斯坦福大学医学院生物信息研究中心于1999年发布的基于BSD 2-clause协议的开源软件。Protege提供本体概念类、关系、属性和实例的构建,不基于具体的本体描述语言,因此用户可以在概念层次上构建领域本体模型。
除了Protege,还有Stanford OpenIE、Tuffy、OpenKE、Grakn等应用于知识图谱构建的开源软件。但它们普遍受到的关注度不高,这在一定程度上体现出了知识图谱领域用于构建图谱的开源软件的匮乏。
完整的知识图谱构建还包括知识的存储。知识图谱有两类存储方式,一类是传统的RDF结构存储,RDF 标准的结构化查询语言是SPARQL;另一类是图数据库,它可以弥补传统关系型数据库在存储知识图谱时查询复杂、缓慢的缺陷。目前常用的图数据库软件包括Neo4j、OrientDB、ArangoDB和AllegroGrap等。
知识图谱提供了一种新的数据和知识组织方式,能够让多源异构的数据知识化,基于知识图谱能够建立各种知识服务和智能应用。知识图谱在金融、医疗、农业、法律等很多垂直领域的应用已经得到了迅速地展开,范围越来越广,程度由浅入深。但知识图谱的构建和应用具有很大的技术难度,需要自然语言处理、数据库和语义推理等多重技术的支持。
连载预告
人工智能开源软件发展现状连载预告:
第八集:知识图谱开源软件
第九集:虚拟现实与增强现实开源软件
第十集:游戏智能与信息安全开源软件
第十一集:人工智能开源软件特性分析
第十二集:基于开源软件的人工智能技术典型解决方案

《中国人工智能开源软件发展白皮书(2018)》
为推动人工智能开源软件产业发展,工业和信息化部信息化和软件服务业司指导中国电子技术标准化研究院,联合上海计算机软件技术开发中心、北京大学、中国科学院、北京京东尚科信息技术有限公司、深圳前海微众银行股份有限公司、蚂蚁小微金融服务集团、北京百度网讯科技有限公司、东软集团股份有限公司、顺丰科技有限公司等企事业单位,编撰形成了《中国人工智能开源软件发展白皮书(2018)》。白皮书现已公开发布,点击左下方阅读全文免费获取下载链接。

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。