微信看一看基于多粒度多状态网络如何预测物品分享率?丨ECML-PKDD-2021

导语
物品分享率预测任务(Item-level share rate prediction (ISRP))旨在基于物品(item,比如视频、文章等)的元信息及其历史分享率序列,预测物品在未来的分享率。一个高质量的物品分享率预测系统,能够帮助我们在百万级候选物品中快速筛选出用户喜欢的、具有潜在爆点的物品。它被广泛地部署在真实推荐系统中,作为粗排/精排模块的前序模块。
然而,物品分享率预测任务面临着以下两项挑战:(1)分享率使用曝光次数作为分母。如果一段时间内物品的曝光次数比较少(经常出现在冷启动/warm up阶段的物品身上),其历史分享率序列会具有较大的波动和不确定性。这种不确定性严重影响了模型对于历史分享率序列建模的有效性和鲁棒性。(2)物品的分享率数据在其不同生命周期处于不同的状态(mode),例如通常状态(normal mode),冷启动状态(cold-start mode),噪声状态(noisy mode)。模型需要有同时建模多种状态下的物品分享率的能力。在这个工作中,我们提出了一个多粒度多状态网络(multi-granularity multi-mode network (MMNet)),解决物品分享率预测的问题。
MMNet使用一个粗粒度和一个细粒度序列模块建模物品的历史分享率序列,同时使用一个元信息模块建模物品的多模态基础属性信息,综合进行分享率预测。在细粒度模块,我们提出了一个多状态建模策略,结合两种扰动块进行多状态的数据平衡和增强,使得模型对于不同状态的分享率序列都有不错的建模能力。
在粗粒度模块,我们基于物品的粗粒度属性进行泛化和数据扩充,缓解曝光不足物品的分享率扰动问题。元信息模块则综合考虑物品多模态的基础属性、文本、图像等元信息,为分享率预估提供辅助。我们在微信看一看系统上进行了离线和线上实验,MMNet获得了最优的结果。目前,MMNet已经部署于微信看一看系统。

模型背景与简介
真实世界的大规模推荐系统往往需要从成百上千万的物品候选中选择合适的物品进行推荐,而系统不可能为所有物品提供足够的曝光机会来收集真实的用户反馈。绝大多数大规模推荐系统都会有简单或复杂的“物品质量检测”模块,用以高效地筛选出用户可能感兴趣的高质量物品。
传统的物品质量检测模块往往会基于物品的元信息(例如公众号来源、标题、内容等信息)给予物品一个静态的质量分,而物品的历史分享率序列也提供了重要的信息,能够反映用户的真实偏好。在这个工作中,我们提出一个物品分享率预测任务(Item-level share rate prediction (ISRP)),旨在基于物品的元信息和历史分享率序列,预测物品在未来的分享率。
物品分享率预测模块作为一个动态的物品质检员,能够在物品的不同生命周期给予尽可能准确的分享率预测。需要注意的是,物品分享率预测任务和流行度预估任务(popularity prediction)比较相似,后者旨在基于元信息或社交传播,预测一个物品(在社交网络中)的最终影响力。而在物品分享率预测任务中,对于物品的历史分享率序列的建模是其重中之重。
物品分享率预测任务主要面临着以下两项挑战:(1)如何缓解物品相关的不确定性。这种不确定性体现在两个方面,包括分享率不确定性和元信息不确定性。分享率不确定性经常出现在物品曝光量不足(例如物品生命周期初期)的阶段,这时物品的曝光量往往波动比较大。这种分享率不确定性对模型的序列建模提出了很高的要求。另外,元信息不确定性也是真实推荐系统的一大难题——物品的某些属性经常会有噪声或者缺失的情况,给预测带来扰动。所以,我们希望模型能够克服不确定性变得更加鲁棒。(2)如何在物品分享率的不同状态下,结合序列和元信息进行建模。我们将物品分享率的状态简单分为三种:通常状态(normal mode),冷启动状态(cold-start mode),噪声状态(noisy mode)。
其中,通常状态表明当前的分享率比较稳定、可靠(一般意味着曝光量足够)。冷启动状态表明当前没有历史分享率信息。噪声状态则代表当前分享率波动较大(曝光量少甚至一段时期没有曝光),分享率不太可靠。通常状态时,模型更加依赖历史分享率序列;而在冷启动状态和噪声状态时,模型会更加依赖元信息,而此时的序列模型则变得难以学习。我们需要设计合理的训练机制,使得模型能够同时处理三种状态下的分享率预测任务。
为了解决这两项挑战,我们提出了一个多粒度多状态网络(multi-granularity multi-mode network (MMNet))。MMNet使用一个粗粒度和一个细粒度序列模块建模物品的历史分享率序列,同时使用一个元信息模块建模物品的多模态元信息,综合这些模块的信息,从而能够在不同状态下进行较准确的分享率预测。(1)在细粒度模块,我们提出了一个多状态建模策略,结合两种扰动块进行多状态的数据平衡和增强,使得模型对于不同状态的分享率序列都有不错的建模能力。两种扰动块具有不同的mask策略,能够增强冷启动和噪声状态下的序列模型的学习。(2)在粗粒度模块,我们基于物品的粗粒度属性(例如tag/category),构建了粗粒度属性的分享率序列。泛化后的粗粒度属性相关的曝光量得到了保证,从而缓解了冷启动/噪声状态下曝光不足物品的分享率扰动问题。(3)元信息模块综合考虑物品多模态的基础属性、文本、图像等元信息,为分享率预测(特别是冷启动状态下)提供辅助。我们在微信看一看系统上进行了离线和线上实验,MMNet获得了最优的结果。目前,MMNet已经部署于微信看一看系统。我们工作的贡献主要如下:
1、我们系统性地总结了物品分享率预测任务这个任务的挑战,并且提出了一套MMNet框架以解决这个问题;
2、我们设计了一套多粒度的分享率序列建模方法,兼顾物品级和taxonomy级的分享率趋势,能够缓解冷启动和噪声状态下的不确定性问题;
3、我们提出了一套多状态建模策略,通过两种不同的扰动块进行冷启动和噪声状态下的数据增强,使得我们能学到更加鲁棒的模型;
4、我们在看一看线上/离线实验中取得了最好的结果,并且成功部署于线上系统,影响千万用户。
具体模型
▍2.1 模型定义
首先,我们先给出物品分享率三种状态:通常状态(normal mode),冷启动状态(cold-start mode),噪声状态(noisy mode)的准确定义如下:

然后,我们也给出模型的三类输入特征,分别对应着MMNet的粗粒度序列模块、细粒度序列模块和元信息模块。这三个模块共同合作,能够在不同状态下给出物品不同角度的特征信息。

▍2.2 模型整体结构
如图1,MMNet主要分为粗粒度序列模块、细粒度序列模块和元信息模块三个模块。其中,细粒度序列模块建模物品的分享率序列,有两种干扰块辅助模型在冷启动状态和噪声状态下的数据增强。粗粒度序列模块建模物品所属的tag/category的分享率序列,能够获取一些全局的粗粒度的分享率信息。而元信息模块则通过xDeepFM,BERT,ResNet50等不同模型,对元特征、文本和图像等多模态信息进行建模。最终,三个模块获取的物品信息会通过gating-based fusion聚合在一起,进行最终的分享率预估。
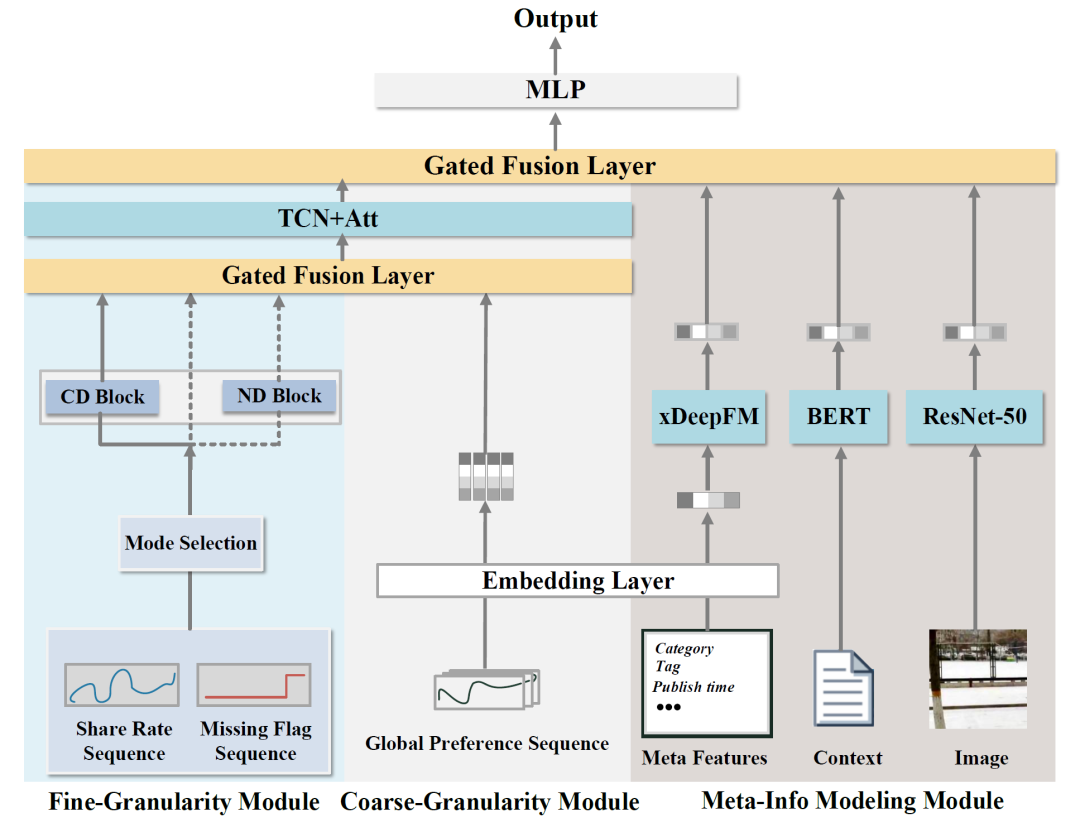
图1:MMNet模型的整体架构
▍2.3 细粒度序列模块
细粒度序列模块针对物品自身的分享率序列进行建模。我们选择一个时间段内的物品平均分享率作为这段时间的分享率,从而为每个物品构建出一个历史分享率序列。这个分享率序列贯穿物品的不同生命周期,其中不同分享率可能属于通常状态、冷启动状态或者噪声状态。站在全局的角度,通常状态的物品远多于冷启动状态和噪声状态,但是冷启动状态和噪声状态又几乎是所有物品的必经之路。模型需要对冷启动状态和噪声状态有足够好的建模能力,这样才能给予真正优质的物品高曝光的机会。
为了加强细粒度模型在冷启动状态和噪声状态的训练,我们在训练时引入了两个扰动块:冷启动扰动块(cold-start disturbance block)和噪声扰动块(noisy disturbance block)。他们通过对原历史分享率序列进行一定策略的mask操作,模拟冷启动和噪声状态下的序列状态。最后,我们得到如下隐状态序列:
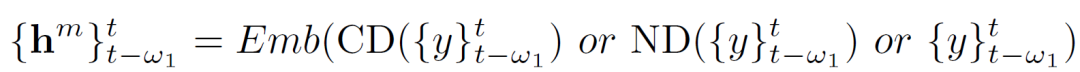
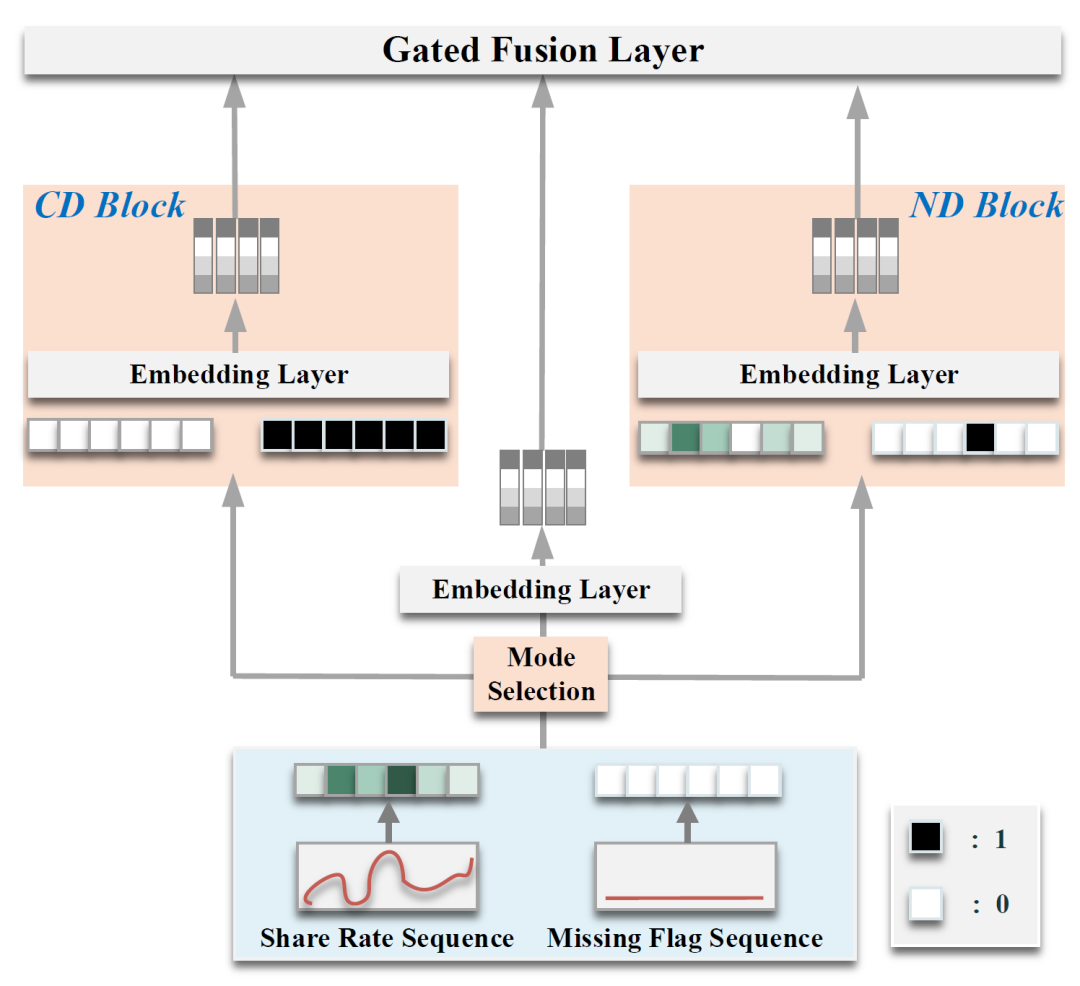
图2:细粒度序列模型和两种扰动块
▍2.3 粗粒度序列模块及序列模块融合
为了缓解物品分享率在冷启动和噪声状态下的不确定性,我们引入了粗粒度分享率序列。直观地,不同推荐系统在不同时期下,用户对于不同主题(topic,tag,category等)的内容有着不同的关注度和分享意愿。例如在世界杯期间,足球、比赛球队、进球球员对应的taxonomy的分享率会有显著的提高。因此,我们基于物品对应的粗粒度taxonomy在一个时间段的平均分享率,构建了物品的粗粒度分享率序列:
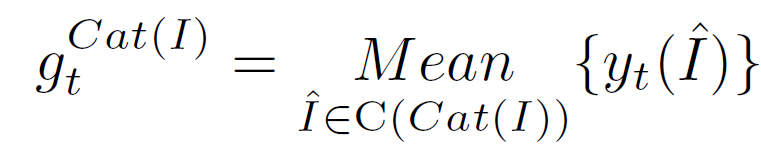
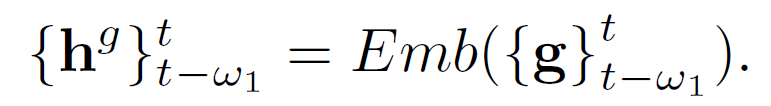
随后,我们使用attention综合考虑细粒度和粗粒度的分享率序列特征,然后使用temporal convolutional network (TCN)进行序列建模,增强时间因素,如下:
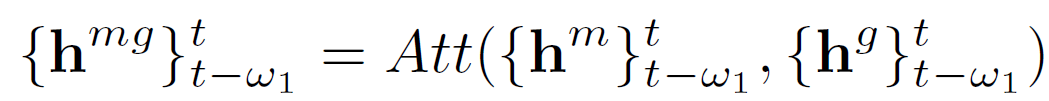

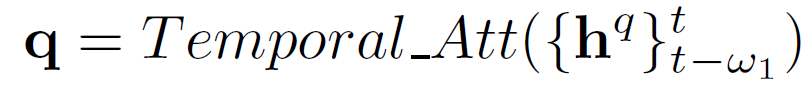
q为物品基于其历史分享率序列学到的特征表示。
▍2.4 元信息模块
我们使用了物品的元信息、文本信息和图像信息作为序列信息的辅助。这些信息在物品的冷启动/噪声阶段起到了重要的作用。

▍2.5 训练目标和线上部署
最后,我们基于gating融合全部的信息,然后使用MSE loss进行训练:
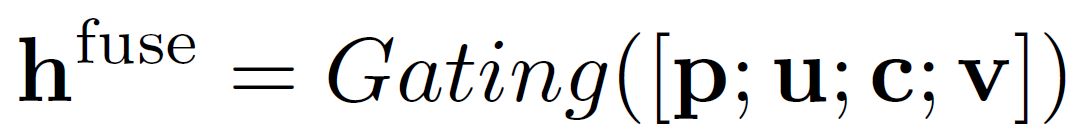
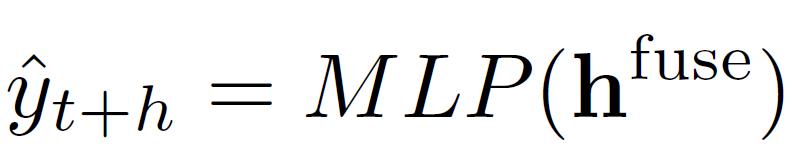
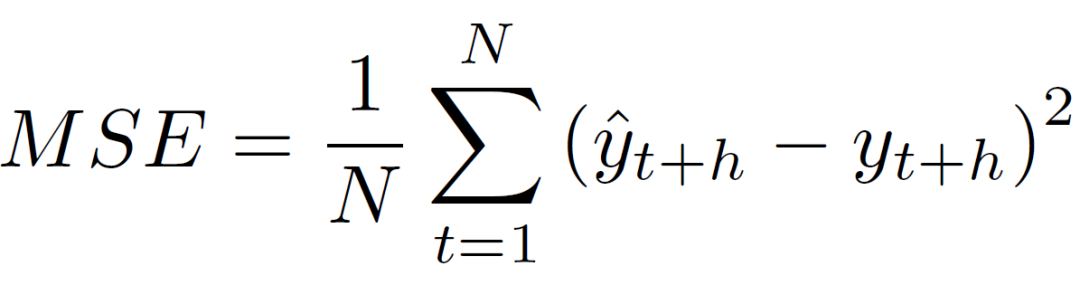
我们的模型不仅用于分享率,也能用于点击率、视频完成率等的预估工作。模型的结果及其中间特征也用于召回和排序等多个阶段,起到了显著的效果。
实验结果
我们在微信看一看数据上构造了三种状态的数据集进行了离线测试,结果显式MMNet在所有状态的所有指标上都获得了显著的提升。
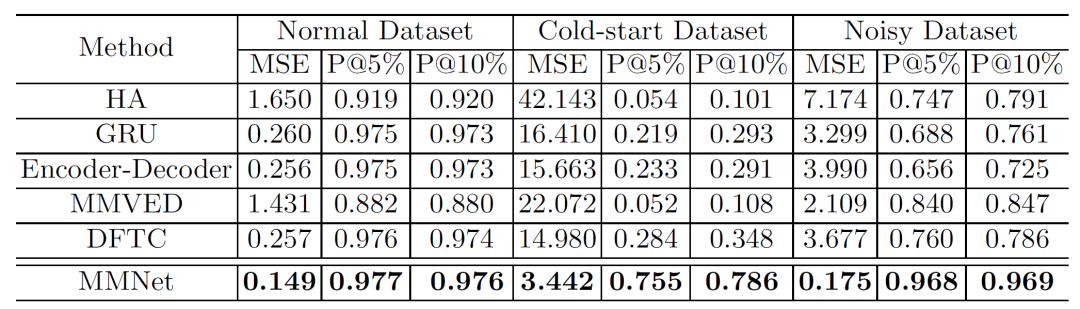
图3:离线实验结果
线上结果也验证了模型在真实系统中的有效性:

图4:线上实验结果
图5给出的消融实验也验证了我们模型各个模块的有效性。需要注意的是,MMNet_norm/cold版本去掉了噪声扰动块,使得模型的数据增强更关注冷启动状态,因此也自然在冷启动状态上有更好的表现。
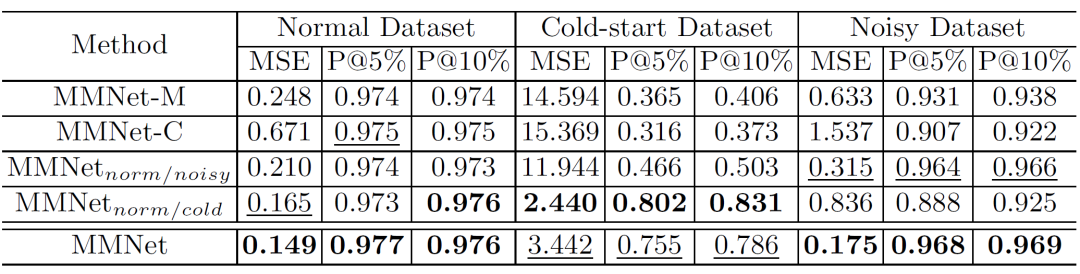
图5:消融实验结果
总结
我们在这篇工作中针对物品分享率预估任务,提出了一个MMNet框架,综合考虑物品的细粒度分享率序列、粗粒度分享率序列和元信息,能够同时处理不同状态下的物品分享率预估。模型在真实世界的推荐系统中有着重要的作用,并已部署于微信看一看系统。
未来我们会探索类似MMoE的多专家的思路,让不同专家专注不同状态下的预测任务,结合准确的状态预估模型和状态先验知识,获得更好的效果。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。




