EdgeBERT:极限压缩,比ALBERT再轻13倍!树莓派上跑BERT的日子要来了?
机器之心转载
来源:夕小瑶的卖萌屋
作者:Sheryc_王苏
这个世界上有两种极具难度的工程:第一种是把很平常的东西做到最大,例如把语言模型扩大成能够写诗写文写代码的 GPT-3;而另一种恰恰相反,是把很平常的东西做到最小。对于 NLPer 来说,这种 “小工程” 最迫在眉睫的施展对象非 BERT 莫属。

论文题目:EdgeBERT: Optimizing On-Chip Inference for Multi-Task NLP
论文链接:https://arxiv.org/pdf/2011.14203.pdf
出处:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations(ICLR'20)
链接:https://arxiv.org/pdf/1909.11942.pdf
嵌入层分解:BERT 中,WordPiece 的嵌入维度和网络中隐藏层维度一致。作者提出,嵌入层编码的是上下文无关信息,而隐藏层则在此基础上增加了上下文信息,所以理应具有更高的维数;同时,若嵌入层和隐藏层维度一致,则在增大隐藏层维数时会同时大幅增加嵌入层参数量。ALBERT 因此将嵌入层进行矩阵分解,引入一个额外的嵌入层 E。设 WordPiece 词汇表规模为V,嵌入层维度为 E,隐藏层维度为 H,则嵌入层参数量可由 O(V x H)降低为O(V x E + E x H)。
参数共享:BERT 中,每个 Transformer 层参数均不同。作者提出将 Transformer 层的所有参数进行层间共享,从而将参数量压缩为仅有一层 Transformer 的量级。
上下句预测任务→句序预测任务:BERT 中,除语言模型的 MLM 任务外还进行了上下句预测任务,判断句 2 是否为句 1 的下一句,然而该任务被 RoBERTa 和 XLNET 等模型证实效果一般。作者提出将其替换为句序预测任务,判断句 2 和句 1 之间的句子顺序来学习文本一致性。
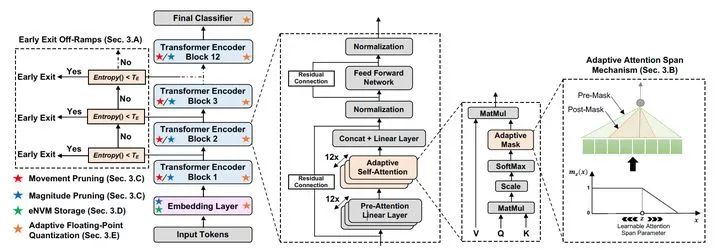
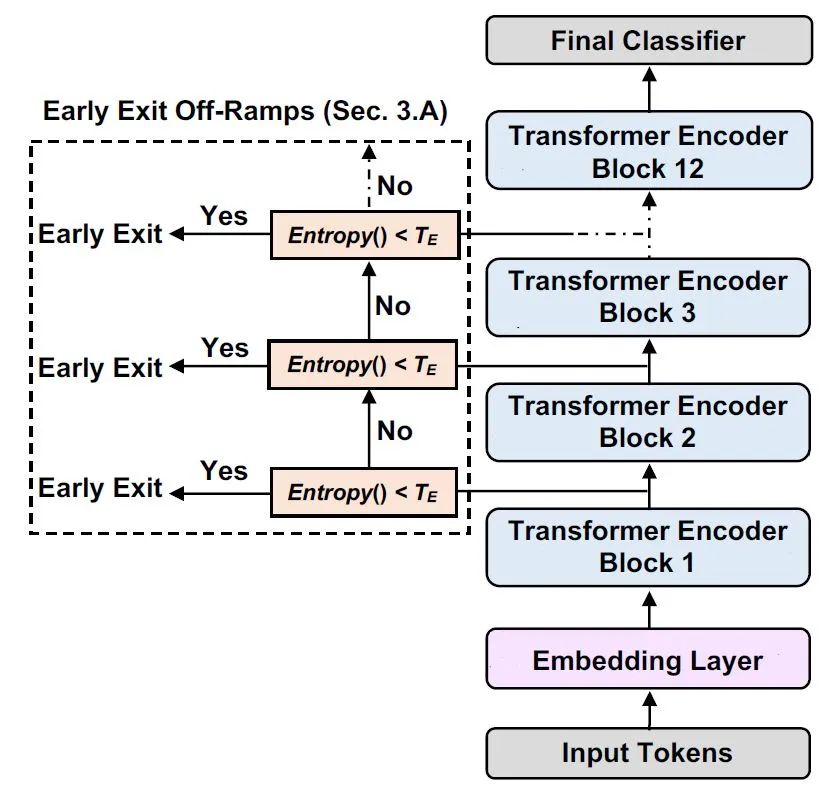
出处:DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference(ACL'20)
链接:https://arxiv.org/pdf/2004.12993.pdf
出处:Adaptive Attention Span in Transformers(ACL'19)
链接:https://arxiv.org/pdf/1905.07799.pdf
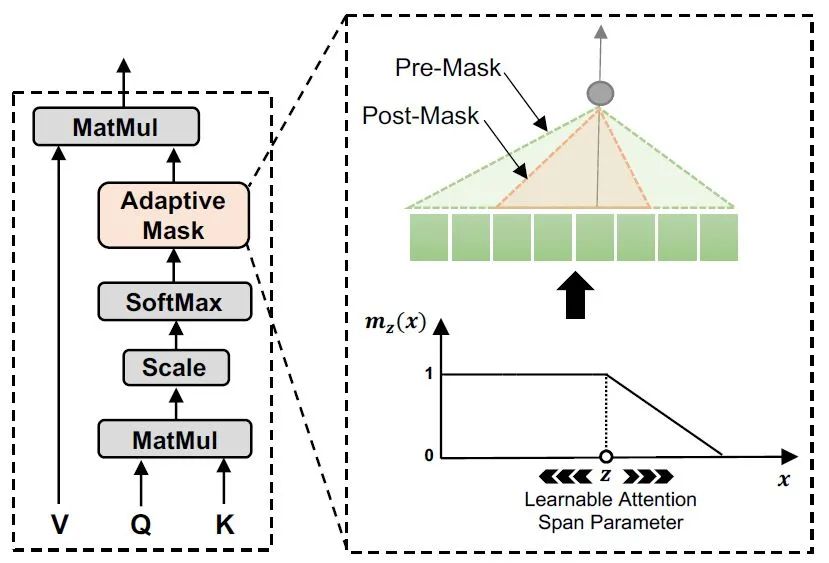
 基于两个 token 之间的距离为注意力机制的权重计算添加了 soft masking。注意力机制中的权重
基于两个 token 之间的距离为注意力机制的权重计算添加了 soft masking。注意力机制中的权重 变为:
变为:

 为控制 soft 程度的超参数,
为控制 soft 程度的超参数, 为序列截止到 token
为序列截止到 token  的长度(原文采用了 Transformer Decoder 结构学习语言模型,故每个 token 只能于自己之前的 token 计算注意力。在 EdgeBERT 中没有提及公式,不过根据模型图的结构来看,分母应修改为对整个序列求和)。mask 函数中的
的长度(原文采用了 Transformer Decoder 结构学习语言模型,故每个 token 只能于自己之前的 token 计算注意力。在 EdgeBERT 中没有提及公式,不过根据模型图的结构来看,分母应修改为对整个序列求和)。mask 函数中的  为 mask 的边界,此边界值会跟随注意力的 head 相关参数和当前输入序列变化:对于注意力机制中的每一个 head
为 mask 的边界,此边界值会跟随注意力的 head 相关参数和当前输入序列变化:对于注意力机制中的每一个 head  ,有
,有 ,其中
,其中 、
、 可训练,
可训练, 为 sigmoid 函数。
连算都不用算了,直接给每一个 head 赋一个可学习的
为 sigmoid 函数。
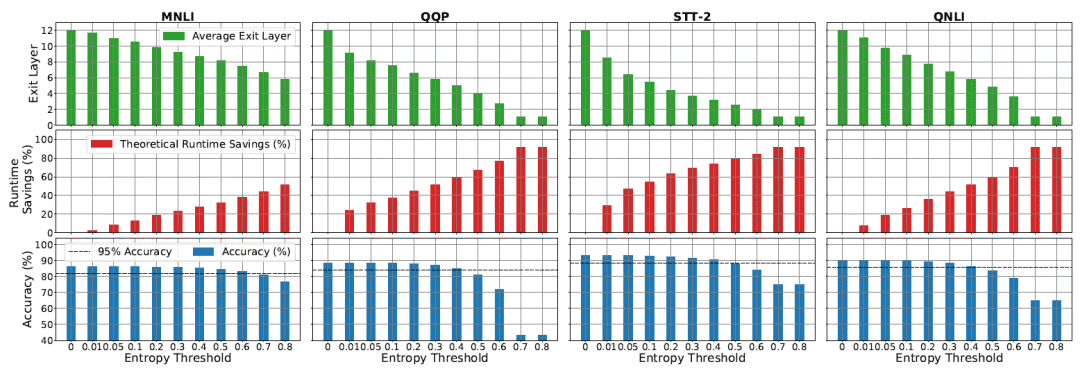
连算都不用算了,直接给每一个 head 赋一个可学习的 ,连输入序列都不考虑了,多出来的参数只有 12 个(因为有 12 个 head)。那么,这样做的结果如何呢?作者将所有序列都 pad/trunc 到 128 长度,经过实验,得到了一个惊人的结果:
,连输入序列都不考虑了,多出来的参数只有 12 个(因为有 12 个 head)。那么,这样做的结果如何呢?作者将所有序列都 pad/trunc 到 128 长度,经过实验,得到了一个惊人的结果:
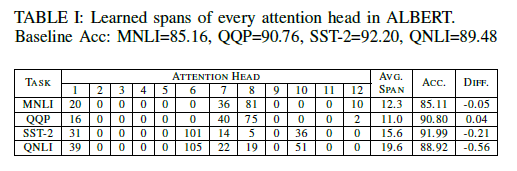 值,和模型在 MNLI/QQP/SST-2/QNLI 四个任务上的准确度。在一大半 head 几乎完全被 mask 掉(
值,和模型在 MNLI/QQP/SST-2/QNLI 四个任务上的准确度。在一大半 head 几乎完全被 mask 掉( )之后,模型居然只在这几个任务上掉了 0.5 甚至 0.05 的准确度!而这一方法也为模型带来了最高
)之后,模型居然只在这几个任务上掉了 0.5 甚至 0.05 的准确度!而这一方法也为模型带来了最高 的计算量降低。
的计算量降低。
出处:Movement Pruning: Adaptive Sparsity by Fine-Tuning(NeurIPS'20)
链接:https://arxiv.org/pdf/2005.07683.pdf
 ,为其赋予同样 size 的重要性分数
,为其赋予同样 size 的重要性分数 ,则剪枝 mask
,则剪枝 mask  。
。
 。
。

 省略近似得到损失函数
省略近似得到损失函数 对重要性分数的梯度:
对重要性分数的梯度:



 时,重要性
时,重要性 增大,此时
增大,此时 与
与 异号。这表示,只有当在反向传播时为正的参数变得更大或为负的参数变得更小时才会得到更大的重要性分数,避免被剪枝。
异号。这表示,只有当在反向传播时为正的参数变得更大或为负的参数变得更小时才会得到更大的重要性分数,避免被剪枝。
出处:Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding(ICLR'16)
链接:https://arxiv.org/pdf/1510.00149.pdf

出处:AdaptivFloat: A Floating-point based Data Type for Resilient Deep Learning Inference(arXiv Preprint)
链接:https://arxiv.org/pdf/1909.13271.pdf

 。
。
 。
。
 的选取能够使得
的选取能够使得 在数轴两侧分布几乎均等(例如在 32 位浮点数 FP32 中,指数范围为至),但这样的数作为机器学习模型的参数显然有些不太合适:为了增加小数的精度,我们甚至要允许
在数轴两侧分布几乎均等(例如在 32 位浮点数 FP32 中,指数范围为至),但这样的数作为机器学习模型的参数显然有些不太合适:为了增加小数的精度,我们甚至要允许 这样显然不会出现的数也能表示,这真的不是在浪费内存?
。所谓动态体现在每个 Tensor 都能得到量身定做的。方法也很简单,找到 Tensor 里最大的一个数,让它能被指数范围恰好覆盖到就好。不过说来简单,为了实现这一方法需要配套地对现有浮点数表示方法进行许多其他修改,感兴趣的话可以去看看 AdaptivFloat 原文,此外 IEEE 754 标准 [5] 同样也可以作为参考哦~
这样显然不会出现的数也能表示,这真的不是在浪费内存?
。所谓动态体现在每个 Tensor 都能得到量身定做的。方法也很简单,找到 Tensor 里最大的一个数,让它能被指数范围恰好覆盖到就好。不过说来简单,为了实现这一方法需要配套地对现有浮点数表示方法进行许多其他修改,感兴趣的话可以去看看 AdaptivFloat 原文,此外 IEEE 754 标准 [5] 同样也可以作为参考哦~
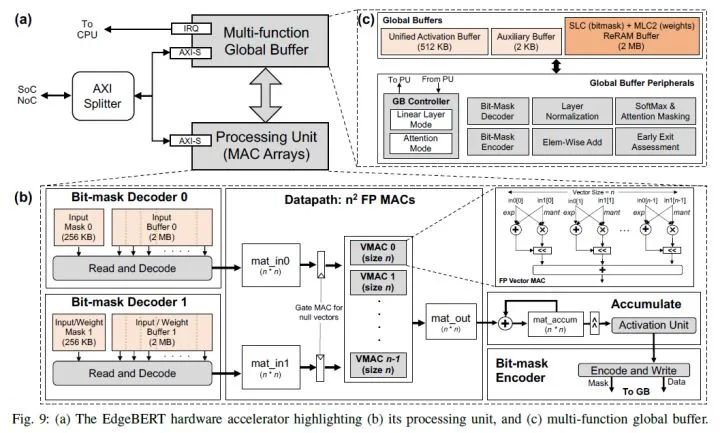
嵌入层:保存了 Embedding 向量。EdgeBERT 在进行下游任务 fine-tune 时一般不对嵌入层进行修改。这类参数相当于只读参数,只对快速读取有较高要求,同时希望能够在掉电时依然保持原有数据来降低数据读写开销,因此适用耗能低、读取速度快的 eNVM(Embedded Non-Volatile Memory,嵌入式非挥发性记忆体)。本文选取的是基于 MLC 的 ReRAM,一种低功耗、高速度的 RAM。
其他参数:这些参数需要在 fine-tune 时进行改变。此处使用的是 SRAM(与计算机内存的 DRAM 不同,SRAM 更贵但功耗更低、带宽更高,常被用于制造 cache 或寄存器)
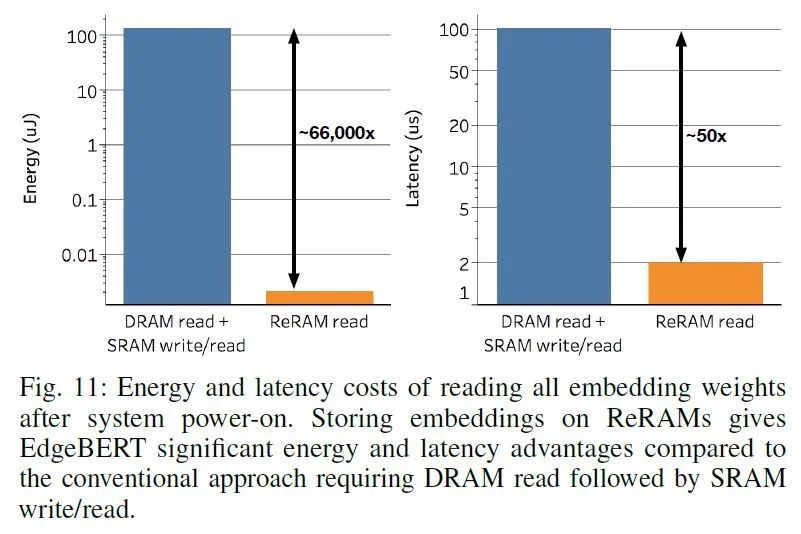
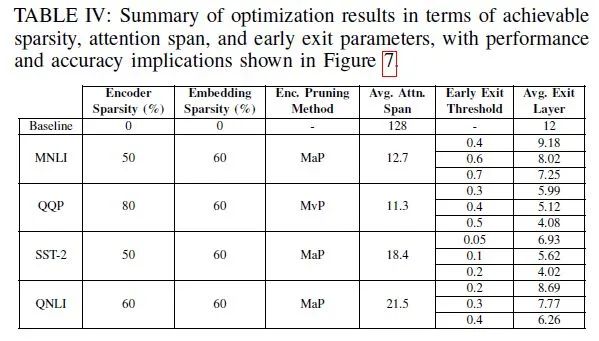
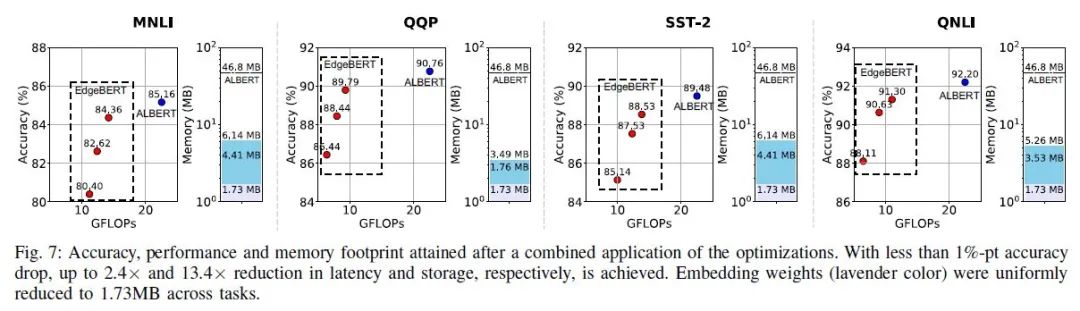
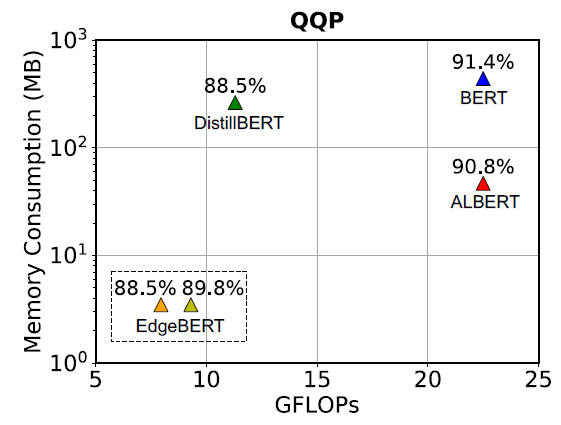
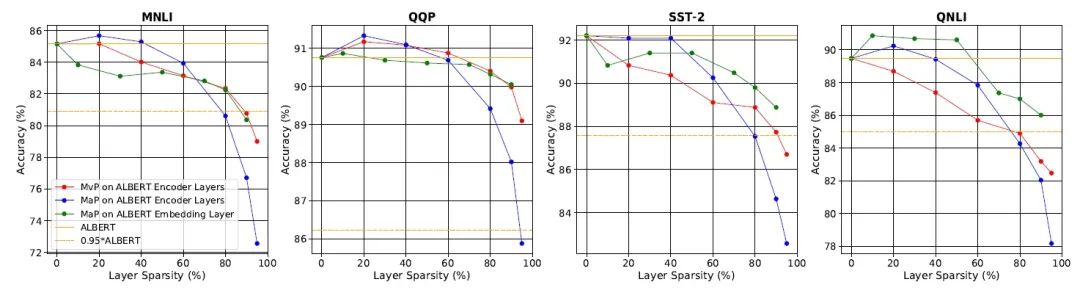
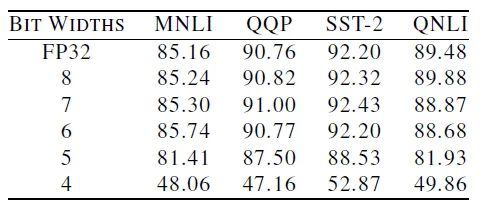
在性能(准确度)相比 ALBERT 下降 1 个百分点时,EdgeBERT 能取得的内存降低和的推理速度;下降 5 个百分点时甚至能取得的推理速度。
Embedding 经过裁剪后仅保留了 40%,使得存储进 eNVM 的嵌入层参数仅 1.73MB。
QQP 的 Transformer 参数被 mask 掉 80%,MNLI、SST-2、QNLI 的 Transformer 参数被 mask 掉 60% 后,性能可以仅下降 1 个百分点。


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



