背景
当前,大部分中文预训练模型都是以字为基本单位的,也就是说中文语句会被拆分为一个个字。中文也有一些多粒度的语言模型,比如创新工场的ZEN和字节跳动的AMBERT,但这类模型的基本单位还是字,只不过想办法融合了词信息。目前以词为单位的中文预训练模型很少,据笔者所了解到就只有腾讯UER开源了一个以词为颗粒度的BERT模型,但实测效果并不好。
那么,纯粹以词为单位的中文预训练模型效果究竟如何呢?有没有它的存在价值呢?
最近,我们预训练并开源了以词为单位的中文BERT模型,称之为WoBERT(Word-based BERT,我
的BERT!)。
实验显示,基于词的WoBERT在不少任务上有它独特的优势,比如速度明显的提升,同时效果基本不降甚至也有提升。在此对我们的工作做一个总结。
开源地址:
https://github.com/ZhuiyiTechnology/WoBERT
字还是词?
究竟是“字”好还是“词”好?这是中文NLP一个很让人抓狂的问题,也有一些工作去系统地研究这个问题。比较新的是香侬科技在ACL2019上发表的《Is Word Segmentation Necessary for Deep Learning of Chinese Representations?》,里边得到了字几乎总是优于词的结论。前面也说了,现在中文预训练模型确实也基本上都是以字为单位的。所以,看上去这个问题已经解决了?就是字更好?
事情远没有这么简单。就拿香侬科技的这篇论文来说,它的实验结果是没有错,但却是没有代表性的。为什么这样说呢?因为在该文的实验设置下,模型的embedding层皆从随机初始化状态开始训练。这样一来,对于同样的任务,
以词为单位的模型Embedding层参数更多,自然就更容易过拟合,
效果容易变差,这不用做实验都能猜个大概。问题是,我们用基于词的模型的时候,通常并不是随机初始化的,往往都是用预训练好的词向量的(下游任务看情况选择是否微调词向量),这才是分词的NLP模型的典型场景,但论文里边却没有比较这个场景,所以论文的结果并没有什么说服力。
事实上,
“过拟合”现象具有两面性,
我们要防止过拟合,但过拟合也正好说明了模型拥有比较强的拟合能力,而如果我们想办法抑制过拟合,
那么就能够在同样复杂度下得到更强的模型,
或者在同样效果下得到更低复杂度的模型。
而缓解过拟合问题的一个重要手段就是更充分的预训练
,所以不引入预训练的比较对以词为单位的模型来说是不公平的,
而我们的WoBERT正是证实了以词为单位的预训练模型的可取性
。
-
-
-
-
-
在文本生成任务上,
能缓解Exposure Bias问题
;
-
对于词的好处,大家可能会有些疑惑。比如第2点,词能缓解Exposure Bias,这是因为理论上来说,序列越短Exposure Bias问题就越不明显(词模型单步预测出一个n字词,相当于字的模型预测了n步,这n步都递归依赖,所以字的模型Exposure Bias问题更严重)。至于第3点,虽然有多义词的存在,但是多数词的含义还是比较确定的,至少比字义更加明确,这样一来可能只需要一个Embedding层就能把词义建模好,而不是像字模型那样,要通用多层模型才能把字组合成词。
看起来不相伯仲,但事实上以字为单位的好处,并非就是以词为单位的缺点了。只要多一些技巧,
以词为单位也能一定程度上避免这几个问题
。比如:
-
以词为单位的参数确实增多了,但是可以
通过预训练来缓解过拟合
,所以这个问题不会很严重;
-
依赖分词算法是个问题,如果我们
只保留最常见的一部分词
,那么不管哪个分词工具分出来的结果都是差不多的,差异性不大;
-
至于边界切分错误,这个难以避免,
但是需要准确的边界的,只是序列标注类任务而已
,文本分类、文本生成其实都不需要准确的边界,因此不能就此否定词模型;
-
如果
我们把大部分字也加入到词表中
,也不会出现未登录词。
所以,其实用词的好处是相当多的,除了需要非常精确边界的序列标注类型的任务外,多数NLP任务以词为单位都不会有什么问题。因此,我们就去做了以词为单位的BERT模型了。
往BERT里边加入中文词,首先得让Tokenizer能分出词来。只需要把词加入到字典vocab.txt里边就行了吗?并不是。BERT自带的Tokenizer会强行把中文字符用空格隔开,因此就算你把词加入到字典中,也不会分出中文词来。此外,BERT做英文word piece的分词的时候,使用的是最大匹配法,这对中文分词来说精度也不够。
为了分出词来,我们修改了一下BERT的Tokenizer,
加入了一个“前分词(pre_tokenize)”操作
。这样我们就可以分出中文词来,具体操作如下:
2. 输入一个句子s,用pre_tokenize先分一次词,得到
![]() ;
3. 遍历各个
;
3. 遍历各个
![]() ,
如果
,
如果
![]() 在词
表中则
保留,否则将
在词
表中则
保留,否则将
![]() 用BERT自带的tokenize函数再分一次;
4. 将每个
用BERT自带的tokenize函数再分一次;
4. 将每个
![]() 的
tokenize结果有序拼接起来,作为最后的tokenize结果;
的
tokenize结果有序拼接起来,作为最后的tokenize结果;
在bert4keras>=0.8.8版本中,实现上述改动只需要在构建Tokenizer的时候传入一行参数,例如:
![]()
其中pre_tokenize为外部传入的分词函数,如果不传入则默认为None。简单起见,WoBERT使用了结巴分词,删除了BERT自带词表的冗余部分(比如带##的中文词),然后加入了20000个额外的中文词(结巴分词自带的词表词频最高的两万个),最终WoBERT的vocab.txt规模是33586。
目前开源的WoBERT是Base版本,在哈工大开源的RoBERTa-wwm-ext基础上进行继续预训练,预训练任务为MLM。初始化阶段,将每个词用BERT自带的Tokenizer切分为字,然后用字embedding的平均作为词embedding的初始化。
到这里,WoBERT的技术要点基本上都说清楚了,剩下的就是开始训练了。我们用单张24G的RTX训练了100万步(大概训练了10天),序列长度为512,学习率为5e-6,batch_size为16,累积梯度16步,相当于batch_size=256训练了6万步左右。训练语料大概是30多G的通用型语料。训练代码已经在文章开头的链接中开源了。
此外,我们还提供了WoNEZHA,这是基于华为开源的NEZHA进行再预训练的,训练细节跟WoBERT基本一样。NEZHA的模型结构跟BERT相似,不同的是它使用了相对位置编码,而BERT用的是绝对位置编码,因此理论上NEZHA能处理的文本长度是无上限的。这里提供以词为单位的WoNEZHA,就是让大家多一个选择。
最后,说一下WoBERT的效果。简单来说,在我们的评测里边,WoBERT相比于BERT,在不需要精确边界的NLP任务上基本都没有变差的,有些还会有一定的提升,而速度上则有明显提升,所以一句话就是“提速不掉点”。
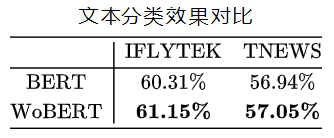
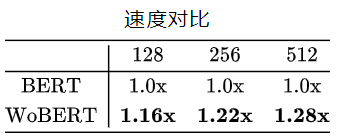
![]() 我们内部还测了不少任务,结果都是类似的,表明这些NLU任务上WoBERT和BERT基本上都差不多的。但是速度上,WoBERT就比BERT有明显优势了,下表是两个模型在处理不同字数的文本时的速度比较:
我们内部还测了不少任务,结果都是类似的,表明这些NLU任务上WoBERT和BERT基本上都差不多的。但是速度上,WoBERT就比BERT有明显优势了,下表是两个模型在处理不同字数的文本时的速度比较:
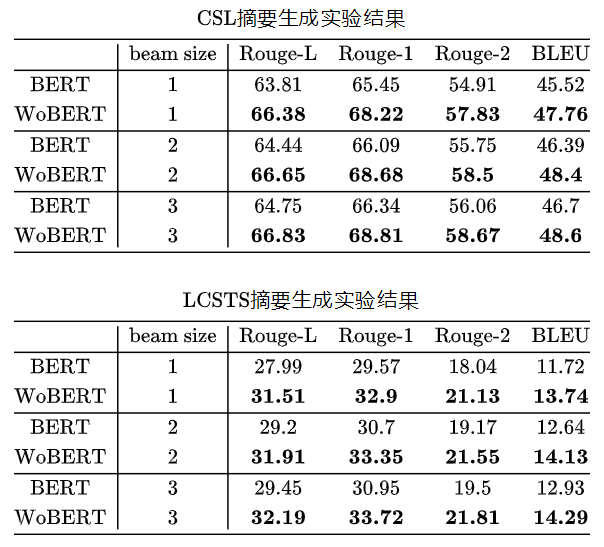
![]() 我们还测了WoBERT+UniLM的方式Seq2Seq任务(CSL/LCSTS标题生成),结果是比以字为单位的模型有明显提升:
我们还测了WoBERT+UniLM的方式Seq2Seq任务(CSL/LCSTS标题生成),结果是比以字为单位的模型有明显提升:
![]() 这说明以词为单位来做文本生成其实是更有优势的。要是生成更长的文本,这个优势还能进一步放大。
当然,我们也不否认,用WoBERT去做NER等序列标注任务时,可能会有明显的掉点,比如做人民日报的NER,掉了3%左右,可能让人意外的是,经过bad case分析,我们发现掉点的原因并不是因为切分错误,而是因为稀疏性(平均来说每个词的样本更少,所以训练得没那么充分)。
不管怎么说,我们把我们的工作开源出来,给大家在使用预训练模型的时候,多一个尝试的选择吧。
这说明以词为单位来做文本生成其实是更有优势的。要是生成更长的文本,这个优势还能进一步放大。
当然,我们也不否认,用WoBERT去做NER等序列标注任务时,可能会有明显的掉点,比如做人民日报的NER,掉了3%左右,可能让人意外的是,经过bad case分析,我们发现掉点的原因并不是因为切分错误,而是因为稀疏性(平均来说每个词的样本更少,所以训练得没那么充分)。
不管怎么说,我们把我们的工作开源出来,给大家在使用预训练模型的时候,多一个尝试的选择吧。
小结
在这篇文章里,我们开源了以词为单位的中文BERT模型(WoBERT),并讨论了以词为单位的优缺点,最后通过实验表明,以词为单位的预训练模型在不少NLP任务(尤其是文本生成)上有它独特的价值,一方面它有速度上的优势,一方面效果上能媲美以字为单位的BERT,欢迎大家测试。
![]()
点击阅读原文,直达“CCF-NLP走进高校之郑州大学”直播页面!
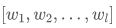 ;
;
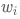 ,
如果
,
如果