BERT, RoBERTa, DistilBERT, XLNet的用法对比
导读:BERT, RoBERTa, DistilBERT, XLNet到底哪家强?在不同的研究领域和应用场景如何选择成了大难题。凡事莫慌,这篇文章帮你理清思路。
BERT 以及后续模型
谷歌基于transformer的BERT系列一经问世就在NLP领域掀起了一场风暴,在几项任务中的表现可谓势头强劲,已经超越了先前沿用的最先进的技术。最近,谷歌对BERT进行了改版,我将对比改版前后主要的相似点和不同点,以便你可以选择在研究或应用中使用哪一种。
BERT是一个双向transformer,用于对大量未标记的文本数据进行预训练,以学习一种语言表示形式,这种语言表示形式可用于对特定机器学习任务进行微调。虽然BERT在几项任务中的表现都优于NLP领域沿用过的最先进的技术,但其性能的提高主要还是归功于双向transformer、掩蔽语言模型对任务的训练以及结构预测功能,还包括大量的数据和谷歌的计算能力。
最近,又提出了几种方法改进BERT的预测指标或计算速度,但是始终达不到两者兼顾。XLNet和RoBERTa改善了性能,而DistilBERT提高了推理速度。下表对它们进行了比较:
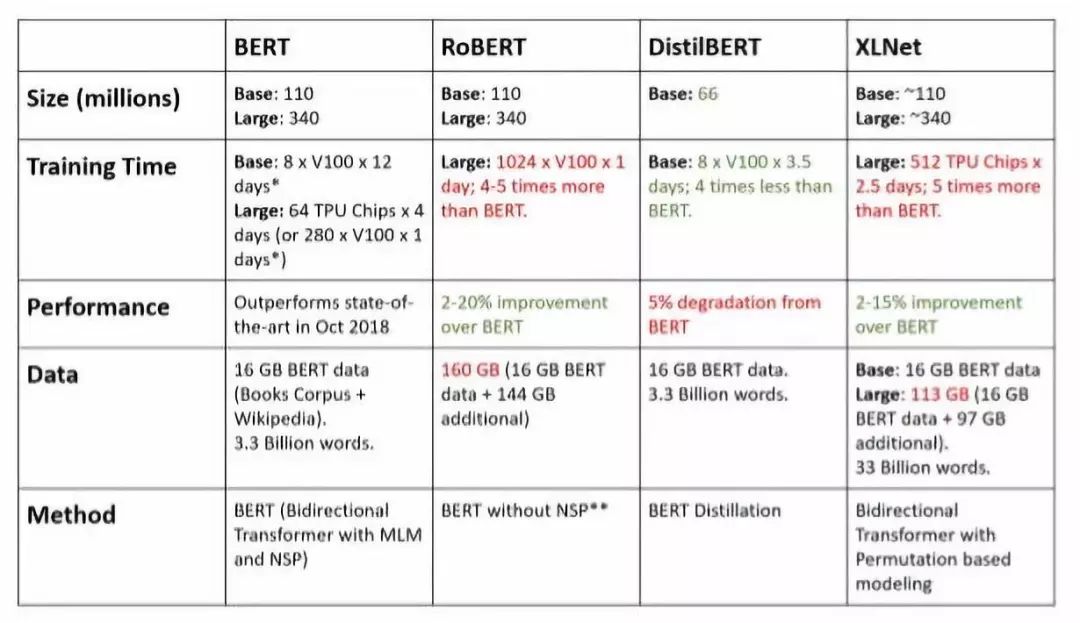
图1:比较BERT和最近的一些改进情况
GPU计算时间是估算的(使用4个TPU Pod进行为时4天的原始训练)
使用大量的小批次数据,根据掩蔽程序的差异进行学习速度和延长时间的训练
数据来源是原始论文
XLNet是一种大型双向transformer,它使用的是改进过的训练方法,这种训练方法拥有更大的数据集和更强的计算能力,在20个语言任务中XLNet比BERT的预测指标要更好。
为了改进训练方法,XLNet引入了置换语言建模,其中所有标记都是按随机顺序预测的。 这与BERT的掩蔽语言模型形成对比,后者只预测了掩蔽(15%)标记。 这也颠覆了传统的语言模型,在传统语言模型中,所有的标记都是按顺序而不是按随机顺序预测的。 这有助于模型学习双向关系,从而更好地处理单词之间的关系和衔接。此外使用Transformer XL做基础架构,即使在不统一排序训练的情况下也能表现出良好的性能。
XLNet使用了超过130 GB的文本数据和512 TPU芯片进行训练,运行时间为2.5天,XLNet用于训练的资料库要比BERT大得多。
RoBERTa,在Facebook上推出的Robustly是BERT的优化方案,RoBERTa在BERT的基础上进行再训练,改进了训练方法,还增加了1000%的数据,强化了计算能力。
为了优化训练程序,RoBERTa从BERT的预训练程序中删除了结构预测(NSP)任务,引入了动态掩蔽,以便在训练期间使掩蔽的标记发生变化。在这过程中也证实了大批次的训练规模在训练过程中的确更有用。
重要的是,RoBERTa使用160 GB的文本进行预训练,其中包含了16GB的文本语料库和BERT使用的英文Wikipedia。其他数据包括CommonCrawl News数据集(6300万篇文章,76 GB),Web文本语料库(38GB)和普通爬虫的故事(31 GB)。 再加上1024个 V100的Tesla GPU每天都在运行,这使得RoBERTa具备了进行预训练的基础。
因此,RoBERTa在GLUE基准测试结果上优于BERT和XLNet:
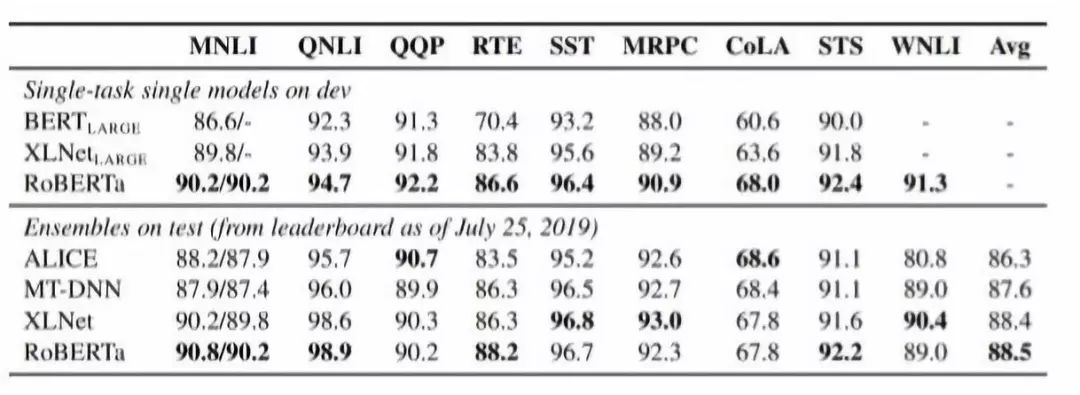
图2:RoBERTa的性能比较。
另一方面,为了减少BERT或相关模型的计算(训练,预测)时间,理应选择使用较小的网络以达到相似的性能。其实有许多方法可以做到这一点,包括剪枝,蒸馏和量化,然而,所有这些都会导致预测指标更低。
DistilBERT学习了BERT的蒸馏(近似)版本,保留了95%的性能,但只使用了一半的参数。 具体来说,它没有标记类型和池化层的嵌入,只保留了谷歌BERT中一半的层。 DistilBERT使用了一种叫做蒸馏的技术,它与谷歌的BERT(也就是由较小的神经网络构成大型神经网络)相似。 这个原理是,一旦要训练一个大型神经网络,就可以使用较小的网络来预估其完整的输出分布。这在某种意义上类似于后验近似。 在贝叶斯统计中用于后验近似的关键优化函数之一是Kulback Leiber散度,自然在这里也被用到了。
注意:在贝叶斯统计中,我们接近真实的后验值(来自数据),而对于蒸馏,我们只能做到接近在较大网络中学习到的后验值。
如何使用
如果你真的需要推理速度快一点,可以接受代价是预测精度稍微下降那么一些的话,那么DistilBERT会是一个合适的选择,但是,如果你还在寻找最佳的预测性能,你最好使用Facebook的RoBERTa。
从理论上讲,基于XLNet置换的训练应该能处理好依赖关系,并且可能在长期运行中能表现出更好的性能。
但是,Google的BERT确实提供了良好的基线,如果你没有上述任何关键需求,就可以使用BERT维持系统的正常运行。
总结
大多数性能的改善(包括BERT本身)都是由于增加了数据量,计算能力或训练过程。 虽然它们确实具有自己的价值,但它们往往倾向于在计算和预测指标之间进行权衡。当前真正需要的是在使用更少的数据和计算资源的同时还可以使性能得到基本的改进。
原文作者:SuleimanKhan
原文链接:https://towardsdatascience.com/bert-roberta-distilbert-xlnet-which-one-to-use-3d5ab82ba5f8
更多内容
专访俞栋:多模态是迈向通用人工智能的重要方向
「LSTM之父」 Jürgen Schmidhuber访谈:畅想人类和 AI 共处的世界 | WAIC 2019
历年 AAAI 最佳论文(since 1996)
一份完全解读:是什么使神经网络变成图神经网络?
点击 阅读原文 获得打包论文资源



