Longformer:超越RoBERTa,为长文档而生的预训练模型

作者 | ChrisCao、小轶

原文链接:https://arxiv.org/pdf/2004.05150.pdf
Github:https://github.com/allenai/longformer
-
复杂度低,将attention机制的复杂度降至 -
通用性强,可用于各类文档级任务 -
部署容易,作者在cuda内核上直接实现了Longformer的attention pattern,并提供了开源代码。
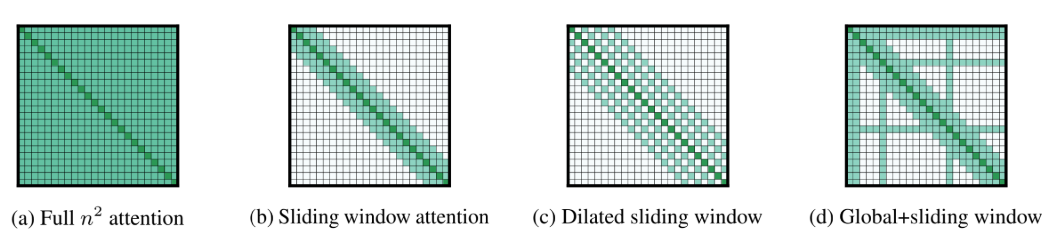
作者共提出了三种新的attention pattern,来降低传统self-attention的复杂度,分别是滑窗机制、膨胀滑窗机制、融合全局信息的滑窗机制。下图展示了传统attention与这三种attention pattern的示意图。接下来将为大家分别讲解。
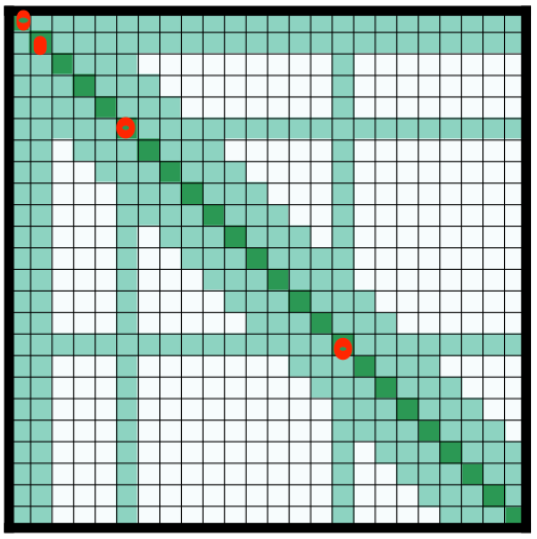
读到这里的,大家可能和我一样,误认为这个窗口 应该比较小,估计在16~64这个量级。但看到实验部分会发现,作者在具体实现的时候,设置的窗口大小 为512,和Bert的Input限制完全一样。所以,大家不要存有“Longformer比Bert还要更轻量”的错觉。


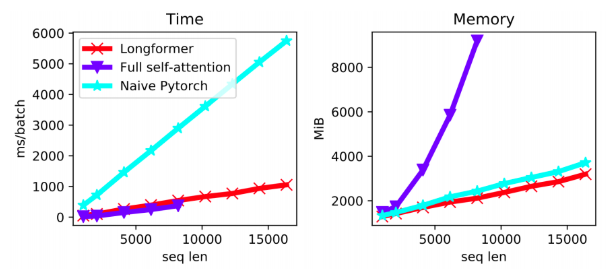
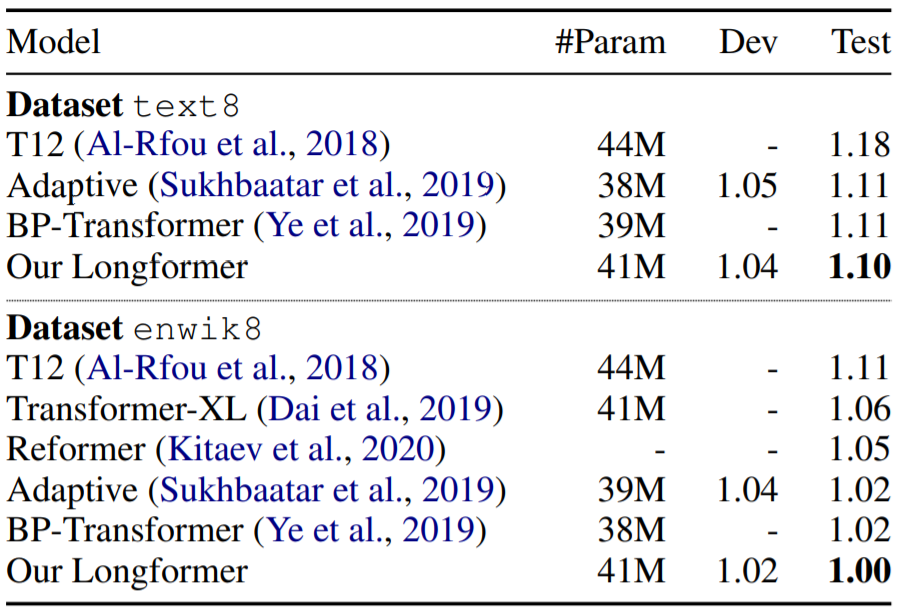
-
表中第一组实验(前三行)讨论的是:如果transformer的不同层采用不同窗口大小,是否可以提高性能?实验结果表明,由底层至高层递增窗口大小,可提升性能;递减则反而性能降低。 -
第二组实验(后两行)是对膨胀滑窗机制的消融实验,证明了增加间隙后的滑窗机制,性能可以有小幅度提升

3、Longformer用于预训练
1)MLM Pretraining


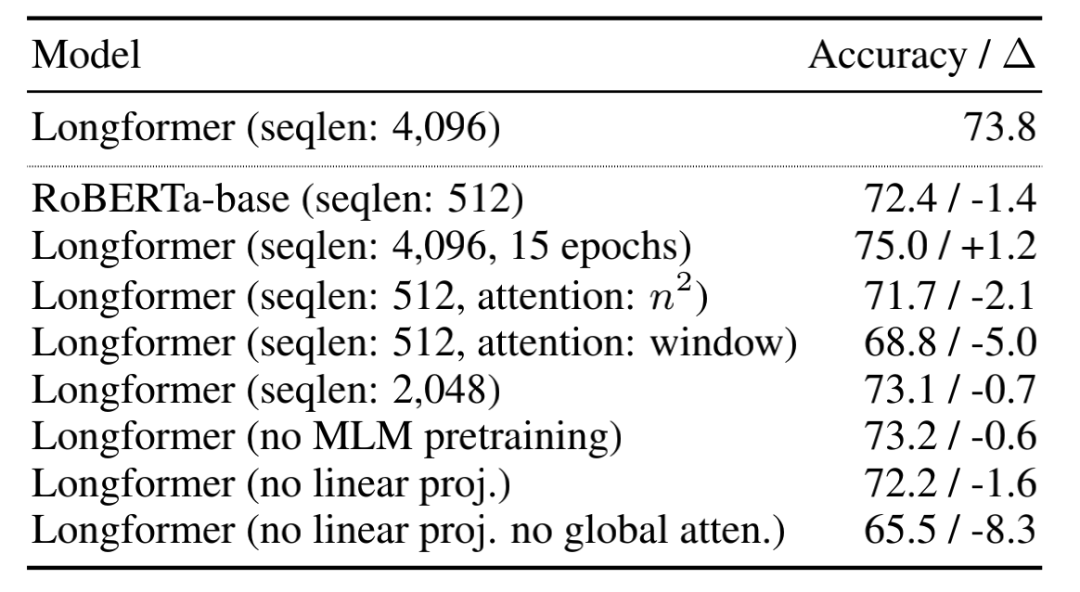
2)消融实验
参考文献:
[1] Dilated CNN:CV中常用的图像编码方式,可拓宽模型编码时的感受野。paper原文链接:https://arxiv.org/abs/1511.07122。另可参考知乎讨论“如何理解空洞卷积(dilated convolution)?”,链接https://www.zhihu.com/question/54149221。
[2] TVM: 关于如何自定义CUDA内核:这里作者使用了TVM (tensor virtual machine)(tvm.apache.org),2018年由华盛顿大学的SAMPL组贡献的开源项目。TVM为不同的深度学习框架和硬件平台实现了统一的编译栈,从而实现将不同框架的深度学习模型到硬件平台的快速部署。

登录查看更多
相关内容

Attention机制最早是在视觉图像领域提出来的,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点。下图表示了attention研究进展的大概趋势。
专知会员服务
32+阅读 · 2020年2月21日
Arxiv
16+阅读 · 2019年5月24日
Arxiv
15+阅读 · 2018年1月5日




相关VIP内容
专知会员服务
32+阅读 · 2020年2月21日
相关资讯
相关论文
Arxiv
16+阅读 · 2019年5月24日
Arxiv
15+阅读 · 2018年1月5日