大众可视化:精美酷炫的可视化图表,自动生成!

编者按:作为一种信息载体,数据可视化可以将枯燥的文字转变成高颜值且直观的图表,实现“一图胜千言”。但要想制作“好的可视化”内容需要极其专业的数据分析能力和图表设计能力,对普通人来说门槛较高。本文中,微软亚洲研究院数据、知识、智能组研究员为大家介绍他们在大众可视化领域的一些探索,让可视化融入普通人的生活中。
在过去十几年的发展中,数据可视化作为一个新兴学科,在信息表达能力方面已经得到了广泛认可,完成了从零到一的转变。但由于相对较高的制作门槛,可视化内容的制作仍然只能由少数专业人士完成,限制了数据可视化的发展。要想实现从一到一万的蜕变,数据可视化必然要走向大众化。
虽然可视化内容的制作过程比较复杂,但是理解的门槛相对较低。研究表明,超过90%的信息是以视觉元素的方式进入人脑的,所以无需专业训练,普通人天生就有从图形图像中寻找信息和发现规律的能力。另外,相比于枯燥的文字,人们往往更容易被精致的图形设计所吸引,也有更强的兴趣去理解和阅读可视化内容。这些都让可视化技术有一个庞大的潜在用户群体,也预示了可视化内容作为一种大众消费内容的巨大潜力。
有数据表明,2010年以来,网络上的可视化内容的数量增长了一百多倍,而2019年更是有超过八成的博客帖子至少带有一个可视化图表。由此可见,可视化的大众化不仅仅是我们的愿景,而已经是一个正在慢慢发生的趋势了。
提到数据可视化,大家首先想到的可能会是饼图、柱状图之类的传统图表。不可否认,这些是,而且一直会是数据可视化的重要手段。但是,随着新的数据类型不断出现,以及在计算机技术的加持之下,新的数据可视化技术也在不断的涌现(如图1 所示)。但万变不离其宗,可视化的本质也一直没有发生改变:将抽象的数据或信息用直观的视觉元素展示出来,以帮助人们快速地理解内容、发现规律、交流信息。一个好的可视化内容能够高度概括纷繁复杂的数据,同时将隐藏的规律变得清晰明了。在这个大数据已经成为基本生产资料的时代,可视化愈发体现出了它不可替代的价值。
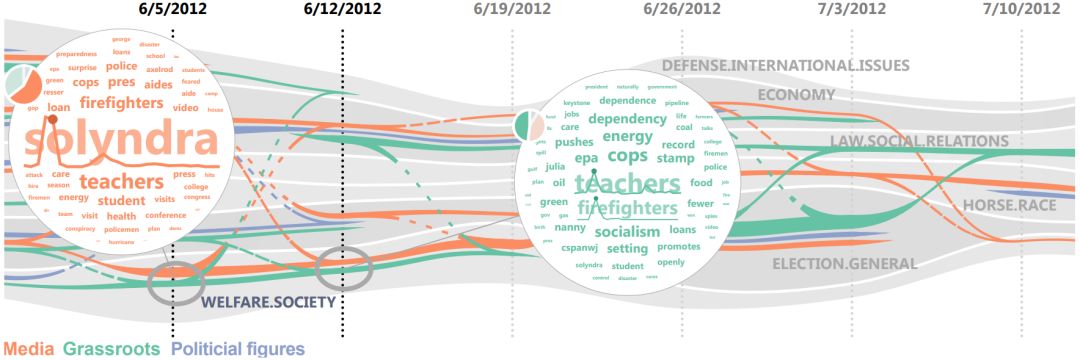
图1:推特主题演化的可视化
对于数据分析师而言,可视化技术能帮他们理解每天都在源源不断生成的大量的新数据。虽然机器学习方法能够从茫茫原始数据中提炼出关键信息,但是这些信息只有在经过人们的理解并产生最后的决策的时候才能真正体现它们的价值,而可视化恰恰能帮人们完成这最后的临门一脚。首先,它能将枯燥复杂的数据变得清晰友好,帮助人们快速全面地掌握关键信息;其次,可视化系统往往支持实时处理和交互分析,这都能够帮助决策者跟踪变化和理解变化背后的原因。统计数据表明,在可视化技术的帮助下,人们有28%的概率能够更及时地做出判断和决策。
另一方面,普通人对可视化的需求也是巨大的。在这个大数据时代,人人可以很方便地在互联网上找到各种信息。但快节奏的生活也导致人们不愿意花太多时间去去理解各种信息。有研究表明,人们平均只会花37秒在一篇网络文章上。那么如何能在37秒内把想表达的信息顺利准确的传递给读者呢?答案就是可视化。作为一个高效的信息载体,可视化恰好满足了人们这种快餐信息的需求。
虽然可视化有上面所说的诸多优点,但并不是说所有的可视化内容都能提供这种好处。假如我们只是简单地把数据一股脑的堆在画布上,这种所谓的可视化很可能适得其反,反而增加了人们阅读的难度。所以,我们在上文中的描述都有一个前提,那就是“好的可视化”,即需要在设计和数据中找到一个平衡点。
首先,一个好的可视化应该能够高效地表达出它想传达的消息,它既不能复杂到失去焦点,也不能简单到丢失信息;其次,一个好的可视化应该符合人的习惯,能自我解释。换言之,人们不用借助说明书就能够毫无障碍地阅读;再次,一个好的可视化应该美观,优美的设计能够极大地增强对读者的吸引力。如果把可视化比作是一种数据到设计的翻译,那么我们可以认为这些是可视化在“信达雅”上的要求。
对于普通人而言,想要制作一个符合上述要求的可视化内容绝对不是一件容易的事情。从获取信息到制作可视化内容,主要面临三大挑战:首先是信息获取的障碍,如何操作复杂的数据分析软件从数据中抽取重要的信息?其次是设计挑战,什么样的设计能既美观又高效地表达我们想要传达的信息?最后是制作挑战,如何通过各种工具制作最终的可视化内容?要想让所有人都能够随时随地地便捷使用可视化内容,实现大众可视化,这三大障碍都必须被克服。
大众可视化的关键在于要让所有人都能毫无障碍地制作好的可视化。但是,人们使用信息可视化的场景千差万别,而不同的场景中人们碰到的障碍也不尽相同。在这里,我们选取了两个常见场景进行了一些初步探索。
Text-to-Viz
假设这样一个场景:某人正在准备一篇文章或是演讲幻灯片。在这个过程中,他觉得有一个观点应该被重点强调。这时加入一个信息图会是一个很好的选择。现在,他需要先上网去寻找一些信息图的设计灵感,然后使用合适的工具将这个设计做出来。这一过程会耗费不少时间和精力,很多可视化的潜在用户可能会因此放弃这一选项。
针对这个场景,我们设定了一个目标,那就是将这个制作过程完全自动化。这个可视化的制作过程就如同一条全自动流水线,输出的产品是可视化内容,而输入的原材料我们选择了对用户要求最低的自然语言。
当然,由于信息的总类五花八门,所以在这次探索里,我们选定了在信息图表中最常见的一类关于比例的信息。例如,用户的输入是“3 out of 5 Chinese people live in rural areas“(每五个中国人中就有三个住在农村地区)这句话,那我们就会自动的设计出合适的信息图(如图2所示)。
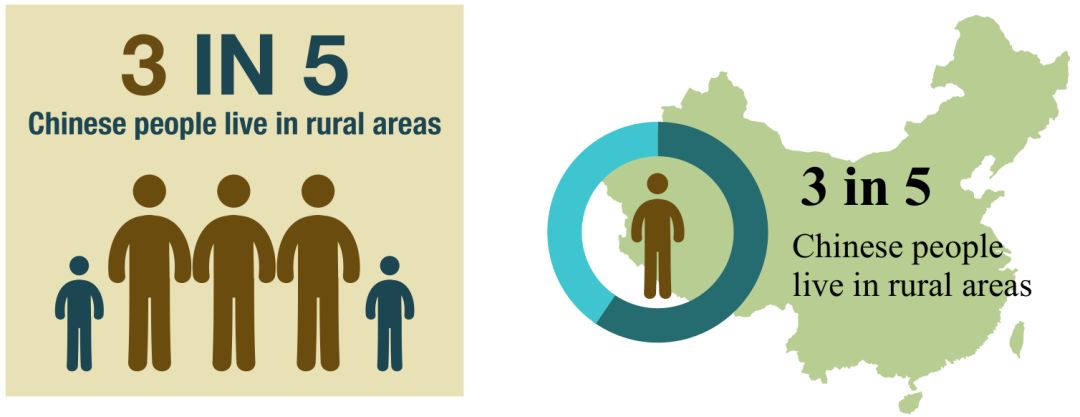
图2:信息图
从用户的输入到信息图的输出,这显然不是一件简单的任务,中间涉及到了许多的技术难点。为此,我们设计了一套复杂的流程。首先通过自然语言分析从文本中提取关键的信息,诸如整体是什么、部分是什么、比例是多少等等;然后,我们收集了网络上大量的设计案例,在这些案例的基础上我们总结并设计出了一套自动设计的算法,将信息分别转化成图形、布局、颜色等等,最终合成许多可能的信息图;最后我们对信息图在若干个维度上评估打分,输出系统推荐出来的最好结果。
详细内容请参考论文Text-to-Viz: Automatic Generation of Infographics from Proportion-Related Natural Language Statements (IEEE VIS 2019)。
论文链接:https://arxiv.org/abs/1907.09091
DataShot
如今我们经常在网络上看到类似于“有关互联网的十个事实“的各种各样的数据海报。这些海报用各种视觉元素简明描绘了各种信息,以达到教育、宣传的目的。但是这种海报的制作也是一个极其复杂的工程。并不是所有人都像数据分析师一样,能够用各种复杂的工具对数据行分析,提炼故事,然后将其清晰简要的展示出来。所以我们也尝试去自动化这个过程。
在这个场景中,我们假想人们只有数据但并不知道数据内部的故事,而我们目标是从一个原始表格数据中自动挖掘信息,整理信息,最后自动生成一个生动的描述数据内故事的一个图形海报(如图3所示)。
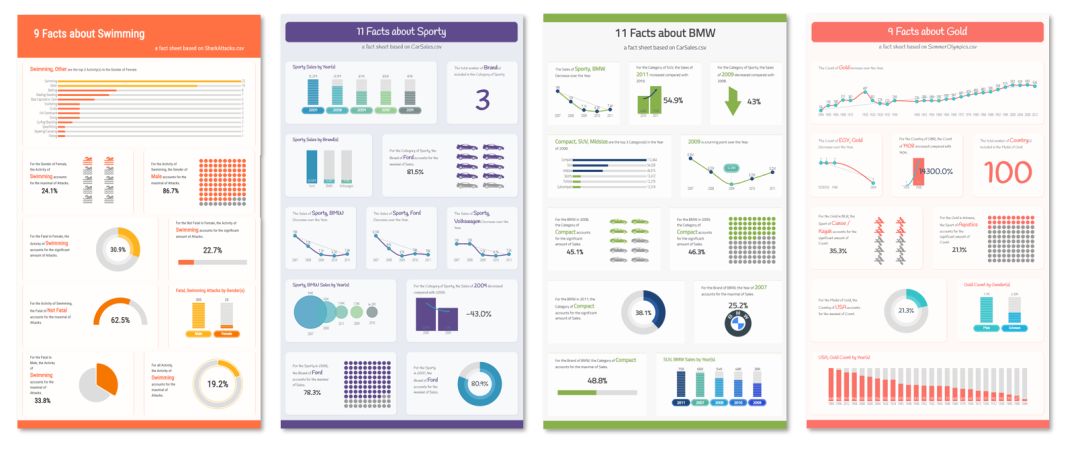
图3:数据海报
与上一个场景相同,为了让这个过程全自动,我们也设计了若干新的技术。首先我们分析了数据海报的组成成分,对数据中可能产生的故事建了一个模型。当给定一个数据集的时候,我们尝试从数据中收集各种类型的事实或是规律。然后将挖掘出的事实整理成有条理的故事。最后,我们实现了一套基于决策树的设计的系统,将整理出的故事可视化,然后自动布局到海报上。
详细内容请参考论文DataShot: Automatic Generation of Fact Sheets from Tabular Data (IEEE VIS 2019)。
论文链接:http://aka.ms/AA6xrgi
当然,人们在现实生活中会遇到更多样和更复杂的场景,我们在上述两个场景中做了一些初步的尝试无法覆盖到所有的数据类型或情况。但我们相信,可视化的未来在于普通人的使用场景中。如今显示设备和计算设备已经在人们的生活中广泛普及,如果可视化制作的障碍也能够被移除,那么,凭借它强大表达能力,可视化一定会惠及每一个普通人,成为我们日常使用的一大工具。
你也许还想看: