从零学习:生成敌对网络(GAN)入门指南
编者按:近年来,神经网络已经取得了很大进展,从能感知图像、声音,到转录人类自然语言,它的发展为我们开启了一扇崭新的大门。但即便如此,我们现在已实现的“智能”距离真正的智能还有不小的差距,机器人能通过传感器收集光谱、声波信息,但它们并不能做到“理解”。这也是许多人强调社会还需要人类的“创造力”的原因:机器人无法自己组织简单语言解释概念,也不能像艺术家一样进行创作。
当然,这个想法放到现在可能有些过时,因为自2014年Ian J. Goodfellow等人首先提出生成对抗网络(Generative Adversarial Network,GAN)后,在短短三年间,这个还不太成熟的深度学习模型就已经成了无监督学习最具前景的方法之一,让许多原本以为需要“创造力”的行为实现了自动化。
从零学习系列第二篇:生成敌对网络(GAN)入门指南,来自数据科学爱好者、深度学习开发者Faizan Shaikh。
本文将介绍GAN的基础概念及其工作方式,并辅之以有趣案例的实现方法和重要资源,方便初学者训练、使用。
目录
什么是GAN?
GAN的工作方式
如何训练GAN
GAN的痛点
实现一个玩具GAN
GAN的应用
资源
什么是GAN?
深度学习领域的大牛Yann LeCun曾在Quora会议上表示:
在我看来,(GAN)是近10年来ML领域提出的最有趣的想法。
这样的评价令人振奋,但似乎对于理解没有任何用处,作为普通的数据科学家,我们眼中的GAN也许更多的是一些实际意义。
那么,什么是GAN?对于这个问题,我们先来打个比方:如果你想改善某些事情,比如说提高下棋水平,你会怎么做?相信普通人的回答都是找一个比自己更强的对手并与之竞争,分析战术技巧、积累经验,直至击败他。GAN的思路也一样,为了成为一个下棋高手(生成模型generator),我们需要一个更强大的对手(判别模型discriminator)。
生成器和判别器的关系可以说是伪造者和调查者的关系。以伪造名画为例,生成器的任务是仿照原画生成赝品,如果蒙混过关(输出),他会得到丰厚奖励。而判别器的任务则是找出赝品和原画的差异,他会从原画中提取特征作为比较内容,以此评估生成的图像是否真实。
如果说这还不够形象,让我们借用微软亚洲研究院的描述:合格男友养成计划。
男:哎,你看我给你拍的好不好?
女:这是什么鬼,你不能学学XXX的构图吗?
男:哦
……
男:这次你看我拍的行不行?
女:你看看你的后期,再看看YYY的后期吧,呵呵
男:哦
……
男:这次好点了吧?
女:呵呵,我看你这辈子是学不会摄影了
……
男:这次呢?
女:嗯,我拿去当头像了
在这个情景中,我们的目标是把男友培养成一个合格的~~陈老师~~摄(拍)影(照)师(的)。产出照片的男友是生成器,鉴别照片质量、审美要求更高的女友是判别器。可以发现,在训练时,每当男友上交一张照片,女友就会指出它们和目标特征(构图、后期)的差距,之后男友根据反馈进行学习,经过数轮重复后,最后他拍出了令人满意的照片。
当然,如果女友水平过高,或者太过天马行空,而男友只是个木讷的“老实人”,那么恭喜你,他们的这段关系(GAN)已经崩溃了。
GAN的工作方式
现在,我们已经大致理解了GAN的概念,可以进一步了解它的工作本质了。
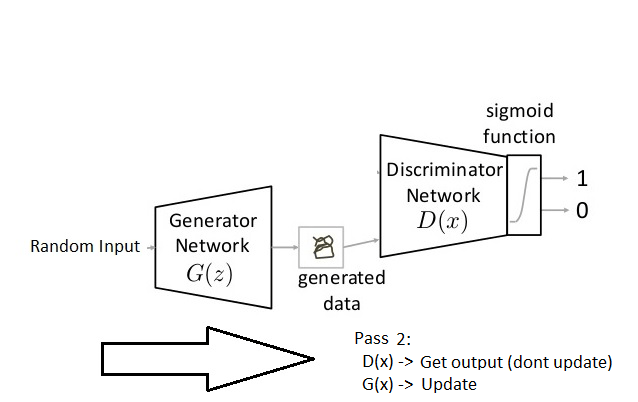
如下图所示,GAN主要由生成器神经网络(Generator Network)和判别器神经网络(Discriminator Network)构成的:
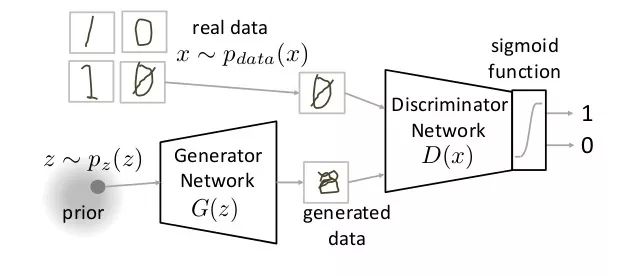
生成器神经网络的任务接收随机输入并尝试生成一个数据样本输入判别器,而判别器神经网络的任务是同时从真实数据和生成器处接收输入,并预测输入是真实的还是生成的。在上图中,我们可以看到生成器G(z)从随机输入p(z)中取了一个样本z,由此产生一个数据输入判别器神经网络D(x),与此同时,D(x)也从真实数据pdata(x)中获得了输入。这之后,D(x)对两个输入用激活函数(sigmoid)进行二元分类,输出范围在0—1之间的概率。
让我们再理一理图中的符号:
Pdata(x):真实数据的分布;
X:pdata(x)中的样本;
P(z):生成器数据分布;
Z:p(z)中的样本;
G(z):生成器神经网络;
D(x):判别器神经网络。
这就是一个基础的GAN,而训练它的方式就是让生成器和判定器互相对抗。这一过程可以用数学来表示:
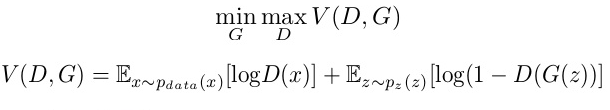
如上式所示,判定器的目标的是使V最大化,而生成器的目标是使V最小化(真实数据与生成数据之间的差异最小化)。换句话说,这是发生在生成器和判定器之间的猫鼠游戏。
正如我们之前提到的,GAN要训练D、G两个神经网络,我们先固定G看D。由于V(D, G)表示的是差异大小,因此对于判别器D,它希望V越接大越好。其中第一项——将Pdata(x)数据映射到判定器内的熵——因为它是真的,所以想被分成1;而对于第二项,它是是P(z)数据映射到生成器内,由此生成假样本输入判定器内的熵,如果D(G(z))被错分为1,那V就无穷小了,所以我们要它接近0。
之后,我们固定D看G。由于第一项不含G成了常数,所以我们可以直接看第二项。可以发现,既然我们的目标是使V最小化,那就是让第二项最小化,那么D(G(z))就该无限靠近1。
注:这种训练GAN的方法受极大极小博弈(minimax game)启示。
如何训练GAN
广泛地说,GAN的训练主要由两部分组成,而且它们还是按顺序进行的。
Pass 1:固定生成器训练判定器(固定意味着将生成器的结果设置为假,神经网络只做正常传播,不做反向传播);
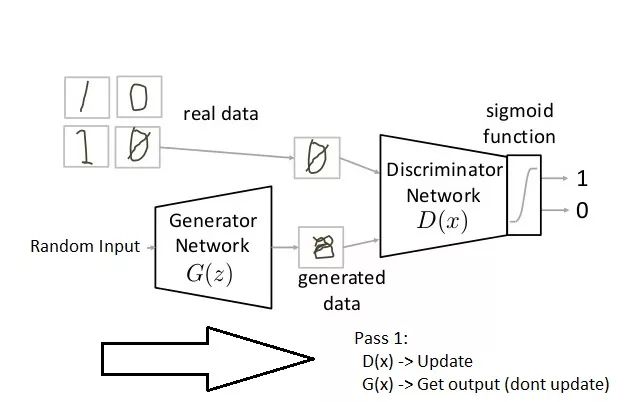
Pass 2:固定判定器训练生成器。
第一步:定义问题。
确定你想生成的对象,是假图像还是加文本,定义问题并搜集数据。
第二步:定义GAN的体系结构。
为你的GAN选定一种结构,比如你的生成器和判定器是多层感知器还是卷积神经网络。这主要取决于你想解决什么问题。
第三步:在真实数据上训练判别器,epoch=n。
训练判别器在真实数据上做出正确预测,轮次n可以是大于等于1的任意自然数。
第四步:为生成器生成假数据,并在假数据上训练判别器。
训练判别器正确鉴别假数据为假。
第五步:用判别器的输出训练生成器。
将判别器的预测结果作为生成器的目标,训练生成器去“欺骗”判别器。
第六步:重复步骤3—5。
第七步:手动检查生成的假数据是否符合期望:如果符合,停止训练;如果有瑕疵,重回第三步。
检查数据是否伪造的最好方法是手动检查,这时你可以评估自己的GAN是否运行良好。
现在,你只需深呼吸一口并静待结果,想象一下,如果有一个功能齐全的生成器,那你就几乎能“伪造”任何东西了。事实上,现在比较常见的应用是生成假新闻、创作情节令人匪夷所思的小说、设置自动答录等。
GAN的痛点
看到这里,你可能会问,既然我们已经有了这样强大的框架,那为什么没有实现什么重大突破呢?事实上,这是因为我们对GAN的理解还停留在表面,即使是“GANs之父”Ian J. Goodfellow,他也无法清除构建一个“足够好”的GAN的过程中的层层阻碍。在他去年发表的论文Improved Techniques for Training GANs中,他还在探讨该如何训练一个GAN。
现在GAN所面临的最重要的问题是稳定性。如果你训练了一个GAN,生成器很弱小,但是判别器却异常强大,你就会发现训练后模型性能很差,因为生成器无法根据反馈有效训练,而这也反过来影响了整个网络。这一点是由损失函数缺失造成的。之前我们提到过,GAN的训练方法启发自极大极小博弈,不用计算损失,就意味着神经网络并不知道自己是否在进步。
另一方面,如果判别器不够强,鉴别范围过于宽泛,那生成器就可以自由生成任何图像,这样导致的训练结果也是一个无用的GAN。让我们回到算式那一节,P(z)是符合分布的生成数据,因为没有预先建模,所以这种随机采样的方式在理论上更接近真实数据,但是这样做的弊端是当面对较大数据时,神经网络缺少约束,会变得过于自由,而且不可控制。
此外,GAN的稳定性问题还体现在它的整体收敛问题上。一方面,生成器和判别器在互相对抗;另一方面,其实它们也互相依赖着进行有效训练。如果一方出现问题,那整个系统就会失败,所以你必须保证它们不崩溃。
这有点像电子游戏波斯王子(Prince of Persia)的情景,王子必须防卫影子的攻击,以免被杀死。如果他杀死了影子,他也会死;如果他什么都不做,那他肯定会死。
下面还有一些GAN面临的应用问题:
注:以下图像是在ImageNet数据集上训练的GAN生成的。
计数问题。GAN无法区分某个位置具体该生成多少特定对象。如下图所示,这些“动物”头部的眼睛太多了;

透视问题。GAN无法适应3D对象,它分辨不了前景和背景的透视差异。如下图所示,它把3D对象转成了3D表示;

全局构造问题。和透视问题一样,GAN也完全把握不了全局构造。例如在下图中,它生成了一头奇怪的牛,它靠两条后腿站着,但是又四脚着地。

针对这些问题,现在我们也有了DCGAN、WassersteinGAN等训练更精确模型的方法。
实现一个玩具GAN
看完理论,让我们实现一个GAN来加深学习印象。
任务:训练一个能自动生成数字的GAN;
数据集:28×28个黑白数字图像,格式为png;
点击https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-digits/下载数据集,注意:这也是一个比赛活动,有兴趣的读者可以前往参加,截止时间还有一周左右。
设置环境:
numpy
pandas
tensorflow
keras
keras_adversarial
在开始写打码前,我们先用伪代码了解下内部实现机制:

Lets start codding!
# 导入模块
%pylab inline
import os
import numpy as np
import pandas as pd
from scipy.misc import imread
import keras
from keras.models import Sequential
from keras.layers import Dense, Flatten, Reshape, InputLayer
from keras.regularizers import L1L2
设定一个seed值防止网络过分自由:
# 防止潜在的随机性
seed = 128
rng = np.random.RandomState(seed)
设置数据和工作目录路径:
#设置路径
root_dir = os.path.abspath('。')
data_dir = os.path.join(root_dir,'Data')
之后是加载我们的数据:
# 加载数据
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
test = pd.read_csv(os.path.join(data_dir, 'test.csv'))
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
train_x = np.stack(temp)
train_x = train_x / 255.
为了使我们的数据更直观,我们先绘制一个图像:
#打印图片
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir,'Train','Images','train',img_name)
img = imread(filepath,flatten = True)
pylab.imshow(img,cmap ='gray')
pylab.axis( 'OFF')
pylab.show()
定义之后我们会用到的变量:
# 定义变量
define vars g_input_shape = 100 d_input_shape = (28, 28) hidden_1_num_units = 500 hidden_2_num_units = 500 g_output_num_units = 784 d_output_num_units = 1 epochs = 25 batch_size = 128
定义生成器神经网络和判别器神经网络:
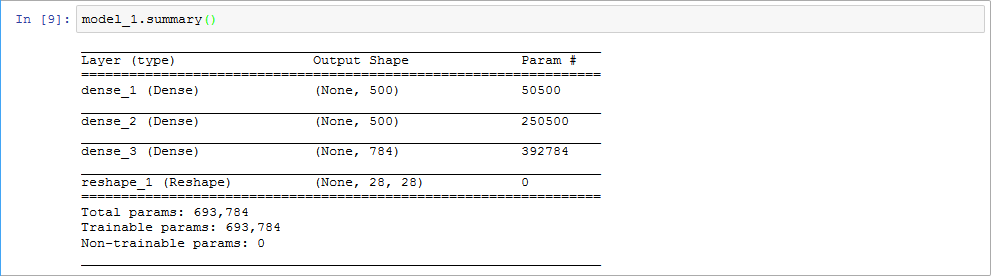
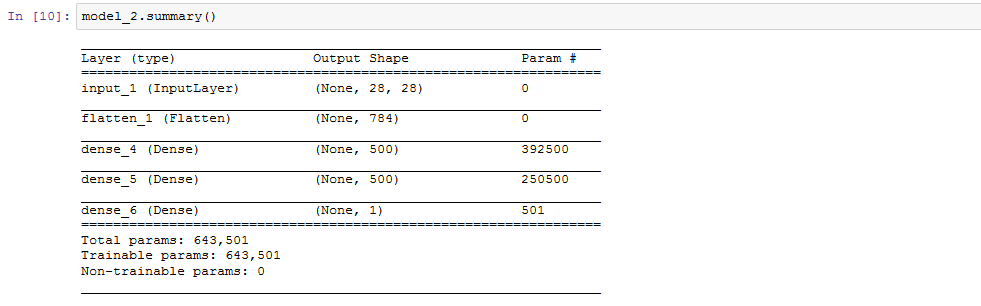
# 生成器
model_1 = Sequential([
Dense(units=hidden_1_num_units, input_dim=g_input_shape, activation='relu', kernel_regularizer=L1L2(1e-5, 1e-5)),
Dense(units=hidden_2_num_units, activation='relu', kernel_regularizer=L1L2(1e-5, 1e-5)),
Dense(units=g_output_num_units, activation='sigmoid', kernel_regularizer=L1L2(1e-5, 1e-5)),
Reshape(d_input_shape),
])
# 判别器
model_2 = Sequential([
InputLayer(input_shape=d_input_shape),
Flatten(),
Dense(units=hidden_1_num_units, activation='relu', kernel_regularizer=L1L2(1e-5, 1e-5)),
Dense(units=hidden_2_num_units, activation='relu', kernel_regularizer=L1L2(1e-5, 1e-5)),
Dense(units=d_output_num_units, activation='sigmoid', kernel_regularizer=L1L2(1e-5, 1e-5)),
])
下图展示了我们的网络架构:
因为我们需要导入一些重要的模块,所以我们需要定义GAN:
from keras_adversarial import AdversarialModel, simple_gan, gan_targets
from keras_adversarial import AdversarialOptimizerSimultaneous, normal_latent_sampling
编译GAN并开始训练:
gan = simple_gan(model_1,model_2,normal_latent_sampling((100,)))
model = AdversarialModel(base_model = gan,player_params = [model_1.trainable_weights,model_2.trainable_weights])
model.adversarial_compile(adversarial_optimizer = AdversarialOptimizerSimultaneous(),player_optimizers = ['adam','adam'],loss ='binary_crossentropy')
history = model.fit(x = train_x,y = gan_targets(train_x.shape [0]),epochs = 10,batch_size = batch_size)
我们的GAN长这样:
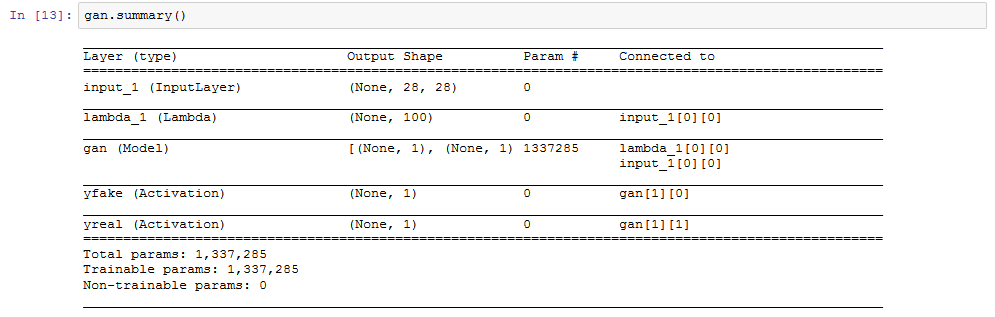
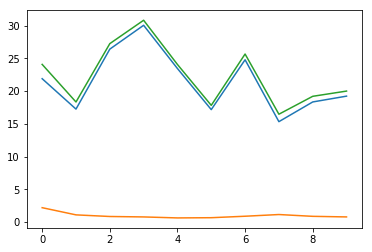
经过10个epoch后,我们会得到一个差不多的图:
plt.plot(history.history['player_0_loss'])
plt.plot(history.history['player_1_loss'])
plt.plot(history.history['loss'])
100个epoch,我们生成了这样的图像:
zsamples = np.random.normal(size=(10, 100))
pred = model_1.predict(zsamples)
for i in range(pred.shape[0]):
plt.imshow(pred[i, :], cmap='gray')
plt.show()
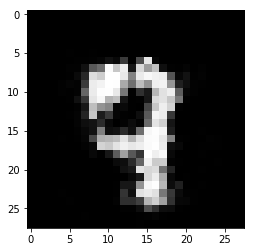
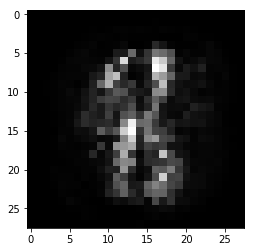
好了,我们的玩具GAN就完成了。
GAN的应用
之前我们介绍了GAN的概念、数学计算、搭建方法等内容,现在可以围观一下当前学界围绕GAN的尖端研究。
预测视频的下一帧。你可以在视频序列上训练GAN,并让它预测下一个画面会是什么;
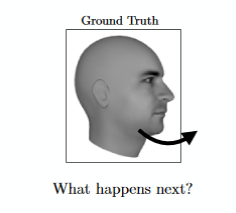
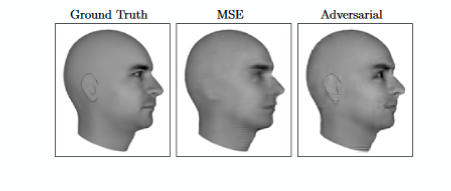
Paper:arxiv.org/pdf/1511.06380.pdf
增加图像分辨率。你可以用GAN生成高清无码图片;

Paper:arxiv.org/pdf/1609.04802.pdf
交互式图像生成。如下图所示,GAN可以实现寥寥几笔就画出令人印象深刻的图片;
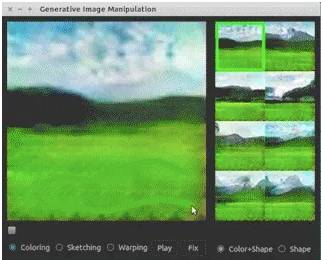
GIF原图请点击【阅读原文】观看
地址:github.com/junyanz/iGAN
图像翻译:用一个图像生成另一张图像。如下图所示,左侧图像是传感器扫描到的标签图像、手提包线条画,右侧是经GAN预测的真实街景图像和真实包包;
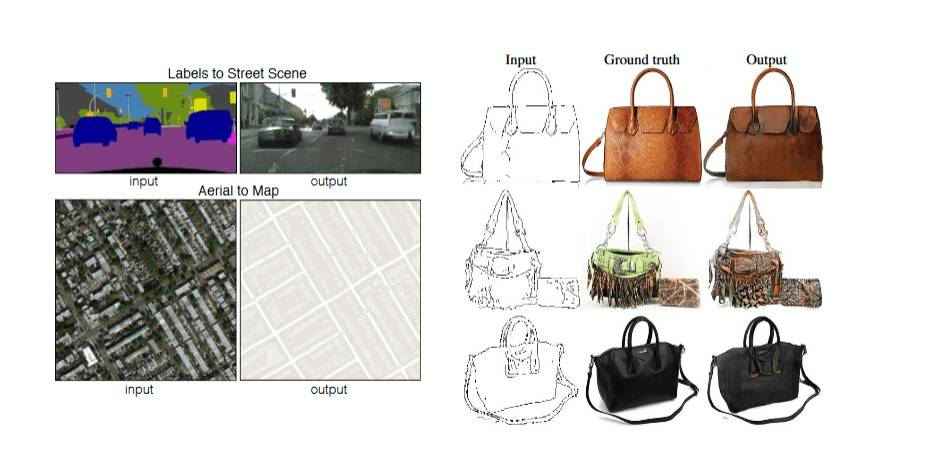
Paper:arxiv.org/pdf/1611.07004.pdf
由文本生成图像。你可以打字告诉GAN你想要什么,它会为你生成相应对象的图片。

Paper:arxiv.org/pdf/1605.05396.pdf
资源
这里有一些资源,可以帮你更深入地了解GAN:
关于GAN的论文:https://github.com/zhangqianhui/AdversarialNetsPapers
深度生成模型简介:http://www.deeplearningbook.org/contents/generative_models.html
Ian Goodfellow的GAN研讨会:https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Generative-Adversarial-Networks
NIPS 2016上的GAN研讨会视频:https://www.youtube.com/playlist?list=PLJscN9YDD1buxCitmej1pjJkR5PMhenTF
原文地址:www.analyticsvidhya.com/blog/2017/06/introductory-generative-adversarial-networks-gans/
“从零学习”第一篇:从零学习:从Python和R理解和编码神经网络(完整版)







