文本分析与可视化

在这篇文章中,我想描述一种文本分析和可视化技术,它使用一种基本的关键字提取机制,只使用单词计数器从我在http://ericbrown.com [1]博客上创建的文章语料库中查找前3个关键词。为了创建这个语料库,我下载了我所有的博客文章(大约1400篇),并抓取了每篇文章的文本。然后,我使用 nltk 和各种 词干提取/词形还原 技术对文章进行令牌化(也可翻译为:标记解析),计算关键词并选取前3个关键词。然后我将所有文章中的关键词聚合起来,使用Gephi[2]工具来创建一个可视化图像。
我已经上传了一个带有完整代码集的jupyter笔记本[3],供你重现此工作。你还可以从这里[4]的csv文件中获得我的博客文章的副本。你需要安装 beautifulsoup 和 nltk。你可以使用以下代码安装他们:

首先,我们加载我们的库:
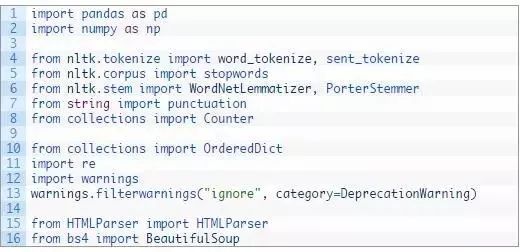
我在这里加载时出现警告,是因为有一个关于 BeautifulSoup 的警告,我们可以忽略它。
现在,让我们来设置一些工作所需要的东西。
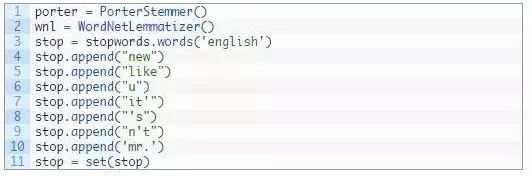
首先,我们来设置停止词、词干提取器和词形还原器。
现在,我们来建立一些我们需要的函数。
tokenizer 函数是从这里[5]引用的。如果你想看一些很酷的主题建模,那就跳过并阅读如何在Python中挖掘新闻反馈数据和提取交互式见解……[6]这是一篇非常好的关于主题建模和集群的文章,我在本文及以后的文章中也会提到这一点。
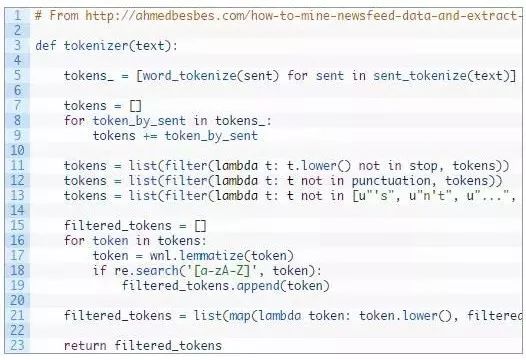
接下来,我的文章中有一些html标记,所以我想在对它做任何其他事情之前先将它从我的文本中删除……这里有一个使用 bs4 的类可以实现,我在Stackoverflow[7]上找到了这段代码。
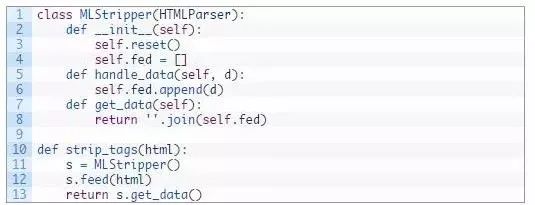
好了,现在来看看有趣的东西。要获得关键词,我们只需要两行代码。这个函数执行计数并为我们返回关键字的数量。

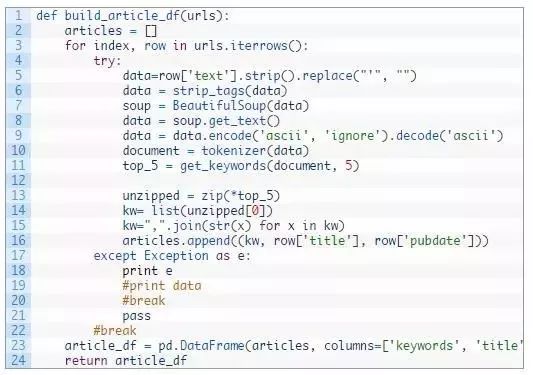
最后,我创建了一个函数来获取一个包含 url /pubdate/author/text的pandas dataframe(数据结构集),然后从中创建关键词。这个函数遍历一个pandas dataframe(每行是一篇来自我博客的文章),标记“text”来源并返回一个pandas dataframe,其中包含关键词、文章标题和文章的发布数据。
现在是时候加载数据并开始分析了。这段代码载入我的博客文章(可以在这里[8]找到),然后从数据中只获取感兴趣的列,重命名它们并为标记化做准备。在读入csv文件时,大多数操作都可以使用一行代码完成,但是我已经为另一个项目编写了这些操作,并且它就是这样。

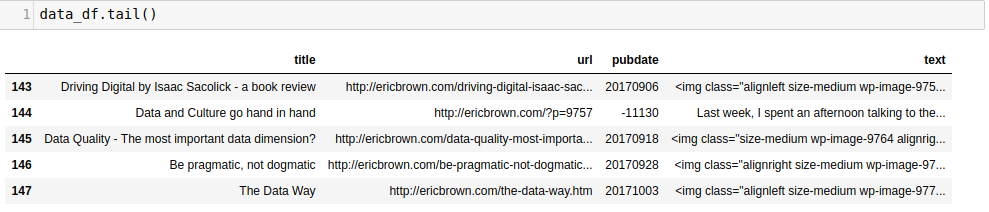
使用dataframe的 tail() 方法我们可以得到:
现在,我们可以通过调用 build_article_df 函数来标记和单词计数工作了。
这将为我们提供一个新的dataframe,其中包含每篇文章的前3个关键词(以及文章的发布日期和标题)。

这本身就很酷。我们使用一个简单的计数器为每篇文章自动生成关键词。不是很复杂,但是很好用。还有很多其他的方法,但是现在我们还是用这个。除了拥有关键词之外,看一看这些关键词之间以及它们和其他关键词之间是如何“连接”起来的,可能会很有趣。例如,“data”在其他文章中出现了多少次?
有多种方法可以回答这个问题,但是一种方法是通过可视化以一个 拓扑/网络 映射来查看关键词之间的连接。我们需要对关键词进行“计数”,然后构建一个共生矩阵,我们可以将这个矩阵导入到 Gephi 中来进行可视化。我们可以使用 networkx 库来绘制网络映射,但是需要做很多工作,否则就很难从中得到有用的东西,相比之下,还是使用 Gephi 对用户更友好。
我们有了关键词,需要一个共生矩阵。要做到这一点,我们需要进行一些操作,让我们的关键词分开来。

现在我们有了一个关键词dataframe kw_df ,它包含两列:关键词和带有关键词的关键词组
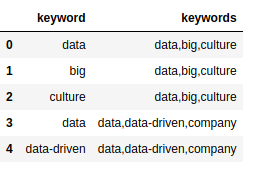
这并没有什么实质意义,但是我们需要两列来构建一个共生矩阵。我们通过迭代每个文档关键词列表( keywords 列)并查看是否包含 关键词 。如果包含,我们就把它加入到共生矩阵中,然后构建出我们的共生矩阵。
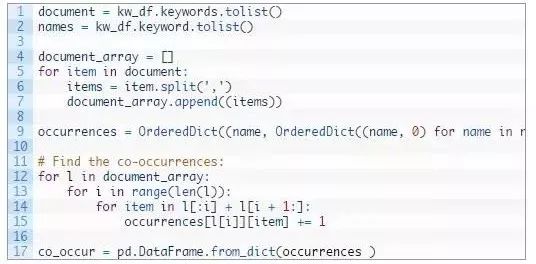
现在,我们在 co_occur dataframe中有一个共生矩阵,可以将其导入到 Gephi 中来查看节点和边缘的映射。将 co_occur dataframe保存为一个CSV文件,以便在 Gephi 中使用(你可以在这里[9]下载该矩阵的副本)。
First, import your co-occuance matrix csv file using File -> Import Spreadsheet and just leave everything at the default. Then, in the ‘overview’ tab, you should see a bunch of nodes and connections like the image below.
走进Gephi
现在,是时候使用Gephi了。对于这个工具,我是新手,所以就不能像教程那样给你提供很多东西,但是我可以告诉你构建网络映射所需要的步骤。首先,使用 File -> Import Spreadsheet 导入共生矩阵csv文件,并将所有内容保留为默认值。然后,在“overview”选项卡中,你应该会看到一连串的节点和连接,如下图所示;
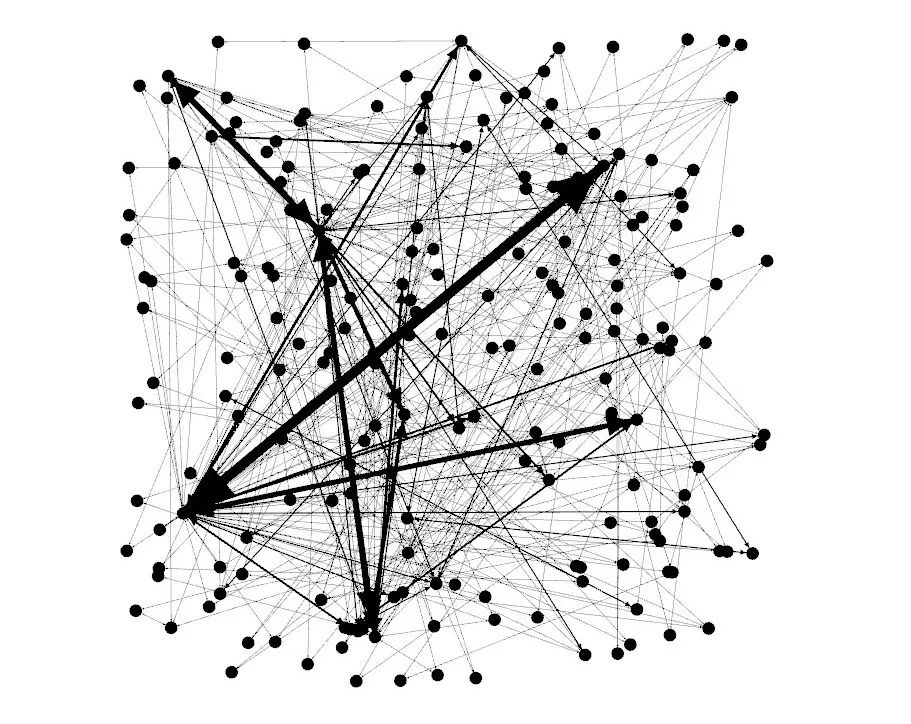
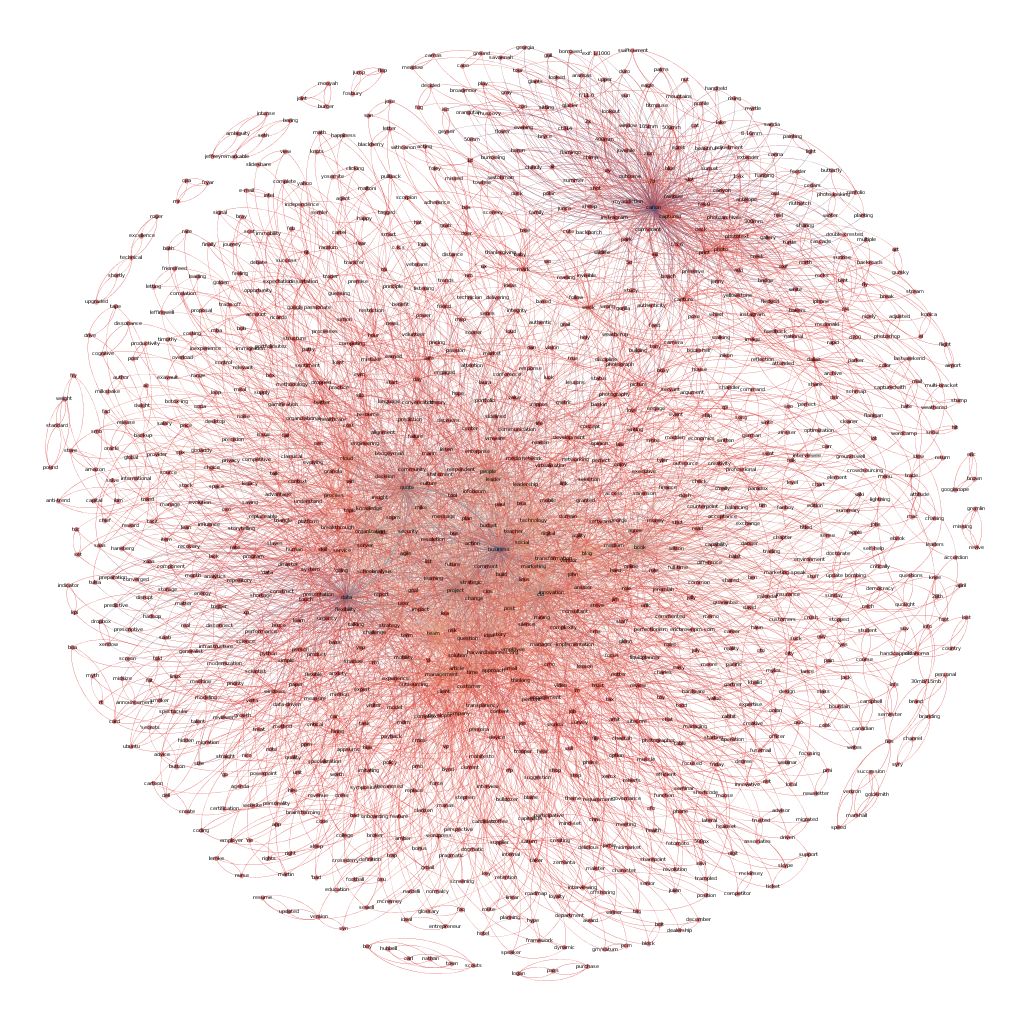
ericbrown.com文章副本的网络映射图
接着,向下移动到“layout”部分,选择Fruchterman Reingold layout,并按下“run”按钮来重新绘制映射图。在某些情况下,当节点在屏幕上稳定下来后,你需要按下“stop”。你会看到如下所示的内容。
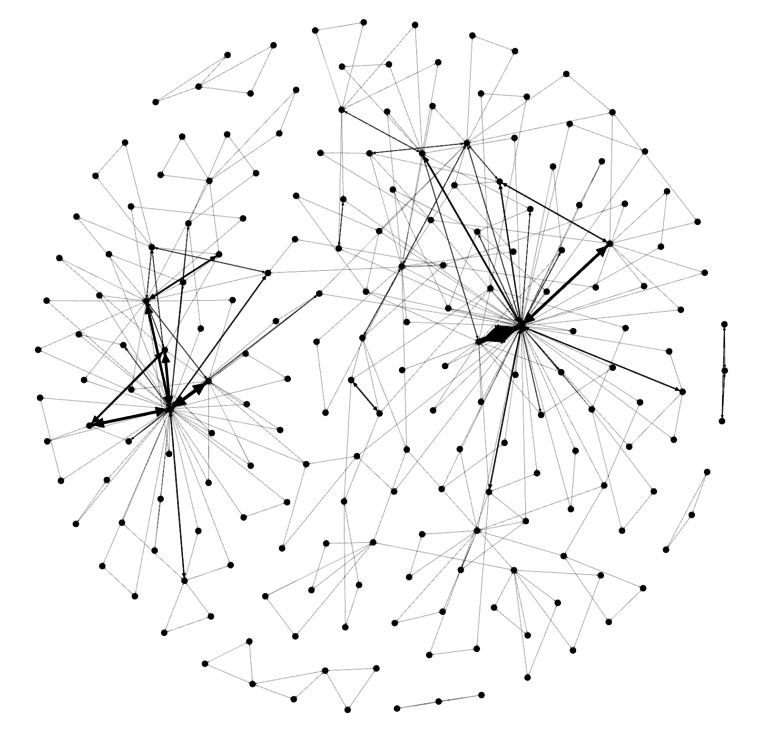
ericbrown.com文章副本的网络映射图
很酷,对吧?现在,让我们给这个图像加入颜色。在“appearance”部分,选择“nodes”,然后选择“ranking”,接着选择“Degree”并点击“apply”。你会看到网络图发生了变化,现在它有了一些与之相关的颜色。如果你愿意,你可以随意改变颜色,但是默认的配色方案应该是这样的:
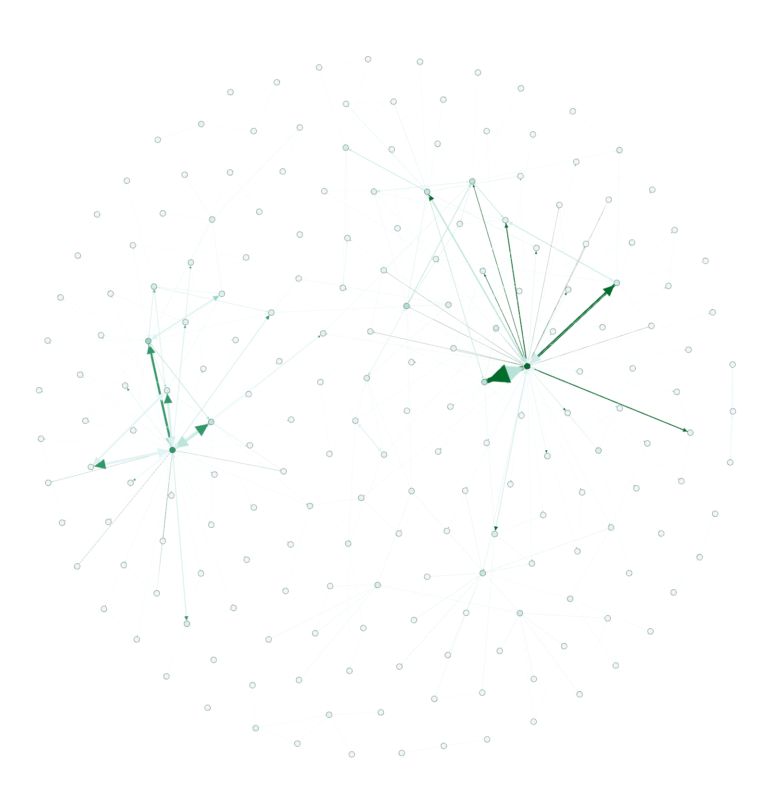
不过这还不是太有趣。文本/关键词在哪里呢? 你需要切换到“overview”选项卡才能看到。你应该会看到如下所示的内容(在下拉列表中选择“Default Curved”之后)。
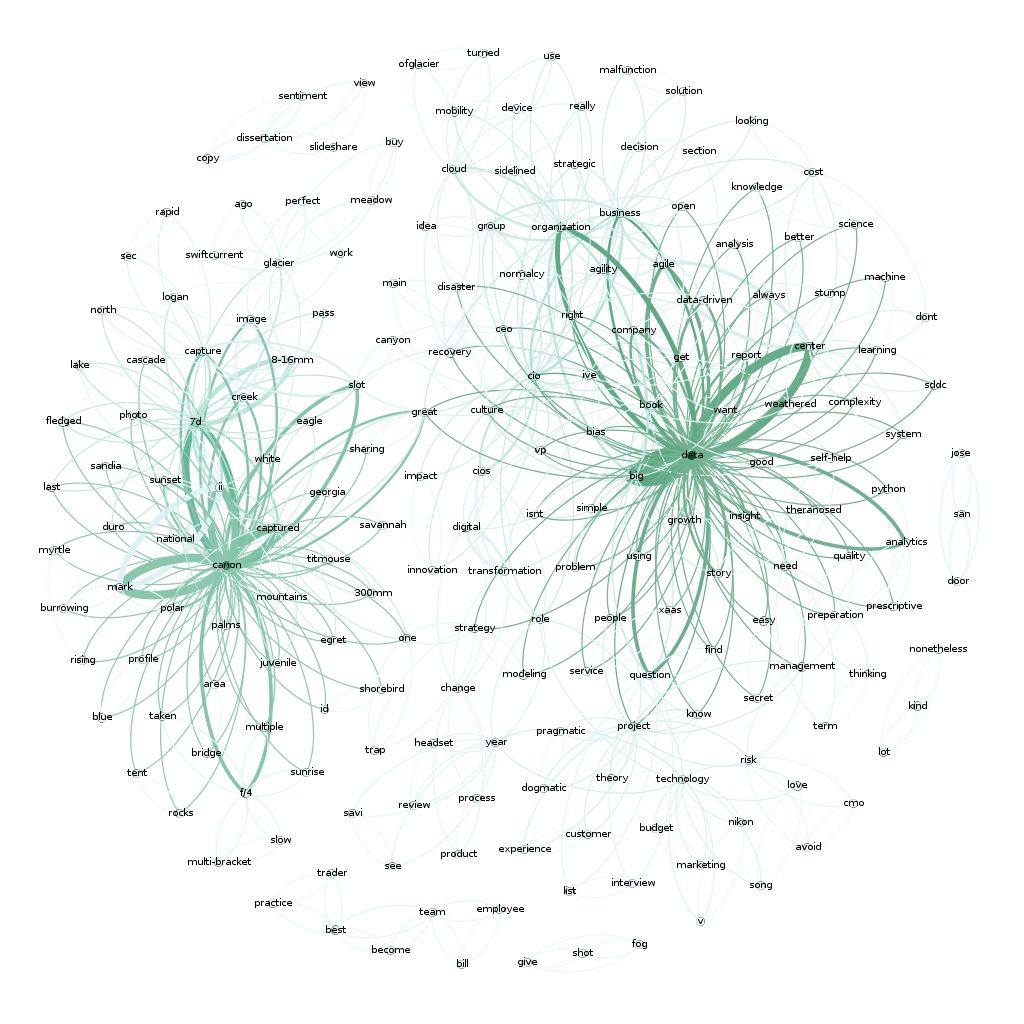
这下子就很酷了。你会在这里看到两个非常不同的很有趣的领域。“Data”和“Canon”……这是有道理的,因为我写了很多关于数据的东西,分享了很多我的摄影作品(用Canon相机拍的)。
如果你感兴趣的话,这是我所有1400篇文章的完整映射图。同样,有两个围绕着摄影和数据的主要集群,但还有一个围绕着‘business’, ‘people’ 和 ‘cio’的大型集群,这与我多年来的大部分写作内容相吻合。
还有许多其他方法可以可视化文本分析。我打算再发几篇文章来谈谈我最近使用和遇到的一些更有趣的方法。请继续关注。
如果你想了解更多关于文本分析的知识,请阅读以下书籍:
使用Python进行文本分析:从数据中获得有用结论的实战方法[10]
Python的自然语言处理:使用自然语言工具包分析文本[11]
R语言文本挖掘[12]
相关链接:
[1]——http://ericbrown.com./
[2]——https://gephi.org/
[3]——https://github.com/urgedata/pythondata/blob/master/Text%20Analytics/ericbrown.ipynb
[4]——https://github.com/urgedata/pythondata/blob/master/examples/tocsv.csv
[5]——http://ahmedbesbes.com/how-to-mine-newsfeed-data-and-extract-interactive-insights-in-python.html
[6]——http://ahmedbesbes.com/how-to-mine-newsfeed-data-and-extract-interactive-insights-in-python.html
[7]——https://stackoverflow.com/questions/753052/strip-html-from-strings-in-python
[8]——https://github.com/urgedata/pythondata/blob/master/examples/tocsv.csv
[9]——https://github.com/urgedata/pythondata/blob/master/Text%20Analytics/out/ericbrown_co-occurancy_matrix.csv
[10]——http://amzn.to/2wTELtb
[11]——http://amzn.to/2y7B9E6
[12]——http://amzn.to/2g6zmaU
英文原文:https://pythondata.com/text-analytics-visualization/
译者:天天向上