学界 | MNIST上的首个对抗鲁棒分类器,骗得了人类才能骗过它
选自arXiv
作者:Lukas Schott, Jonas Rauber, Matthias Bethge,Wieland Brendel
机器之心编译
参与:晓坤、李亚洲
深度学习网络的对抗鲁棒性问题远未得到解决,而之前提出的当前最佳方法被本研究发现是过拟合于某种对抗攻击类型的。在今天要介绍的论文中,研究者提出了一种基于变分自编码器的分类模型ABS,可以导出每个实例的鲁棒性边界。在MNIST上的实验结果表明,ABS对各种对抗攻击都具备鲁棒性,达到当前最佳;并且能骗过它的很多对抗样本,人类也是能理解其语义含义的。
如下图所示,ABS 把 0 识别成 6,把 1 识别成 2... 这对于人类而言,也有识别出错的可能。

深度神经网络非常容易受到微小的对抗扰动的影响,这些扰动几乎对人的识别没什么影响,但能将 DNN 的分类预测转变为任意想要的目标类别。寻找有效抵御机制的一个关键难题是可靠评估模型鲁棒性。有文献已经屡次表明,先前提出的所有抵御机制都不能增加模型的稳健性,而是预防最小的已有对抗样本攻击。少部分可验证的抵御机制只能保证数据点周围一小部分 linear regime 内的鲁棒性。
当前认为唯一有效的防御方法是 Madry 等人提出的一种特别类型的对抗训练。在 MNIST 上,对抗扰动 L_∞ 范数限制为 0.3 时,目前为止这种方法能够达到 88.79% 的准确率。也就是说,如果我们允许攻击器扰动每个像素亮度达到 0.3 时(范围为 0-1),它只能在 10% 的样本上诱骗模型。这是很大的成功,但模型真的学到更多因果特征来分类 MNIST 吗?在本文中,研究者证明并非如此:首先,Madry 等人提出的防御方法在 L_∞ 上过拟合,在某种意义上,L_2 和 L_0 中的对抗扰动跟无防御的网络一样小。第二,因为 MNIST 中单个像素的二值(非黑即白)特性,Mardy 等人方法取得的稳健结果也能用简单的输入二值化方法来获得。第三,它是直接把识别不出的图像分类为一个数字。最后,Madry 等人找到的最小对抗样本对人类没有意义。

图 4:示例:CNN、Madry 方法和本文提出的 ABS 模型以超过 90% 准确率将图像分类为「1」。
总结起来,即使是 MNIST 也不能被认为用相关的对抗鲁棒性方法解决了。「解决了(solved)」一词意味着模型能够达到知道 99% 的准确率(查看 GiLmer 等人论文中准确率与鲁棒性的权衡)且有效的对抗样本要对人类有语义意义(也就是说样本看起来可以归属到某一类)。因此,尽管 MNIST 被认为非常简单,找到 MNIST 上的对抗鲁棒性模型仍是一个开发性难题。
作者在本文中探索的潜在解决方案受到了不可识别图像或远端对抗(distal adversarials)的启发。远端对抗是和训练图像不相似,看起来像噪声,但仍以高信度被模型分类的图像。看起来似乎很难在前馈网络中防御此类图像,因为我们对于远超出训练领域的输入如何被分类很难进行控制。相对地,生成模型可以学习输入的分布,并因此可以度量其分类信度。通过在每个类别中额外地学习图像分布,我们可以检查输入展示的图像特征如何影响分类结果(例如,公交车的图像应该包含真实的公交车特征)。按照这种信息论的思路,我们可以想到著名的贝叶斯分类器概念。在本文中,作者介绍了一种基于变分自编码器的微调变体,其在实现高准确率的同时能保证鲁棒性。
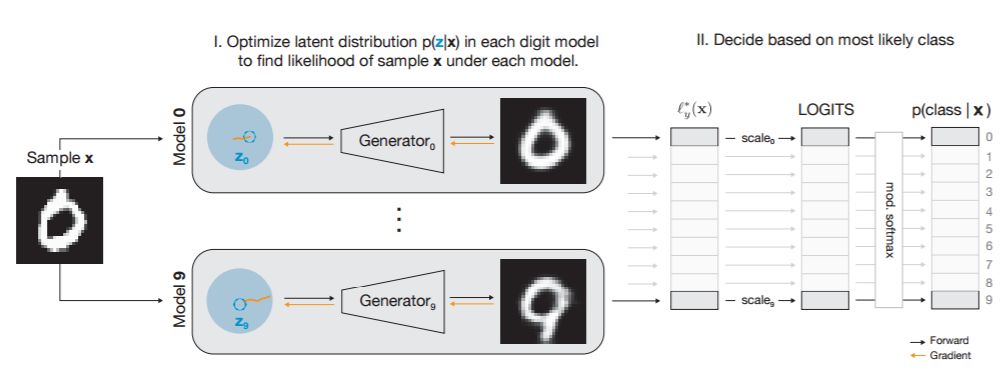
图 1:模型架构概览图。简单来说:I) 在隐藏空间执行梯度下降,对每个采样 x,我们计算出每个类别的对数似然度下界(ELBO);II) 类-条件(class-conditional)ELBO 的类依赖(class-dependent)标量权重构成了最终的分类预测。
本文的研究贡献总结如下:
本研究表明 MNIST 的对抗鲁棒性问题并没有得到解决:当前最佳的 Madry 等人提出的防御方法仍然对微小的扰动很脆弱;
研究者引入了一种新的分类模型,并导出了特定于实例的鲁棒性保证;
研究者开发了一种新的利用了 ABS 模型的生成结构的攻击方法;
研究者引入了一种新的基于决策的最小化 L_0 的攻击;
研究者在多种攻击类型上进行了防御方法的扩展实验评估,表明 ABS 模型能在 L_0、L_2、L_∞扰动上能超越当前最佳,并且对 ABS 有效的对抗攻击对于人类而言也具备语义含义。
作者认为尽管已经做了较充分的对比实验,但仍然是不全面的,之后将会开源模型架构和预训练权重,让社区独立地进行模型评估。
论文标题:TOWARDS THE FIRST ADVERSARIALLY ROBUST NEURAL NETWORK MODEL ON MNIST

地址:https://arxiv.org/pdf/1805.09190v3.pdf
尽管付出了巨大的努力,深度神经网络在 MNIST(计算机视觉中最常用的小型数据集)上执行分类任务时仍然对微小的扰动高度敏感。我们在本研究中表明即使是广泛认可和目前最成功的由 Madry 等人提出的对抗方法也存在如下问题:(1)对 L_∞指标过拟合(对 L_2 和 L_0 扰动则很敏感);(2)对(人类)不可识别的图像以高确定度进行分类;(3)表现并没有比简单的输入二值化方法更好;(4)使用的对抗扰动对人类而言没有语义含义。
这些结果表明 MNIST 的对抗鲁棒性问题远远没有得到解决。我们在本文中展示了一种新型的鲁棒分类模型,其使用学习到的类条件(class-conditional)数据分布来执行合成分析(analysis by synthesis)。我们导出了鲁棒性的边界,并在大量实验中使用最大化的有效对抗攻击来评估我们的模型,包括:(a)L_p 范数的基于决策、基于分数、基于梯度和基于迁移的攻击;(b)设计了一种新的利用防御模型的结构的攻击;(c)设计了一种新的基于决策的的攻击,其试图最小化扰动像素的数量(L_0),结果表明我们的方法在 MNIST 上的 L_0、L_2、L_∞扰动攻击中能取得当前最佳的鲁棒性,并且展示大多数对抗样本都远远偏离了原始类别和对抗类别之间的感知边界。
实验
我们对比了我们的 ABS 模型、输入二值化变体(Binary ABS)、输入二值化的 CNN(Binary CNN)与其它三种模型的对抗鲁棒性表现,包括:当前最佳的 L_∞防御(Madry et al., 2018)、最近邻模型(具备鲁棒性但不准确的基线)、标准 CNN(准确而不够鲁棒的基线)。
对每个模型和 L_p 范数,我们展示了随着对抗扰动尺度增加模型准确率降低的表现,如图 2 所示。在图(b)中我们能看到 Madry 等人的方法在 L_∞距离=0.3 的阈值内有很好的表现,而 Binary ABS 能达到 0.5 的阈值。
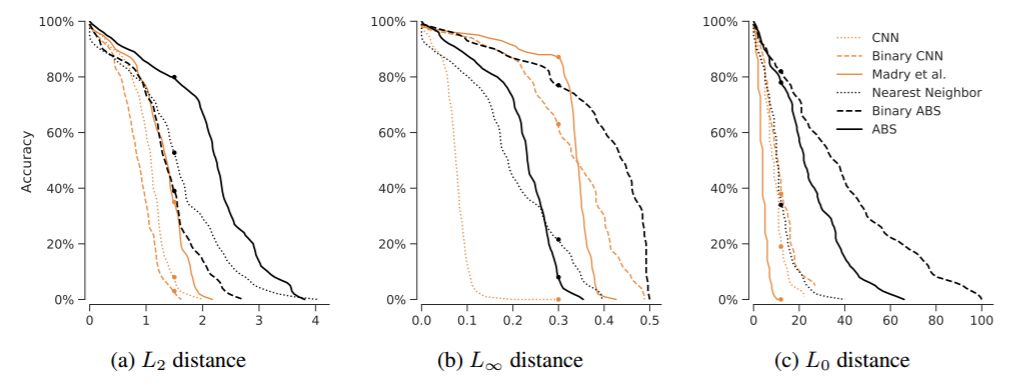
图 2:所有模型在各种距离指标(L_0、L_2、L_∞扰动攻击)上随对抗扰动尺度变化的识别准确率变化。
结果
我们对所有模型的鲁棒性评估结果如表 1 和图 2 所示。所有的模型(除了最近邻分类器)都在干净的测试样本中达到了将近 99% 的准确率。其中我们分别使用了 L_0、L_2、L_∞扰动攻击。
对于 L_2 扰动,我们的 ABS 模型显著超越了所有其它模型。
对于 L_∞扰动,我们的 Binary ABS 模型在中等扰动尺寸下达到当前最佳。从准确率的角度看,当扰动距离<0.3 时,Madry 等人的方法似乎更加鲁棒。然而,如图 2 中的准确率下降曲线所示,这只是针对特定阈值下才有效(Madry 等人的方法专门为 0.3 阈值优化)。而稍微更大的阈值下(例如 0.35),Binary ABS 模型的表现要好得多。
对于 L_0 扰动,ABS 和 Binary ABS 相比其它模型的鲁棒性都要好得多。有趣的是,Madry 等人的方法鲁棒性最低,甚至低于基线 CNN。
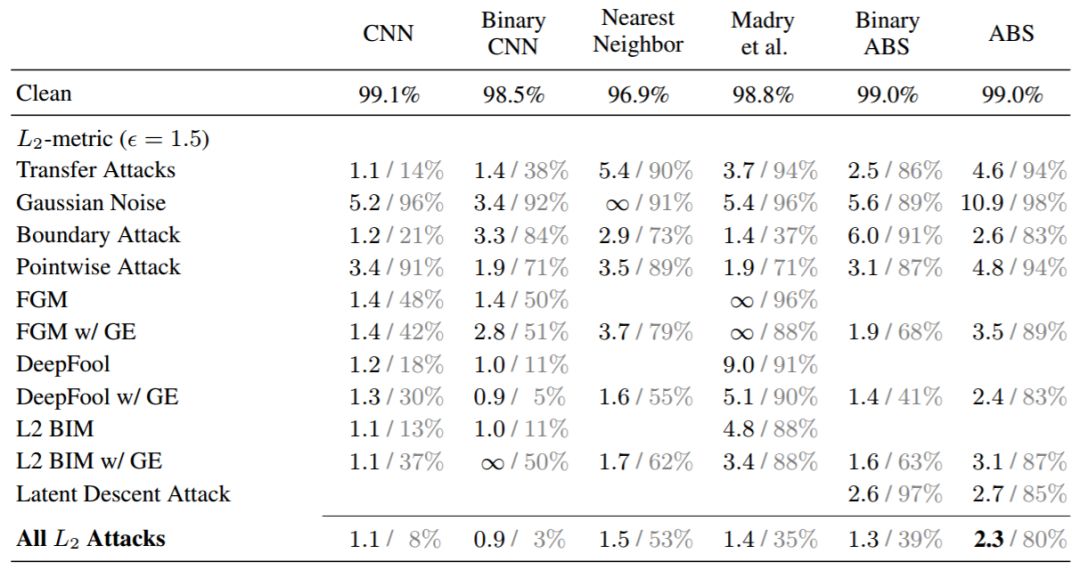
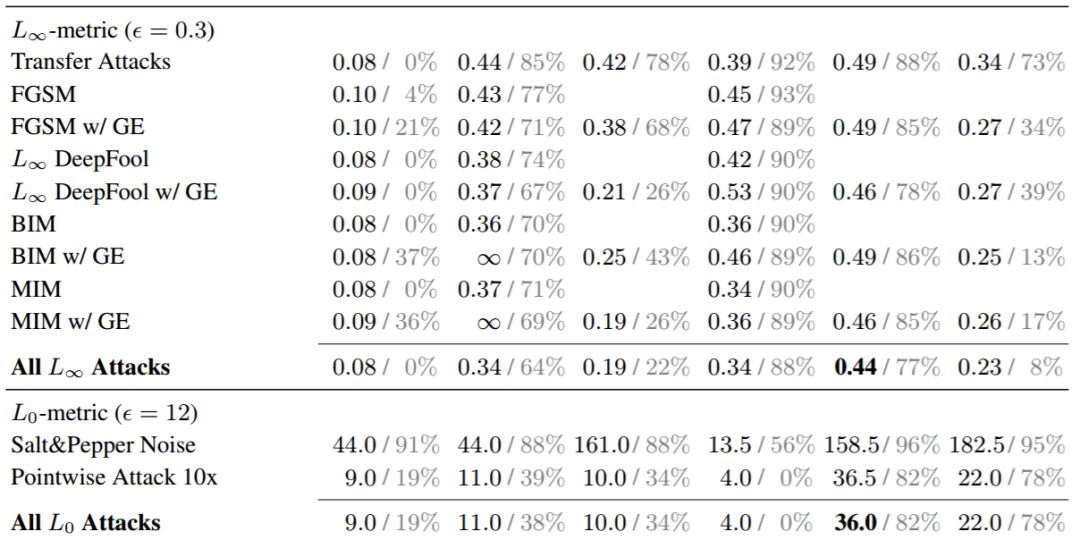
表 1:不同模型在不同对抗攻击和距离指标下的 MNIST 分类准确率结果。每一项展示了所有样本的中位数对抗距离(左值,黑体),以及模型在对抗扰动阈值(L_2 = 1.5、L_∞ = 0.3、L_0 = 12)下的分类准确率(右值,灰体)。「w/ GE」表示使用了数值梯度估计的攻击。
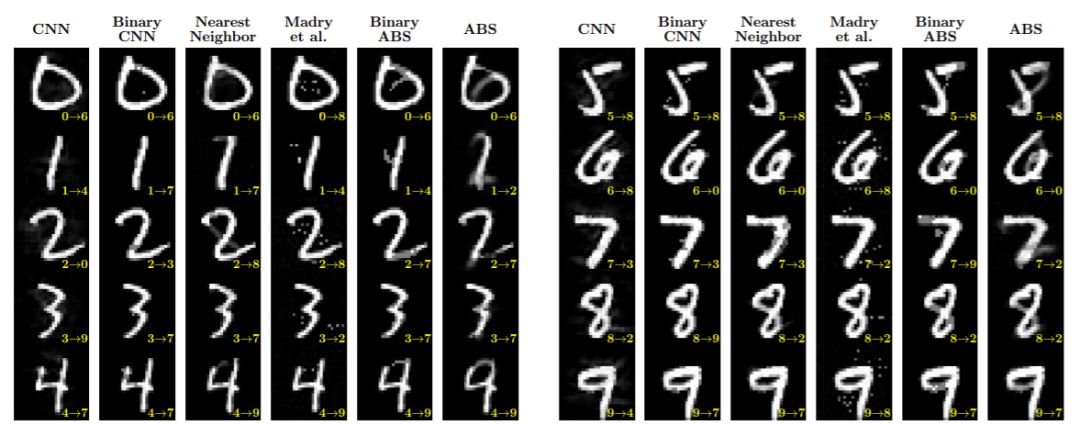
图 3:对 ABS 模型有效的对抗样本在人类感知上是有意义的:对每个样本(从每个类别中随机选取),我们展示了任意攻击中的最小 L_2 对抗扰动。我们的 ABS 模型的有效对抗攻击是视觉上可见并且通常在语义上有意义的。Madry 等人的方法的有效攻击在视觉上可见,但语义含义要模糊得多。
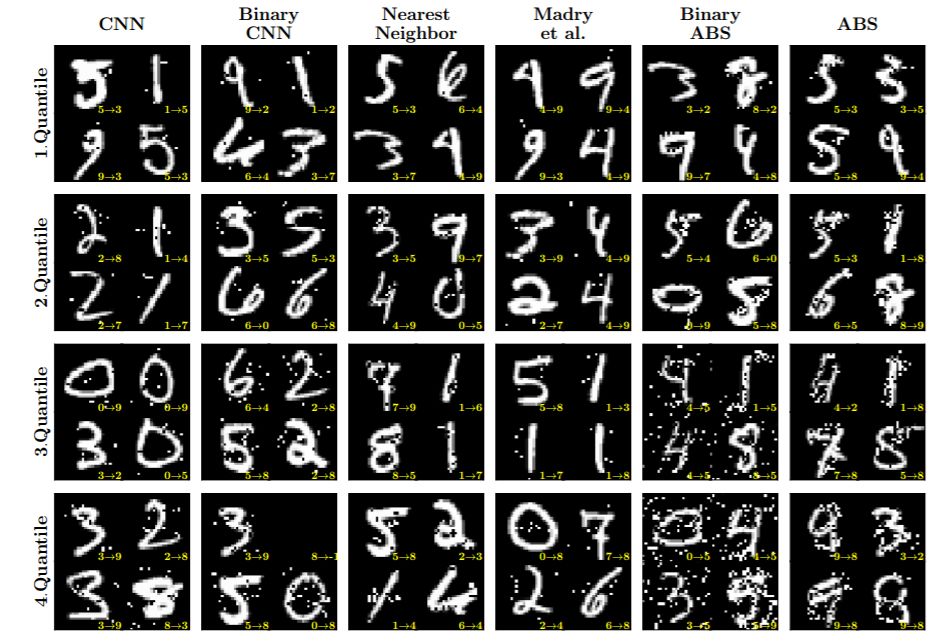
图 5:L_0 误差分位数:我们以前总是为每个模型选择任意攻击的最小化 L_0 对抗扰动。为了进行无偏差选取,我们随机地在四个误差分位数(0 − 25%、25 − 50%、50 − 75%、75 − 100%))中采样图像。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


