机器之心 & ArXiv Weekly Radiostation
本周主要论文包括奇虎360人工智能研究院和清华大学联合发布的大规模中文跨模态基准数据集 Zero,以及 Science 封面特刊的五篇 AI 帮助揭示核孔复合体结构的论文
。
-
AI-based structure prediction empowers integrative structural analysis of human nuclear pores
-
Structure of cytoplasmic ring of nuclear pore complex by integrative cryo-EM and AlphaFold
-
Quantum computational advantage with a programmable photonic processor
-
Rethinking Graph Neural Networks for Anomaly Detection
-
Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework
-
Siamese Image Modeling for Self-Supervised Vision Representation Learning
-
FlowBot3D: Learning 3D Articulation Flow to Manipulate Articulated Objects
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:AI-based structure prediction empowers integrative structural analysis of human nuclear pores
-
-
论文地址:https://www.science.org/doi/10.1126/science.abm9506
摘要:
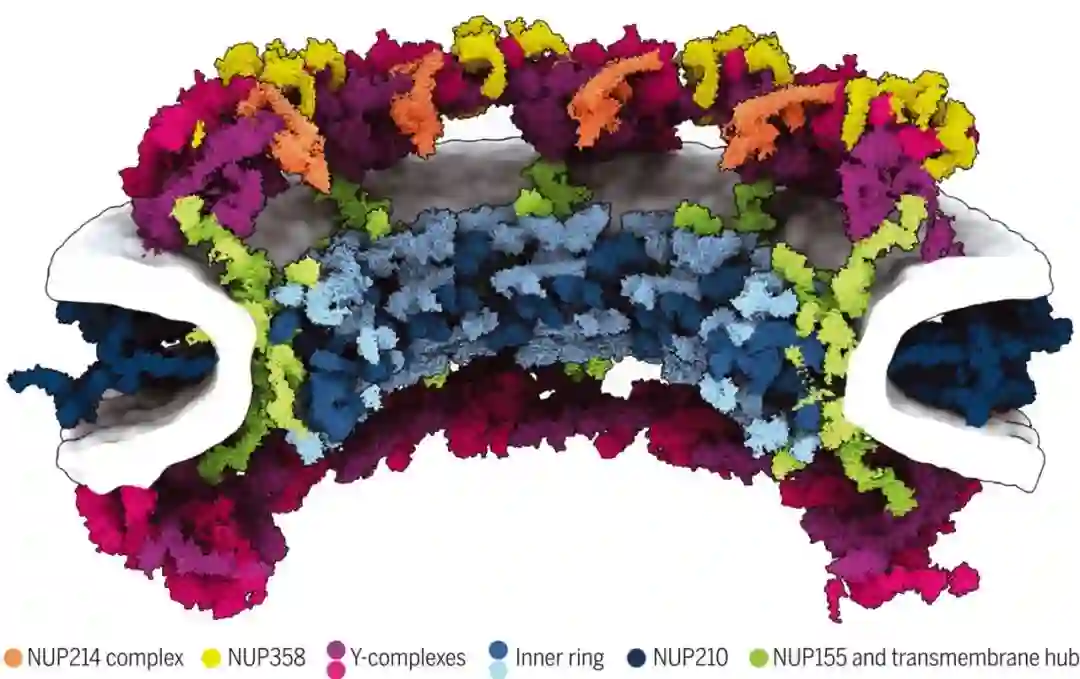
虽然核孔复合体(NPC)介导核质转运,它们错综复杂的 120 兆道尔顿架构仍未完全得到了解。马克斯・普朗克生物物理研究所等机构的研究者报告了具有显式膜和多构象状态的人类 NPC 支架的 70 兆道尔顿模型。他们将基于 AI 的结构预测与原位和细胞冷冻电子断层扫描、综合建模相结合。结果表明,接头核孔蛋白在亚复合体内和亚复合体之间组织支架,以建立高阶结构。微秒长的分子动力学模拟表明,支架不需要稳定内外核膜融合,而是扩大中心孔。他们举例阐释了如何将基于 AI 的建模与原位结构生物学相结合,以了解跨空间组织级别的亚细胞结构。
![]()
推荐:
新研究将基于 AI 的结构预测与原位和细胞冷冻电子断层扫描、综合建模相结合。
论文 2:Structure of cytoplasmic ring of nuclear pore complex by integrative cryo-EM and AlphaFold
-
-
论文地址:https://www.science.org/doi/10.1126/science.abm9326
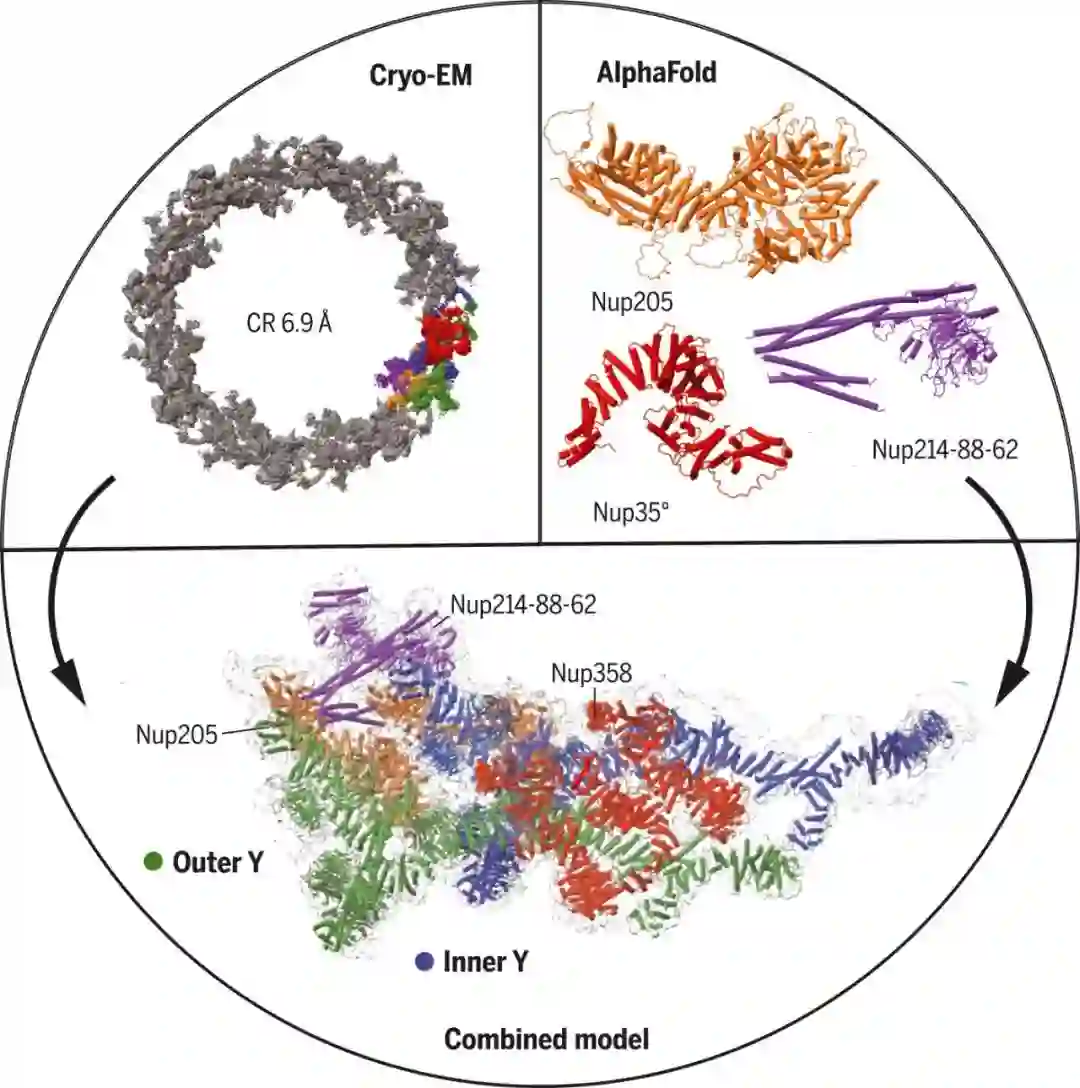
摘要:哈佛医学院等机构的研究者使用单粒子冷冻电子显微镜和 AlphaFold 预测,从非洲爪蟾卵母细胞中确定了近乎完整的 NPC 细胞质环结构。具体地,他们使用 AlphaFold 预测核孔蛋白的结构,并使用突出的二级结构密度作为指导来适应中等分辨率的地图。某些分子相互作用通过使用 AlphaFold 的复杂预测进一步得到建立或确认。
研究者确定了五份 Nup358 的结合模式,它是最大的 NPC 亚基,具有用于转运的 Phe-Gly 重复序列。他们预测 Nup358 包含一个卷曲螺旋结构域,可以提供活性以帮助它在一定条件下作为 NPC 形成的成核中心。
![]()
非洲爪蟾 NPC 细胞质环的 Cryo-EM 结构。
推荐:
研究者使用 DeepMind 的 AlphaFold 来预测核孔蛋白的结构。
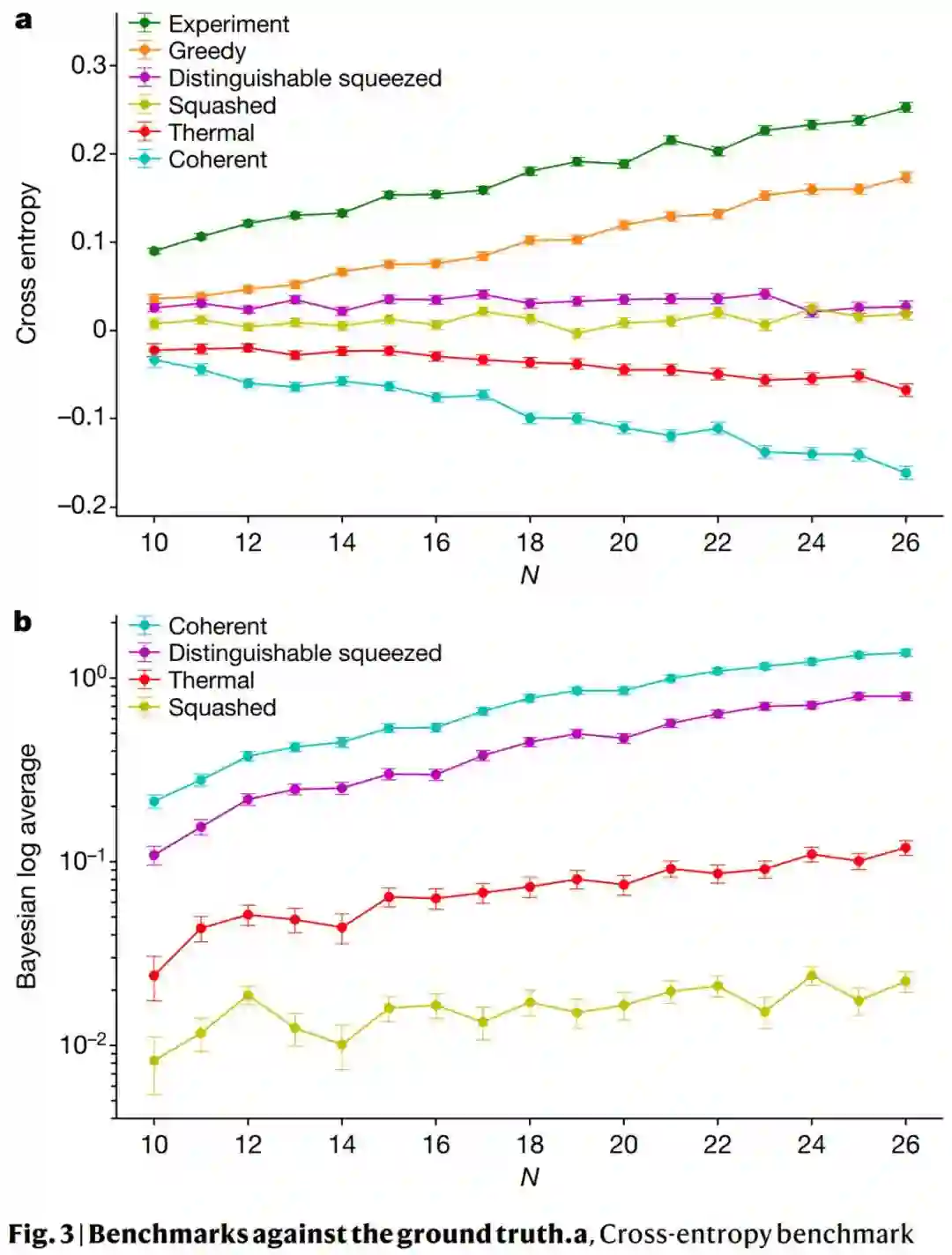
论文 3:Quantum computational advantage with a programmable photonic processor
-
-
论文地址:https://www.nature.com/articles/s41586-022-04725-x.pdf
摘要:
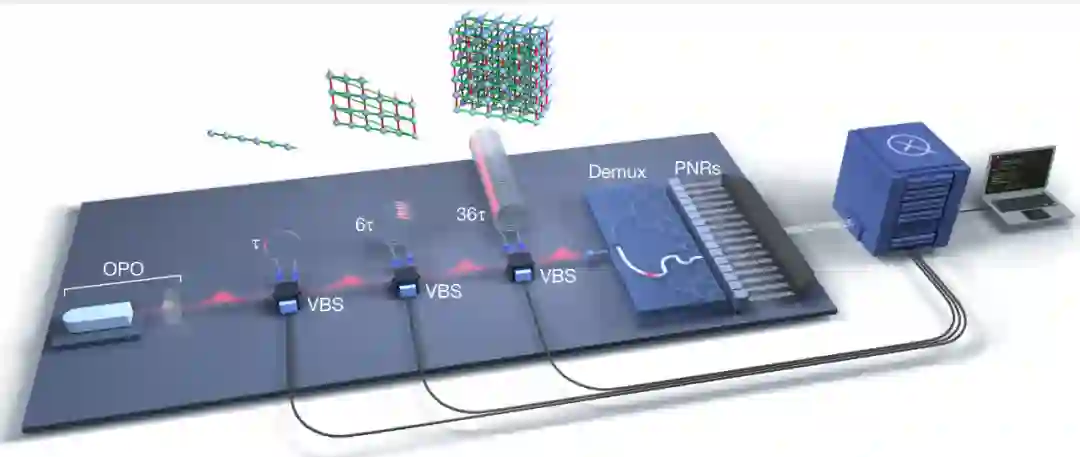
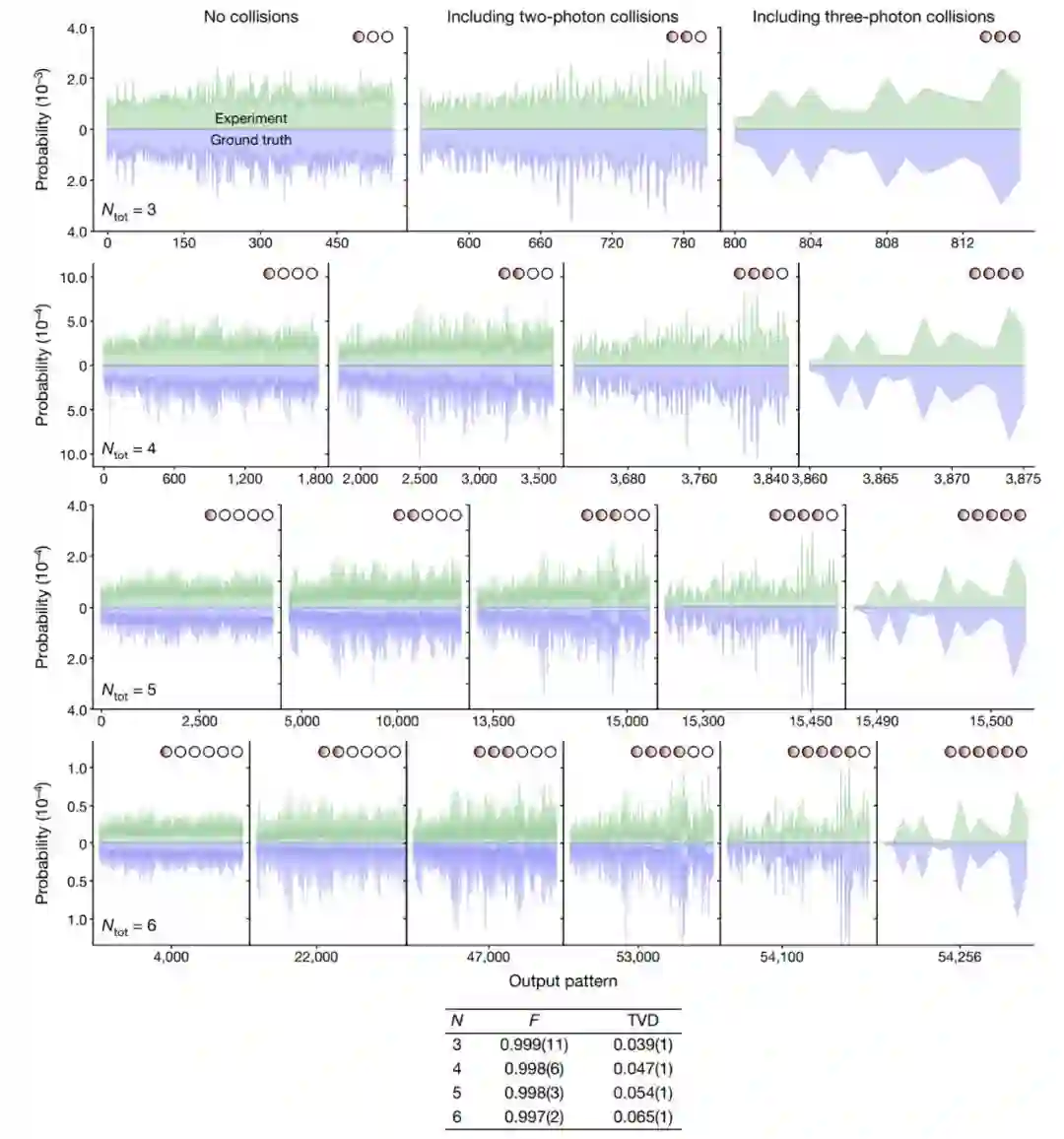
在一项新研究《可编程光子处理器的量子计算优越性》中,多伦多量子计算初创公司 Xanadu 推出了全新的设备 Borealis,它可能是第一台完全可编程的光子量子计算机。这项研究 6 月 1 日正式发表在 Nature 杂志。
在 Borealis 中,量子比特由所谓的「压缩态」构成,由光脉冲中的多个光子的叠加组成。由于量子物理学的超现实性质,传统量子比特能够以一种称为叠加的状态存在,它们可以表示数据的 0 或 1,而压缩态能够以 0、1、2、3 或更多的状态存在。它能够生成多达 216 个压缩光脉冲序列。「重要的是要认识到 Borealis 并不等同于 216 量子比特的传统设备。由于它使用压缩态的量子比特,它处理的量子任务与基于超导电路量子比特或离子阱的设备不同。」Lavoie 说。
![]()
![]()
![]()
推荐:
首台完全可编程光量子计算机面世:超过最强超算富岳 7.8 万亿倍。
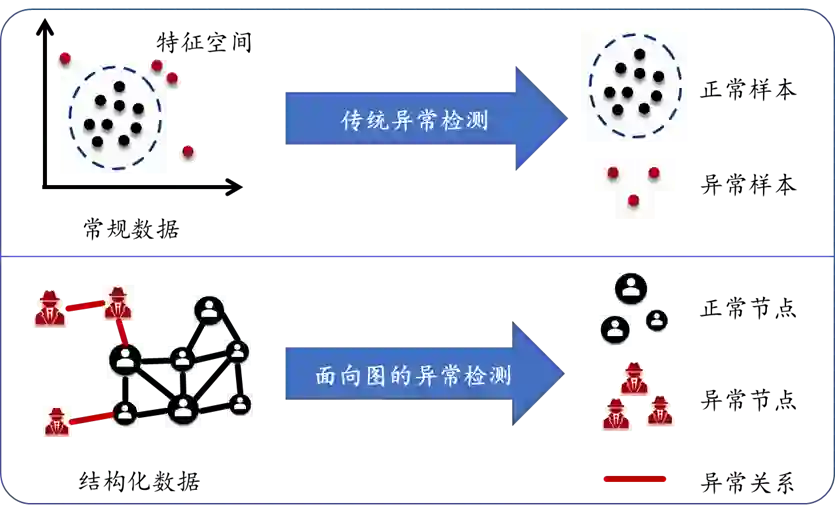
论文 4:Rethinking Graph Neural Networks for Anomaly Detection
-
-
论文地址:https://arxiv.org/pdf/2205.15508.pdf
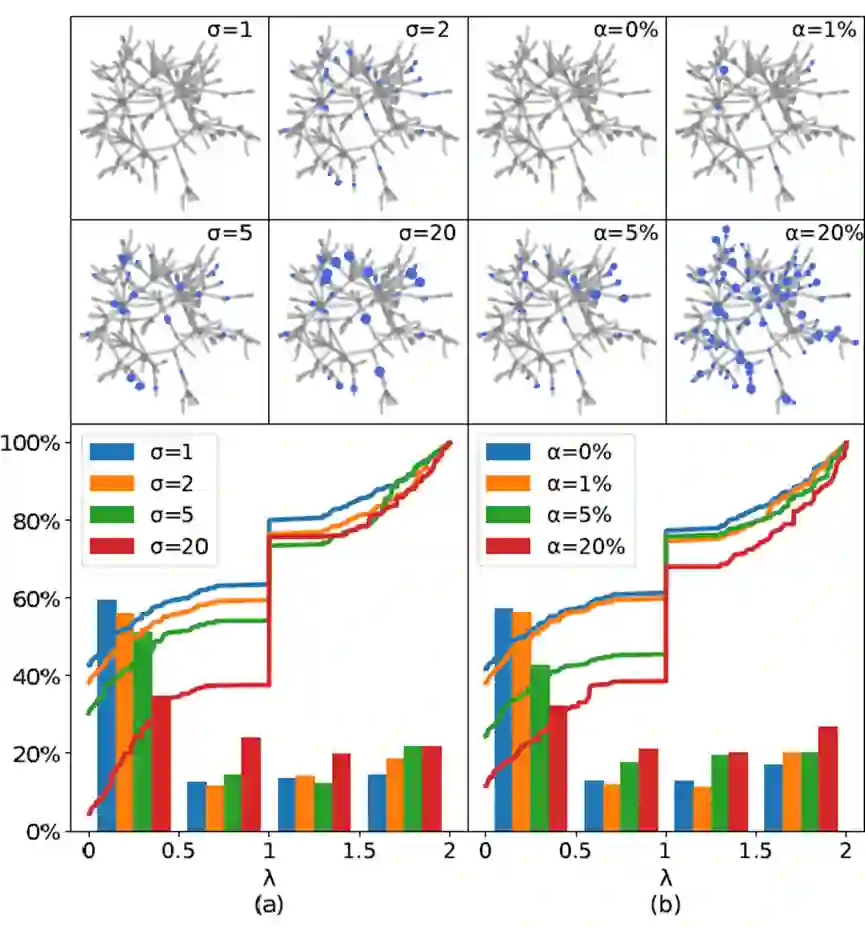
摘要:图神经网络(GNN)被广泛应用于结构化数据的异常检测,例如社交网络恶意账号检测、金融交易欺诈检测等。香港科技大学和斯坦福大学首次从谱域的角度(即图拉普拉斯矩阵的谱分解)分析了异常数据可能造成的影响。
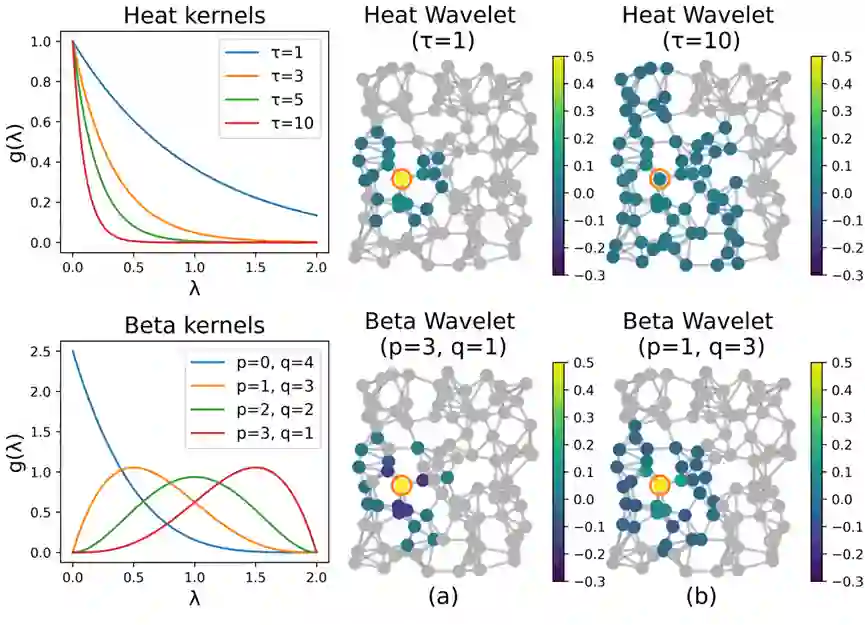
他们的核心发现是:异常数据将导致频谱能量出现 “右移” 现象,即频谱能量分布从低频向高频移动。基于这一发现,他们又提出了 Beta 小波图神经网络(BWGNN)。它拥有多个具有局部性的带通滤波器,能够更好捕获 “右移” 产生的高频异常信息。在四个大规模图异常检测数据集上,BWGNN 的性能均优于现有的模型。
![]()
![]()
![]()
热核小波与 Beta 核小波在谱域(左)和空域(右)上的对比,Beta 函数具有更好的带通与局部性质。
推荐:
基于结构化数据的异常检测再思考:我们究竟需要怎样的图神经网络?入选 ICML 2022
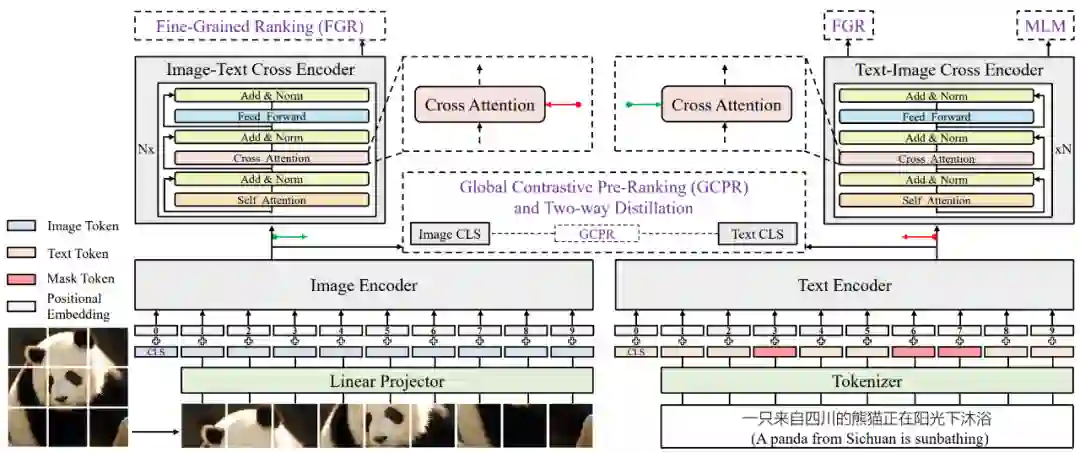
论文 5:Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework
-
-
论文地址:https://arxiv.org/pdf/2205.03860.pdf
摘要:
最近,奇虎 360 人工智能研究院和清华大学的研究者在其最新论文中重点关注了大规模视觉语言数据集和跨模态表征学习模型。研究者提出了一个大规模中文跨模态基准数据集 Zero,它包含了两个被称为 Zero-Corpus 的预训练数据集和五个下游任务数据集,一定程度上填补了中文图文跨模态领域数据集的空白。
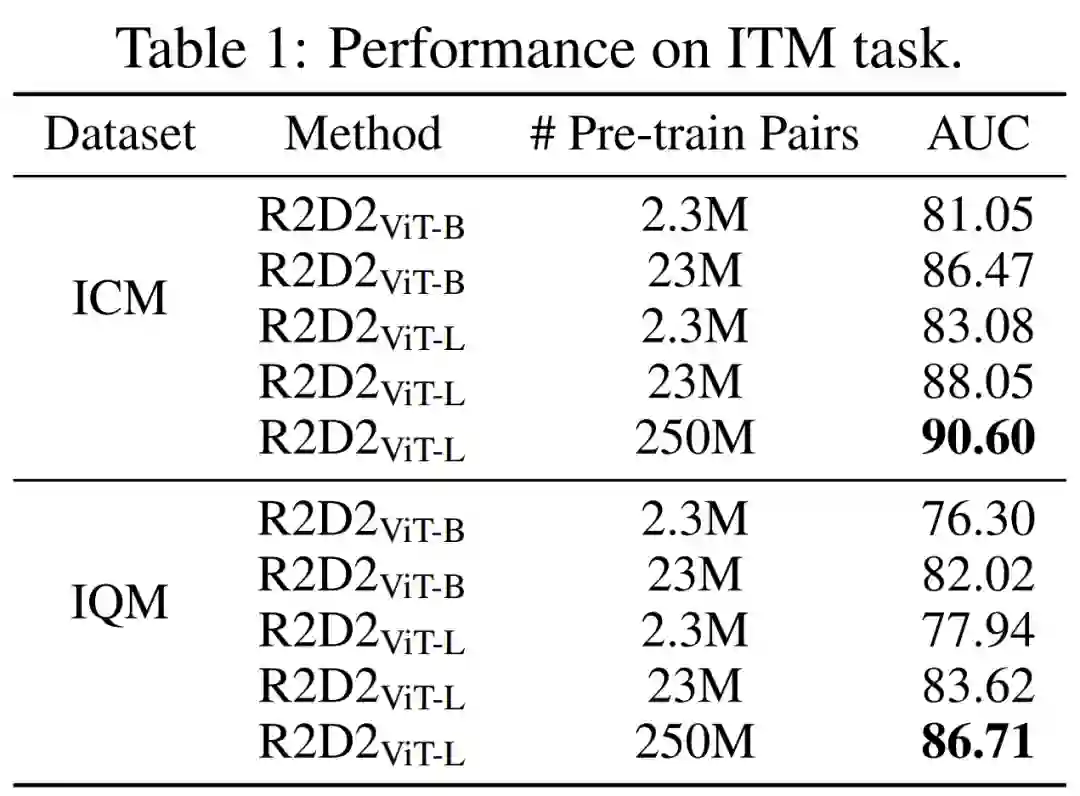
进一步,研究者们还提出了一个视觉语言预训练框架 R2D2,用于大规模跨模态学习,基于所提出的 Zero-Corpus 数据集进行预训练,并在多个下游任务上进行测试,R2D2 取得多项超越 SOTA 的结果。上述数据集和模型,均已开源。
研究者还尝试用更大的 2.5 亿内部数据集训练 R2D2 模型,相对 2300 万数据,模型效果依然有显著提升。特别是在零样本任务上,相对此前的 SOTA,在 Flickr30k-CN 数据集上,R@M 提升到 85.6%(提升了 4.7%),在 COCO-CN 数据集上,R@M 提升到 80.5%(提升了 5.4%),在 MUGE 数据集上,R@M 提升到 69.5%(提升了 6.3%)。
![]()
![]()
![]()
推荐:
从 50 亿图文中提取中文跨模态新基准 Zero,奇虎 360 全新预训练框架超越多项 SOTA。
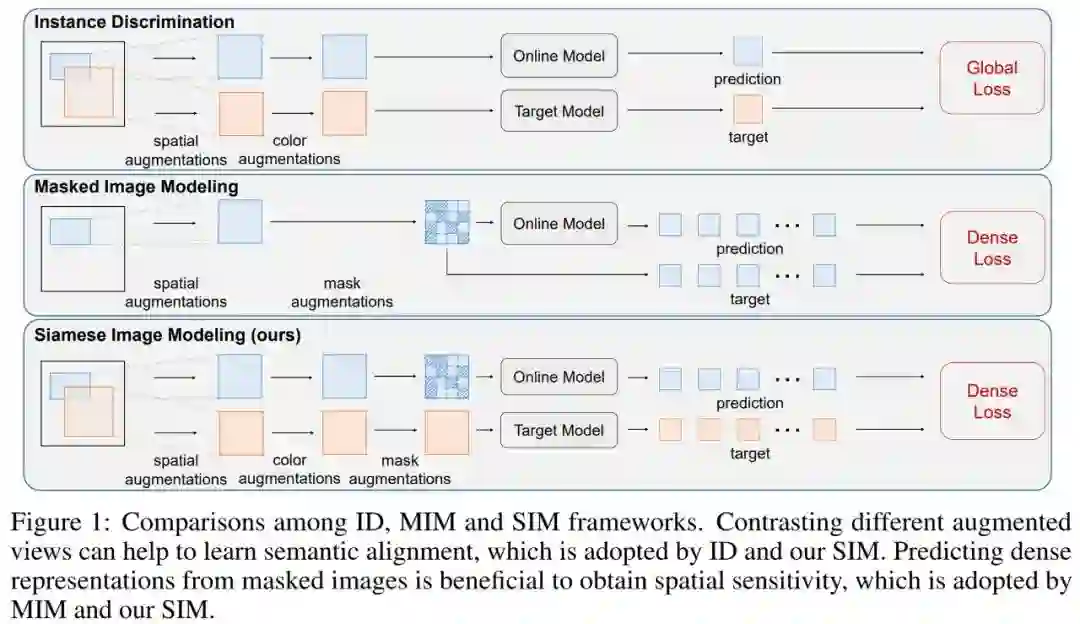
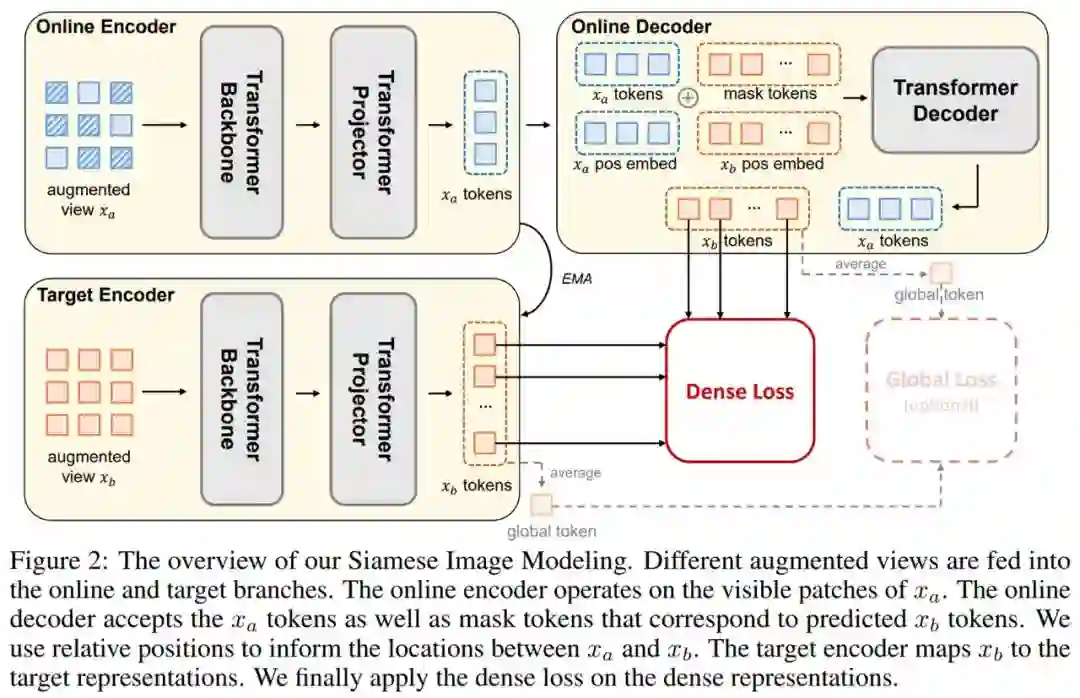
论文 6:Siamese Image Modeling for Self-Supervised Vision Representation Learning
-
-
论文地址:https://arxiv.org/abs/2206.01204
摘要:
研究者提出了 Siamese Image Modeling(SIM),该方法通过一张遮盖的增强视图来预测相同图像的另一张增强视图的密集特征表示。为了达到这个目标,SIM 采用了孪生网络结构,该结构包含 online 和 target 两个分支。Online 分支首先将第一张遮盖视图映射到特征空间,然后基于第一张图的特征和第一、二张图的相对位置坐标来预测第二张图的特征;Target 分支则负责将第二张图映射到特征空间来获得目标特征。
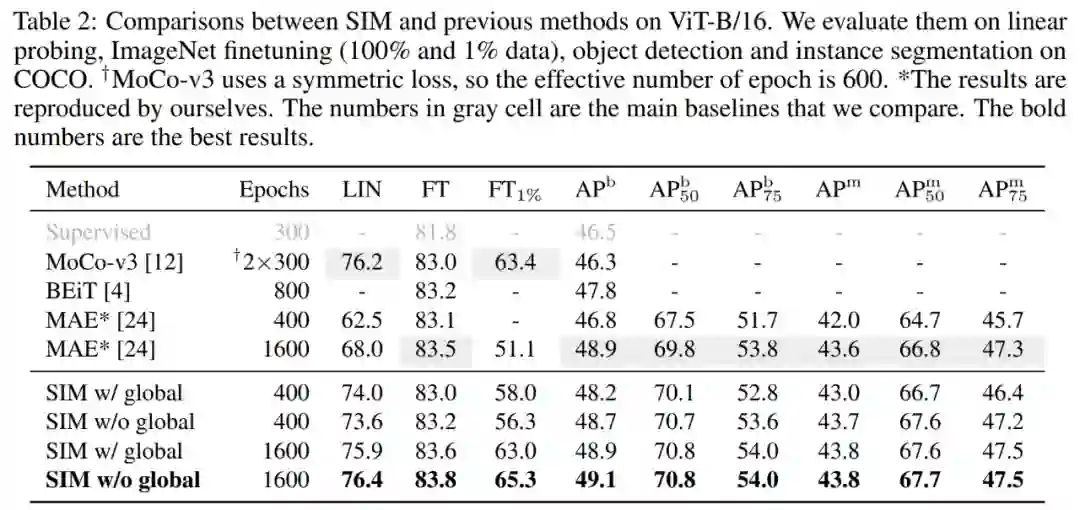
通过这种方式,SIM 能够分别在线性分类任务上和 ID 方法持平,以及在检测任务上和 MIM 方法持平,研究者进一步发现即便没有全局的损失函数,SIM 也能给出很好的线性分类表现。
![]()
![]()
Siamese Image Modeling 概览。
![]()
ViT-B/16 上 SIM 与其他方法的结果比较。
推荐:
自监督学习如何兼顾语义对齐与空间分辨能力?清华、商汤提出「SIM」方法。
论文 7:FlowBot3D: Learning 3D Articulation Flow to Manipulate Articulated Objects
-
-
论文地址:https://arxiv.org/pdf/2205.04382.pdf
摘要:
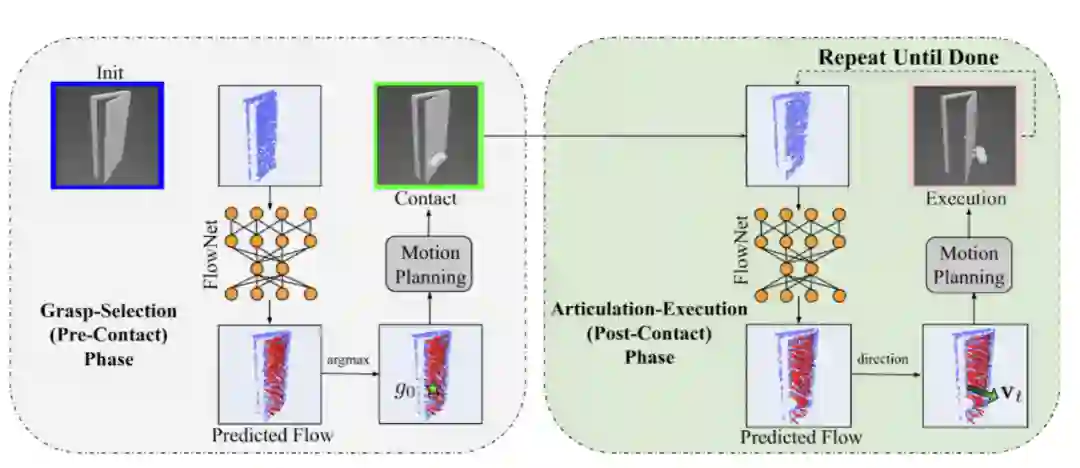
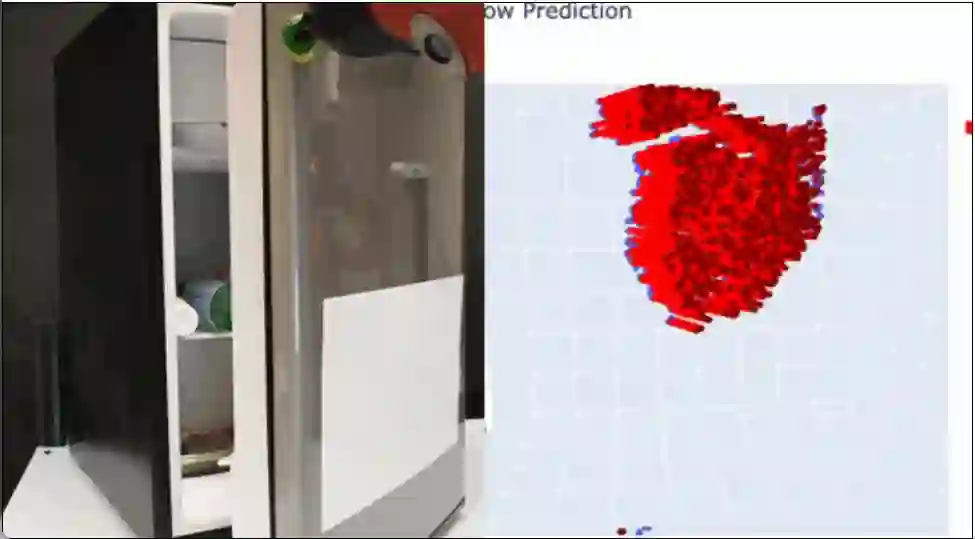
最近,CMU 机器人学院 David Held 教授 R-PAD 实验室的两名学生 Ben Eisner 和 Harry Zhang 在操纵复杂的关节物体方面取得了突破,并推出了基于 3D 神经网络的 FlowBot 3D,一种有效表达和预测关节物体部分运动轨迹的算法,如日常家具。该算法包含两个部分。
第一个部分是感知部分,这个部分使用 3D 深度神经网络从被操纵家具物体的点云数据中预测三维瞬时运动轨迹。算法的第二个部分是策略部分,它使用预测得到的 3D Articulated Flow 来选择机器人的下一个动作。
两者都在模拟器中完全学习,可以直接在现实世界中实现,无需重新训练或调整。在 FlowBot 3D 算法的帮助下,机器人可以像人类一样随意操纵日常家具等关节物体。
![]()
![]()
![]()
推荐:
CMU 发表新型灵巧机器人算法,准确学习日常家具的操纵方法。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Unsupervised Key Event Detection from Massive Text Corpora. (from Jiawei Han)
2. Beyond Opinion Mining: Summarizing Opinions of Customer Reviews. (from Bing Liu)
3. Words are all you need? Capturing human sensory similarity with textual descriptors. (from Thomas L. Griffiths)
4. Face-Dubbing++: Lip-Synchronous, Voice Preserving Translation of Videos. (from Alexander Waibel)
5. Plumber: A Modular Framework to Create Information Extraction Pipelines. (from Sören Auer)
6. LegoNN: Building Modular Encoder-Decoder Models. (from Abdelrahman Mohamed)
7. Latent Topology Induction for Understanding Contextualized Representations. (from Mirella Lapata)
8. Annotation Error Detection: Analyzing the Past and Present for a More Coherent Future. (from Bonnie Webber)
9. Topic-Aware Evaluation and Transformer Methods for Topic-Controllable Summarization. (from Grigorios Tsoumakas)
10. Factuality Enhanced Language Models for Open-Ended Text Generation. (from Bryan Catanzaro)
1. PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images. (from Xiangyu Zhang, Jian Sun)
2. Revisiting the "Video" in Video-Language Understanding. (from Li Fei-Fei)
3. PrivHAR: Recognizing Human Actions From Privacy-preserving Lens. (from Li Fei-Fei)
4. Compositional Visual Generation with Composable Diffusion Models. (from Antonio Torralba, Joshua B. Tenenbaum)
5. Polymorphic-GAN: Generating Aligned Samples across Multiple Domains with Learned Morph Maps. (from Antonio Torralba)
6. Towards Fast Adaptation of Pretrained Contrastive Models for Multi-channel Video-Language Retrieval. (from Shih-Fu Chang)
7. Beyond RGB: Scene-Property Synthesis with Neural Radiance Fields. (from Martial Hebert)
8. Generating Long Videos of Dynamic Scenes. (from Alexei A. Efros)
9. STIP: A SpatioTemporal Information-Preserving and Perception-Augmented Model for High-Resolution Video Prediction. (from Wen Gao)
10. Hierarchical Similarity Learning for Aliasing Suppression Image Super-Resolution. (from Wen Gao)
1. Schema-Guided Event Graph Completion. (from Jiawei Han)
2. BaCaDI: Bayesian Causal Discovery with Unknown Interventions. (from Bernhard Schölkopf, Andreas Krause)
3. Causal Discovery in Heterogeneous Environments Under the Sparse Mechanism Shift Hypothesis. (from Bernhard Schölkopf)
4. Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination. (from Philip S. Yu)
5. DORA: Exploring outlier representations in Deep Neural Networks. (from Klaus-Robert Müller)
6. Imitating Past Successes can be Very Suboptimal. (from Sergey Levine, Ruslan Salakhutdinov)
7. Towards Understanding Why Mask-Reconstruction Pretraining Helps in Downstream Tasks. (from Shuicheng Yan)
8. From "Where" to "What": Towards Human-Understandable Explanations through Concept Relevance Propagation. (from Thomas Wiegand)
9. Expressiveness and Learnability: A Unifying View for Evaluating Self-Supervised Learning. (from Aaron Courville)
10. Beyond Tabula Rasa: Reincarnating Reinforcement Learning. (from Aaron Courville, Marc G. Bellemare)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com