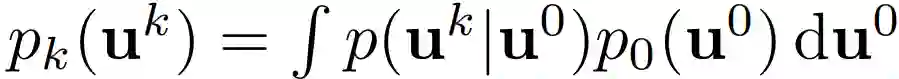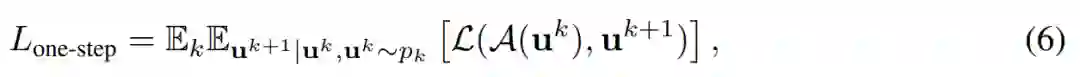机器之心 & ArXiv Weekly Radiostation
本周论文包括:哈佛大学和埃默里大学的科学家研发的一种「合成鱼」装置,登上了顶级学术期刊《Science》;索尼 AI 赛车手登上 Nature 封面等研究。
An autonomously swimming biohybrid fish designed with human cardiac biophysics
A Model-Agnostic Causal Learning Framework for Recommendation using Search Data
Outracing champion Gran Turismo drivers with deep reinforcement learning
On Neural Differential Equations
SLIP: Self-supervision meets Language-Image Pre-training
MESSAGE PASSING NEURAL PDE SOLVERS
pNLP-Mixer: an Efficient all-MLP Architecture for Language
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:An autonomously swimming biohybrid fish designed with human cardiac biophysics
摘要:
这是由哈佛大学和埃默里大学的科学家研发的一种「合成鱼」装置,是由活的心肌细胞(由人类干细胞培育而成)组成的,它可以持续游动 100 天以上。研究登上了顶级学术期刊《Science》。
这条合成鱼的创造基于人体心脏的两个关键调节特征:(1) 心脏自发发挥作用,无需有意识的输入(自动性);(2) 由机械运动(机械电信号)发起的信息传递。
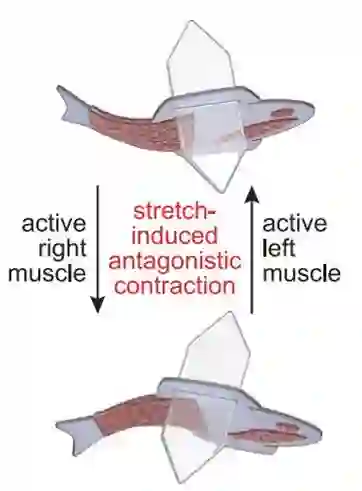
在设计上,一方面,这条鱼有双层肌细胞,尾鳍两侧各有一层。当一侧收缩时,另一侧伸展,这使得对机械运动敏感的离子通道打开,导致带电离子流入并在该侧收缩。整体而言,该鱼是由 73000 个活体心肌细胞(cardio myocyte, CM)组成,水凝胶纸复合体总长为 14 毫米,总质量为 25.0 毫克,包括 0.36 毫克肌肉质量。
![]()
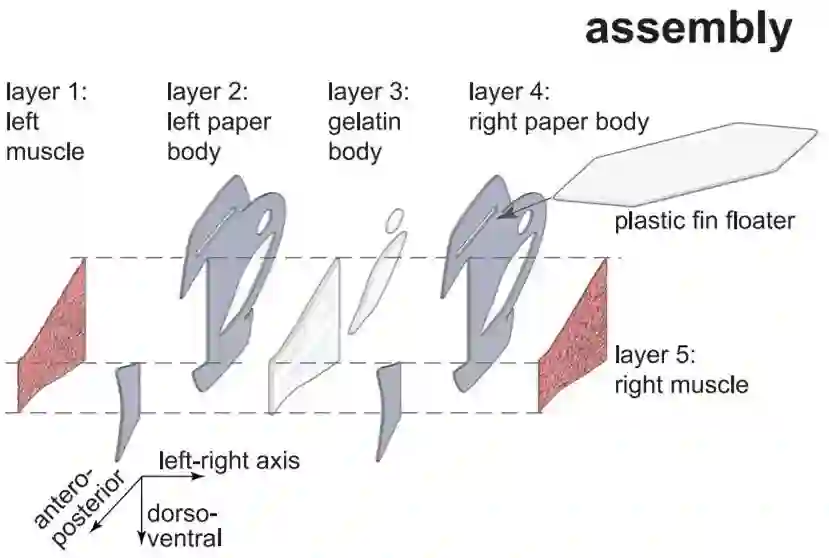
下图详细展示了这条鱼的五层(five-layered)身体结构。当鱼鳍一侧收缩时,另一侧伸展,形成了一个自我维持的游泳运动。
![]()
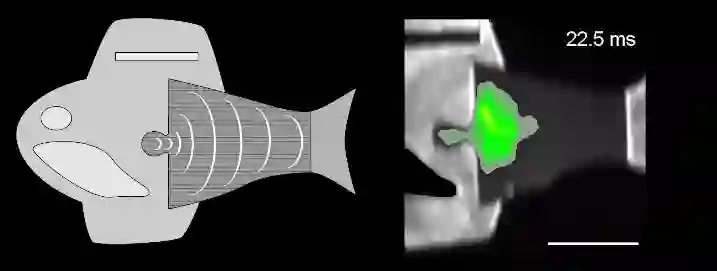
另一方面,研究者还设计了一个「自主起搏节点」(autonomous pacing node),他们称为 G-node,它就像普通的起搏器一样,控制自主收缩的频率和节奏。两层肌肉和自主起搏节点一起能够产生连续、自发和协调的来回鳍运动,从而可以驱动这条鱼游动超过 100 天。
![]()
推荐:
用人类心脏细胞造机器鱼,游泳速度比真鱼还快,哈佛新研究登上 Science。
论文 2:A Model-Agnostic Causal Learning Framework for Recommendation using Search Data
摘要:
快手和人大的研究者提出了一个模型无关的因果学习框架,该框架被称作 IV4Rec,用来有效地分离出这两种关系,从而加强推荐模型的效果。更确切地说,研究者联合考虑了搜索场景和推荐场景下的用户行为。通过借鉴因果推断中的概念,他们将用户的搜索行为作为工具变量(Instrumental variables, IVs),来帮助分解原本推荐中 embedding,即 treatments。然后使用深度神经网络将分离的两个部分结合起来,用结合后的结果来完成推荐任务。
IV4Rec 是一个模型无关的框架,它可以应用到众多推荐模型中,比如 NRHUB 和 DIN。在公开数据集 MIND 和快手短视频数据集上的实验结果表明,IV4Rec 可以有效地提升推荐模型的效果,该技术已经申请中国发明专利。
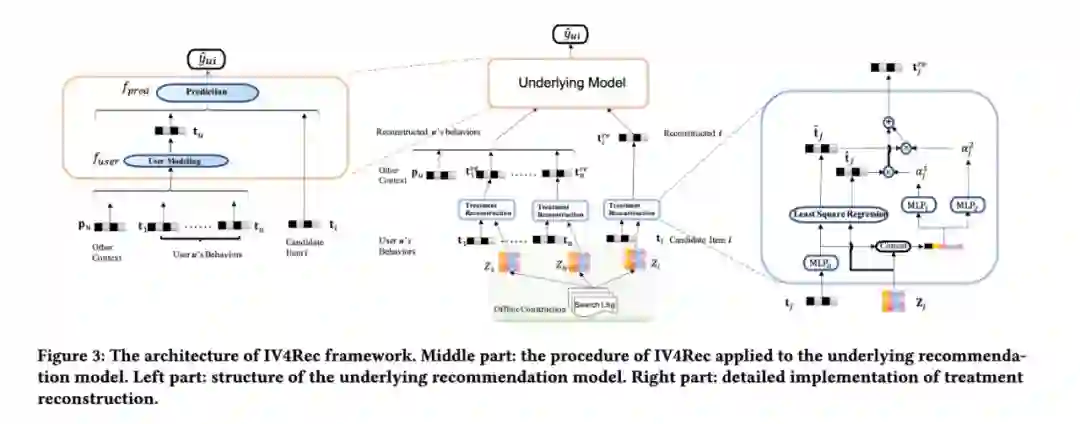
该方法主要分为三个部分:A. 构造 treatment (T)和 Instrumental Variables (IVs),B. 重构 treatment,C. 将重构的 treatment 应用到推荐模型。
![]()
研究者提出的 IV4Rec 框架可以应用在所有符合 underlying model 结构的模型上,只需要简单地在 item embedding layer 后加入 treatment reconstruction module。重构的用户表示是通过其浏览历史中的物品的重构向量得到的,再利用重构出的用户和候选物品向量,便可以得到更加精确的预测值。
推荐:
将因果关系估计引入推荐系统、提升推荐模型效果,快手新研究被 WWW22 接收。
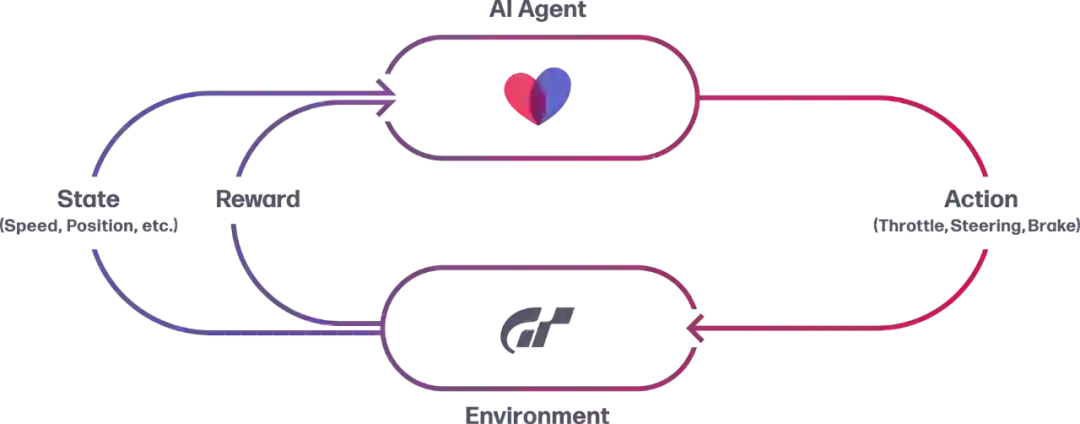
论文 3:Outracing champion Gran Turismo drivers with deep reinforcement learning
摘要:
今日索尼宣布,其研究人员已经开发出一款名为「 GT Sophy」的 AI 驱动程序,其能够在 GT 赛车运动中连续几圈击败人类顶级电子竞技赛车手。相关论文登上 Nature 封面。
GT Sophy 使用一种称为强化学习的方法进行训练:本质上是一种试错形式,其中 AI 智能体被扔到一个没有指令的环境中,并因达到某些目标而获得奖励。在 GT Sophy 的案例中,索尼的研究人员表示,他们必须非常谨慎地设计这种奖励:例如,微调碰撞惩罚,以塑造一种足够强悍的驾驶风格,从而赢得胜利,但这并不会导致 AI 粗暴地将其他赛车赶出道路。
使用强化学习,GT Sophy 只需几个小时的训练就能在赛道上行驶,并且在一两天的时间内就能超越训练数据集中 95% 的车手比赛。经过大约 45,000 小时的全部训练,GT Sophy 能够在三个赛道上取得超人的表现。
GT Sophy 的输入被限制在 10Hz,而人类的理论最大输入是 60Hz。索尼表示这导致人类驾驶员在高速行驶时表现出更加流畅的动作。在反应时间方面,GT Sophy 能够在 23-30 毫秒内对比赛环境中的事件做出反应,这比职业运动员的 200-250 毫秒的最高反应时间要快得多。作为补偿,研究人员添加了人工延迟,以 100 毫秒、200 毫秒和 250 毫秒的反应时间训练 GT Sophy。但正如他们发现的那样:所有这三项测试都达到了超越人类水平的单圈时间。
GT Sophy 与三位顶级电子竞技车手进行了测试:Emily Jones、Valerio Gallo 和 Igor Fraga。尽管没有一位车手能够在计时赛中击败 AI,但比赛让他们发现了新的战术。索尼表示目前他们正在努力将 GT Sophy 整合到未来的 Gran Turismo 游戏中,但还没有明确的时间点。
超现实模拟器
新型强化学习技术
分布式训练平台
大规模训练基础设施
![]()
![]()
推荐:
弯道极限超车、击败人类顶级玩家,索尼 AI 赛车手登上 Nature 封面。
论文 4:On Neural Differential Equations
摘要:
近日,一篇专门探讨神经微分方程的博士论文《 On Neural Differential Equations》吸引了领域内研究者的注意,谷歌 AI 负责人、知名学者 Jeff Dean 也点赞推荐。这篇论文的 examiner 甚至褒赞它为「神经微分方程的教科书」。
论文作者为牛津大学数学研究所的博士生 Patrick Kidger,他的主要研究兴趣在于神经微分方程以及更广泛的深度学习和时间序列。他希望这篇论文可以吸引到任何对深度学习与动力学系统结合感兴趣的读者,并希望为当前的 SOTA 研究提供有益的参考。
神经常微分方程(neural ordinary diffeqs):用于学习物理系统,作为离散架构的连续时间限制,包括对可表达性的理论结果;
神经受控微分方程(neural controlled diffeqs):用于建模时间序列函数、处理不规则数据;
神经随机微分方程(neural stochastic diffeqs):用于从复杂的高维随机动态中采样;
数值法(numerical methods):一类新的可逆微分方程求解器或布朗重建(Brownian reconstruction)问题。
此外,这篇论文还涉及了其他一些主题,比如用于动力学系统的符号回归(如通过正则化演化)、深度隐式模型(如深度均衡模型、可微优化)。
在回答网友的提问「为什么神经微分方程如此重要」时,作者表示,「神经微分方程将当前使用的两种主流建模方法——神经网络和微分方程结合在一起,为我们提供了很多在神经网络和微分方程中使用得很好的理论,并在物理、金融、时间序列和生成建模等领域获得了直接的实际应用。」
推荐:
被誉为「教科书」,牛津大学 231 页博士论文全面阐述神经微分方程。
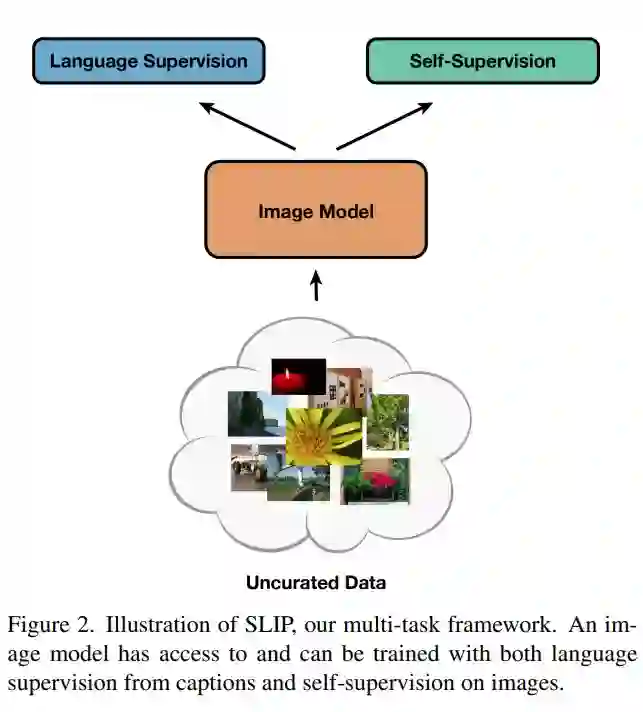
论文 5:SLIP: Self-supervision meets Language-Image Pre-training
摘要:
近日,为了探究对图像进行自监督学习的势头是否会进入语言监督领域,来自加州大学伯克利分校和 Facebook AI 研究院的研究者调查了 CLIP 形式的语言监督是否也受益于图像自监督。该研究注意到,将两种训练目标结合是否会让性能更强目前尚不清楚,但这两个目标都要求模型对有关图像的质量不同且相互矛盾的信息进行编码,因而会导致干扰。
为了探索这些问题,该研究提出了一种结合语言监督和自监督的多任务框架 SLIP(Self-supervision meet Language-Image Pre-training),并在 YFCC100M 的一个子集上预训练各种 SLIP 模型,又在三种不同的设置下评估了表征质量:零样本迁移、线性分类和端到端微调。除了一组 25 个分类基准之外,该研究还在 ImageNet 数据集上评估了下游任务的性能。
该研究通过对不同模型大小、训练计划和预训练数据集进行实验进一步了验证了其发现。研究结果最终表明,SLIP 在大多数评估测试中都显著提高了性能,这表明在语言监督背景下自监督具有普遍效用。此外,研究者更详细地分析了该方法的各个组成部分,例如预训练数据集和数据处理方法的选择,并讨论了此类方法的评估局限性。
![]()
下图算法 1 概述了用于自监督的 SLIP-SimCLR。
![]()
论文 6:MESSAGE PASSING NEURAL PDE SOLVERS
摘要:
近日,阿姆斯特丹大学、高通 AI 研究院的三位研究者在论文《Message Passing Neural PDE Solvers》中提出使用端到端神经求解器来从数值上求解 PDE。
提出一个基于神经消息传递(message passing, MP)的端到端全神经 PDE 求解器,其灵活性能够满足典型 PDE 问题的所有结构需求。这一设计的灵感来源于一些经典求解器(有限差分、有限体积和 WENO 格式)可以作为消息传递的特例;
提出时间捆绑(temporal bundling)和前推(pushforward)技巧,以在训练自回归模型中鼓励零稳定性(zerostability);
在给定类中实现跨多个 PDE 的泛化。在测试期间,新的 PDE 稀疏可以成为求解器的输入。
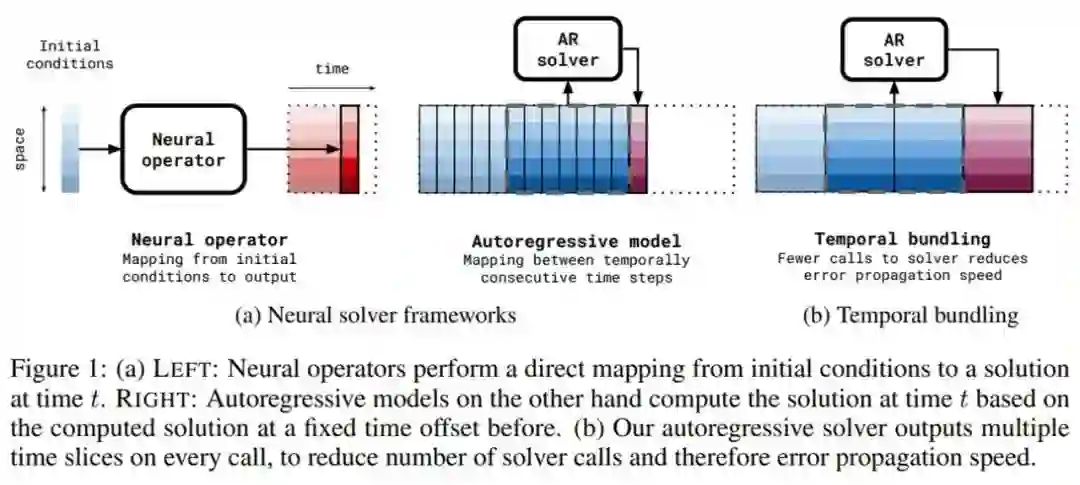
研究者基于最近该领域令人兴奋的工作进展来学习 PDE 求解器。这些神经 PDE 求解器的背后离不开这一快速发展且有影响力的研究领域。用于时间 PDE 的神经 PDE 求解器可以分为两大类,分别为自回归方法和神经算子方法,具体如下图 1a 所示。
![]()
研究者通过两部分详细描述了他们的方法,即训练框架和架构。其中训练框架解决自回归求解器中的分布位移问题,该问题会导致不稳定性;网络架构是一个消息传递神经网络。
自回归求解器将解 u^k 映射到因果后续(causally consequent)解 u^k+1。一种直接的训练方法是单步训练。如果 p_0(u^0 ) 在训练集中是初始条件的分布,则
![]()
是迭代为 k 时的真值分布。研究者最小化如下公式(6)
![]()
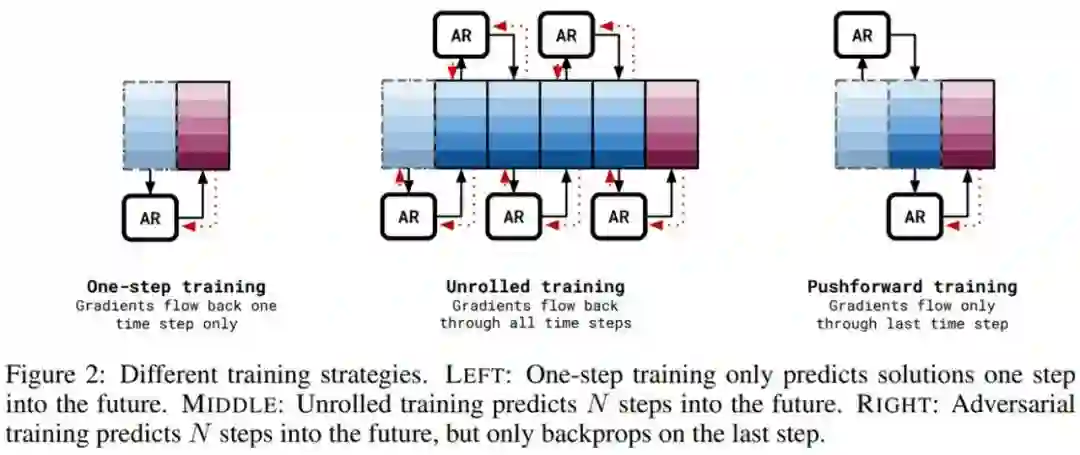
下图 2 为不同的训练策略。图左为单步训练,只能预测接下来一步的解;图中为展开(unrolled)训练,可以预测接下来 N 步的解;图右为对抗性训练,可以预测接下来 N 步的解,但只能在最后一步反向传播。
![]()
推荐:
ML 大牛 Max Welling 等用全神经求解器做到了更强、更快。
论文 7:pNLP-Mixer: an Efficient all-MLP Architecture for Language
摘要:
去年来自谷歌大脑的研究团队在网络架构设计方面挖出新坑,提出 MLP-Mixer。该架构无需卷积、注意力机制,仅需 MLP 即可达到与 CNN、Transformer 相媲美的性能。
时隔半年之久,来自 IBM Research 的研究团队提出 pNLP-Mixer,将 MLP-Mixer 应用于 NLP 任务,而不是谷歌的 CV 任务。
大型预训练语言模型极大地改变了自然语言处理(NLP)的格局。如今,它们成为处理各种 NLP 任务的首选框架,即使在有限数量的注释之下。但是,由于内存占用和推理成本,在生产环境中使用这些模型(无论是在云环境还是在边缘环境)仍然是一个挑战。
研究者开始提出可替代方案,他们最近对高效 NLP 的研究表明,小型权重高效(small weight-efficient)模型可以以很小的成本达到具有竞争力的性能。近日,来自 IBM Research 的研究者提出了 pNLP-Mixer,这是一种可用于 NLP 任务的基于投影(projection)的 MLP-Mixer 模型,它通过一个新颖的投影层(projection layer)实现了高权重效率。
该研究在两个多语言语义分析数据集 MTOP 和 multiATIS 上对模型进行评估。结果表明,在 MTOP 上,pNLP-Mixer 达到了与 mBERT 相媲美的性能,而后者有 38 倍多的参数,此外,pNLP-Mixer 还优于小模型 pQRNN,而前者参数少了 3 倍。在长序列分类任务中,pNLP-Mixer 在没有进行预训练的情况下比 RoBERTa 表现更好,后者的参数是 pNLP-Mixer 的 100 倍。
pNLP-Mixer 是从头开始设计的,可以适用于两种边缘情况,即内存和延迟受限,并作为 NLP pipeline 的主干而存在。
![]()
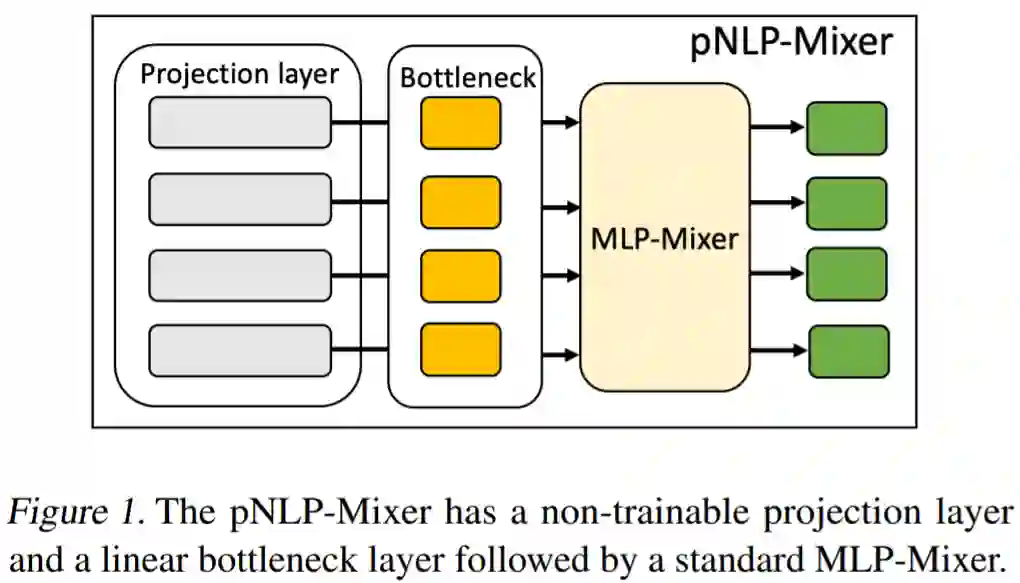
图 1 描述了高层模型架构,pNLP-Mixer 属于基于投影的模型:它不是基于 transformer 模型那样的可以存储大型嵌入表,而是使用投影层,该投影层使用不可训练的哈希函数从单个 token 中捕获形态学(也就是词法)知识。这个投影层可以被看作是从输入文本中生成表示的特征提取器。一旦输入特征被计算出来,它们就会被送入一个称为瓶颈层(bottleneck layer)的可训练线性层。其中瓶颈层的输出是标准 MLP- mixer 架构的一系列 MLP 块的输入。
使用全 MLP 架构进行语言处理具有以下优点。与基于注意力的模型相比,MLP-Mixer 可以捕获长距离依赖关系,而不会在序列长度上引入二次成本。此外,仅使用 MLP,模型不仅实现起来简单,而且在从手机到服务器级推理加速器的各种设备中都具有开箱即用的硬件加速功能。
这项研究表明,在 NLP 任务中,像 MLP-Mixer 这样的简单模型可以作为基于 transformer 模型的有效替代方案,即使在不使用大型嵌入表的环境中也是如此。这其中的关键是模型提供了高质量的输入特征。
![]()
推荐:
继 MLP-Mixer 应用于 CV 之后,又应用于 NLP 任务。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. TaxoEnrich: Self-Supervised Taxonomy Completion via Structure-Semantic Representations. (from Jiawei Han)
2. Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. (from Jiawei Han)
3. Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations. (from Jiawei Han)
4. Zero-Shot Aspect-Based Sentiment Analysis. (from Bing Liu)
5. Evaluating natural language processing models with generalization metrics that do not need access to any training or testing data. (from Kannan Ramchandran, Michael W. Mahoney)
6. Cross-Platform Difference in Facebook and Text Messages Language Use: Illustrated by Depression Diagnosis. (from Lyle Ungar)
7. AdaPrompt: Adaptive Model Training for Prompt-based NLP. (from Yang Liu)
8. No Parameters Left Behind: Sensitivity Guided Adaptive Learning Rate for Training Large Transformer Models. (from Jianfeng Gao)
9. Interactive Mobile App Navigation with Uncertain or Under-specified Natural Language Commands. (from Kate Saenko)
10. LEAPMood: Light and Efficient Architecture to Predict Mood with Genetic Algorithm driven Hyperparameter Tuning. (from Sumit Kumar)
本周 10 篇 CV 精选论文是:
1. Learning with Neighbor Consistency for Noisy Labels. (from Cordelia Schmid)
2. MaskGIT: Masked Generative Image Transformer. (from Ce Liu, William T. Freeman)
3. Residual Aligned: Gradient Optimization for Non-Negative Image Synthesis. (from Serge Belongie)
4. Advances in MetaDL: AAAI 2021 challenge and workshop. (from Isabelle Guyon)
5. Point-Level Region Contrast for Object Detection Pre-Training. (from Alan Yuille, Alexander C. Berg)
6. Causal Scene BERT: Improving object detection by searching for challenging groups of data. (from Kyunghyun Cho)
7. FEAT: Face Editing with Attention. (from Daniel Cohen-Or)
8. Self-Conditioned Generative Adversarial Networks for Image Editing. (from Daniel Cohen-Or)
9. Ada-NETS: Face Clustering via Adaptive Neighbour Discovery in the Structure Space. (from Ming Lin)
10. GiraffeDet: A Heavy-Neck Paradigm for Object Detection. (from Ming Lin)
本周 10 篇 ML 精选论文是:
1. Image-to-Image Regression with Distribution-Free Uncertainty Quantification and Applications in Imaging. (from Jitendra Malik)
2. Conformal prediction for the design problem. (from Michael I. Jordan)
3. Transferred Q-learning. (from Michael I. Jordan)
4. Reward-Respecting Subtasks for Model-Based Reinforcement Learning. (from Richard S. Sutton)
5. Robust Hybrid Learning With Expert Augmentation. (from Guillermo Sapiro)
6. Evaluation Methods and Measures for Causal Learning Algorithms. (from Huan Liu)
7. LTU Attacker for Membership Inference. (from Isabelle Guyon)
8. Hidden Heterogeneity: When to Choose Similarity-Based Calibration. (from Thomas G. Dietterich)
9. Predicting Human Similarity Judgments Using Large Language Models. (from Thomas L. Griffiths)
10. Can Humans Do Less-Than-One-Shot Learning?. (from Thomas L. Griffiths)
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com