【泡泡图灵智库】单一RGBD图像的深层次深度信息修复
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Deep Depth Completion of a Single RGB-D Image
作者:Yinda Zhang
来源:arXiv cs:CV
播音员:申影
编译:张国强
审核:Reality
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——单一RGB-D图像的深层次深度信息完善,该文章发表于arXiv cs:CV 2018。
本文的工作目标是完成RGB-D图像的深度通道。商品级深度摄像机通常无法感知有光泽,明亮,透明和远处表面的深度。为了解决这个问题,我们训练一个深度网络,将RGB图像作为输入,并预测稠密表面的法线和遮挡边界。然后将这些预测与由RGB-D相机提供的原始深度观测相结合,以求解所有像素的深度,包括原始观测中缺失的那些像素。作为使用新的深度完成基准数据集进行大量实验的结果,该方法被选择为其他方法(例如直接修补深度),其中通过渲染由多视图RGB-D扫描创建的表面重建来填充训练数据中的空洞。不同网络输入,深度表示,损失函数,优化方法,修补方法和深度估计网络的实验表明,我们提出的方法提供了比这些替代方案更好的深度完成。
介绍
深度感应已经广泛应用于自动驾驶,增强现实和场景重建等各种应用中。 尽管近期深度感应技术有所进步,但当表面光滑,明亮,薄弱,靠近或远离相机时,微软Kinect,英特尔实感和Google Tango等商品RGB-D相机仍会产生缺失数据的深度图像。 这些当房间很大,表面光亮且照明强度很大时(例如,在博物馆,医院,教室,商店等等),问题就会出现。即使在家中,深度图像通常也缺少超过50%的像素(1)。
本文的工作目标是修复用商品相机拍摄的RGB-D图像的深度通道。

图1 深度信息修复
通过从颜色预测法线,然后求解完成的深度,我们在RGB-D图像的深度通道中填充大量缺失区域。
算法流程
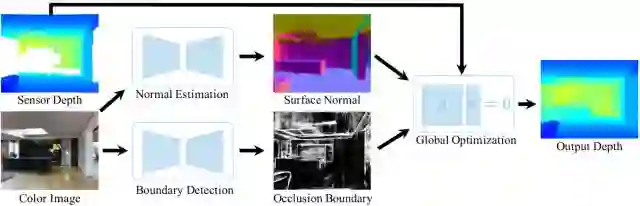
图2 系统流程图
给定输入RGB-D图像,我们根据颜色预测曲面法线和遮挡边界,然后利用由输入深度调整的全局线性优化求解输出深度。

图3 深度修复数据集
深度修复是从大型室内环境的多视图表面重建计算的。 在此示例中,底部显示了原始颜色和深度通道,其中标记为红点的视点渲染深度。 渲染后的网格(由大图像中的顶点着色)通过组合来自遍布整个场景的各种其他视图(黄色点)的RGB-D图像创建,这些视图在渲染到红点视图时协作填充孔。

图4 使用曲面法线来解决深度修复问题
(a)深度不能从曲面法线求解的例子。(b)缺少深度的区域标记为红色。 红色箭头显示不能从表面法线集成深度的路径。 然而,在现实世界的图像中,通过连接相邻像素(沿着地板,天花板等)的许多路径,在这些路径上可以集成深度(绿色箭头)。

图5 不同输入的表面法线估计
第一行显示输入彩色图像,原始深度和渲染法线。 最下面一行显示了输入仅为深度时的表面法线预测,仅显示颜色和两者。 中间一个对失踪区域表现最好,而其他两个模型在其他地方可以与其他地方相媲美,即使没有深度作为输入。
主要结果
我们发现,在NVIDIA TITAN X GPU上,预测320x256色彩的表面法线和遮挡边界需要约0.3秒。 在英特尔至强2.4GHz CPU上解决深度的线性方程式需要约1.5秒。
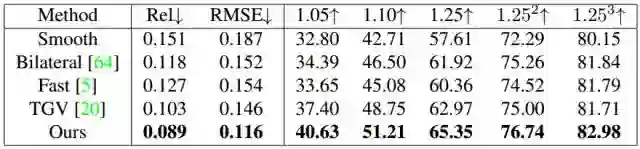
图6 本文方法与基线修补方法进行比较
实验结果表明我们的方法明显优于基线修补方法。
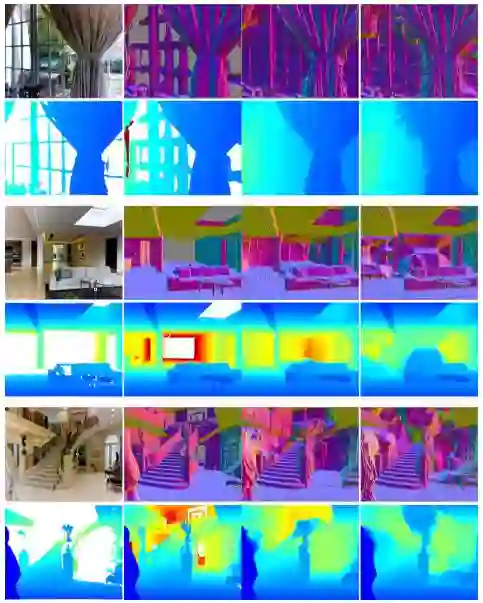
图7 与联合双边过滤器进行比较
本文提出的方法从颜色中学习更好的指导并产生相对更清晰和更准确的结果。
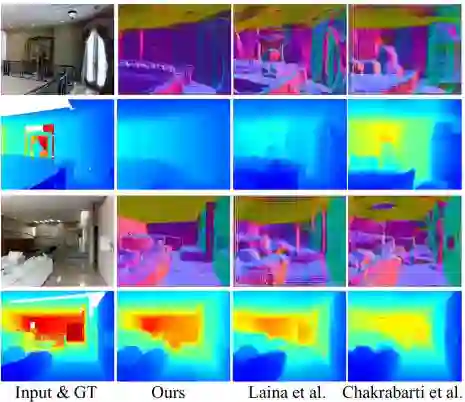
图8 与深度估计方法的比较
本文提出的方法是比较深度估计设置下的最先进的方法。 我们的方法不仅产生准确的深度值,而且还产生如表面法线中所反映的大尺寸几何结构
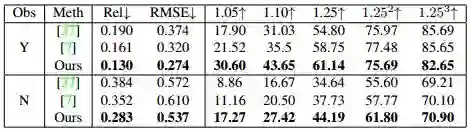
图9 与深度估计方法的比较
本文比较Laina等人和Chakrabarti等人。 所有的方法在观察到的像素上表现出不可观察的像素,这表明未观察到的像素更难。 我们的方法明显优于其他方法。

Abstract
The goal of our work is to complete the depth channel of an RGB-D image. Commodity-grade depth cameras often fail to sense depth for shiny, bright, transparent, and distant surfaces. To address this problem, we train a deep network that takes an RGB image as input and predicts dense surface normals and occlusion boundaries. Those predictions are then combined with raw depth observations provided by the RGB-D camera to solve for depths for all pixels, including those missing in the original observation. This method was chosen over others (e.g., inpainting depths directly) as the result of extensive experiments with a new depth completion benchmark dataset, where holes are filled in training data through the rendering of surface reconstructions created from multiview RGB-D scans. Experiments with different network inputs, depth representations, loss functions,optimization methods, inpainting methods, and deep depth estimation networks show that our proposed approach provides better depth completions than these alternatives.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


