旷视提出DRConv:动态区域感知卷积,提升分类/检测/分割性能!
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文作者:张凯
https://zhuanlan.zhihu.com/p/136998353
本文已由原作者授权,不得擅自二次转载
背景
《Dynamic Region-Aware Convolution》是2020年旷视在arXiv上的新论文,该论文实际上是在动态卷积(local形式)上引入了空间上的分组,从而显著提升了计算机视觉任务(分类检测分割)等性能,在云端实验还是非常值得尝试的。

论文地址:https://arxiv.org/abs/2003.12243
一、研究动机
该论文提出了一种新的卷积方式Dynamic Region-Aware Convolution(DRConv),动态区域感知卷积,该卷积基于不同feature map 上不同区域特征的特性,采用不同的卷积核,在少量增加参数量的情况下,显著提升了分类、检测、分割等任务的性能。
二、研究方法
整体思路如图所示:
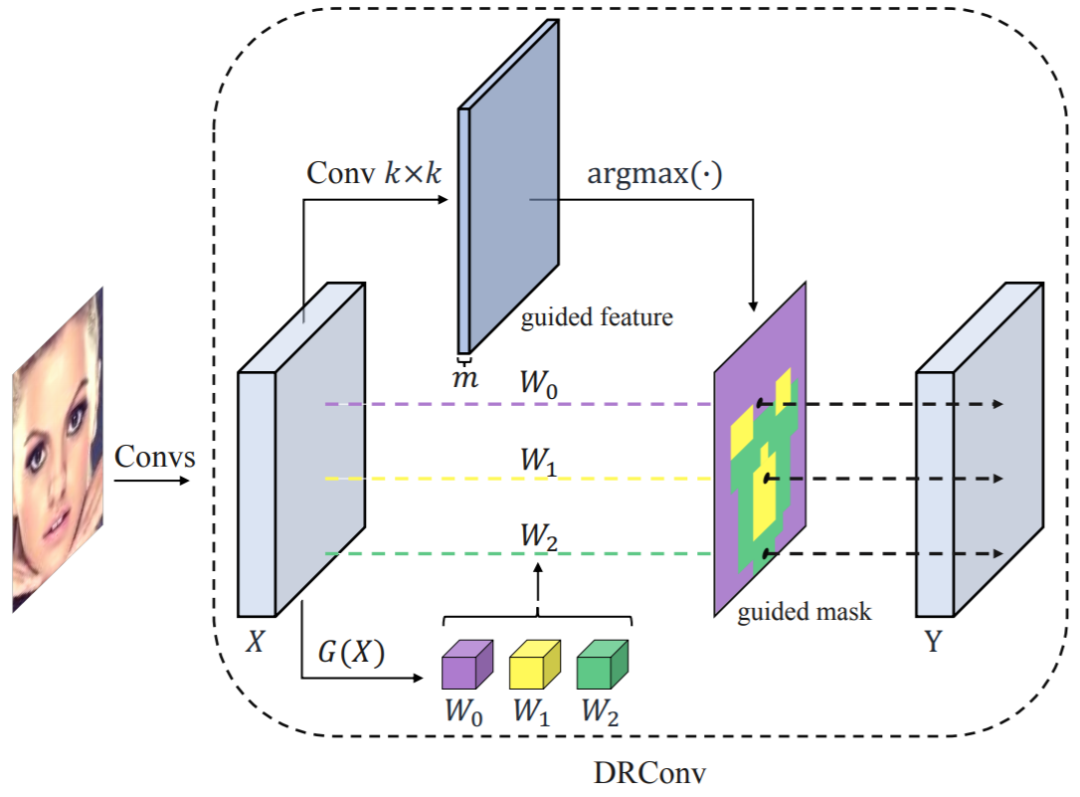
作者主要在输入的特征图上生成一个mask,将输入特征图进行一个粗分类,划分成m个区域,然后再生成m个不同的卷积,在每个区域内部,不同位置的卷积核是共享的,在不同区域,卷积是不同的。该做法一方面充分利用了特征图上的空间信息,另一方面又能保持较好的不变性。对比标准卷积,该方法不增加计算量,同时标准卷积所有位置采用相同的卷积核,为了获取足够信息,需要很大的通道数,这种做法是低效的。对比local convolution,即每个位置都采用不同的卷积核,该方法一方面可以减少很大的参数量,另一方面在相似的区域采用相同的卷积核有利于保持不变性。(该论文认为局部卷积在分类任务上没有提升,就是由于这个原因。)
主要分成以下几个部分:
(1) 动态区域感知卷积
标准卷积如下:
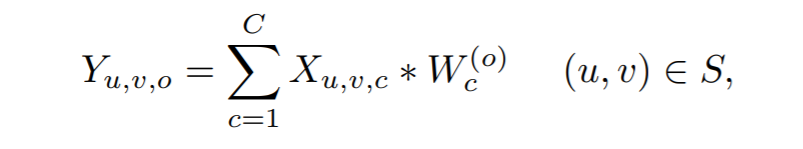
局部卷积则是不同位置都有不同的卷积核:
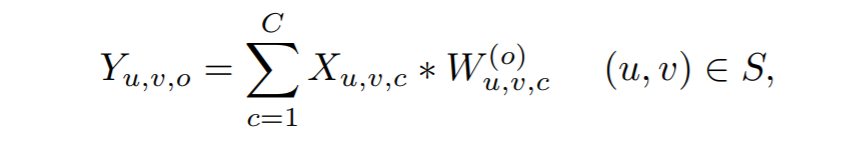
对于动态区域感知卷积,其不同区域采用不同的卷积核:
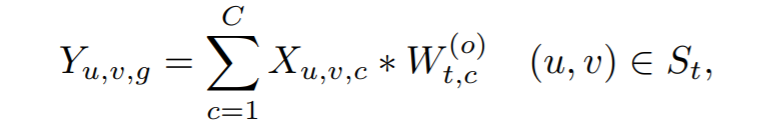
(2) Guided-mask
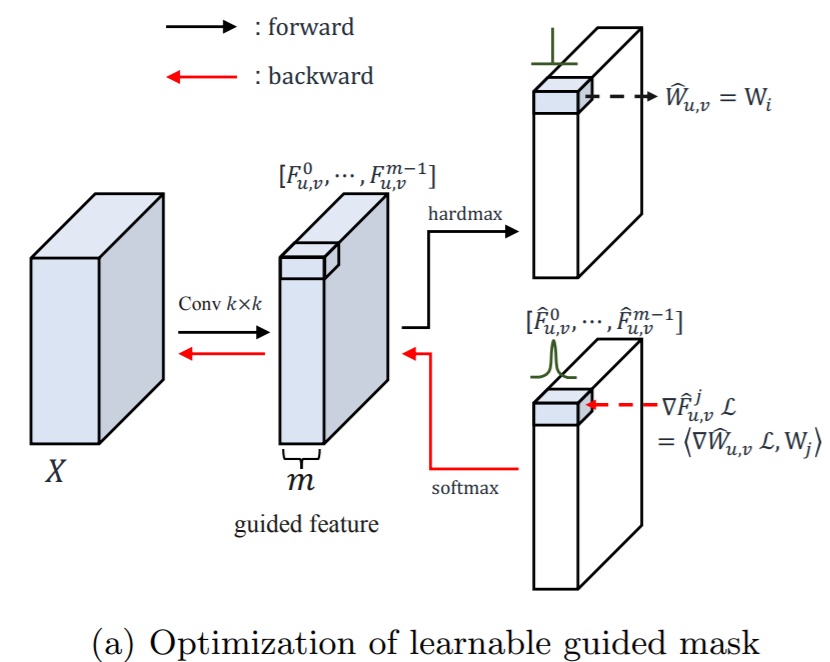
在forward中,作者采用一个卷积得到m个通道的特征,然后在通道维上对每一个位置取argmax,取其索引,即为该位置对应在卷积核生成模块应该采用的卷积核:
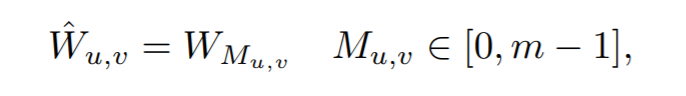
在backward中,由于采用了argmax,无法进行梯度传播,所以考虑采用softmax进行替代,估计的特征图为softmax之后的特征图:
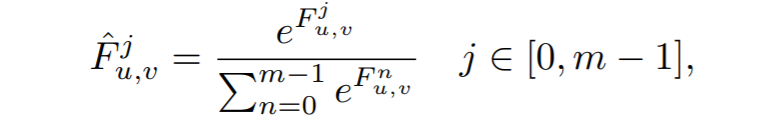
其估计特征图的梯度为(由wj的梯度进行传播):
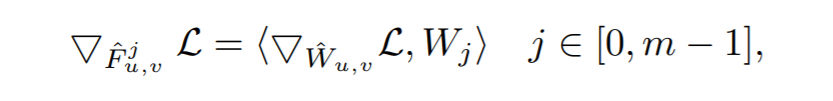
然后用估计特征图梯度通过softmax反传:
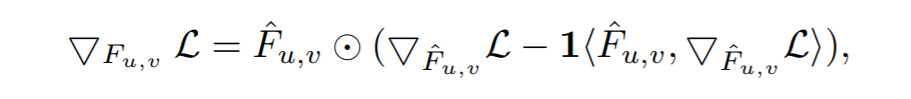
(3) 卷积核生成模块
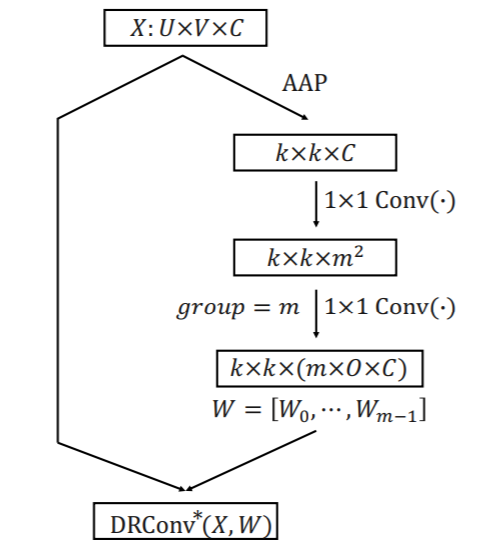
整个卷积核生成模块如图所示,首先采用一个average adaptive pooling得到kxkxC的特征图,然后接一个1x1的卷积,激活函数采用sigmoid,然后采用一个1x1卷积,没有激活函数,groups为m。得到m个kxk的卷积核。
三、实验结果

在分类任务上,采用DRConv在不同的模型上,性能有较为显著的提升,而计算量只增加了部分。
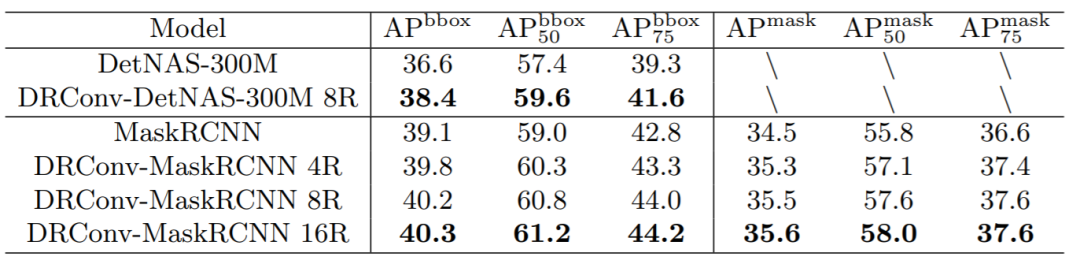
在检测和分割任务上,该方法也有明显的提升,并且region数目越多,其性能提升也更加明显。
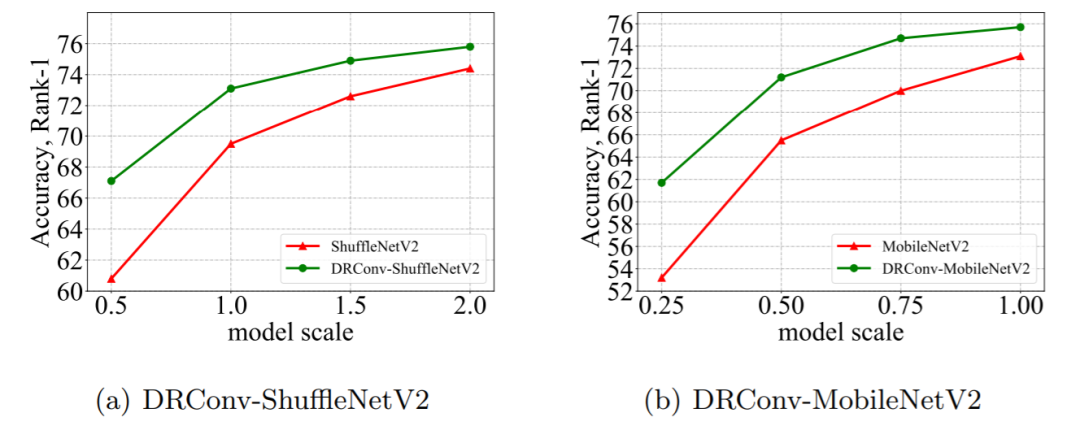
从模型大小上看,其模型越小,其性能提升更加明显,这是由于小模型表达能力不足导致的。
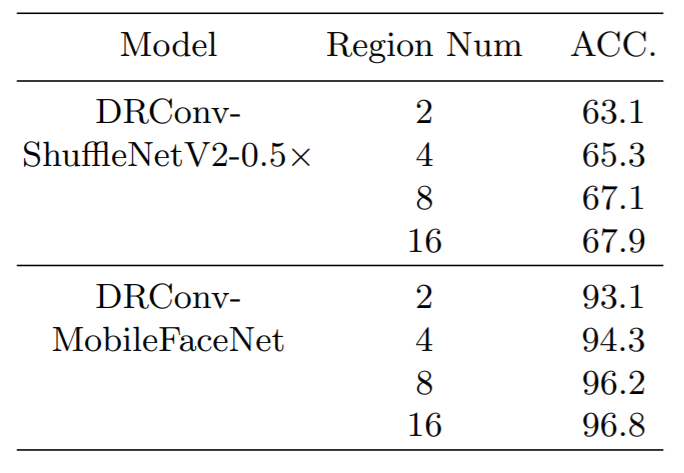
Region 数目越大,其性能提升越明显,增加到8以上,其性能增加不明显。

从可视化的角度来看,底层特征区域的分割是较为离散的,高层语义特征上,其分割更加连续,这是由于高层语义特征有较大的感受野所致。
四、总结分析
该论文实际上是利用了特征图的空间特性显著提升了网络性能,缺点是非常不利于并行优化(batchsize的并行可以通过group 卷积实现),对硬件也非常不友好。
论文下载
在CVer公众号后台回复:DRConv,即可下载本论文
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1400+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
请给CVer一个在看!
