AAAI 2020 | 超低精度量化BERT,UC伯克利提出用二阶信息压缩神经网络
机器之心发布
机器之心编辑部
2020 年 2 月 7 日-2 月 12 日,AAAI 2020 将于美国纽约举办。不久之前,大会官方公布了今年的论文收录信息:收到 8800 篇提交论文,评审了 7737 篇,接收 1591 篇,接收率 20.6%。为向读者们分享更多的优质内容、促进学术交流,在 AAAI 2020 开幕之前,机器之心策划了多期线上分享。





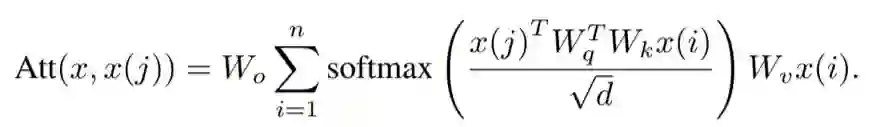
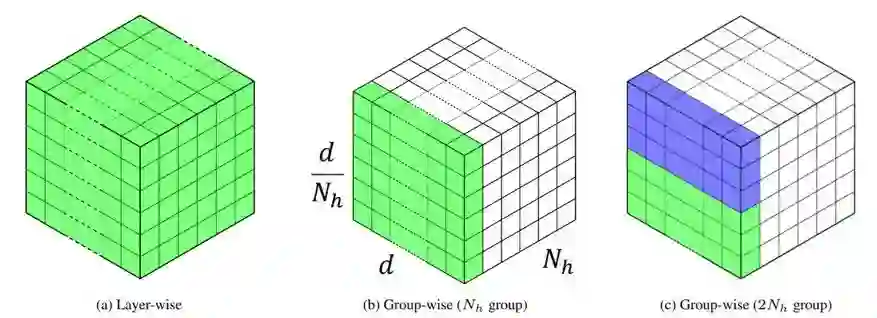
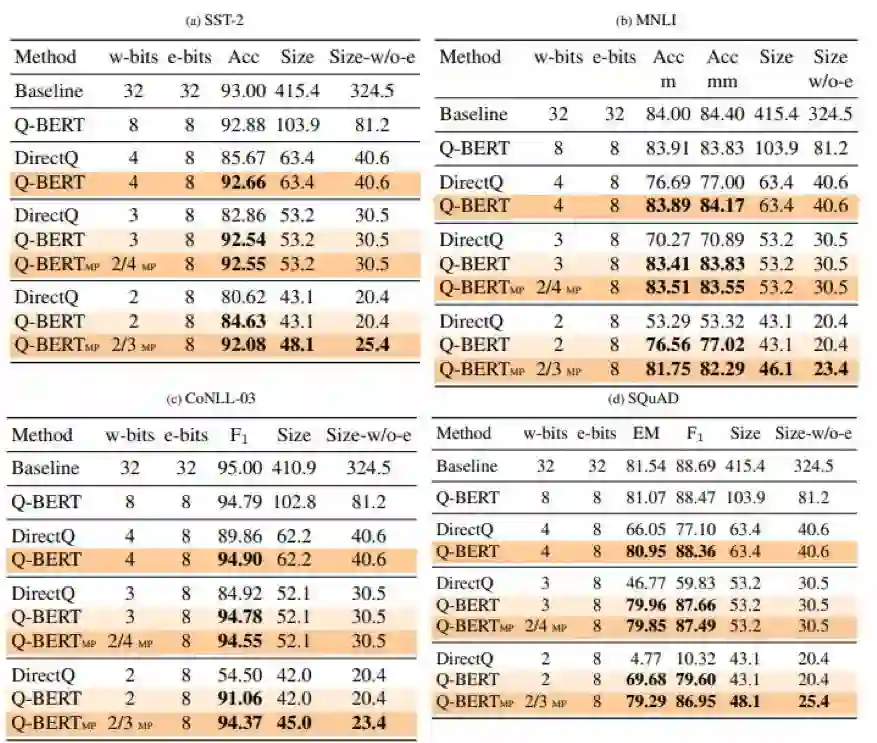
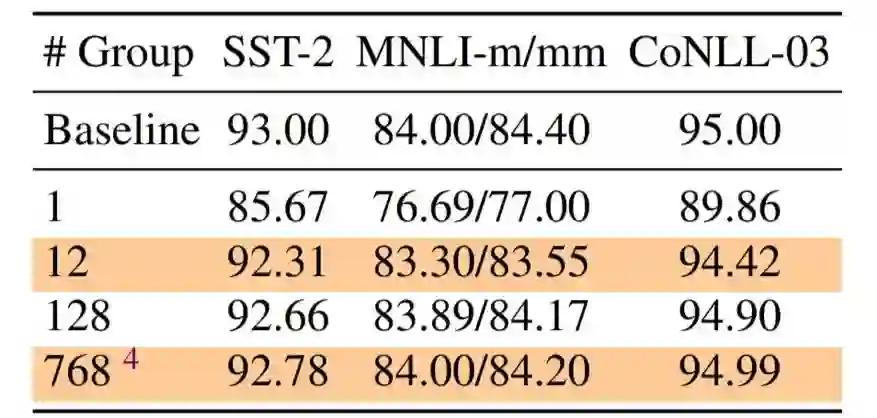
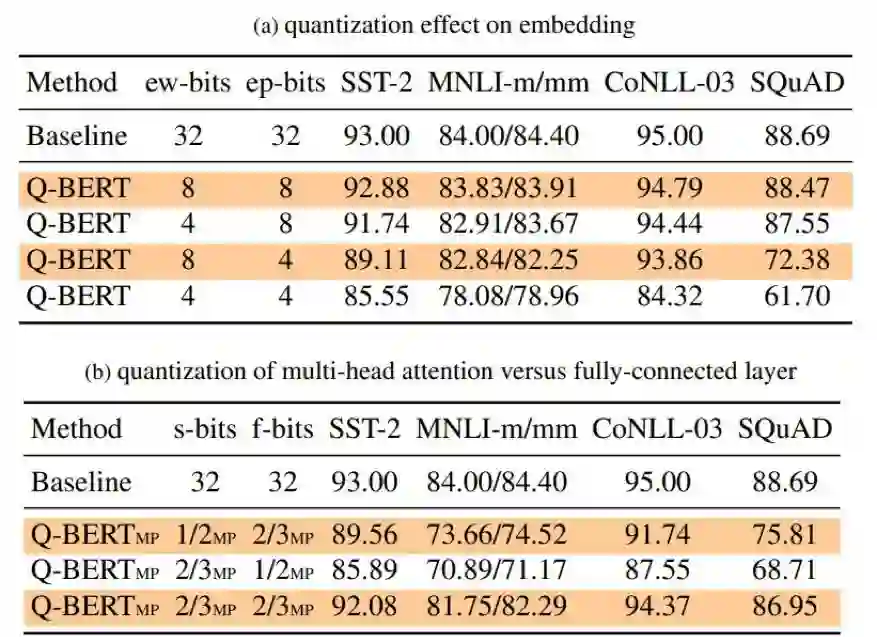
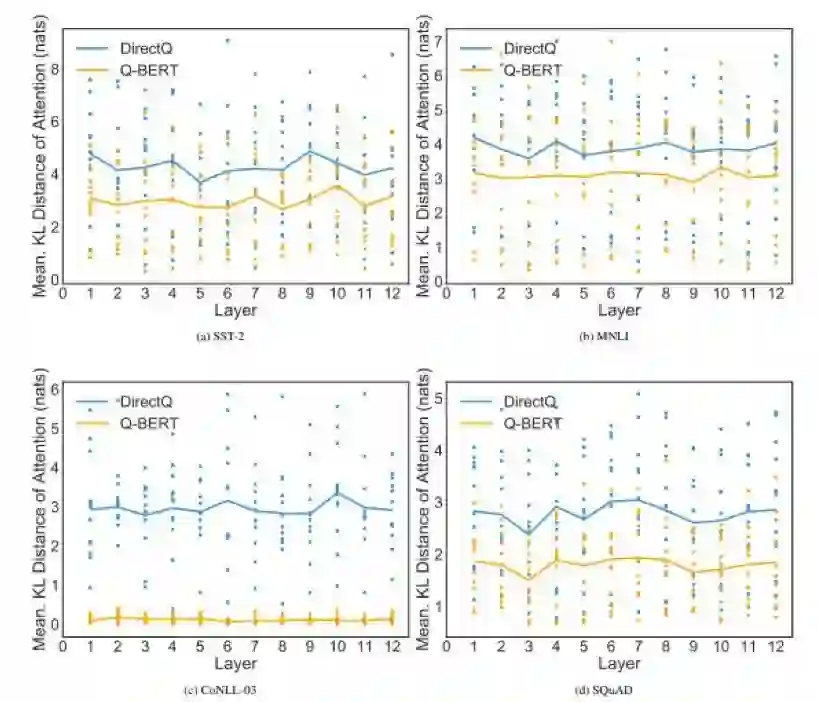
登录查看更多
相关内容
Arxiv
4+阅读 · 2018年1月11日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月11日