AI综述专栏 | 深度神经网络加速与压缩
AI综述专栏简介
在科学研究中,从方法论上来讲,都应先见森林,再见树木。当前,人工智能科技迅猛发展,万木争荣,更应系统梳理脉络。为此,我们特别精选国内外优秀的综述论文,开辟“综述”专栏,敬请关注。
作者简介
王培松,博士,中国科学院自动化研究所模式识别国家重点实验室助理研究员。于2013年在山东大学获学士学位,2018年在中国科学院自动化研究所获博士学位。目前主要从事深度学习、机器学习、图像与视频分析以及神经网络加速与压缩等方面的研究。在ACM-TOMM、Cognitive Computation等国际期刊和CVPR、AAAI、ECCV、ACM MM等顶级国际会议上发表论文数篇。

程健,现为中国科学院自动化研究所南京人工智能芯片创新研究院常务副院长、人工智能与先进计算联合实验室主任、模式识别国家重点实验室研究员。分别于1998年和2001年在武汉大学获学士和硕士学位,2004年在中国科学院自动化研究所获博士学位。2004年至2006年在诺基亚研究中心做博士后研究。2006年9月至今在中科院自动化研究所工作。目前主要从事深度学习、人工智能芯片设计、图像与视频内容分析等方面研究,在相关领域发表学术论文100余篇,英文编著二本。曾先后获得中科院卢嘉锡青年人才奖、中科院青年促进会优秀会员奖、中国电子学会自然科学一等奖、教育部自然科学二等奖等。目前担任国际期刊《PatternRecognition》的编委,曾担任2010年ICIMCS国际会议主席、HHME2010组织主席、CCPR 2012出版主席。

1、引言
近几年来,深度神经网络的性能获得大幅度提升,同时网络的存储和计算复杂度也随之增长。如何对深度神经网络进行加速与压缩,提高深度神经网络的运行效率,成为深度学习领域的研究热点。针对该问题,在学术界和工业界共同的努力下,一系列的方法被相继提出。在本文中,我们将深入探索深度神经网络加速与压缩的最新研究进展。具体而言,本文将这些方法分成以下六类,即网络剪枝、低秩分解、网络量化、知识迁移网络、紧凑网络设计,并讨论它们的优缺点。更多详细内容请参考文献[6]。
2、基于剪枝的神经网络加速与压缩
网络权值稀疏化或网络剪枝(pruning),是一种传统的网络压缩方法之一。其中心思想是通过移除神经网络中的部分连接,从而可以降低网络的存储以及计算量。近几年,随着深度神经网络的广泛流行,基于网络剪枝的方法又重新回到了研究者的视线[14][15],并受到了越来越多的关注。根据是否对可以剪掉的元素位置做约束,可以分成结构化剪枝和非结构化剪枝。在下面的几节中,我们将详细描述不同的剪枝方法。
2.1 非结构化剪枝
非结构化剪枝是指网络的任何位置的参数都可以被剪掉,由于没有对剪枝的形式做任何额外的限制,可以达到很高的稀疏度。Han等人在[14]中提出了一个三阶段的深度压缩框架(Deep Compression):网络剪枝、量化和霍夫曼编码。通过使用这种方法,AlexNet可以在没有精度损失的情况下压缩35倍。网络剪枝之后,需要对网络进行重训练,以弥补剪枝过程中的精度损失。在[14]中,某个权值一旦被剪掉,在后续的重训练过程中一直保持为零,所以可能导致精度下降。为了解决这个问题,[12]提出了一个动态网络剪枝框架,它由两个操作组成:剪枝和恢复。剪枝操作旨在去除那些当前不重要的参数,而恢复操作旨在恢复被错误剪掉的连接。该方法可以在更少的训练周期下,取得比[14]更高的压缩比。非结构化剪枝由于没有对可以剪掉的权值的位置做任何结构化限制,因此可以在无损或者精度损失很小的条件下,大幅度移除网络中的权值,从而大大降低模型的存储。但是,该类方法导致剪枝后的权值矩阵是无规则稀疏的,因此实际加速效果较低。
2.2 结构化剪枝
不同于非结构化剪枝,结构化剪枝对去除权值的位置做了一定限制。根据结构化粒度的不同,又可以分为向量级剪枝(vector-level pruning),核级剪枝(kernel-level pruning),组级剪枝(group-levelpruning)和通道级剪枝(filter-level or channel-level pruning)四种。对于输入和输出通道分别为S和T的卷积层,假设其卷积核空间维度是D×D,那么该卷积层的参数是一个T×S×D×D的张量。我们称该卷积层共有T个3-D卷积核(也称为滤波器,filter),其中每个卷积核(滤波器)是由S个2-D卷积核组成的。
向量级剪枝技术是指的每次剪去某个2-D卷积核中的一行。[32]对多种剪枝粒度进行了探讨,并发现向量级剪枝比非结构化的剪枝占用更少的存储空间,因为向量级剪枝需要较少的索引来指示剪枝后的参数。
在[1]中,Anwar等人首次提出并探索了核级剪枝和通道级剪枝技术。核级剪枝是指每次把3-D卷积核中某一个2-D卷积核全部去掉。而通道级剪枝则是把某个3-D卷积核全部去掉,对应的整个输出通道都可以剪掉,因此,通道剪枝对于加速深度神经网络更有效。并且,通过删除整个卷积核,卷积层的参数可以表示成一个小的稠密矩阵,而不需要使用如压缩稀疏行格式(Compressed Sparse Row,CSR)或压缩稀疏列格式(Compressed Sparse Column,CSC)等特殊的方法进行存储。[31]提出了一种名为ThiNet的通道剪枝方法。他们使用下一层的特征来指导当前卷积层的剪枝,通过最小化下一层特征的重建误差,使用贪婪的方式选择需要删除的通道。与[31]类似,[17]提出了一种两阶段迭代算法,使用特征拟合的方法实现通道卷积。具体而言,他们为每个卷积核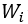
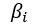
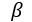
Lebedev等人在[28]中提出的“分组脑部损伤”(Group-wise Brain Damage)方法,属于组级剪枝方法。组级剪枝方法限制每个卷积核都具有相同的稀疏模式。由于每个卷积核为零的元素的位置都是相同的,因此,在计算过程中,可以对卷积核中的元素进行重新排序,表示为一个小的稠密矩阵;相对应的,对网络的输入也需要进行重新排列,得到压缩后的稠密矩阵,这样卷积操作就可以利用基本线性代数子程序(BLAS)[42]来实现更高的加速。同时,由于每个卷积核的稀疏模式是相同的,因此,对于每一层,可以只保存一份非零元素位置的标记,从而可以实现高效的存储。
3、权值张量低秩分解
卷积层的参数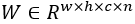
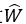
对于二分量分解,卷积层的权值张量被分解成两部分,并且该卷积层可以被两个连续的卷积层替换。在[24]中,Jaderberg等人提出将空间维度为
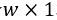

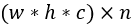
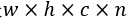

在对两分量分解方法进行分析的基础上,一种很直观的三分量分解方法是使用两个连续的两分量分解。通过SVD分解可以得到两个权值张量(或矩阵):第一个是


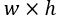
进一步的,通过考虑四维卷积核在四个维度上的低秩性,可以得到四分量分解方法。这种方法对应于基于CP分解的神经网络加速方法[27]。通过CP分解[26],卷积层参数可以分解成四部分,即
4 、基于量化的神经网络加速与压缩
量化是实现加速和压缩的一种常用方法,在图像视频压缩、语音编解码、信息检索等领域有着广泛的应用。近几年,量化方法被广泛应用于深度神经网络加速和压缩。我们可以将这些方法分为两大类:基于码本的量化,包括标量量化和矢量量化,以及定点数量化。
4.1 基于码本的量化
基于标量量化的神经网络压缩方法,其基本思想是将网络的每一个权值量化为一个有限集合(即码本)中的某一个元素。在[4]中,Chen等人提出HashNet,将网络权值随机地划分到多个哈希桶中,同一个哈希桶中的所有元素共享一个权值,从而可以对神经网络进行压缩。在HashNet的基础上,该作者又提出了FreshNet[5],首先将网络卷积核变换到频率域,然后在频率域进行随机哈希,并且对不太重要的高频部分使用更低的哈希位数,以实现更高的压缩。在[11]中,Gong等人直接对网络的权值进行K均值聚类(K-means clustering)[16],每一个权值都使用聚类中心来表示,可以达到非常高的压缩比。在[14]中,Han等人提出三阶段神经网络压缩方法,首先对网络进行剪枝,第二阶段对剪枝后的权值使用K均值聚类进行量化,最后再对量化后的权值进行霍夫曼编码。
矢量量化与标量量化非常类似,区别在于矢量量化以向量(一组权值)为基本单位进行量化。[11]中使用了乘机量化(Product Quantization),把网络权值划分成多个子空间,并在每个子空间上进行K均值聚类,从而减少权值的量化误差。该方法能够对网络的全连接层实现非常高的压缩。在后续工作[43,7]中,吴家祥等人对该方法进行了许多改进,提出了同时对网络的卷积层和全连接层进行量化;并通过使用特征拟合来优化乘机量化问题,进一步减小量化误差。该方法可以达到4到6倍的加速以及15到20倍的压缩,同时网络精度下降非常低。
目前,基于码本的量化方法得到的网络在运行阶段有两种运行方式,一种是对压缩后的权值进行解码,恢复出与原始网络参数同样大小的权值张量再进行计算。这种方式,网络的存储降低,但是网络的运行时间并没有发生变化。另一种运行方式是把矩阵运算转换成查表运算[43],同时降低网络的存储和计算量。但是由于查表对内存访问不友好,因此实际加速效果要低于理论加速效果。
4.2 定点数量化
深度神经网络普遍使用32位单精度浮点数表示,然而浮点数计算往往占用资源多,执行速度慢。相比之下,定点数操作处理逻辑相对简单,能够达到更高的执行效率。
基于上述原因,神经网络定点量化获得了越来越多的关注。在[13]中,Hammerstrom提出了一种使用8比特输入和输出,以及16比特内部表示的神经网络加速的超大规模集成电路架构。除了直接进行定点量化,[33]中提出了使用对数量化来对卷积神经网络进行加速和压缩。
近期,网络二值量化(-1,+1)和三值量化(-1,0,+1)等方法受到了越来越多的研究者的关注。相对于32位浮点数网络,权值二值化可以节约32倍存储,同时由于所有权值都量化到+1或者-1,整个网络的浮点数乘加运算可以转换成浮点数加减法。在[8]中,Courbariaux等人提出了BinaryConnect网络,该方法可以实现权值二值化网络的训练。在[34]中,Rastegari等人提出二值权值网络(Binary Weight Network,BWN),通过对每一个卷积核引入一个缩放因子,有效降低权值量化误差,并首次在ImageNet[36]大规模图像分类任务上,对AlexNet网络实现权值二值量化,达到比较低的精度损失。在[20]中,Hu等人提出使用哈希方法对网络权值进行二值化,相比于之前的工作,该方法可以有效降低分类精度损失。在[29]中,Li等人对BWN网络进行扩展,提出了三值权值网络(Ternary Weight Network,TWN),通过最小化权值拟合误差求得三值化的权值以及对应的缩放因子,实现网络量化。在[49]中,Zhu等人提出了学习三值量化(Trained Ternary Quantization)方法,同时对三值权值和缩放因子进行优化。在[47]中,Zhou等人提出了一种增量式网络量化(Incremental Network Quantization,INQ)方法,逐渐把网络权值进行量化。文章[40]中提出对网络权值进行三值分解,相比于之前工作,取得了更好的性能。
除了对网络权值进行量化,网络激活也可以进行低比特量化。Hubara等人在[21]中对BinaryConnect网络进行了扩展,提出二值神经网络(Binarized Neural Networks,BNN),直接使用符号函数(sign)同时对网络权值和激活进行二值化,在CIFAR-10等小型数据集上,BNN能够达到甚至超过全精度网络的性能。在[34]中,Rastegari等人在二值权值网络(BWN)基础上提出XNOR-Net,对网络激活也引入了缩放因子,并对激活进行二值化。该方法是最早把二值网络应用到ImageNet大规模图像分类任务上的工作之一。在[48]中,Zhou等人提出了DoReFa-Net,探讨在不同比特数量情况下的网络性能。除了对网络权值和激活量化以外,DoReFa-Net还对不同比特数的网络梯度量化进行了实验分析。在[2]中,Cai等人提出了半波高斯量化(Half-wave Gaussian Quantization,HWGQ),通过使用激活2比特量化,权值二值量化,该方法在ImageNet大规模图像分类任务上,大大降低了常用的卷积神经网络量化的精度损失。[41]提出了两阶段量化方法,实现激活2比特,权值三值量化,并取得非常好的性能。
目前,虽然深度神经网络权值-激活低比特量化获得了非常大的进展,但是相比于浮点网络,依然有很大的性能损失。如何进行网络非常低比特的压缩,改进量化及训练方法以提升低比特网络性能,依然需要非常多的探索。
5、知识迁移网络
知识迁移网络与上述网络加速与压缩方法不同,该方法使用两种类型的网络,一种是教师网络,另一种是学生网络。该方法首先训练教师网络,达到非常高的性能,然后通过使用学生网络对教师网络进行拟合,从而把教师网络学到的知识迁移到学生网络中。一般来说,教师网络是一个大型神经网络或神经网络集合,而学生网络则是一个紧凑而高效的神经网络。
在[18]中,Hinton等人提出了一种通过教师网络softmax层的输出来训练学生网络的知识蒸馏(knowledge distillation,KD)方法。遵循这种思路,[35]提出FitNets训练网络更深,但通道数更少的学生网络。由于神经网络的深度比宽度更重要,因此更深的学生网络将具有更高的准确性。此外,该方法同时利用教师网络的中间层特征输出和最终的softmax层输出来训练学生网络。[44]提出通过模仿教师网络的注意力图(attention map)来训练学生网络,而不是模仿中间层的特征输出。在[3]中,Chen等人在图像目标检测任务上对知识迁移网络进行了探索。
6、紧凑网络设计
神经网络加速与压缩的目标是在相似的网络性能下,实现网络的低存储和低计算量。大部分神经网络加速与压缩的方法都保持网络结构不变。而另一种思路是直接设计更加紧凑的网络结构,该网络具有存储和计算量低,并且网络性能高的特性。
在[22]中,Iandola等人提出SqueezeNet,通过大量使用
在上述网络中,
7、总结
在本文中,我们对深度神经网络加速与压缩的相关研究进展进行了回顾。具体地,本文将这些方法分成以下六类,即网络剪枝、低秩分解、网络量化、知识迁移网络以及紧凑网络设,并讨论它们的优缺点。希望本文能够为深度神经网络加速与压缩的相关研究人员带来一定的启发,促进模型压缩与加速领域的发展。
参考文献
[1] Sajid Anwar,Kyuyeon Hwang, and Wonyong Sung.Structured pruning of deep convolutional neuralnetworks.ACM Journal on Emerging Technologies in Computing Systems (JETC),13(3):32, 2017.
[2] Zhaowei Cai,Xiaodong He, Jian Sun, and Nuno Vasconcelos.Deep learning with low precision byhalfwave gaussian quantization. July 2017.
[3] Guobin Chen,Wongun Choi, Xiang Yu, Tony Han, and Manmohan Chandraker. Learning efficientobjectdetection models with knowledge distillation. In Advances in NeuralInformation Processing Systems, pages 742–751, 2017.
[4] Wenlin Chen,James Wilson, Stephen Tyree, Kilian Weinberger, and Yixin Chen. Compressingneural networks with the hashing trick. In InternationalConference on MachineLearning, pages 2285–2294,2015.
[5] Wenlin Chen,James T Wilson, Stephen Tyree, Kilian Q Weinberger, and Yixin Chen. Compressingconvolutional neural networks. arXiv preprint arXiv:1506.04449, 2015.
[6] Jian Cheng,Pei-song Wang, Gang Li, Qing-hao Hu, and Han-qing Lu. Recent advances inefficient computation of deep convolutional neural networks.
Frontiers ofInformation Technology & Electronic Engineering, 19(1):64–77, Jan 2018.
[7] Jian Cheng,Jiaxiang Wu, Cong Leng, Yuhang Wang, and Qinghao Hu. Quantized cnn: A unifiedapproach to accelerate and compress convolutional
networks. IEEETransactions on Neural Networks and Learning Systems (TNNLS), PP:1–14, 2017.
[8] MatthieuCourbariaux, Yoshua Bengio, and Jean-Pierre David. Binaryconnect: Training deepneural networks with binary weights during propagations. In Advances in NeuralInformation Processing Systems, pages 3123–3131, 2015.
[9] Lieven DeLathauwer, Bart De Moor, and Joos Vandewalle.On the best rank-1 and rank-(r 1,r 2,..., rn) approximation of higher-order tensors. SIAM Journal
on Matrix Analysisand Applications, 21(4):1324–1342, 2000.
[10] Misha Denil,Babak Shakibi, Laurent Dinh, Nando de Freitas, et al. Predicting parameters indeep learning. In Advances in Neural Information Processing Systems, pages2148–2156, 2013.
[11] Yunchao Gong,Liu Liu, Ming Yang, and Lubomir Bourdev. Compressing deep convolutionalnetworks using vector quantization. arXiv preprint arXiv:1412.6115, 2014.
[12] Yiwen Guo,Anbang Yao, and Yurong Chen. Dynamic network surgery for efficient dnns. InAdvances In Neural Information Processing Systems, pages 1379–1387, 2016.
[13] D.Hammerstrom. A vlsi architecture for high-performance, low-cost, on-chiplearning. In IJCNN International Joint Conference on Neural Networks,
pages 537–544vol.2, 2012.
[14] Song Han,Huizi Mao, and William J Dally. Deep compression: Compressing deep neuralnetworks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149,2015.
[15] Song Han, JeffPool, John Tran, and William Dally.Learning both weights and connections forefficient neural network. In Advances in Neural Information
Processing Systems,pages 1135–1143, 2015.
[16] John AHartigan and Manchek A Wong. Algorithm as 136: A k-means clustering algorithm.Journal of the Royal Statistical Society. Series C (Applied
Statistics),28(1):100–108, 1979.
[17] Yihui He,Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neuralnetworks. In The IEEE International Conference on Computer
Vision (ICCV), Oct2017.
[18] GeoffreyHinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neuralnetwork. arXiv preprint arXiv:1503.02531, 2015.
[19] Andrew GHoward, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand,Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neuralnetworks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
[20] Qinghao Hu,Peisong Wang, and Jian Cheng. From hashing to cnns: Training binary weightnetworks via hashing. In AAAI, February 2018.
[21] Itay Hubara,Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarizedneural networks. In Advances in neural information processing systems, pages4107–4115, 2016.
[22] Forrest NIandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, andKurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parametersand< 0.5 mb model size. arXiv preprint arXiv:1602.07360, 2016.
[23] Sergey Ioffeand Christian Szegedy. Batch normalization: Accelerating deep network trainingby reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
[24] Max Jaderberg,Andrea Vedaldi, and Andrew Zisserman.Speeding up convolutional neural networkswith low rank expansions. arXiv preprint arXiv:1405.3866, 2014.
[25] Yong-Deok Kim,Eunhyeok Park, Sungjoo Yoo, Taelim Choi, Lu Yang, and Dongjun Shin. Compressionof deep convolutional neural networks for fast
and low powermobile applications. arXiv preprint arXiv:1511.06530, 2015.
[26] Tamara G Koldaand Brett W Bader. Tensor decompositions and applications. SIAM review,51(3):455–500, 2009.
[27] Vadim Lebedev,Yaroslav Ganin, Maksim Rakhuba, Ivan Oseledets, and Victor Lempitsky.Speedingup convolutional neural networks using fine-tuned cp-decomposition.arXiv preprint arXiv:1412.6553,2014.
[28] Vadim Lebedevand Victor Lempitsky. Fast convnets using group-wise brain damage. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 2554–2564, 2016.
[29] Fengfu Li, BoZhang, and Bin Liu. Ternary weightnetworks. arXiv preprint arXiv:1605.04711,2016.
[30] Zhuang Liu,Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang.Learning efficient convolutional networks through network slimming. In The IEEEInternational Conference on Computer Vision (ICCV), Oct 2017.
[31] Jian-Hao Luo,Jianxin Wu, and Weiyao Lin. Thinet: A filter level pruning method for deepneural network compression. Oct 2017.
[32] Huizi Mao,Song Han, Jeff Pool, Wenshuo Li, Xingyu Liu, Yu Wang, and William J Dally.Exploring the regularity of sparse structure in convolutional neural networks.arXiv preprint arXiv:1705.08922, 2017.
[33] DaisukeMiyashita, Edward H Lee, and Boris Murmann. Convolutional neural networks usinglogarithmic data representation. arXiv preprint arXiv:1603.01025, 2016.
[34] MohammadRastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenetclassification using binary convolutional neural networks. In ECCV (4), volume9908, pages 525–542.Springer, 2016.
[35] AdrianaRomero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta,and Yoshua Bengio. Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550,2014.
[36] OlgaRussakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma,Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al.Imagenet large scale visual recognition challenge. International Journal ofComputer Vision, 115(3):211–252, 2015.
[37] Karen Simonyanand Andrew Zisserman. Very deep convolutional networks for large-scale imagerecognition. arXiv preprint arXiv:1409.1556, 2014.
[38] RobertTibshirani. Regression shrinkage and selection via the lasso. Journal of theRoyal Statistical Society. Series B (Methodological), pages 267–288,1996.
[39] Peisong Wangand Jian Cheng. Accelerating convolutional neural networks for mobileapplications. In Proceedings of the 2016 ACM on Multimedia Conference, pages541–545. ACM, 2016.
[40] Peisong Wangand Jian Cheng. Fixed-point factorized networks. In 2017 IEEE Conference onComputer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July21-26, 2017, pages 3966–3974, 2017.
[41] Peisong Wang,Qinghao Hu, Yifan Zhang, Chunjie Zhang, Yang Liu, and Jian Cheng. Two-stepquantization for low-bit neural networks. In IEEE Conference on Computer Visionand Pattern Recognition (CVPR), 2018.
[42] R Clint Whaleyand Antoine Petitet. Minimizing development and maintenance costs in supportingpersistently optimized blas. Software: Practice and Experience, 35(2):101–121,2005.
[43] Jiaxiang Wu,Cong Leng, Yuhang Wang, Qinghao Hu, and Jian Cheng. Quantized convolutionalneural networks for mobile devices. In IEEE Conference on Computer Vision andPattern Recognition (CVPR), 2016.
[44] SergeyZagoruyko and Nikos Komodakis. Paying more attention to attention: Improvingthe performance of convolutional neural networks via attention transfer. arXivpreprint arXiv:1612.03928, 2016.
[45] Xiangyu Zhang,Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficientconvolutional neural network for mobile devices. arXiv
preprintarXiv:1707.01083, 2017.
[46] Xiangyu Zhang,Jianhua Zou, Kaiming He, and Jian Sun. Accelerating very deep convolutionalnetworks for classification and detection. IEEE Transactions on PatternAnalysis and Machine Intelligence (TPAMI), 2015.
[47] Aojun Zhou,Anbang Yao, Yiwen Guo, Lin Xu, and Yurong Chen. Incremental network quantization:Towards lossless cnns with low-precision weights. arXiv preprintarXiv:1702.03044, 2017.
[48] Shuchang Zhou,Yuxin Wu, Zekun Ni, Xinyu Zhou, He Wen, and Yuheng Zou. Dorefa-net: Traininglow bitwidth convolutional neural networks with low bitwidth gradients. arXivpreprint arXiv:1606.06160, 2016.
[49] Chenzhuo Zhu, SongHan, Huizi Mao, and William J Dally. Trained ternary quantization. arXivpreprint arXiv:1612.01064, 2016.

历史文章推荐:

