讲堂|孙茂松:运用之妙,存乎一心——从机器翻译到古诗生成

“微软AI讲堂”是我们近期推出的一个系列活动。我们希望借助讲座、分享、讨论等多样化的形式,走进校园,传递知识,普及科学,为大家揭开人工智能的神秘面纱。
上周,微软AI讲堂的首站来到了清华大学。此次分享会聚焦人工智能领域的自然语言理解方向,清华大学计算机科学与技术系教授、党委书记孙茂松老师以及微软亚洲研究院副院长周明博士两位自然语言理解领域的顶级专家分别从不同的角度带来了他们的分享。
继此前分享了周明博士的演讲:自然语言对话引擎,今天与大家分享的是清华大学计算机科学与技术系教授、党委书记孙茂松老师的演讲:运用之妙,存乎一心——从机器翻译到古诗生成。
演讲全文如下(文字内容略有精简):
大家下午好!我今天演讲的题目叫做运用之妙,存乎一心——从机器翻译到古诗生成。这是来自岳飞的一句话,意思是说可以不排阵,照样能打好仗,原意为要有灵活性。大家都知道一篇中文翻译成英文,这是机器翻译。而古诗生成则是计算机系统自动作一个古诗,看似这两件事差的很远,但实际上计算模型是一样的。在这个意义上,我们也可以叫做运用之妙,存乎一心,这个一心就是计算模型,也是我今天要讲的。今天的演讲分为四个部分。
第一部分,语言计算之利器:LSTM神经网络
LSTM(Long Short-Term Memory,长短时记忆)神经网络主要是针对语言。自然语言就是人类说的语言,人类的语言极其重要。《人类简史》一书中提到,大概在180万年到200万年前,原始人开始直立行走,而直立行走对人的发展产生了一系列的变化。其中有一个很重要,那就是直立行走后导致的喉部,即与语音相关的器官发生了极大变化,适宜说话。到了大概10万年前产生了语言。
大概7万年前,人类的祖先——智人所向披靡,有学者说智人之所以能达到这个境界就是因为有语言。语言最大的好处就是大家可以共同商量对策来解决问题,所以生存能力就会极大的提高。

人类文明在五六千年左右有了文字,中国的甲骨文在3300年前就有了。这也是人区别于动物的一个最本质的特征。所以语言的计算是人工智能最核心的部分,这个从人工智能发展的历史上就可以看出来。
当然,语言的计算很复杂,比如貌似最为简单的分词问题。“一行白鹭上青天”里和“国家总理一行外出访问”,这个“一行”含义就不同。这就需要语言的知识。有些分词问题的解决还同时需要世界的知识。
这几年,深度神经网络取得了很大进步,最早是在图像和语音领域,而在这两个领域上的突破都和微软有直接的关系。一个是2015年微软亚洲研究院的研究员将神经网络的层数提升到了152层,图像识别的能力最终超过了人类。再一个是语音识别方面,微软用深度学习将语音识别的错误率降到了5.9%。
但是语音识别和图像识别基本上还是属于人的感知层面。动物也有图像识别和声音识别的能力,但如果加入语言的概念,动物就没有了。
在机器认知方面,自然语言是一个很重要的部分。从去年开始,深度神经网络用于自然语言处理的效果开始显著显示出来了。一个代表性的工作是Google的机器翻译,他们用的是刚才提到的LSTM模型。谷歌给出的实验结果表明,假设完美的翻译效果是6分,人类专家也不能达到6分。而神经网络模型在某些语言对之间达到的翻译效果与人类已经相差无几。
第二部分,百川终归海:LSTM与机器翻译
下面简单讲讲机器翻译的发展历史。首先我们说说双语、多语的重要性,举两个例子,一个是巴比伦塔。大家可能知道,《圣经创世记》说人类要建造一个能通上天的通天塔,上帝为了阻止这个行为就创造了不同的语言,语言不通就没法商量,没法商量就建不起来,这里我们可以看到双语的重要性。
双语的重要性还有一个很典型的例子,叫罗塞塔石碑。古埃及象形文字在一个时期已经没有人能认识了,后来发现了这个石碑。罗塞塔石碑上有三种文字,包括古埃及文字和古希腊文,通过古希腊文把古埃及文字最终解读了出来。从这儿也可看到双语的重要性。

机器翻译有几个过程,提出机器翻译任务是在1947年。大家知道信息论的创始人叫香农,还有一个人叫Warren Weaver,Weaver,他在1949年和香农合作发表了著名的The Mathematical Theory of Communication,奠定了信息论的基础。Weaver在1947年时给控制论之父Norbert Wiener写过一封信来探讨机器翻译的可能性。
1949年Weaver写了备忘录《翻译》,正式提出了信息翻译的任务。他提出机器翻译的基本策略与四个东西有关:
(1)意义与上下文。一个词如果是多义词,那么它的具体含义需要靠上下文来决定,类似我们后来的马尔可夫模型。
(2)语言与逻辑。语言和逻辑密不可分,要分析一个句子的逻辑离不开句法语义分析,这和句法分析、语义分析是相关的。
(3)从编码、解码角度研究语言统计语义性质。
(4)普遍的语言结构。有学者认为人类的原始语言可能是一样的。
上面所说的(1)和(3)其实是统计模型,(2)和(4)是规则模型,Weaver个人比较推崇统计模型,但是后来的发展实际上是沿着规则模型的系统在往下走。因为语言学的理论根深蒂固,有词法、语法等等规则,所以基本上到1956年的机器翻译都是沿着这条路线在走。
当时机器翻译是世界计算机领域的前沿,但从1957年到1966年就跌下来了。机器翻译在1966年跌入了波谷,原因在于当时很多机器翻译系统都出来了,这些系统基本上都是基于规则的,但当大家去尝试这些系统时发现有问题。
1960年以色列知名哲学家、数学家和语言学家Yehoshua Bar-Hillel发表了一篇文章,表示机器翻译太难了。举个例子,“The box was in the pen.”和“The pen was in the box.”。“Pen”有两个意思,“钢笔”和“围栏”,而且这里面还有介词,这两个简单的句子,在当时任何规则系统都解决不了。
1964年,美国科学院和美国国家研究理事会成立了一个“语言自动处理咨询委员会”(AutomaticLanguage Processing Advisory Committee, 简称ALPAC委员会),对机器翻译的进展状况,尤其是对过去十余年美国国防部、国家科学基金会和中央情报局重金资助的相关项目的执行效果进行评估。1966年11月,该委员会发布了一个题为《语言与机器:翻译和语言学视角下的计算机》的报告,即著名的ALPAC报告。报告中有两个结论:
(1)对全自动机器翻译持基本否定的态度,认为在可预期的将来,不可能达到与人工翻译相比更为快速、高质量、便宜的目标,转而建议应该支持更为现实的机器辅助翻译;
(2)机器翻译遇到了难以克服的“语义屏障”问题,应该加强对计算语言学的支持。
报告一出来,机器翻译就开始走下坡,美国所有对机器翻译的项目资助全停了。但是欧洲和日本还在做,所以后来又有很多系统。从1967年到1989年,发展比较平稳。到1990年以后发生的事就比较激动人心了。
第一个冲击波——统计机器翻译模型
1990年,芬兰赫尔辛基的第13届国际计算语言学大会提出了处理大规模真实文本的战略任务。所以当时整个机器翻译就转向了统计模型,这就是刚才讲的基于规则模型的一个大翻转,此时也产生了一个原来方法的终结者,就是IBM模型1-5。
关于IBM模型1-5效果,当时一个很有名的学者Och这么评价:“只要给我充分的并行语言数据,那么,对于任何两种语言,我就可以在几小时之内构造出一个机器翻译系统”。这其实就是把大数据的思想灌输到系统中,所以后来就有了Google,百度,包括微软的翻译等等,使得机器翻译可以面向大众,在互联网上提供服务。
第二个冲击波——神经机器翻译模型
神经网络模型,也就是现在说的Deep Learning(深度学习)神经网络模型。它终结了IBM模型1-5,翻译结果有明显的提升,使得像Google、微软、百度等的互联网翻译服务升级。LSTM我们把它叫做端到端的方法,Yann LeCun、YoshuaBengio和Geoffrey Hinton这三位就在《Nature》上表示,端到端的机器翻译有可能终结整个传统的机器翻译系统,虽然当时端到端,也就是LSTM的效果还没有完全超过传统的模型。

机器翻译的发展曲线,高潮、波谷,再起来,和人工智能的发展曲线也比较像。一开始大家有空前高涨的情绪,然后一下子到了谷底,接着又一次激情上来,现在我们还在上升阶段。
第三部分,岂复须人为:LSTM与古诗生成
下面我们再看看创作古诗,为什么研究作古诗呢?这个很自然,我们想看看LSTM模型到底怎么样。于是就用古诗创作来检测这个模型,同时希望能对模型提出改进。大的框架和机器翻译是一样的,差别就是机器翻译实际上是考虑语义的相似性,古诗生成则是考虑语义的相关性,两者虽有差异,但模型其实差不多。
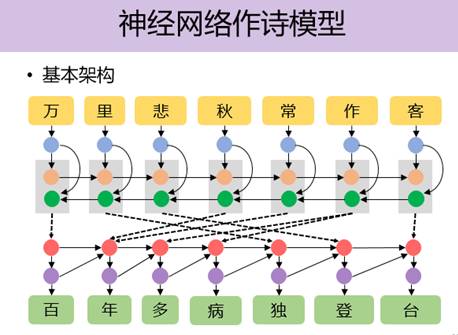
当然针对这个任务,我们对LSTM模型有不少改进。最后得到的效果是,举例来说,当你输入上句,江上西风一棹归,机器会产生下句,夕阳不见客舟低。另外上句,又听西风堕叶声,机器给出下句,万事尽随天籁起。对联做的还不算太理想,但也还可以。
但是完全产生一首古诗,给定题目,比如叫《秋雁》,自动生成的七绝诗为:
白蘋江上惊秋雁
红蓼洲边起暮鸦
遥指翠微亭下路
行人不见武陵花
还可以自动生成藏头诗。我们的古诗生成系统(起名叫“九歌”)现场创作,与人类诗人在效果上有一拼,各有特色,例如七绝首字藏“机智过人”。

平仄也符合,押韵也符合,诗意也还不错。我估计现在在座的80%的同学作诗作不过这个系统。我们也做过测试,就是把计算机产生的诗和古诗放在一起让人打分。我们的系统得分比古人还是略差,但是已经有一定的可比性了。
第四部分,思考
最后总结一下,神经网络虽然好,但是它还是有很多不足的地方,比如The pen was in the box。这个几十年前就提出的不好处理的例句,现在的某些机器翻译还是错的。这就触到了神经网络的痛处,缺乏理论分析,而这就需要把知识放进来。
总结一下我的感受:
(1)技术重大进步的境界。机器翻译也好,古诗创作也好,最大的进步都是依赖于重大技术的面世,而绝不是现有技术的修修补补,殚精竭思的去搞一些小技巧。它们都是由于方法论上的革命而变得更加精准,这就是创新的重要性。
(2)弱人工智能金秋。现在这个时期,有人说是人工智能的夏天,特别hot,有人说冬天快到了,但我认为是秋天,是金秋,是收获的季节,现在是弱人工智能收获的金秋。
我们现有的,包括LSTM模型、CNN模型都是过去一二十年整个学术界研究成果的最突出的体现,一二十年一遇,但其潜能还远远没有发挥出来。如果现在在弱人工智能的不同领域去深挖,一定能达到很好的效果。
再往下估计人工智能的冬天就会到来,这个冬天不是在弱人工智能的意义下,而是在强人工智能的意义下的。那以后要想取得更大的进步,必须依赖强人工智能的突破,而强人工智能的突破必然是新一轮的方法论层面上的突破,非常困难。在这个突破出现之前,人工智能会陷入冬天,积攒新的勃发力量。
今天我就讲到这,谢谢大家!

清华大学计算机科学与技术系教授、党委书记,孙茂松
孙茂松,主要研究领域为自然语言处理、互联网智能、机器学习、社会计算和计算教育学。国家重点基础研究发展计划(973计划)项目首席科学家,国家社会科学基金重大项目首席专家。在国际刊物、国际会议、国内核心刊物上发表论文160余篇,主持完成文本信息处理领域ISO国际标准2项。
主要学术兼职包括:教育部在线教育研究中心副主任,清华大学大规模在线教育研究中心主任,清华大学-新加坡国立大学下一代搜索技术联合研究中心共同主任,国务院学位委员会第六届学科评议组计算机科学与技术组成员,国家自然科学基金委员会第十二、十三届专家评审组成员,中国科学技术协会第九届全国委员会委员,北京市语言文字工作委员会专家委员会副主任,中国中文信息学会第六、七届副理事长,《中文信息学报》主编,《大数据》杂志编委会副主任,全国计算机慕课联盟副理事长,多个教育部或省市级重点实验室学术委员会主任、副主任,国家语言文字工作委员会“两岸语言文字交流与合作协调小组”成员等。2007年获全国语言文字先进工作者,2016年获全国优秀科技工作者及首都市民学习之星。
你也许还想看:







