什么是自然语言理解(NLU)?及2019最新进展

自然语言理解(NLU)跟 NLP 是什么关系?为什么说它是人工智能领域里一个难点?NLU 的发展史历史和目前最现金的方法是什么?
本文将解答上面的问题,带你全面了解自然语言理解(NLU)。
什么是自然语言理解(NLU)?
大家最常听到的是 NLP,而 自然语言理解(NLU) 则是 NLP 的一部分:

什么是自然语言?
自然语言就是大家平时在生活中常用的表达方式,大家平时说的「讲人话」就是这个意思。
自然语言:我背有点驼(非自然语言:我的背部呈弯曲状)
自然语言:宝宝的经纪人睡了宝宝的宝宝
自然语言理解就是希望机器像人一样,具备正常人的语言理解能力,由于自然语言在理解上有很多难点(下面详细说明),所以 NLU 是至今还远不如人类的表现。

下面用一个具体的案例来深度说明一下自然语言理解(NLU):
对话系统这个事情在2015年开始突然火起来了,主要是因为一个技术的普及:机器学习特别是深度学习带来的语音识别和NLU(自然语言理解)——主要解决的是识别人讲的话。
这个技术的普及让很多团队都掌握了一组关键技能:意图识别和实体提取。
这意味着什么?我们来看一个例子。
在生活中,如果想要订机票,人们会有很多种自然的表达:
“订机票”;
“有去上海的航班么?”;
“看看航班,下周二出发去纽约的”;
“要出差,帮我查下机票”;
等等等等
可以说“自然的表达” 有无穷多的组合(自然语言)都是在代表 “订机票” 这个意图的。而听到这些表达的人,可以准确理解这些表达指的是“订机票”这件事。
而要理解这么多种不同的表达,对机器是个挑战。在过去,机器只能处理“结构化的数据”(比如关键词),也就是说如果要听懂人在讲什么,必须要用户输入精确的指令。
所以,无论你说“我要出差”还是“帮我看看去北京的航班”,只要这些字里面没有包含提前设定好的关键词“订机票”,系统都无法处理。而且,只要出现了关键词,比如“我要退订机票”里也有这三个字,也会被处理成用户想要订机票。

自然语言理解这个技能出现后,可以让机器从各种自然语言的表达中,区分出来,哪些话归属于这个意图;而那些表达不是归于这一类的,而不再依赖那么死板的关键词。比如经过训练后,机器能够识别“帮我推荐一家附近的餐厅”,就不属于“订机票”这个意图的表达。
并且,通过训练,机器还能够在句子当中自动提取出来“上海”,这两个字指的是目的地这个概念(即实体);“下周二”指的是出发时间。
这样一来,看上去“机器就能听懂人话啦!”。

自然语言理解(NLU)的应用
几乎所有跟文字语言和语音相关的应用都会用到 NLU,下面举一些具体的例子。

机器翻译
基于规则的翻译效果经常不太好,所以如果想提升翻译的效果,必须建立在对内容的理解之上。
如果是不理解上下文,就会出现下面的笑话:
I like apple, it’s so fast!
我喜欢「苹果」,它很快!
机器客服
如果想实现问答,就要建立在多轮对话的理解基础之上,自然语言理解是必备的能力。
下面的例子对于机器来说就很难理解:
“有什么可以帮您?”
“你好,我想投诉”
“请问投诉的车牌号是多少?”
“xxxxxx”
“请问是什么问题?”
“我刚上车,那个态度恶劣的哥谭市民就冲我发火”
机器很容易理解为:那个态度恶劣/的/哥谭/市民/就冲我发火
智能音箱
智能音箱中,NLU 也是重要的一个环节。很多语音交互都是很短的短语,音箱不但需要能否识别用户在说什么话,更要理解用户的意图。
“我冷了”
机器:帮您把空调调高1度
用户并没有提到空调,但是机器需要知道用户的意图——空调有点冷,需要把温度调高。
自然语言理解(NLU)的难点
下面先列举一些机器不容易理解的案例:
校长说衣服上除了校徽别别别的
过几天天天天气不好
看见西门吹雪点上了灯,叶孤城冷笑着说:
“我也想吹吹吹雪吹过的灯”,然后就吹灭了灯。
今天多得谢逊出手相救,在这里我想真心感谢“谢谢谢逊大侠出手”
灭霸把美队按在地上一边摩擦一边给他洗脑,被打残的钢铁侠说:
灭霸爸爸叭叭叭叭儿的在那叭叭啥呢
姑姑你估估我鼓鼓的口袋里有多少谷和菇!
!
“你看到王刚了吗”“王刚刚刚刚走”
张杰陪俩女儿跳格子:
俏俏我们不要跳跳跳跳过的格子啦

那么对于机器来说,NLU 难点大致可以归为5类:
难点1:语言的多样性
自然语言没有什么通用的规律,你总能找到很多例外的情况。
另外,自然语言的组合方式非常灵活,字、词、短语、句子、段落…不同的组合可以表达出很多的含义。例如:
我要听大王叫我来巡山
给我播大王叫我来巡山
我想听歌大王叫我来巡山
放首大王叫我来巡山
给唱一首大王叫我来巡山
放音乐大王叫我来巡山
放首歌大王叫我来巡山
给大爷来首大王叫我来巡山
难点2:语言的歧义性
如果不联系上下文,缺少环境的约束,语言有很大的歧义性。例如:
我要去拉萨
需要火车票?
需要飞机票?
想听音乐?
还是想查找景点?
难点3:语言的鲁棒性
自然语言在输入的过程中,尤其是通过语音识别获得的文本,会存在多字、少字、错字、噪音等问题。例如:
大王叫我来新山
大王叫让我来巡山
大王叫我巡山
难点4:语言的知识依赖
语言是对世界的符号化描述,语言天然连接着世界知识,例如:
大鸭梨
除了表示水果,还可以表示餐厅名
7天
可以表示时间,也可以表示酒店名
晚安
有一首歌也叫《晚安》
难点5:语言的上下文
上下文的概念包括很多种:对话的上下文、设备的上下文、应用的上下文、用户画像…
U:买张火车票
A:请问你要去哪里?
U:宁夏
U:来首歌听
A:请问你想听什么歌?
U:宁夏
NLU 的实现方式
自然语言理解跟整个人工智能的发展历史类似,一共经历了3次迭代:
基于规则的方法
基于统计的方法
基于深度学习的方法

最早大家通过总结规律来判断自然语言的意图,常见的方法有:CFG、JSGF等。
后来出现了基于统计学的 NLU 方式,常见的方法有:SVM、ME等。
随着深度学习的爆发,CNN、RNN、LSTM 都成为了最新的”统治者”。
到了2019年,BERT 和 GPT-2 的表现震惊了业界,他们都是用了 Transformer,下面将重点介绍 Transformer,因为他是目前「最先进」的方法。

Transformer 和 CNN / RNN 的比较
Transformer 的原理比较复杂,这里就不详细说明了,感兴趣的朋友可以查看下面的文章,讲的很详细:
《BERT大火却不懂Transformer?读这一篇就够了》
下面将摘取一部分《why Self-Attention?A Targeted Evaluation of Neural Machine Translation Architectures》里的数据,直观的让大家看出来3者的比较。
语义特征提取能力
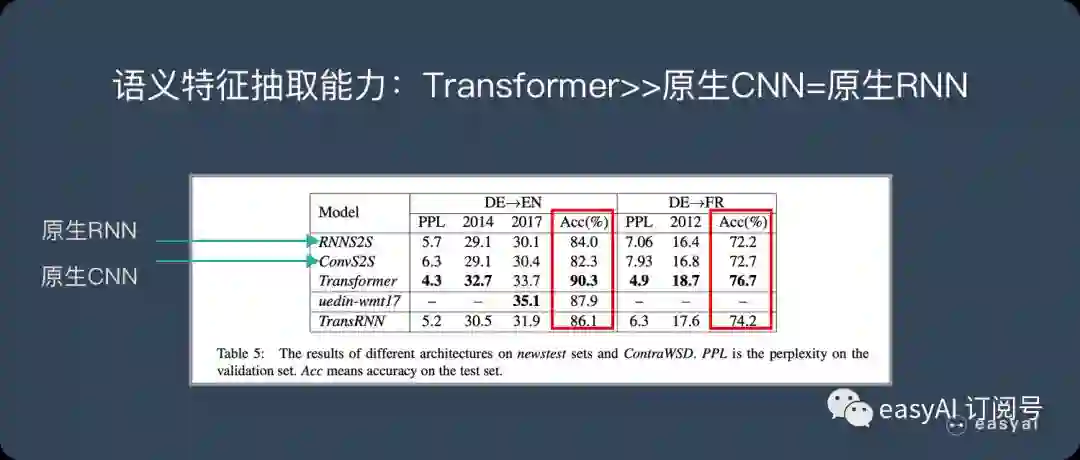
从语义特征提取能力来说,目前实验支持如下结论:Transformer在这方面的能力非常显著地超过RNN和CNN(在考察语义类能力的任务WSD中,Transformer超过RNN和CNN大约4-8个绝对百分点),RNN和CNN两者能力差不太多。
长距离特征捕获能力

原生CNN特征抽取器在这方面极为显著地弱于RNN和Transformer,Transformer微弱优于RNN模型(尤其在主语谓语距离小于13时),能力由强到弱排序为Transformer>RNN>>CNN; 但在比较远的距离上(主语谓语距离大于13),RNN微弱优于Transformer,所以综合看,可以认为Transformer和RNN在这方面能力差不太多,而CNN则显著弱于前两者。
任务综合特征抽取能力

Transformer综合能力要明显强于RNN和CNN(你要知道,技术发展到现在阶段,BLEU绝对值提升1个点是很难的事情),而RNN和CNN看上去表现基本相当,貌似CNN表现略好一些。
并行计算能力及运算效率

Transformer Base最快,CNN次之,再次Transformer Big,最慢的是RNN。RNN比前两者慢了3倍到几十倍之间。
关于 Transformer ,推荐几篇优秀的文章给大家,让大家有一个更综合的了解:
《放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较》
《从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史》
《效果惊人的GPT 2.0模型:它告诉了我们什么》


