ICLR 2019最佳论文 | ON-LSTM:用有序神经元表达层次结构

作者丨苏剑林
研究方向丨NLP,神经网络
个人主页丨kexue.fm
今天介绍一个有意思的 LSTM 变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种 LSTM 内部的神经元是经过特定排序的,从而能够表达更丰富的信息。
ON-LSTM 来自文章 Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到 LSTM 中去,从而允许 LSTM 能自动学习到层级结构信息。
这篇论文还有另一个身份:ICLR 2019 的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。


笔者留意到 ON-LSTM 是因为机器之心的介绍,里边提到它出了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得 ICLR 2019 最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍 ON-LSTM 之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是和
的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始读了好几次仍然像天书一样。总之,文章写法实在不敢恭维。
基本原理
通常来说,在文章的前半部分,都是要先扯一些背景知识的。
LSTM
首先来回顾一下普通的 LSTM。用常见的记号,普通的 LSTM 写为:
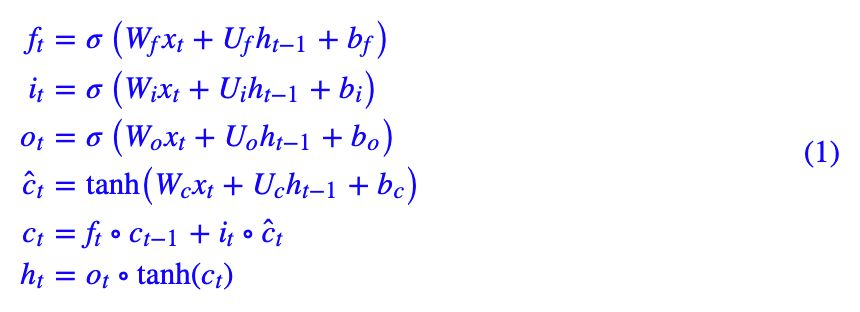
如果熟悉了神经网络本身,其实这样的结构没有什么神秘的,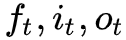
和当前信息
,用 sigmoid 激活,因为 sigmoid 的结果在 0~1 之间,所以它们的含义可以诠释为“门(gate)”,分别称为遗忘门、输入门、输出门。不过我个人觉着 gate 这个名字是不够贴切的,“valve(阀门)”也许更贴切些。
有了门之后,被整合为 ĉt,然后通过 ∘ 运算(对应逐位相乘,有时候也记为 ⊗)与前面的“门”结合起来,来对
和 ĉt 进行加权求和。
下面是自己画的一个 LSTM 的示意图:
▲ LSTM运算流程示意图
语言和序信息
在常见的神经网络中,神经元通常都是无序的,比如遗忘门 ft 是一个向量,向量的各个元素的位置没有什么规律。如果把 LSTM 运算过程中涉及到的所有向量的位置按照同一方式重新打乱,权重的顺序也相应地打乱,然后输出结果可以只是原来向量的重新排序(考虑多层的情况下,甚至可以完全不变),信息量不变,不影响后续网络对它的使用。
换言之,LSTM 以及普通的神经网络都没有用到神经元的序信息,ON-LSTM 则试图把这些神经元排个序,并且用这个序来表示一些特定的结构,从而把神经元的序信息利用起来。
ON-LSTM 的思考对象是自然语言。一个自然句子通常能表示为一些层级结构,这些结构如果人为地抽象出来,就是我们所说的语法信息,而 ON-LSTM 希望能够模型在训练的过程中自然地学习到这种层级结构,并且训练完成后还能把它解析出来(可视化),这就利用到了前面说的神经元的序信息。
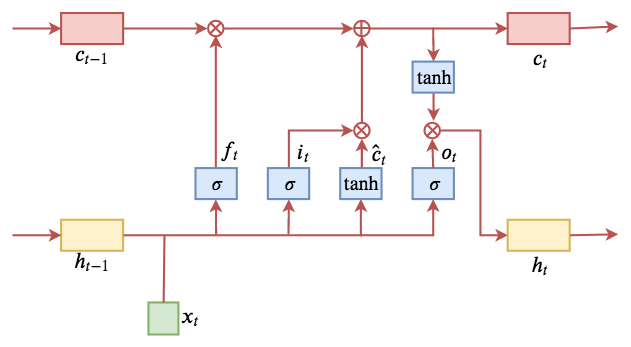
为了达到这个目标,我们需要有一个层级的概念,层级越低代表语言中颗粒度越小的结构,而层级越高则代表颗粒度越粗的结构,比如在中文句子中,“字”可以认为是最低层级的结构,词次之,再上面是词组、短语等。层级越高,颗粒度越粗,那么它在句子中的跨度就越大。
用原文的图示就是:
▲ 层级结构导致了不同模型的不同跨度,也就是不同层级信息的传输距离不一样,这最终将引导我们将层级结构进行矩阵化表示,从而融入到神经网络中。
ON-LSTM
最后一句“层级越高,颗粒度越粗,那么它在句子中的跨度就越大”看起来是废话,但它对于 ON-LSTM 的设计有着指导作用。
首先,这要求我们在设计 ON-LSTM 的编码时能区分高低层级的信息;其次,这也告诉我们,高层级的信息意味着它要在高层级对应的编码区间保留更久(不那么容易被遗忘门过滤掉),而低层级的信息则意味着它在对应的区间更容易被遗忘。
设计:分区间更新
有了这个指导之后,我们可以着手建立。假设 ON-LSTM 中的神经元都排好序后,向量 ct 的 index 越小的元素,表示越低层级的信息,而 index 越大的元素,则表示越高层级的信息。然后,ON-LSTM 的门结构和输出结构依然和普通的 LSTM 一样:
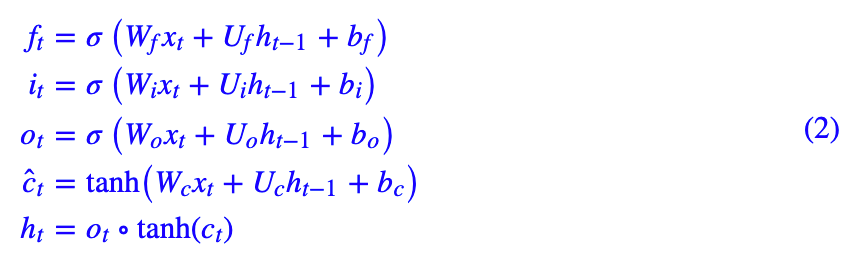
不同的是从 ĉt 到 ct 的更新机制不一样。 由于每次在更新 ct 之前,首先预测两个整数 df 和 di,分别表示历史信息和当前输入 xt 的层级:

至于 F1,F2 的具体结构,我们后面再补充,先把核心思路讲清楚。这便是我不满原论文写作的原因,一上来就定义 cumax,事前事后都没能把思想讲清楚。
有了 df,di 之后,那么有两种可能:
1. df≤di,这意味着当前输入 xt 的层级要高于历史记录的层级,那就是说,两者之间的信息流有交汇,当前输入信息要整合到高于等于 df 的层级中,方法是:
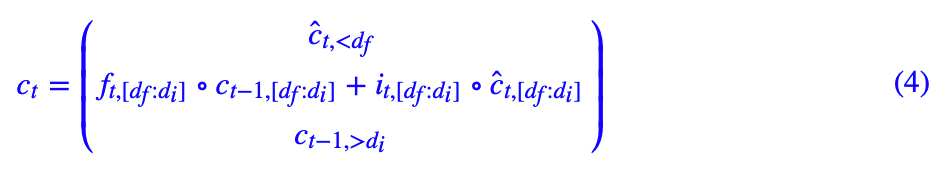
这个公式是说,由于当前输入层级更高,它影响到了交集 [df,di] 的部分,这部分由普通的 LSTM 更新公式来更新,小于 df 的部分,直接覆盖为当前输入 ĉt 对应的部分,大于 di 的部分,保持历史记录对应的部分不变。
这个更新公式是符合直觉的,因为我们已经将神经元排好序了,位置越前的神经元储存越低层结构信息,而对于当前输入来说,显然更容易影响低层信息,所以当前输入的“波及”范围是 [0,di](自下而上),而对于历史记录来说,它保留的是高层信息,所以“波及”范围是 [df,dmax](自上而下,dmax 是最高层级),在不相交部分,它们“各自为政”,各自保留自己的信息;在相交部分,信息要进行融合,退化为普通的 LSTM。
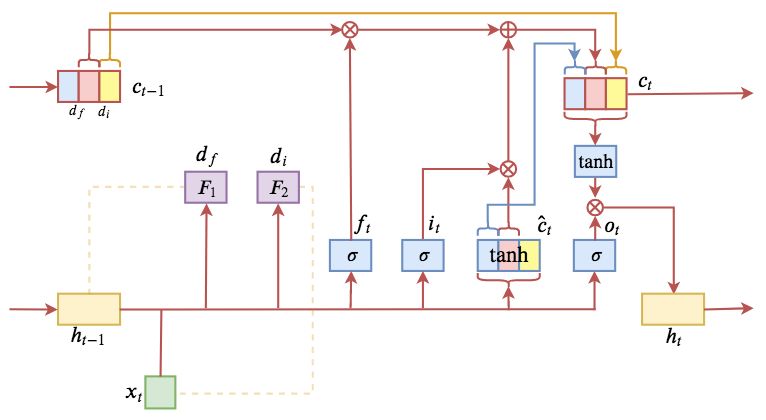
▲ ON-LSTM设计图。主要想法是将LSTM的神经元排序,然后分段更新。
2. df>di,这意味着历史记录和当前输入 xt 互不相交,那么对于 [di,df] 的部分处于“无人问津”的状态,
不愿意去更新它,xt 也没能力去更新它,所以只好置零,而剩下的更新则跟前面一样:

至此,我们能够理解 ON-LSTM 的基本原理了,它将神经元排序之后,通过位置的前后来表示信息层级的高低,然后在更新神经元时,先分别预测历史的层级 df 和输入的层级 di,通过这两个层级来对神经元实行分区间更新。
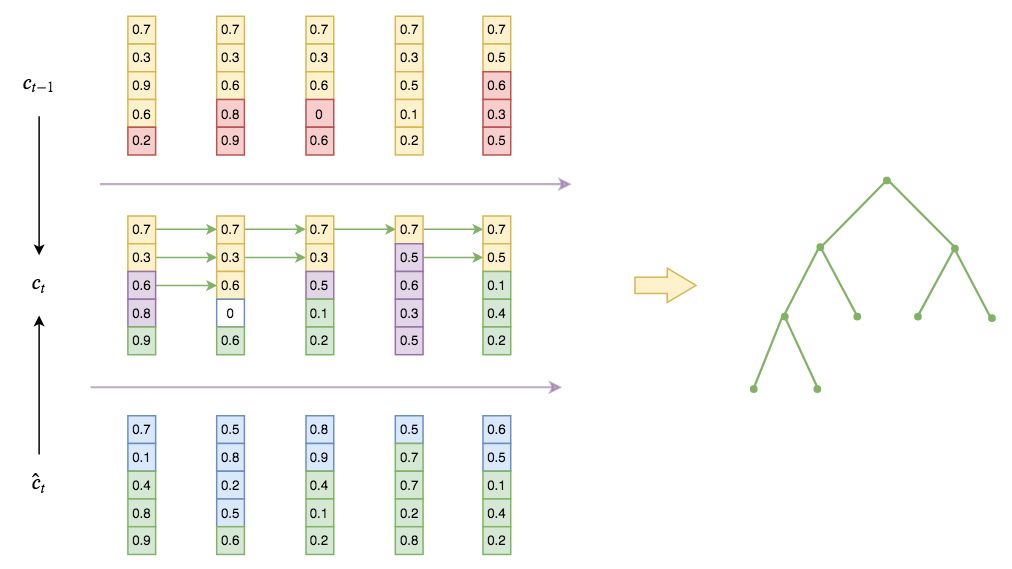
▲ ON-LSTM分区间更新图示。图上数字都是随机生成的,最上为历史信息,最下为当前输入,中间为当前整合的输出。最上方黄色部分为历史信息层级,最下方绿色部分为输入信息层级,中间部分黄色则是直接复制的历史信息,绿色则是直接复制的输入信息,紫色是按照LSTM方式融合的交集信息,白色是互不相关的“空白地带”。从历史信息的复制传递中,我们就可以析出对应的如右图的层次结构。
这样一来,高层信息就可能保留相当长的距离(因为高层直接复制历史信息,导致历史信息可能不断被复制而不改变),而低层信息在每一步输入时都可能被更新(因为低层直接复制输入,而输入是不断改变的),所以就通过信息分级来嵌入了层级结构。更通俗地说就是分组更新,更高的组信息传得更远(跨度更大),更低的组跨度更小,这些不同的跨度就形成了输入序列的层级结构。
请反复阅读这段话,直接完全理解为止,这段话称得上是 ON-LSTM 的设计总纲。
成型:分段软化
现在要解决的问题就是,这两个层级怎么预测,即 F1,F2 怎么构建。用一个模型来输出一个整数不难,但是这样的模型通常都是不可导的,无法很好地整合到整个模型进行反向传播,所以,更好的方案是进行“软化”,即寻求一些光滑近似。
为了进行软化,我们先对 (4),(5) 进行改写。引入记号 1k,它表示第 k 位为1、其他都为 0 的 dmax 维向量(即 one hot 向量),那么 (4),(5) 可以统一地写为:
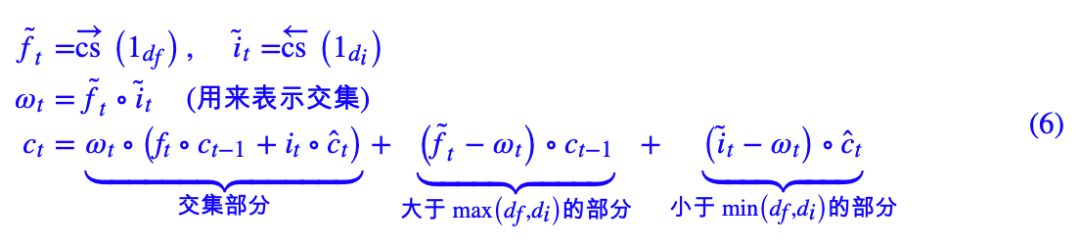
其中分别是右向/左向的 cumsum 操作:
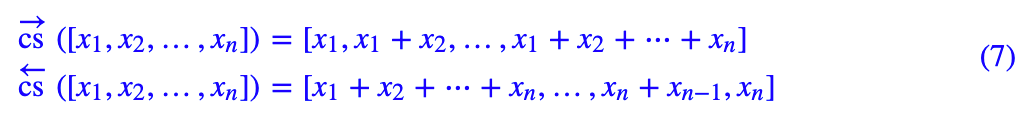
注意,这里指的是 (6) 所给出的结果,跟 (4),(5) 分情况给出的结果,是完全等价的。这只需要留意到给出了一个从 df 位开始后面全是 1、其他位全是 0 的 dmax 维向量,而
给出了一个从 0 到 di 位全是 1、其他位全是 0 的 dmax 维向量,那么
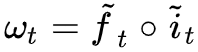
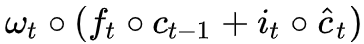
而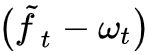
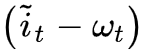
现在,ct 的更新公式由式 (6) 来描述,两个 one hot 向量由两个整数 df,di 决定,而这两个整数本身是由模型 F1,F2 预测出来的,所以我们可以干脆直接用模型预测
就是了。
当然,就算预测出来两个 one hot 向量,也没有改变整个更新课程不可导的事实。但是,我们可以考虑将用一般的浮点数向量来代替,比如:
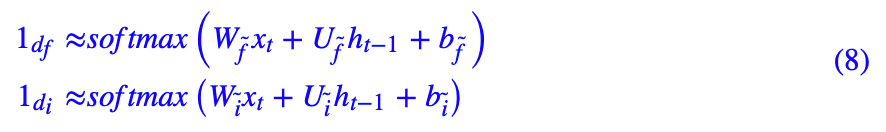
这样一来,我们用一个和 xt 的全连接层,来预测两个向量并且做 softmax,就可以作为
的近似,并且它是完全可导的,从而我们将它们取代
代入到 (6) 中,就得到 ON-LSTM 的 ct 的更新公式:

把剩余部分(即 (2))也写在一起,整个 ON-LSTM 的更新公式就是:
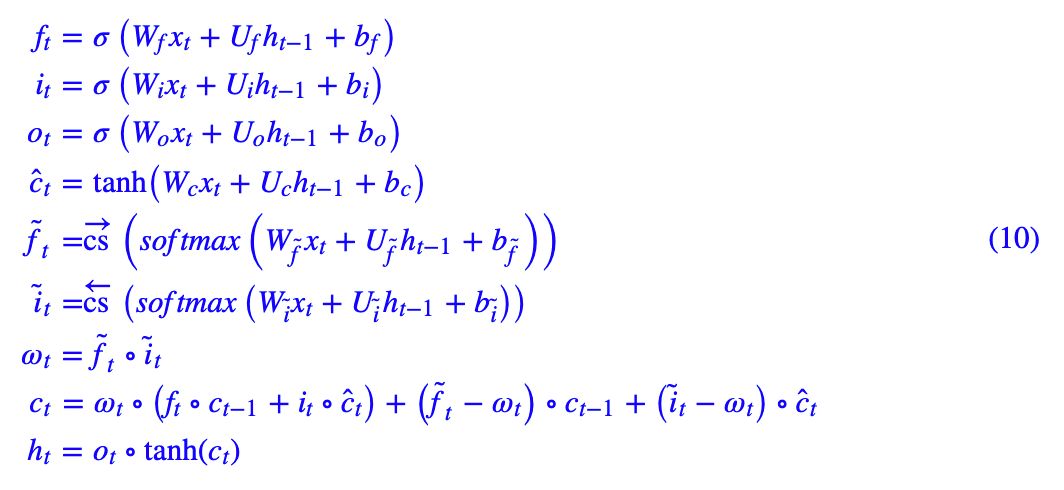
示意图如下。对比 LSTM 的 (1),就可以发现主要改动在哪了。其中新引入的和
被作者称为“主遗忘门(master forget gate)”和“主输入门(master input gate)”。
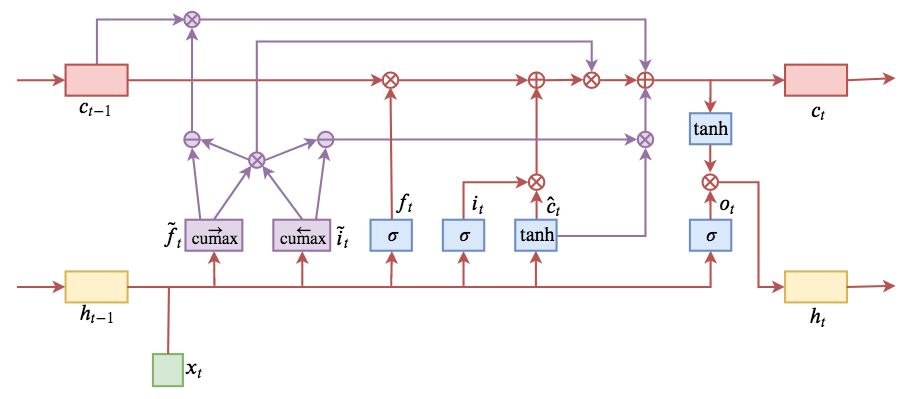
▲ ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
注:
1. 论文中将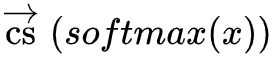
2. 作为数列来看,是一个单调递增的数列,而
是一个单调递减的数列;
3. 对于,论文定义为:
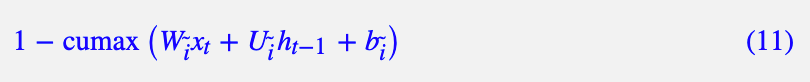
这个选择会产生类似的单调递减的向量,一般情况下没有什么差别,但从对称性的角度来看,我认为我的选择更合理一些。
实验与思考
下面简单汇总一下 ON-LSTM 的实验,其中包括原作者的实现(PyTroch)以及笔者自己的复现(Keras),最后谈及笔者对此 ON-LSTM 的一些思考。
作者实现:
https://github.com/yikangshen/Ordered-Neurons
个人实现:
https://github.com/bojone/on-lstm
限于笔者水平,个人的理解、复现可能存在问题,如果读者发现,请不吝指出,谢谢。
分组的层级
代表层级的向量,
要与 ft 等做∘运算,这意味着它们的维度大小(即神经元数目)要相等。而我们知道,根据不同的需求,LSTM 的隐层神经元数可以达到几百甚至几千,这意味着
,
所描述的层级数也有几百甚至几千。而事实上,序列的层级结构(如果存在的话)的总层级数一般不会太大,也就是说两者之间存在一点矛盾之处。
ON-LSTM 的作者想了个比较合理的解决方法,假设隐层神经元数目为 n,它可以分解为 n=pq,那么我们可以只构造一个 p 个神经元的,
,然后将
,
的每个神经元依次重复 q 次,这样就得到一个 n 维的
,
,然后再与 ft 等做∘运算。例如 n=6=2×3,那么先构造一个 2 维向量如 [0.1,0.9],然后依次重复 3 次得到 [0.1,0.1,0.1,0.9,0.9,0.9]。
这样一来,我们既减少了层级的总数,同时还减少了模型的参数量,因为 p 通常可以取得比较小(比 n 小 1~2 个数量级),因此相比普通的 LSTM,ON-LSTM 并没有增加太多参数量。
语言模型
作者做了若干个实验,包括语言模型、语法评价、逻辑推理等,不少实验中均达到当前最优效果,普遍超越了普通的 LSTM,这证明了 ON-LSTM 所引入的层级结构信息是有价值的。其中我比较熟悉的也就只有语言模型了,就放一个语言模型实验的截图好了:
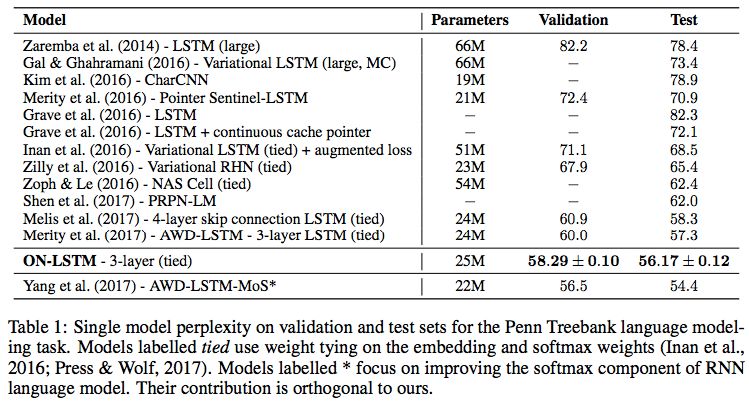
▲ ON-LSTM原论文中的语言模型实验效果
无监督语法
如果仅仅是在常规的一些语言任务中超过普通 LSTM,那么 ON-LSTM 也算不上什么突破,但 ON-LSTM 的一个令人兴奋的特性是它能够无监督地从训练好的模型(比如语言模型)中提取输入序列的层级树结构。提取的思路如下:
首先我们考虑:
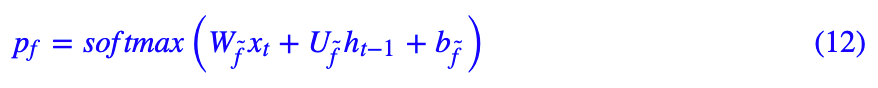
它是在
之前的结果,根据我们前面的推导,它就是历史信息的层级 df 的一个软化版本,那么我们可以写出:

这里的 pf(k) 就是指向量 pf 的第 k 个元素。但是,pf 中所包含的 softmax 本身就是一个“软化”后的算子,这种情况下我们可能考虑“软化”的 argmax 比较好,即:
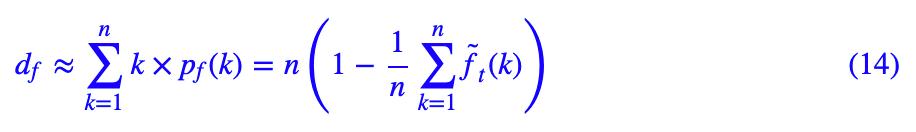
第二个等号是恒等变换,大家可以自行证明一下。这样我们就得到了一个层级的计算公式了,它正比于:
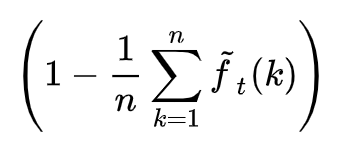
这样以来,我们就可以用序列:
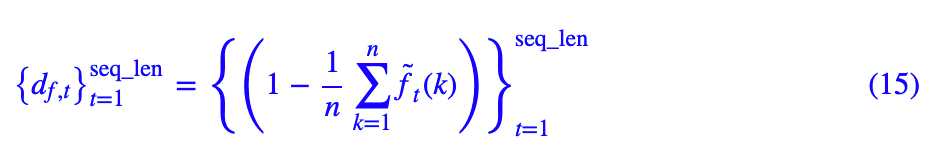
来表示输入序列的层级变化。有了这个层级序列后,按照下述贪心算法来析出层次结构:
给定输入序列 {xt} 到预训练好的 ON-LSTM,输出对应的层级序列 {df,t},然后找出层级序列中最大值所在的下标,比如 k,那么就将输入序列分区为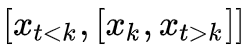
和
重复上述步骤,直到每个子序列长度为 1。
作者是用三层的 ON-LSTM 训练了一个语言模型,然后用中间那层 ON-LSTM 的来计算层级,然后跟标注的语法结构对比,发现准确率颇高。我自己也在中文语料下尝试了一下:
https://github.com/bojone/on-lstm/blob/master/lm_model.py
至于效果,因为我没做过也不了解语法分析,我也不知道怎么评价,反正好像看着是那么一回事,但是又好像不大对一样,所以各位读者自己评价好了。近一两年,无监督语法分析其实还有不少研究工作,可能要都读一读才能更深刻地理解 ON-LSTM。
输入:苹果的颜色是什么
输出:
[
[
[
'苹果',
'的'
],
[
'颜色',
'是'
]
],
'什么'
]
输入:爱真的需要勇气
输出:
[
'爱',
[
'真的',
[
'需要',
'勇气'
]
]
]思考与发散
文章最后,我们来一起思考几个问题。
1. RNN 还有研究价值?
首先,有读者可能会困惑,都 9102 年了,居然还有人研究 RNN 类模型,还有研究价值吗?近年来,BERT、GPT 等基于 Attention 和语言模型的预训练模型,在 NLP 的诸多任务上都提升了效果,甚至有文章直接说“RNN 已死”之类的。事实上真的如此吗?
我认为,RNN 活得好好的,并且在将来的相当长时间内都不会死,原因至少包含下面几个:
第一,BERT 之类的模型,以增加好几个数量级的算力为代价,在一些任务上提升了也就一两个百分点的效果,这样的性价比只有在学术研究和比赛刷榜才有价值,在工程上几乎没什么用(至少没法直接用);
第二,RNN 类的模型本身具有一些无可比拟的优势,比如它能轻松模拟一个计数函数,在很多序列分析的场景,RNN 效果好得很;
第三,几乎所有 seq2seq 模型(哪怕是 BERT 中)decoder 都是一种 RNN,因为它们基本都是递归解码的,RNN 哪会消失?
2. 单向 ON-LSTM 就够了?
然后,读者可能会有疑惑:你要析出层级结构,但是只用了单向的 ON-LSTM,这意味着当前的层级分析还不依赖于将来的输入,这显然是不大符合事实的。这个笔者也有同样的困惑,但是作者的实验表明这样做效果已经够好了,可能自然语言的整体结构都倾向于是局部的、单向的(从左往右),所以对于自然语言来说单向也就够了。
如果一般情况下是否用双向比较好呢?双向的话是不是要像 BERT 那样用 masked language model 的方式来训练呢?双向的话又怎么计算层级序列呢?这一切都还没有完整的答案。
至于无监督析出的结构是不是一定就符合人类自身理解的层级结构呢?这个也说不准,因为比较没有什么监督指引,神经网络就“按照自己的方式去理解”了,而幸运的是,神经网络的“自己的方式”,似乎跟人类自身的方式有不少重叠之处。
3. 能否用到 CNN 或者 Attention?
最后,可能想到的一个困惑是,这种设计能不能用到 CNN、Attention 之中呢?换句话说能不能将 CNN、Attention 的神经元也排个序,融入层级结构信息呢?
个人感觉是有可能的,但需要重新设计,因为层级结构被假设为连续嵌套的,RNN 的递归性正好可以描述了这种连续性,而 CNN、Attention 的非递归性导致我们很难直接去表达这种连续嵌套结构。
不管怎样,我觉得这是个值得思考的主题,有进一步的思考结果我会和大家分享,当然也欢迎读者们和我分享你的思考。
文章小结
本文梳理了 LSTM 的一个新变种 ON-LSTM 的来龙去脉,主要突出了它在表达层级结构上的设计原理。个人感觉整体的设计还是比较巧妙和有趣的,值得细细思考一番。
最后,学习和研究都关键是有自己的判断能力,不要人云亦云,更不能轻信媒体的“标题党”。BERT 的 Transformer 固然有它的优势,但是 LSTM 等 RNN 模型的魅力依然不可小觑。我甚至觉得,诸如 LSTM 之类的 RNN 模型,会在将来的某天,焕发出更强烈的光彩,Transformer 与之相比将会相当逊色。
让我们拭目以待好了。

点击以下标题查看作者其他文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客




