学界 | 伯克利最新:基于视觉模型强化学习的通用机器人

大数据文摘出品
编译:蒋晔、杨威、张弛、蒋宝尚
人类的学习能力是无限的!
有时候,只要看一眼,有些天分的人就能进行模仿。用学术一点的话说就是:只需少量的明确监督和反馈,人类就可以通过简单的交互和对世界的生理感知,来学习各种运动技能。
机器人们“做梦”都想拥有这个技能。虽然在某些特定的方面,机器人取得了重大的进展。但是机器人获得大量且多样化的全部通用技能仍然是一个挑战。
现在,伯克利有个团队开发一款“万能机器人”,无需反复学习,只需看“一眼”就能执行不同的任务,例如整理物品,挑选玩具或者折叠毛巾。

下面,文摘菌将带大家将看看它是如何工作的?机器人如何仅基于原始感知数据(即图像像素,无需物体检测器或手工设计的感知组件)来自我学习?以及展示如何使用已学到的经验来完成许多不同的任务。并且,将演示这种方法如何通过原始像素,执行任务以及与机器人从未见过的物体进行交互。
学会从无监督的交互中进行预测
首先需要一种收集各种数据的方法。如果训练机器人用单个物体执行单一技能,即使用特定的锤子击中特定的钉子,那么它将只学习那个给定的环境, 即锤子和钉子就是它的整个宇宙。
如何建造能够学习更多通用技能的机器人呢?可以让机器人在不同的环境中学习,而不是在单一给定的环境中学习单个任务,类似于孩子玩耍和探索。
如果一个机器人可以自己收集数据并完全自主地学习,那么它就不需要监督,因此可以一天24时刻收集经验并了解世界!此外,多个机器人可以同时收集数据并分享经验,数据收集是可扩展的,因此可以收集具有许多物体和机器人动作的各种数据。为了实现这一点,我们用两个机器人随机采样各种物体,包括玩具和杯子等刚性物体,以及布和毛巾等可变形物体,并同时收集数据:
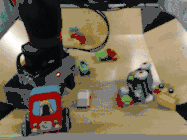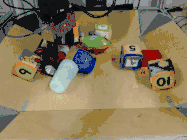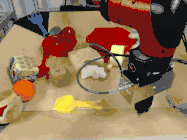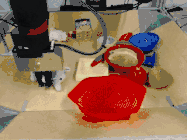

两个机器人与世界交互,通过许多物体和许多动作自主地收集数据。
在数据收集过程中,可以观察机器人的传感器观测的内容:图像像素(视觉),手臂的位置(本体感知)以及发送到机器人的动作命令(动作)。
但是无法直接测量物体的位置,它们对被推动的反应,速度等。此外,在这些数据中,没有进步或成功的概念。与打砖块游戏或敲钉子游戏不同,我们不会获得分数或目标。在现实世界中进行交互时,我们学习的是自身感知(机器人的传感器)提供的东西。
那么,当只有我们的感知时,我们能学到什么?我们可以学习预测,如果机器人以一种方式移动其手臂而不是另一种方式,世界将会是什么样子?

如果机器人以不同的方式移动手臂,学习物理,物体和自身,机器人就会学会预测未来会是什么样子。
预测帮助我们学习关于世界的普遍事物,例如物体和物理。而这些通用知识正是玩打砖块游戏的智能体所缺失的。预测还可以让我们从我们拥有的所有数据中学习:动作和图像流有许多隐式监督信息。这很重要,因为我们没有打分或回报函数。
无模型强化学习系统通常仅从回报函数提供的监督中学习,而基于模型的RL智能体可以利用他们观察到的像素中可用的丰富信息进行自我学习。
现在,我们如何使用这些预测呢?
计划执行人类指定的任务
如果有一个万能的预测模型,那么可以用它来实现目标。也就是说,如果理解行为的后果,那么就可以预期结果来选择相应的行为。
使用基于采样的过程来计划。尤其是,可以在许多不同的候选动作序列中采样,然后选择最好的计划(最有可能导致预期结果的动作),并从拟合最优的候选动作序列的动作分布中重新采样,用以迭代优化。一旦找到了期望的计划,就会在现实世界中执行划的第一步,观察下一个图像,如果发生意外的话就重新计划。
现在自然有一个问题,用户如何为机器人指定目标或期望的结果?我们已经尝试了许多不同的方法来解决这一问题。发现的最简单的机制是,简单地单击初始图像中的一个像素,并通过单击另一个像素位置来指定该像素对应的物体的移动方式。
还可以给出一对以上的像素来指定其他所需物体的运动。虽然有些类型的目标无法以这种方式表达(已经探索了更通用的目标指定方式,例如目标分类器),但发现指定像素位置可用于描述各种各样的任务,并且它非常容易提供。需要说明的是,当机器人与现实世界交互时,用户提供的目标指定方式不会在数据收集过程中使用,即当我们希望机器人使用其预测模型来实现某个目标。
实验
伯克利团队收集了2周的无监督数据,在Sawyer机器人上实验了这种方法。重要的是,训练期间唯一的人类参与是为机器人提供各种各样的物体用于收集随机的机器人运动的数据的编码。
能够以极少的工作就可以几乎每天24小时收集多个机器人的数据。在所有这些数据上(包括两个摄像机视点)训练单一动作条件的视频预测模型,并使用前面描述的迭代计划过程来计划和执行用户指定的任务。
由于着手实现通用性,在广泛的任务中评估了相同的预测模型,这些任务涉及机器人以前从未见过的物体和机器人以前没有遇到的目标。
例如,要求机器人折叠短裤:



上:目标是折叠短裤的左侧。 中:机器人的预测与其计划相对应。 下:机器人执行其计划。
或者把苹果放在盘子上:



上:目标是将苹果放在盘子上。 中:机器人的预测与其计划相对应。 下:机器人执行其计划。
最后,我们还可以要求机器人用毛巾盖住勺子:

左:目标是用毛巾盖住勺子。 中:机器人的预测与其计划相对应。 右:机器人执行其计划。
有趣的是,我们发现,即使模型的预测远非完美,它仍然可以使用这些预测来有效地实现指定的目标。
相关工作
已有许多工作针对这个基于模型的强化学习(RL)的问题,即学习预测模型,然后使用该模型来行动或使用它来学习策略。在此类的先前工作中,许多集中在设置物体的位置或者其它可直接获得的任务相关信息,而不是通过图像或其他原始传感器进行观测。
这种低维状态表示是一种很强的假设,在现实世界中通常是不可能实现的。直接对原始图像帧进行操作的基于模型的RL方法尚未得到广泛研究。针对简单的合成图像和视频游戏环境,已经提出了几种算法,这些算法集中在一组固定的物体和任务上。其他工作研究了现实世界中侧重个人技能的基于模型的RL。
最近的一些工作研究了自我监督的机器人学习,其中大规模的未利用数据收集被用于学习个人技能,例如抓握,推动与抓握的协作或避障。
抓握
https://arxiv.org/abs/1603.02199
推动与抓握的协作
https://arxiv.org/abs/1803.09956
避障
https://arxiv.org/abs/1704.05588
讨论
在视觉上多样的设定中,泛化到许多不同的任务可以说是当今强化学习和机器人研究的最大挑战之一。深度学习大大减少了部署算法所需的特定任务的工程量;然而,现有方法通常需要大量的监督经验或集中于掌握单个任务。结果表明,伯克利的方法可以泛化到大量的任务和物体,包括以前从未见过的任务和物体。
模型的通用性是从现实世界中进行大规模自我监督学习的结果。这些结果代表了向前迈进的重要一步,即单个的机器人强化学习系统实现了任务的通用性。
【今日机器学习概念】
Have a Great Definition


志愿者介绍
后台回复“志愿者”加入我们







