【新作集锦】开局告捷!贺智能感知中心11篇论文挺进CVPR2018!


今日聚焦
自动化所智能感知与计算中心11篇论文被CVPR2018接收,再创历史新高!紫冬君特向各位老师和同学表示祝贺!文章概要整理如下(排名不分先后),欢迎阅读,转发更赞!
【01】Dynamic Feature Learning for Partial Face Recognition
Lingxiao He, Haiqing Li, Qi Zhang, Zhenan Sun
在视频监控,移动手机等场景中,部分人脸识别是一个非常重要的任务。然而,很少有方法研究部分人脸块识别。我们提出一种动态特征匹配方法来解决部分人脸识别问题,它结合全卷积网络和稀疏表达分类。首先,利用全卷积网络提取Gallery和Probe的特征图;其次,利用一个大小滑动窗口把Gallery的特征图分解为与Probe特征图大小相同的子特征图,进而动态特征字典;最后,利用稀疏表达分类来匹配Probe特征图与动态特征字典的相似度。基于动态特征匹配方法,我们提出了滑动损失来优化全卷积网络。该损失减小类内变化,增加了类间变化,从而提高动态特征匹配的性能。相比于其他部分人脸识别方法,我们提出的动态匹配方法取得很好的性能。
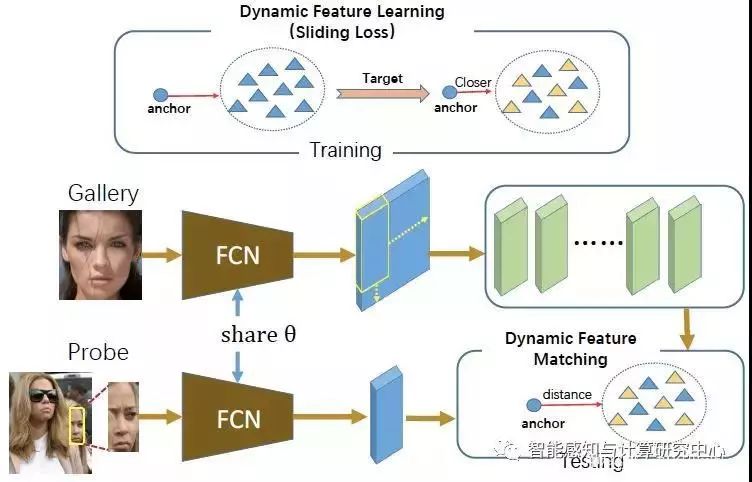
动态特征匹配的部分人脸识别框架

【02】Deep Spatial Feature Reconstruction for Partial Person Re-identification: Freestyle Approach
Lingxiao He, Jian Liang, Haiqing Li, Zhenan Sun
部分行人再识别是一个非常重要并且具有挑战性的问题。在无约束环境中,行人容易被遮挡,有姿态和视角变化,所以有时候只有部分可见的行人图像可用于识别。然而,很少有研究提出一种可以识别部分行人的方法。我们提出了一种快速且精确的方法来处理部分行人再识别的问题。提出的方法利用全卷积网络抽取与输入图像尺寸相对应的空域特征图,这样输入的图像没有尺寸约束。为了匹配一对不同尺寸大小的行人图像,我们提出了一种不需要行人对齐的方法:深度空域特征重建。特别地,我们借鉴字典学习中重建误差来计算不同的空域特征图的相似度。按照这种匹配方式,我们利用端到端学习方法增大来自于同一个人的图像对的相似度,反之亦然。由此可见,我们方法不需要对齐,对输入图像尺寸没有限制。我们在Partial REID,Partial iLIDS和Market1501上取得很好的效果。
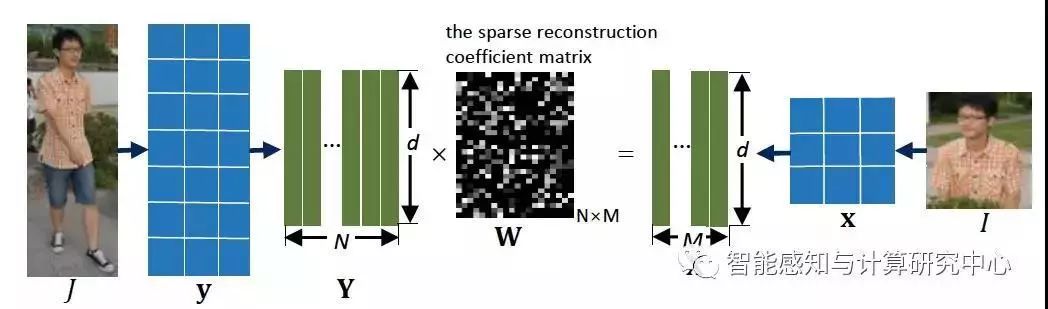
深度空域特征重建

【03】Adversarially Occluded Samples For Improving Generalization of Person Re-identification Models
Houjing Huang, Dangwei Li, ZhangZhang, Kaiqi Huang
行人再识别(ReID)是跨摄像机行人检索任务,由于存在光照变化、视角变化、遮挡等复杂因素,目前的模型往往在训练阶段达到了很高的准确率,但是测试阶段的性能却不尽人意。为了提高模型的泛化性能,我们提出了一种特殊的样本来扩充数据集:对抗式遮挡样本。整个方法流程如下:(1)按照常用的方法训练一个ReID模型;(2)通过网络可视化的方法找出模型在识别训练样本时所关注的区域,对这些区域进行(部分)遮挡就可以产生新的样本,同时我们保持这些样本原有的类别标签;(3)最后,把新的样本加入到原始数据集中,按照之前的方法训练一个新的模型。这种样本不仅模拟了现实中的遮挡情况,而且对于模型来说是困难样本,可以给模型的训练提供动量,从而跳出局部极小点,减少模型的过拟合。实验发现原始的ReID模型识别训练样本时只关注一些局部的身体区域,加入新样本训练后的模型则可以同时关注到一些之前没关注的身体区域,从而提高了模型在测试阶段的鲁棒性。下图是该方法的一个具体实现,其中ReID采用ID多分类模型,模型可视化方法采用滑动窗口遮挡的方法。
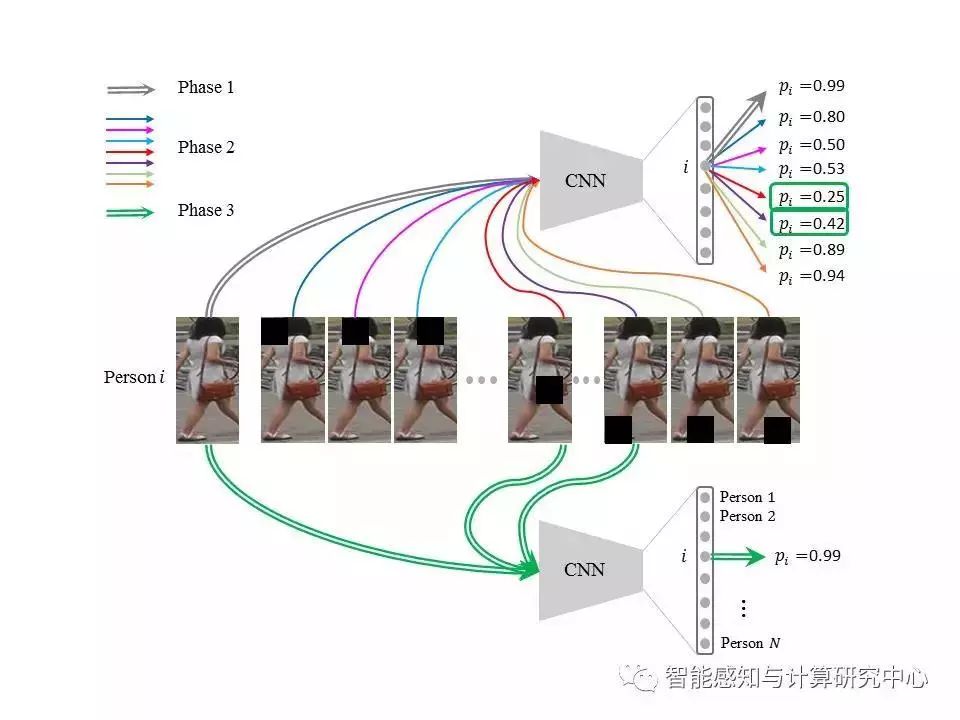
基于对抗式遮挡的数据扩增算法流程图
【04】Learning Semantic Concepts and Order for Image and Sentence Matching
Yan Huang, Qi Wu, Liang Wang
图像文本匹配的关键问题在于如何准确度量图像文本之间的跨模态相似度。我们通过数据分析发现:图像文本之所以能够匹配,主要是由于如下两点原因:1)图像文本虽体现不同的模态特性,但他们包含共同的语义概念;2)语义概念的集合并不是无序的,而是按照一定的语义顺序组织起来的。由此,我们提出了一个模型来联合对图像文本所包含的语义概念和语义顺序进行学习。该模型使用了一个多标签区域化的卷积网络来对任意图像预测其所包含的语义概念集合。然后,基于得到的语义概念将其有规律地排列起来,即学习语义顺序。这一过程具体是通过联合图像文本匹配和生成的策略来实现的。此外,还探究了局部语义概念与全局上下文信息之间的互补作用,以及对文本生成的影响。我们在当前主流的图像文本匹配数据库Flickr30k和MSCOCO上进行了大量实验,验证了我们所提出方法的有效性,并取得了当前最好的跨模态检索结果。
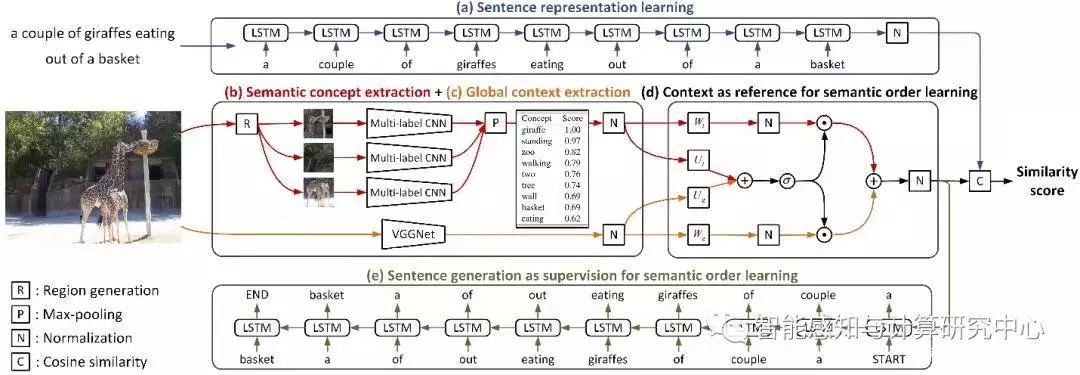
联合图像语义概念和语义顺序学习框架
【05】A2-RL: Aesthetics Aware Reinforcement Learning for Image Cropping
Debang Li,Huikai Wu,Junge Zhang,Kaiqi Huang
随着当前图像数据量的不断增长,对图像进行自动处理的需求也逐渐变大,而图像裁剪是图像处理中的一个十分重要的步骤。图像自动裁剪技术不仅能够快速的完成对大多数图片的处理,同时还能够辅助专业摄像师找到更好的视角来提升图像的构图质量,其具有十分大的应用价值。由于图像裁剪的数据标注较难获得,而且一般数据量较少,我们提出了一种基于强化学习的弱监督(不需要裁剪框标注)图像自动裁剪算法A2RL。之前的弱监督自动裁剪算法大部分使用滑动窗口来获取候选区域,其需要耗费较大的计算资源和时间,为了解决上述问题,我们将强化学习引入到自动裁剪中,使用一个智能体(agent)在输入图像上自适应的调整候选区域的位置和大小。该智能体以图像的全局特征和局部特征作为观测信息,并且根据当前和历史的观测作为依据来决定下一步的动作。在训练过程中,该智能体根据图像质量的评分计算奖励,并使用A3C算法进行训练,最终学到较好的候选区域调整策略。在实验过程中,我们的方法在多个标准的裁剪数据集上进行了测试,其不仅在速度上取得了较大的提升,同时在精度上也有明显的提高。我们方法的整体框架图为:
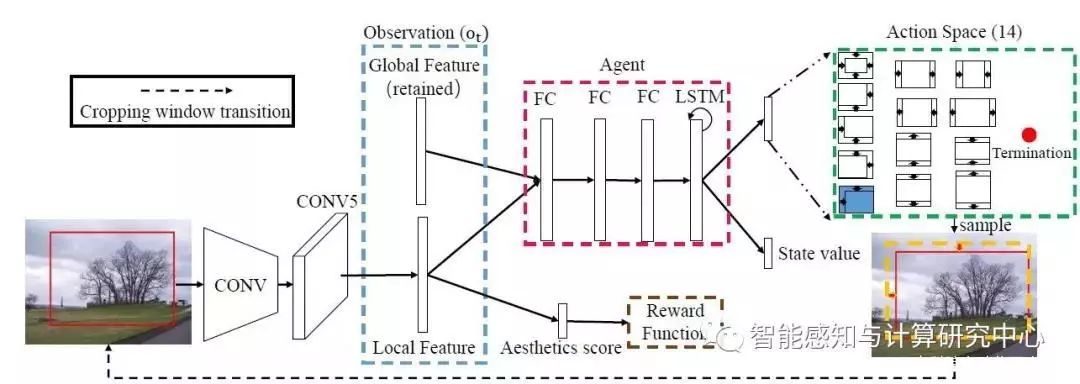
基于强化学习的图像自动裁剪模型架构
【06】Discriminative Learning of Latent Features for Zero-Shot Recognition
Yan Li, Junge Zhang, Kaiqi Huang, Jianguo Zhang
零样本学习(Zero-Shot Learning)通过在视觉和语义两个空间之间学习一个共同的嵌入式空间,能够实现对测试集中的未知类别进行测试。以往的零样本工作,主要集中在嵌入式空间学习过程中,忽略了视觉特征、语义特征在零样本学习中的作用。我们针对传统的零样本学习过程中,特征表达区分度不足的问题,从视觉空间和语义空间两个方面提出了改进方法,在两个空间同时学习到区分度更强的特征表达,进而极大地提升了零样本学习的识别性能。具体来说,1)在视觉空间,我们提出了zoom net,从原始的图片中,自动挖掘具有区分度的图片区域。2)在语义空间,除了用户定义的属性之外,我们利用triplet loss,自动地学习具有区分度的“隐式属性”。3)最终,图片空间中的区分性区域挖掘,以及语义空间中的区分性隐属性学习两个模块在一个端到端框架中联合学习,共同促进。
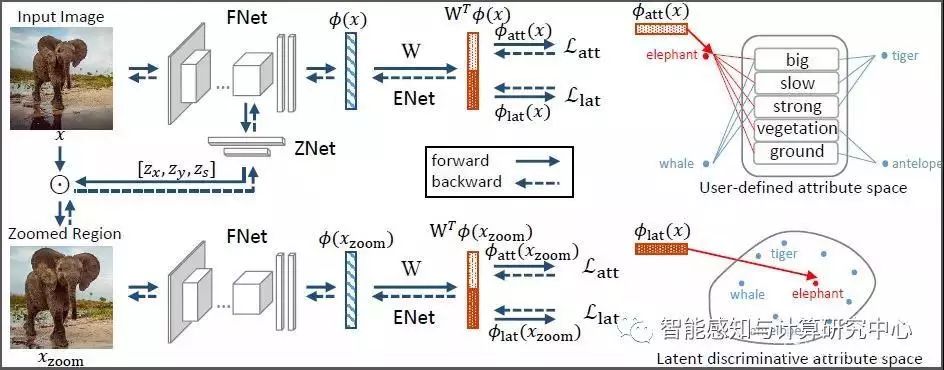
用于零样本学习的隐式判别性特征挖掘框架
【07】Pose-Guided Photorealistic Face Rotation
Yibo Hu, Xiang Wu, Bin Yu, Ran He, Zhenan Sun
随着深度学习的发展,人脸识别算法的性能得到了广泛提升,然而大姿态人脸识别问题依然亟待解决。人脸旋转为人脸识别中的大姿态问题提供了一种有效的解决方式。我们提出了一种任意角度的人脸旋转算法Couple-Agent Pose-Guided Generative Adversarial Network (CAPG-GAN)。CAPG-GAN通过人脸关键点编码姿态信息指导对抗生成网络进行人脸生成任务。同时使用身份保持损失函数和全变分正则项约束人脸的身份信息和局部纹理信息。最终我们的算法在Multil-PIE和LFW上均取得了不错的识别率,同时如图所示,CAPG-GAN可以根据人脸关键编码信息生成任意角度人脸。
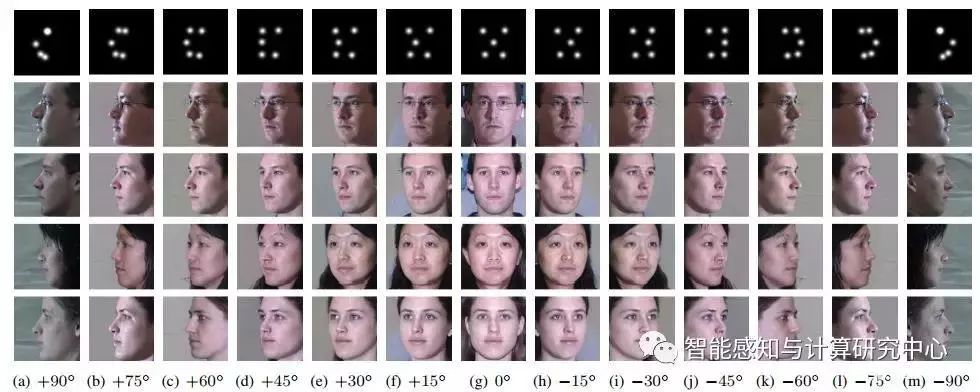
不同姿态人脸图像生成结果
【08】Multistage Adversarial Losses for Pose-Based Human Image Synthesis
Chenyang Si, Wei Wang, Liang Wang, Tieniu Tan
单张图片的多视角图像合成在计算机视觉中是一个非常重要并且具有挑战性的问题,而且对于人的多视角图像合成在对人体行为理解中具有很重要的应用价值。利用人的多视角合成可以有效地解决在计算机视觉中存在的跨视角问题,例如跨视角行为识别、跨视角行人再识别等等。由于人姿态的多变性,人的多视角图像合成比刚性物体(如车、椅子等等)的多视角合成更具有挑战性。我们提出了多阶段对抗损失函数在基于人体关键点的多视角人体图像合成算法,该算法可以生成高质量多视角人体图像,而且可以保持合成人的姿态在三维空间中保持一致。为了可以生成高质量图像,我们提出从低维度人体结构到图像前景,最后合成背景的多阶段图像生成模型,为了解决均方误差损失函数引起的图像模糊的问题,我们在多阶段使用对抗损失函数。我们的算法如图所示:
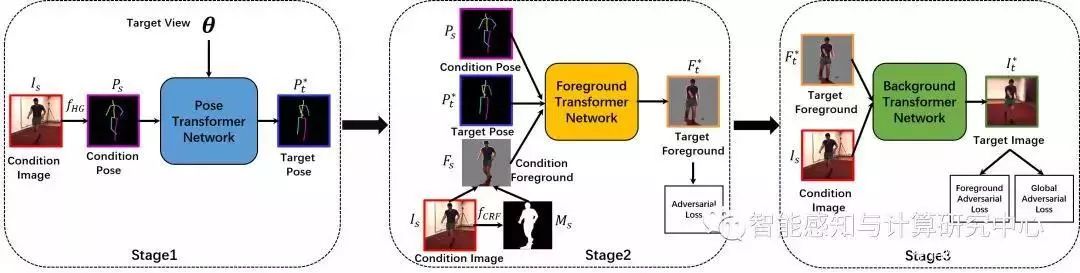
基于pose的多阶段对抗学习的人体图像合成网络框架
【09】Mask-guided Contrastive Attention Model for Person Re-Identification
Chunfeng Song, Yan Huang, Wanli Ouyang, and Liang Wang
行人再识别问题是一个重要且具有挑战性的经典计算机视觉任务。通常摄像头采集到的行人图像中含有杂乱的背景,并且图像中的行人通常有多种多样的姿态和视角,这些多样性造成的困难在之前的研究中都尚未得到很好的解决。为了解决上述问题,我们引进了二值化的行人分割轮廓图作为额外输入,并与彩色图像合成为四通道的新输入,然后设计了一种基于分割轮廓图的对比注意模型来学习背景无关的行人特征。在此基础上,我们提出了一种区域级别的三元组损失函数,分别来约束来自全图区域、行人身体区域、背景区域的特征,提出的损失函数可以让来自全图区域和行人身体区域的特征在特征空间靠近,并远离背景区域,最终达到去除背景的作用。所提出的方法在三个行人再识别数据集上验证了有效性,取得了当前最好的性能。
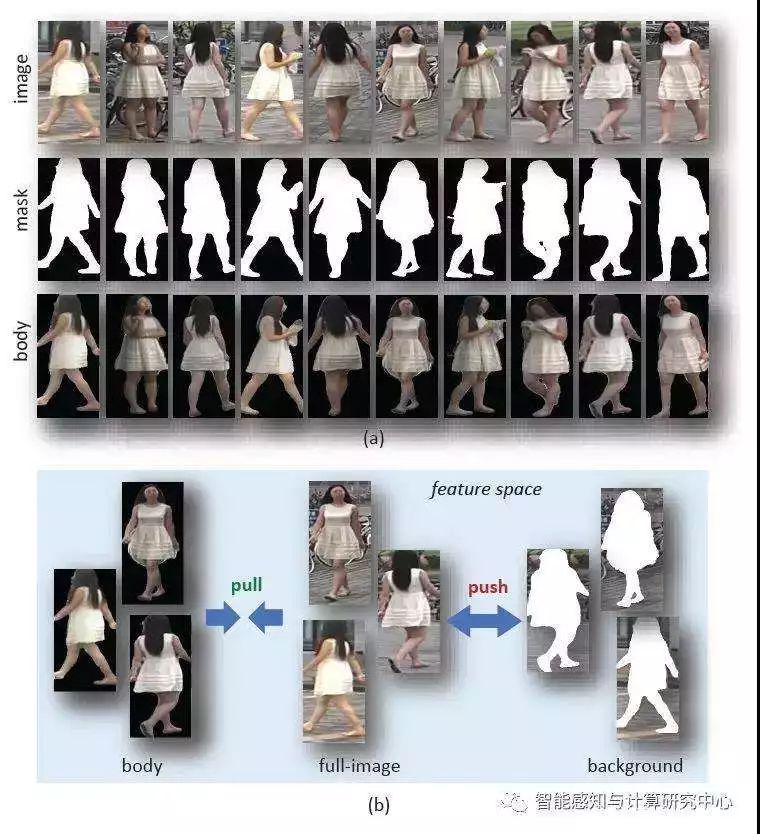
二值化分割轮廓与区域级别三元组约束示意图
【10】M^3: Multimodal Memory Modelling for Video Captioning
Junbo Wang, Wei Wang, Yan Huang, Liang Wang, Tieniu Tan
视频描述对于理解视觉与语言是十分重要的一环,同时也是很有挑战性的任务。它有很多的实际应用价值,包括人机交互、视频检索、为盲人转述视频等。针对这一问题,我们提出了一个多模态记忆模型用于视频描述,这一模型建立了视觉与文本共享的记忆存储器用来模拟长范围视觉文本依赖性并且进一步指导视频描述中的全局视觉目标的关注。借鉴神经图灵机模型的原理,该模型通过多次读写操作与视频和句子进行交互并附加了一个外部记忆存储器用来存储来自视觉与语言模态的信息。下图展示了用于视频描述的多模态记忆建模的整体框架。这一框架包含三个关键模块:基于卷积网络的视频编码器,多模态记忆存储器,基于LSTM的文本解码器。(1)基于卷积网络的视频编码器首先利用预训练的2D或者3D卷积网络模型提取关键帧或段的特征,再利用时序注意模型选择与当前单词最相关的视觉表示,并写入到记忆存储器中;(2)基于LSTM的文本解码器利用LSTM模型对句子的产生进行建模,它预测当前的单词不仅依赖于之前时刻的隐藏表示,而且还有从记忆存储器中读取的信息,同样地,它会向记忆存储器中写入更新的表示。(3)多模态记忆存储器包含一个记忆存储矩阵用来与视频编码器和文本解码器进行交互,例如,从LSTM解码器中写入隐藏表示和读取记忆内容用于解码器。每一步写入操作都会更新多模态记忆存储器。最后,我们在两个公开的数据集(MSVD和MSR-VTT)上对提出的模型进行了评价。实验结果表明提出的模型在BLEU和METEOR两个指标上都超过了许多当前最好的结果。
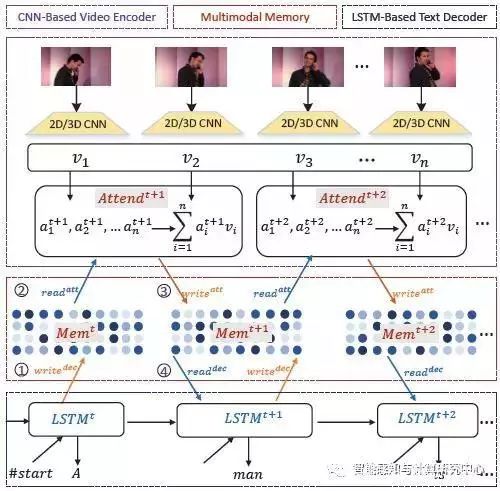
用于视频描述的多模态记忆模型架构
【11】Fast End-to-End Trainable Guided Filter
Huikai Wu, Shuai Zheng, Junge Zhang, Kaiqi Huang
我们提出了一个全新的用于联合超分 (Joint Upsampling) 的深度学习模块---引导滤波单元 (Guided Filtering Layer)。此模块将传统的引导滤波 (Image Guided Filtering) 算法建模为一个可以反向传播、与其他模块联合训练的深度学习单元,同时还引入可以自适应学习的引导图 (Guidance Map)来提高灵活性。通过与原有的卷积神经网络结合,引导滤波单元可以广泛地应用于稠密预测任务 (Dense Prediction Task),并获得更快的速度、更高的精度和更少的内存占用量。试验证明,引导滤波单元可以在众多图像处理任务中取得最好的性能并获得10至100倍的速度提升。在计算机视觉中的众多稠密匹配任务中,此模块同样可以取得显著的性能提升。代码和论文将公布在https://github.com/wuhuikai/DeepGuidedFilter。

使用卷积神经网络和提出的引导滤波单元进行图像到图像变换的结果展示

更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
来源:智能感知与计算研究中心
整理:郭瑞娥
编辑:欧梨成


中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!
觉得好,就竖个大拇指吧!

