局部人脸识别的动态特征匹配(文末附文章及源码地址)
【导读】该文章被Trans收录。无约束环境下的局部人脸识别(PFR)是一项非常重要的任务,尤其是在视频监控和移动设备等由于遮挡、视野外、大视角等原因容易捕捉到局部人脸图像的情况下。然而,到目前为止,很少有人关注PFR,因此,识别任意patch的问题的人脸图像在很大程度上仍未解决。提出了一种新的局部人脸识别方法——动态特征匹配(DFM),该方法将全卷积网络和稀疏表示分类(SRC)相结合,解决了不同人脸大小的局部人脸识别问题。DFM不需要局部人脸相对于整体人脸的先验位置信息。通过共享计算,对整个输入图像进行一次特征图的计算,大大提高了速度。
背景
近年来,由于深度卷积神经网络(CNNs)的迅速发展,它在银行、边境控制、移动锁定和签名系统等实际应用中得到了广泛的应用。虽然人脸识别算法的性能有所提高,但这些算法在没有用户协作的不受控制的环境中仍然不能很好地处理局部人脸。在由视频监控摄像机拍摄的典型场景中,如下图所示,1)人脸可以被其他个人的脸、太阳镜、帽子或围巾等物体遮住;2)在没有用户合作和意识的情况下以各种姿势拍摄;3)部分放置在摄像机的视野之外。

此外,监控录像是案件调查的重要线索,犯罪嫌疑人可能只露出部分人脸。因此,开发一个既适用于整体人脸又适用于局部人脸的人脸识别系统是至关重要的。
现有的基于CNN的人脸识别网络有一个明显的缺点:它们需要固定输入图像的大小(例如224×224),因为全连接的层需要输入向量有确定的大小。因此,它们不能直接处理任意大小/尺度的面部图像,如上图所示。具体可见“我们知识星球的分析”。(https://articles.zsxq.com/id_jprzhdbdoqd3.html)
在计算任意尺寸人脸图像的特征表示时,CNN是不有效的。
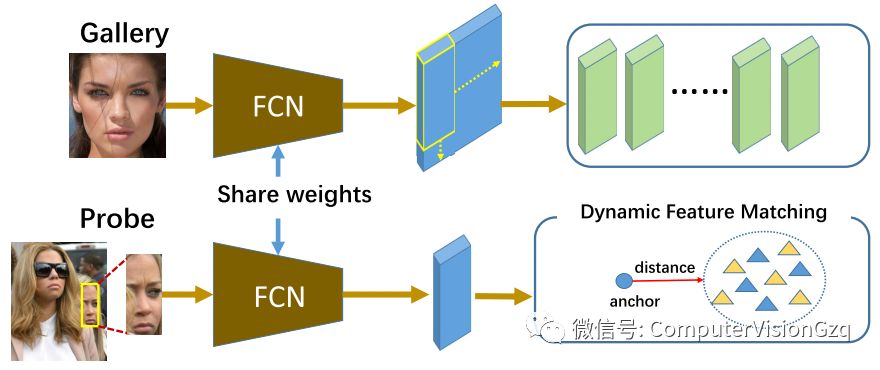
今天就介绍了一种局部人脸识别方法:动态特征匹配(DynamicFeatureMatch,DFM),它可以处理任意尺寸的局部人脸,而无需额外的预处理,具有较高的精度和计算效率。上图展示出了DFM的结构。
全卷积网络(FCNs)适用于任意大小的输入图像,同时生成具有相应大小的输入图像的空间特征映射。首先,应用FCN技术提取给定图库和探测面的空间特征图。为了获得更多的鉴别特征,将最近成功的人脸模型VGGFace通过丢弃网络中的非卷积部分转移到FCN。不管输入脸的大小/规模如何,最后的池化层都用作特征提取器。其次,在SWM的激励下,建立了一个与探针特征映射相同大小的滑动窗口,将图库特征映射分解为几个特征级的图库子特征映射(探针特征映射的维数与每个图库子特征映射的维数相等)。
给出了一个新的探针,将整个图库特征映射分解为与探针特征映射大小相对应的子特征映射,而不需要重复计算图库特征映射。这个框架是有利的,因为卷积层只在整个/局部脸上转发一次。与某些文章的SWM相比,该方法的速度提高了20×。最后,采用稀疏表示分类(SRC)实现无对齐匹配。SRC提供了一个每类一个样本的策略,在(S. Liao, A. K. Jain, and S. Z. Li, “Partial face recognition: Alignmentfree approach,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 5, pp. 1193–1205, May 2013.)中实现了不对齐的部分人脸匹配。该稀疏解决方案提供了一种可行方案,其中探针特征映射由这些图库子特征映射线性表示。不幸的是,SRC最小化了重建误差,而不对图库子特征映射的选择施加限制。因此,可以选择一些不同的子特征映射来满足最小重建目标误差。
为了解决这一问题,在SRC中加入了子特征映射选择约束,因此,相似的子特征图在特征构造中得到了越来越多的关注,大大减少了匹配不匹配的可能性。实验验证了该策略的有效性。
算法框架
Fully Convolutional Network
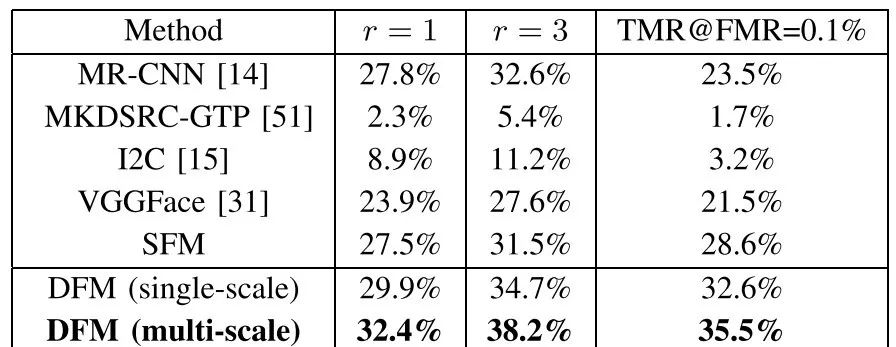
典型的识别网络采用固定大小的输入,产生非空间输出。分类和检索任务中使用的全连接层计算固定维特征表示,而不考虑空间坐标。具有全连接层的卷积神经网络不能从任意大小的输入中推断特征表示,因为生成的特征向量的长度必须是一个预先定义的固定维数。例如,VGGFace需要224×224张人脸图像才能推断出4096维特征向量。为了处理任意大小的人脸图像,丢弃了全连接层,从不同大小的输入中得到一个全卷积网络(FCN)的空间特征表示。提出的FCN是在一个成功的人脸识别模型VGGFace的基础上实现的,该模型生成了健壮的特征,如下表所示。
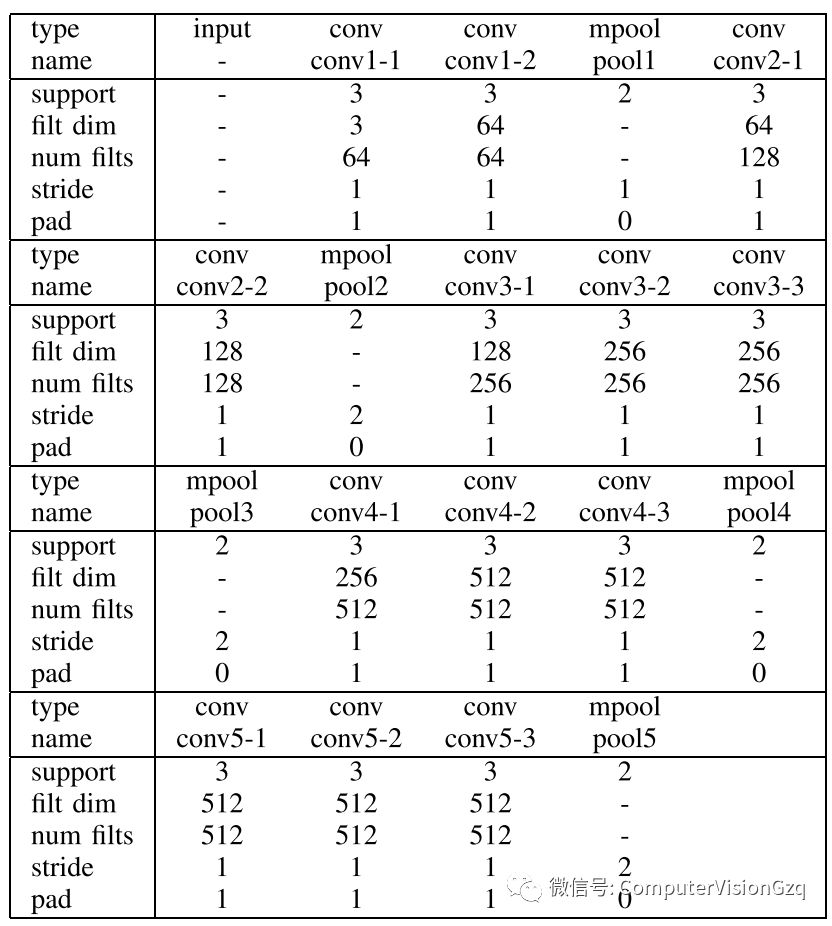
FCN包含卷积层、池化层和ReLU层。FCN中的最后一个池化层生成空间特征表示(这些输出称为特征映射),Softmax损失被连接到池化5层,使得池化5层的输出更具判别性。修改后的FCN(来自VGGFace)在Casia-WebFace数据库上进行了微调。在训练阶段,所有大小相同的图像(实验中为224×224)都用于FCN的训练,而Softmax损失的输出则由训练集中subjects决定,并采用随机梯度下降(SGD)进行优化。
Dynamic Feature Representation & Matching
按照惯例,数据库中包含的一组固定大小的多类整体面孔称为图片库。有待识别的人脸/局部人脸称为探针。探针的大小等于或小于图库中面部图像的大小。“计算机视觉协会”知识星球详细介绍了所提出的动态特征构造方法。

Multi-Scale Representation
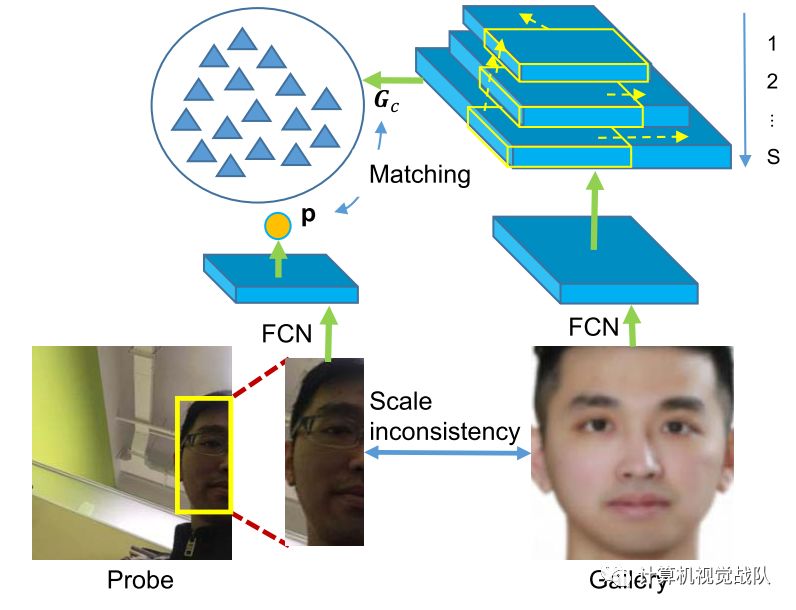
实现不同探针尺度的不变性是识别任意一幅人体图像的一个具有挑战性的问题。对于整体人脸识别,可以直接调整人脸图像的大小,使其具有预定的尺度。如下图所示,很难明确地确定局部人脸尺度(探针脸和数据人脸有不同的尺度)。因此,局部脸和整体脸之间的尺度很容易因尺度不一致而不匹配,从而导致性能下降。这一观察指出,单尺度表示法对尺度变化的鲁棒性不是很强,为了减轻尺度不匹配的影响,DFM中采用了多尺度表示法。
实验结果
表1 1000类性能比较(SINGLE-SHOT)
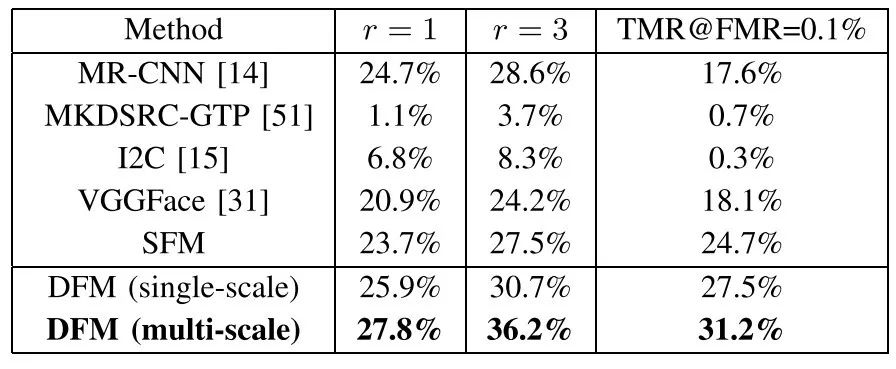
表2 1000类性能比较(MULTI-SHOT)

不同人脸区域样本
文章地址:
http://openaccess.thecvf.com/content_cvpr_2018/papers/He_Dynamic_Feature_Learning_CVPR_2018_paper.pdf
源码:http://www.cbsr.ia.ac.cn/users/znsun/
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。

我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

微信学习讨论群,我们会第一时间在该些群里预告!

